Elastic Search란?
검색 및 분석 특화 데이터 엔진이다. 방대한 양의 데이터에 대해 실시간으로 저장, 검색 등의 작업을 수행할 수 있게 해준다.
실제로 ES(이하 Elastic Search를 ES로 줄여 부르겠다)를 쓰기 전, 약 30만 개의 문자열 데이터에 특정 단어를 포함한 데이터를 불러오는 쿼리를 날렸을 때 결과를 받기까지 약 14초가 걸렸지만, ES를 도입한 이후 3.5초까지 줄어들었다.
ES와 관련된 몇 가지 특징을 살펴보자.
# inverted index
ES가 빠른 검색이 가능한 이유는 역색인때문이다. 우리는 이미 역색인을 알고있다. 정보 서적의 맨 뒷장을 펼쳐보면 서적에서 다루는 단어들의 목록을 볼 수 있다. 서적을 통해 어떤 단어에 대한 정보를 얻고자 할 때, 가장 뒤의 일람을 참고하여 해당 단어가 나오는 페이지로 가서 글을 읽는 것은 편하다.
ES는 이를 데이터에 그대로 적용한다. 일반적인 DB의 경우(index 없다고 가정), 특정 단어가 들어간 데이터를 검색하기 위해선 LIKE 쿼리를 통해 DB에 저장된 데이터의 전문 검색을 진행해야 한다. 데이터 수가 많고 각각의 데이터들의 길이가 길다면 꽤 느리고 부담가는 작업이 되겠지만,, row 단위로 데이터 원문이 저장되니 이거 말고 방법이 없다.
그러나 ES는 데이터를 저장할 때 inverted index, 즉 역색인을 진행한다. 일단 텍스트를 여러개의 키워드로 쪼개고, 쪼갠 키워드가 자기 자신이 등장한 데이터의 인덱스를 가리키도록 하는 것이다. 아래 사진을 보자.
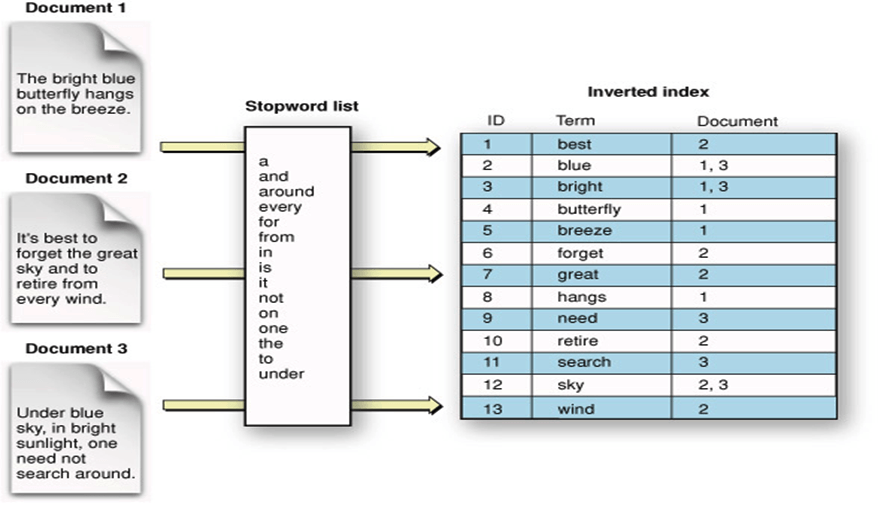 만약 위의 예시에서
만약 위의 예시에서 blue를 검색한다고 해보자. inverted index가 없었다면, LIKE "blue" 쿼리가 나갔을 것이고, 스레드는 Document 1~3을 돌며 blue 단어의 존재 여부를 찾을 것이다. 그러나 Document가 저장될 때 inverted indexing 과정이 일어난다면, 우리는 간단하게 오른쪽 테이블에서 blue 행을 살펴보고, Document 1,3에 해당 단어가 포함됐다는 정보를 얻으면 된다.
간단하게 역색인 과정을 살펴보겠다.
- 텍스트를 띄어쓰기 단위로 분리한다. 이렇게 텍스트를 특정 단위로 분리하는 작업을 토크나이징(tokenizing)이라고 하며, 분리된 단어들을 토큰(token)이라고 한다.
- 대문자가 있다면 모두 소문자로 변경한다. (The → the)
- 토큰을 ascii 순서로 정렬한다.
- a, an, the, to 와 같이 검색에 큰 의미 없는 불용어(stopword)를 제거한다.
- 형태소 분석 과정을 거쳐서 단어를 원형으로 변환한다. 주로 ~s, ~ing 를 동사 원형으로 변경하는 작업이라고 한다. 단, 한글은 언어 특성상 이 과정이 까다롭다. 엘라스틱 서치는 nori 라는 한글 형태소 분석기를 사용한다고 한다.
- 중복된 토큰을 병합하고, 동의어를 처리한다.
단어 검색을 위해 형태소 자체를 처리하는 구문적 알고리즘을 사용한다. 따라서 삽입된 데이터가 검색 가능한 상태가 될 때 까지 약간의 대기 시간이 존재하게 된다. 때문에 ES는 데이터의 완전한 실시간 처리가 되지 않는다는 특징이 있다.
그리고 ES는 기본적으로 저장되는 데이터의 모든 필드를 인덱싱한다. 이 때, 필드 각각의 자료 타입에 맞는 자료구조를 사용한다. String의 경우 위에서 설명한 방식으로, 숫자 혹은 지리 관련 Field는 BKD 트리에 저장하는 등의 방식을 사용한다.
# sharding
ES는 정해준 노드들에 전체 데이터 군집을 샤딩, 즉 분산 저장한다. 각 노드들엔 검색 요청을 날렸을 때 데이터 목록을 검색할 워커들이 있다. 데이터가 여러 곳에 나눠 저장되면 샤드된 개수만큼 워커들이 활동할 수 있으므로 더 빠른 검색이 가능해진다.
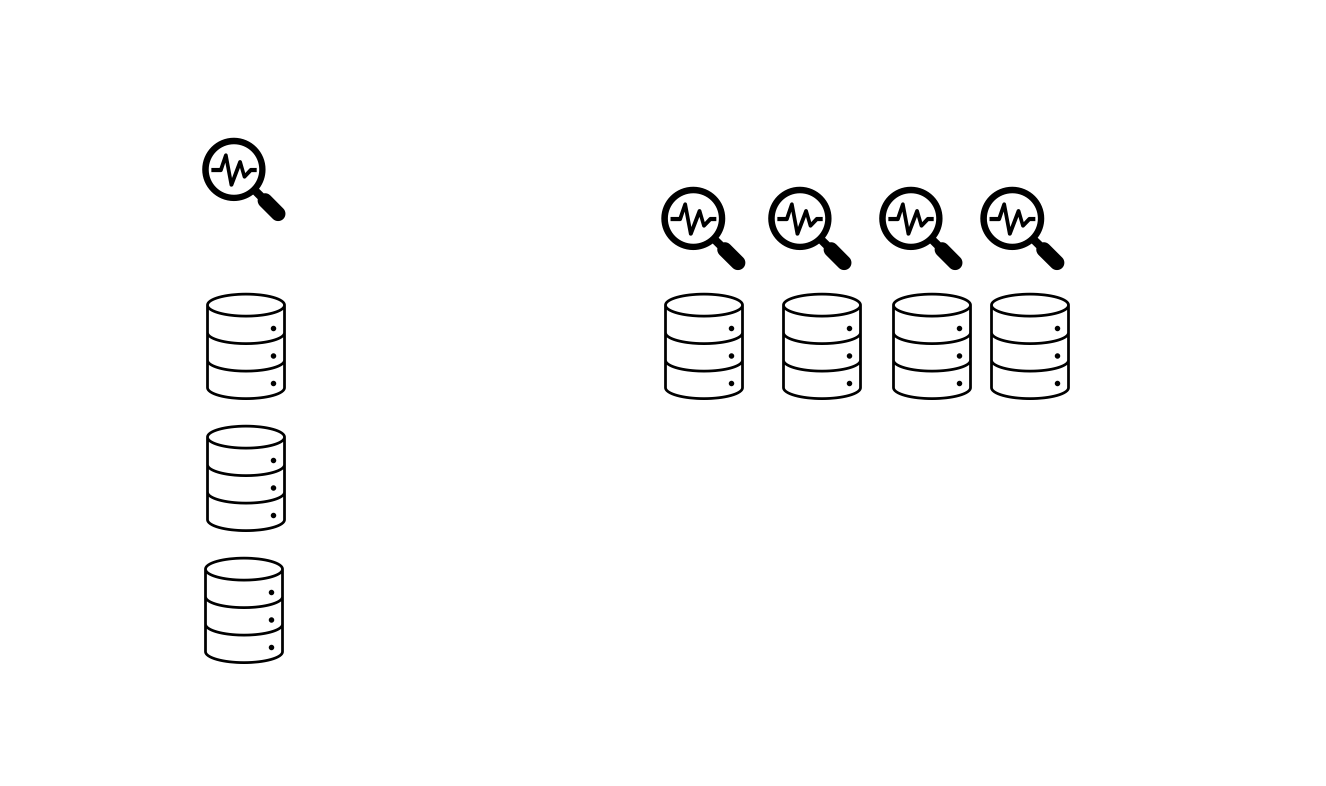 왼쪽은 샤드 없이 전체 데이터를 하나의 워커가 검색하는 상황이고, 오른쪽은 전체 데이터를 4개의 샤드로 나눠 4개의 워커가 데이터를 검색하는 상황이다. 뭐가 더 빠를지는 알겠지?
왼쪽은 샤드 없이 전체 데이터를 하나의 워커가 검색하는 상황이고, 오른쪽은 전체 데이터를 4개의 샤드로 나눠 4개의 워커가 데이터를 검색하는 상황이다. 뭐가 더 빠를지는 알겠지?
# replica
샤딩을 진행하면 더 빠른 검색이 가능하지만, 이 경우 분산 저장된 저장소들 중 하나가 죽으면 데이터가 유실될 수도 있고, 그동안 검색이 제대로 진행되지 않을 수도 있다. 이를 방지하기 위해 ES에서는 샤드된 데이터들을 복제하여 여러 노드에 중복 저장한다. 그러면 노드 하나가 죽거나 동작 불가 상태에 빠지더라도 나머지 노드들에 저장된 레플리카 데이터로 정상적인 동작과 데이터 보존이 가능해질 수 있다.
언제나 일반 DB보다 좋은 것은 X
앞서 말했듯, 역색인 과정은 시간이 좀 걸린다. 따라서 insert가 자주 일어나고, 그에 대한 빠른 처리가 가능해야하는 상황에서 ES는 좋은 선택이 아니다. 요컨데 데이터의 실시간 처리가 불가능하다는 한계점이 있다.
또한 샤드가 일어나는 특성상 ES는 트랜잭션을 지원하지 않는다. 그리고 ES에서 데이터 수정도 꽤나 까다로운 작업임을 짐작할 수 있다. 데이터가 수정되면 해당 데이터 전문에 대해 역색인 과정도 다시 일어나야한다.
결국, ES는 정말 "검색에 특화된 엔진"이라는 새로운 데이터가 저장되거나 데이터의 수정 및 삭제가 자주 일어나는 요소라면 ES 도입을 깊게 고민하는 것이 좋다. 반대로 말하면, 데이터 삽입 및 수정은 자주 일어나지 않으면서 빠른 검색이나 조회가 자주 필요한 데이터라면 ES가 적합한 솔루션이 될 수 있다.
1. ES 인스턴스 띄우기
GCP에 ES 인스턴스 4개를 띄웠다. OS는 지금까지 그래왔듯 Cent OS7을 사용했다. 노드는 4개로 구성할 것이다!

sudo yum install docker을 통해 docker 설치하고, sudo systemcall start docker을 통해 도커를 실행한다.
많은 데이터를 다루는 작업인만큼 ES는 가상 메모리를 많이 사용한다. 클라우드 서비스에서 기본으로 제공하는 것 이상의 용량이 필요하니 커맨드로 최대 vm 용량을 늘려주자.
$ sudo sysctl -w vm.max_map_count=262144이제 각 도커를 이용해 각 노드들에 ES 컨테이너를 구동시키고, 노드들을 연결시켜주는 작업이 필요하다. 일단 es-instance-1에는 아래 커맨드를 입력한다.
$ docker network create somenetwork
$ docker run -d --name elasticsearch --net somenetwork -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={1번 IP 빼고 나머지 3개 IP}" \
-e "node.name=es01" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={1번 IP}" \
elasticsearch:7.10.1- ES에 사용될 docker network,
somenetwork를 만들었다. - 9200포트는 HTTP 네트워크 통신을 위해, 9300은 ES 노드들간 통신을 위해 사용되는 포트이다.
{1번 IP}에는 es-instance-1 본인의 IP를,{1번 IP 빼고 나머지 3개 IP}에는 es-instance-2,3,4의 내부 IP를 ","로 구분해서 넣어주면 된다. 결국 es-instance-1의 SSH 커맨드 창에 입력될 커맨드는 아래와 같다.

es-instance-2,3,4에 아래 커맨드를 각각 입력한다.
$ docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={자기 IP 빼고 나머지 3개 IP}" \
-e "node.name=es02" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={자기 IP}" \
elasticsearch:7.10.11번과 비교하면 --net somenetwork가 빠졌다.
커맨드를 입력하면 docker 측에서 elasticsearch:7.10.1 이미지를 서버에 내려받고 컨테이너를 실행할 것이다. es-instance중 아무거나 골라서 해당 서버의 IP의 9200번 포트에 들어가보자. 그 전에 "Multi Elastic Head"라는 크롬 익스텐션을 다운받고 사용하는 것을 추천한다!
하여튼 ES 서버에 들어가면 아래와 같이 우리가 구성한 4개의 es 노드들을 확인할 수 있다.
 그 뒤, indices-new index를 클릭하고 새로운 데이터 저장소(ES에선 index라고 부른다)를 추가하자. 이름은 "post_8_1"로, shard는 8, replica는 1로 둔다.
그 뒤, indices-new index를 클릭하고 새로운 데이터 저장소(ES에선 index라고 부른다)를 추가하자. 이름은 "post_8_1"로, shard는 8, replica는 1로 둔다.
해당 과정을 끝내고 Overview 탭에 돌아오면 아래와 같이 post_8_1이 나타난다.
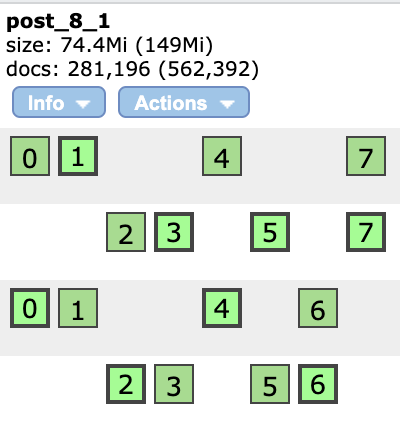
우리가 저장할 데이터가 8개의 샤드에 나눠져있고, 각 샤드는 1개씩의 레플리카(복사본)을 가지게 된다는 뜻이다. row 단위로 노드가 나뉘었는데, 하나의 노드가 죽어도 0~7번 샤드가 모두 동작할 수 있는 상태인 것이 보인다. 이것이 레플리카의 힘!
2. Spring 프로젝트 적용
기존 스프링부트 프로젝트의 pom.xml에 JPA 의존성을 삭제하고 ES 의존성을 추가한다. (spring start 이용)
그리고 엔티티인 Post, 레포지토리인 PostRepository를 다음과 같이 수정한다.
@Document(indexName = "post_8_1")
public class Post {
@Id
private String id;
private String content;
}
@Repository
public interface PostRepository extends ElasticsearchRepository<Post, String> {
List<Post> findByContent(String content);
}@Document: ES에서 사용되는 데이터임을 명시했다. 사용하는 index 이름은 "post_8_1"로, 아까 우리가 만들었던 index이다.- ID 타입으로 String이 사용된 것을 확인하자!
extends ElasticsearchRepository를 사용했다. 그리고 쿼리문 역시findByContentContains에서Contains부분이 잘렸다.
그리고 applicaion.yml파일의 jpa관련 설정을 싹 지우고 es로 채운다.
spring:
data:
elasticsearch:
hosts: 10.146.0.2,10.146.0.6,10.146.0.7,10.146.0.8
port: 9200hosts부분에 4개 노드의 내부 IP를 넣었다.
그 뒤 io bound application 프로젝트에 POST 요청을 오지게 날려서(artillery 이용) 약 30만 개의 데이터를 쌓았다. 위아래의 나머지 index들은 shard와 replica 없이 공부를 위해 구성한 인덱스들이다..
위아래의 나머지 index들은 shard와 replica 없이 공부를 위해 구성한 인덱스들이다..
search 요청을 날리기 전, ES에선 기본적으로 검색 결과를 10,000개 까지만 반환하도록 설정되어있다. http://{ES 노드 IP}:9200/post_8_1/_settings로 PUT 요청을 다음의 body와 함께 날리자.
{
"index": {
"max_result_window": 300000
}
}3. 결과 비교!
기존에 ES를 사용하지 않고 JPA만을 사용한 채로 30만건의 데이터에 search 요청을 날렸을 때의 결과다.
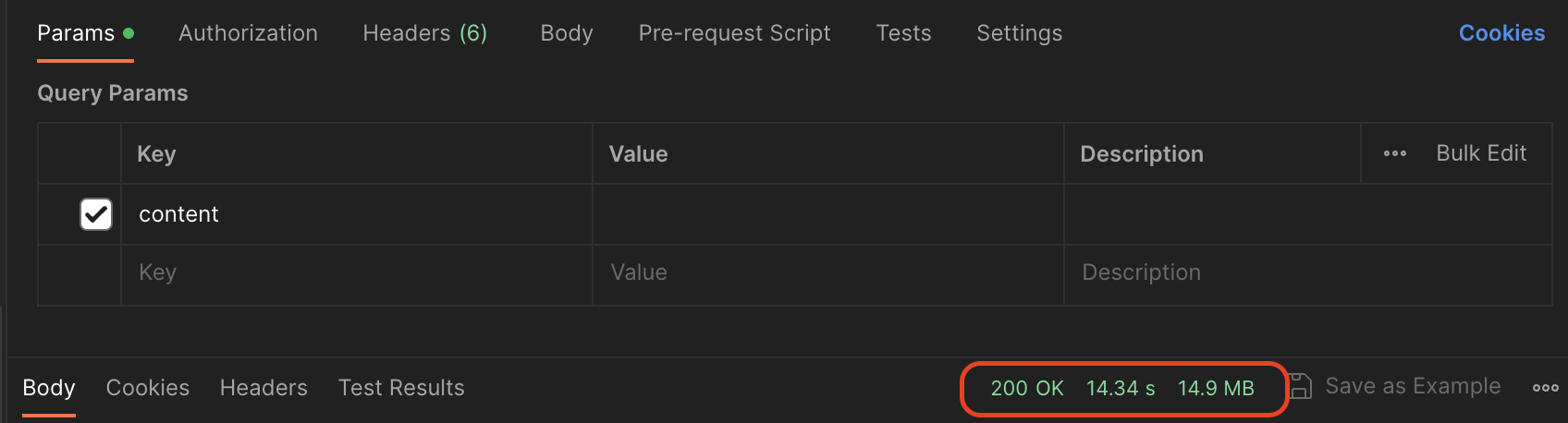 query parameter는 영화였는데 지금 왜 잘렸지; 하여간 14.3초 정도가 걸렸다. 이제 ES 서버에 같은 요청을 날려보자.
query parameter는 영화였는데 지금 왜 잘렸지; 하여간 14.3초 정도가 걸렸다. 이제 ES 서버에 같은 요청을 날려보자.
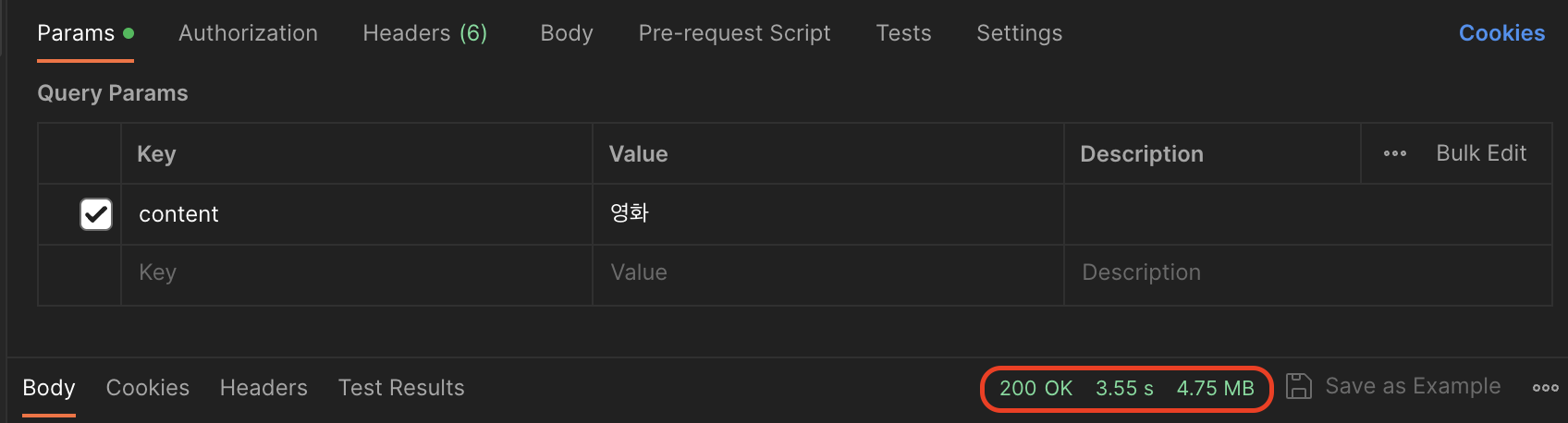 감동의 발전이다.
감동의 발전이다.
ES의 검색 성능은 적당한 개수의 노드와 자주 나오지 않는 단어에 대한 검색일 수록 강렬해진다.
- 샤드가 1개인 경우 DB보다 성능이 안나올 수도 있다.
- 해당 키워드로 검색되는 문서의 개수가 많은 경우 DB가 더 성능이 좋을 수 있다.
- 노드도 여러개, 샤드도 여러개인 경우 DB보다 검색 성능이 점점 좋아진다.
- 매칭되는 문서 개수가 적은 경우 ES가 좀 더 빠른 검색 성능을 보인다
그렇다고 해서 한정된 노드 안에서 무식하게 샤드를 늘려봤자, 같은 프로세스 안에서 스레드를 늘리는 꼴밖에 안난다. 한정된 리소스 안에서 여러 번의 테스트를 거쳐 최적의 결과를 뽑아낼 수 있는 지점을 찾는 것이 중요한 것 같다.
REFERENCE
https://hudi.blog/elasticsearch-inverted-index/
https://tecoble.techcourse.co.kr/post/2021-10-19-elasticsearch/

좋은 글 감사합니다!