인덱스로 쿼리 속도 개선하기!
지난번에 겪었던 카드사 고객사의 성능 개선 삽질기를 풀어볼까 해요. 비슷한 경험 있으실 거예요... 분명 예상했던 곳이 아닌 다른 곳에서 병목이 터져버리는... 😩
저도 이번에 애 좀 먹었습니다. "상담 이력 다운로드" 때문에 성능 문제가 터질 거라고 예상했는데... 로그인에서부터 삐걱거릴 줄이야!
로그인부터 버벅인다고? (Ft. Gatling)
저는 원래 상담 이력 다운로드 기능에서 병목이 생길 거라고 확신했어요. 워낙 상담량이 많은 사이트라, 이력을 한 번에 쭉 내려받는 과정에서 부하가 상당할 거라고 봤죠. 그래서 게틀링(Gatling)이라는 녀석을 사용해서 시나리오를 짜봤습니다.
게틀링(Gatling) 테스트 시나리오
- 약 100명 정도의 상담사 동시 로그인
- 상담 이력 다운로드 요청
- 동시에 500건의 상담 처리
야심 차게 테스트를 돌렸습니다!!
"자, 이제 다운로드 부분에서 그래프가 솟구치겠구만!" 하고 모니터를 뚫어져라 보고 있었는데...
"다운로드 전부터 부하가 발생한다...? 왜?"
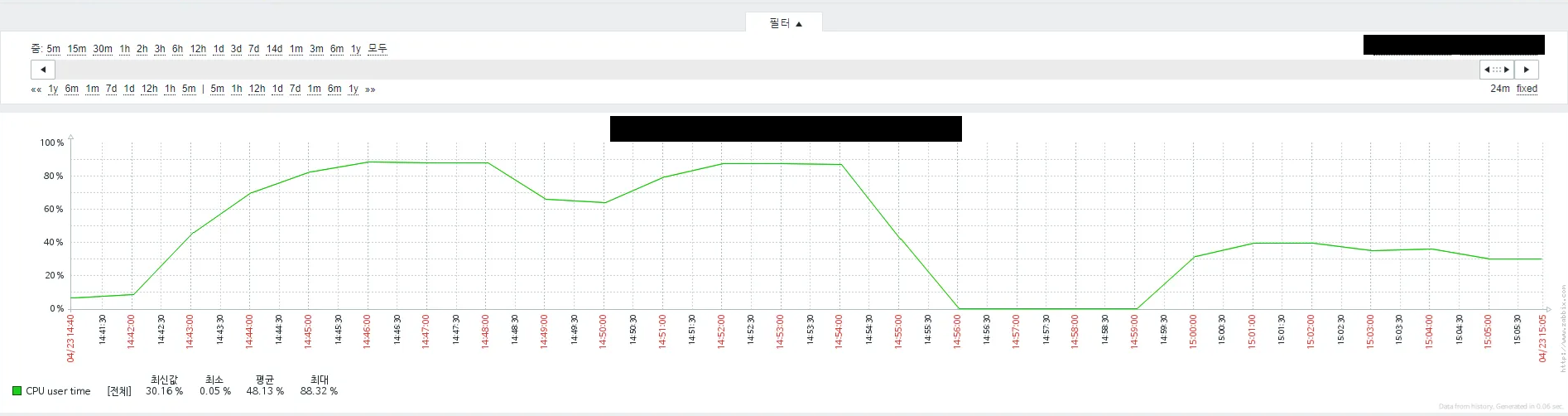
Zabbix 모니터링 그래프를 보니 초반부터 심상치 않은 조짐이 보이기 시작하는 거예요. 상담사 로그인 부분에서부터 부하가 발생하기 시작하더라고요.
"에이, 설마 다운로드랑 같이 돌려서 그런 거 아냐?"
저도 처음엔 그렇게 생각했죠. 근데 아니었습니다! 혹시나 해서 다운로드 요청을 빼고 로그인만 돌려봤는데도 여전히 부하가 발생하더라고요. 🤦♂️ (이때부터 등골이 오싹해지기 시작...)
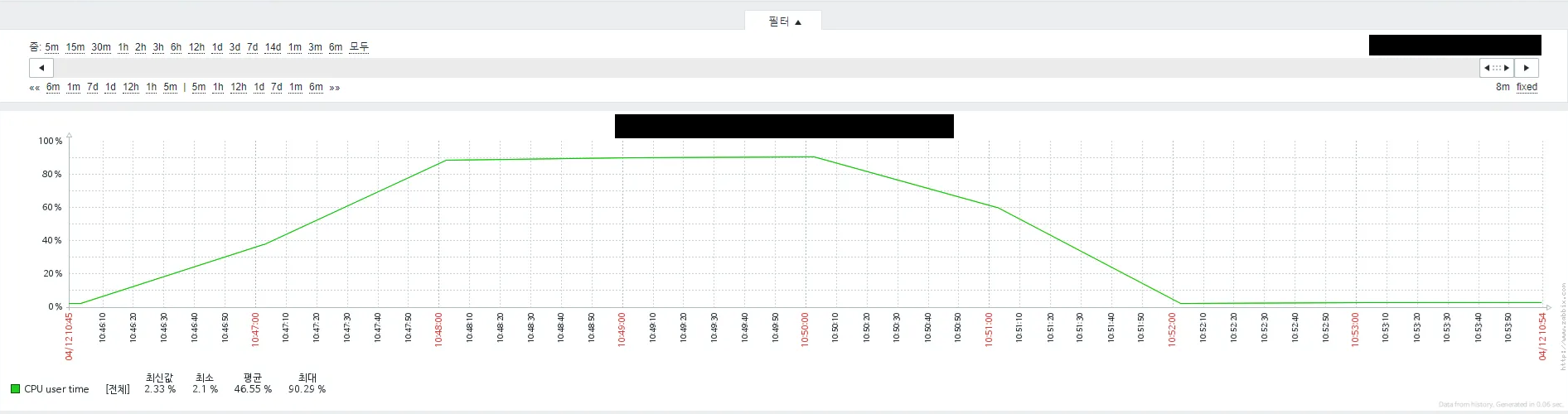
어디서부터 잘못된 걸까... 쿼리 로그를 뒤지기 시작했습니다.
너였구나, 범인이!
저희 솔루션에서는 time over 되는 로그를 남기고 있었기 때문에 오래걸리는 쿼리를 쉽게 분석할 수 있었습니다.
확인 해보니 상담사가 로그인할 때마다 부하가 발생했고, 그중에서도 상담사의 배분 상태를 로깅하는 부분이 가장 의심스러웠습니다. 쿼리 실행 시간이 유독 길었거든요.
문제의 테이블은 상담사 배분 상태 테이블이었어요. 상담사의 배분 상태를 기록하는 테이블인데, 구조는 다음과 같습니다.
log_id- PKlog_seqaccount_idservice_typework_statuscreated_bycreated_date
이 테이블에는 PK인 log_id만 인덱스가 걸려있었습니다.
문제의 쿼리는 바로 이 녀석이었습니다.
SELECT COALESCE(MAX(log_seq),-1) + 1 FROM account_work_status WHERE account_id = #accountId:CHAR#상담사가 로그인할 때마다 실행되는 쿼리인데, 인덱싱되어 있지 않은 account_id를 WHERE 조건으로 사용해서 테이블 풀 스캔(Full Scan)이 발생하고 있었던 거죠. 상담사 수가 많아지고 로그 데이터가 쌓일수록 이 쿼리는 점점 더 느려질 수밖에 없는 구조였던 겁니다.
해결책은 간단했습니다. log_seq와 account_id를 묶어서 복합 인덱스를 추가해줬습니다.👌
튜닝 후 쿼리 실행 계획을 볼까요?
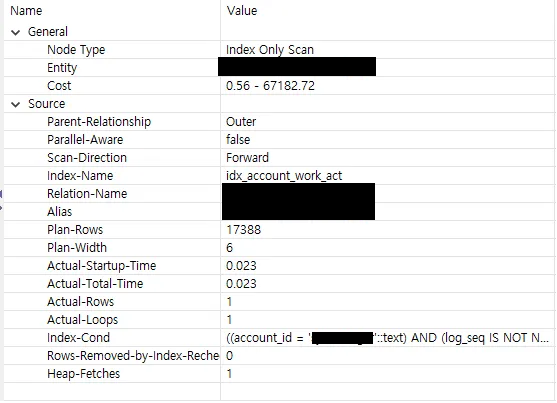
보이시나요? log_id만 바라보던 녀석이 이제 account_id를 통해 빠르게 데이터를 찾아낼 수 있게 되었습니다! 이 작은 변화가 로그인 시 발생하는 부하를 크게 줄여주었죠.
사용자 경험 기반의 성능 개선: "1년 치 상담 목록이 왜 필요해?"
로그인 시 발생하는 부하를 줄이는 또 다른 방법은 바로 사용자 경험 개선에 있었어요. 상담사가 로그인하면 첫 페이지에 상담 목록이 뜨는데, 이게 최근 1년 치 데이터를 한 번에 불러오고 있었던 거예요.
상담 목록은 10개씩 페이징 되어있으니, 솔직히 상담사가 로그인하자마자 1년 치 데이터를 전부 볼 필요가 있을까요? 없습니다!😵
그래서 과감하게 판단했습니다. 첫 페이지에 보여주는 상담 목록을 "최근 한 달"로 변경하는 거죠. 이렇게 하니 로그인 시 불러오는 데이터 양 자체가 확 줄어들면서 서버 부하도 자연스럽게 감소했습니다. 사용자 경험을 고려한 성능 개선이라고 할 수 있겠죠!
이번 시스템 성능 개선은 저에게 큰 교훈을 주었습니다. 막연히 예상했던 곳이 아닌, 의외의 지점에서 병목이 발생할 수 있다는 것, 그리고 단순한 인덱스 추가나 데이터 조회 범위 조정만으로도 큰 성능 개선 효과를 볼 수 있다는 것을 다시 한번 깨달았네요.
혹시 여러분들도 시스템이 느리다고 느껴지는데 어디서부터 손대야 할지 모르겠다면, 이번 제 삽질기가 조금이나마 도움이 되었으면 좋겠습니다!
