TIL
- www.naver.com과 naver.com의 차이?
- 라우팅 프로토콜 (RIP, OSPF, BGP)
- Java의 Exception
1. A 레코드 / CNAME
DNS에 아래와 같은 도메인 이름 - IP 주소 매핑 테이블이 있다고 가정하자. (실제로 DNS가 이와 같이 구성되어 있는 것은 아니며, 이해를 돕기 위함임!)
| 도메인 이름 | IP 주소 |
|---|---|
| buchu.com | 91.123.32.1 |
| some.domain.kr | 121.99.112.0 |
| eat.meal.link | 201.1.33.81 |
1-1) A레코드 : 실제 도메인 이름과 IP 주소의 매칭
앞선 표의 내용이 A레코드라고 말할 수 있다. 실제로 도메인 이름을 들고 해당하는 IP주소를 매칭해주는 것은 A레코드의 정보를 바탕으로 이뤄진다.
A레코드는 도메인명과 IP의 연결쌍이다! 라고 단순히 생각하자.
1-2) CNAME : 도메인 주소의 별칭 지정
주소창에 www.naver.com을 치든, naver.com을 치든 같은 IP 주소로 이동한다. 그치만 mail.naver.com은 또 다른 IP주소에 해당된다. 이는 www.naver.com이 naver.com이라는 별명을 가지고 있기 때문이다(혹은 반대). 이것을 CNAME이라고 한다.
CNAME은 Canonical NAME의 약자로, 특정 도메인명을 또다른 도메인명으로 매핑시키는.. 도메인 이름에 대한 별칭이다. 도메인 이름의 도메인 이름? 그렇다고 해서 또다른 DNS 형식을 따르는 것은 아니고, 도메인명을 구매하고 등록할 때 A레코드와 함께 설정해주면 된다.
| 도메인 이름 | 별칭 / IP주소 |
|---|---|
| naver.com | www.naver.com |
| www.naver.com | 123.123.123.123 |
| mail.naver.com | 121.32.19.0 |
이해가 쉽도록, DNS 서버에 저장된 정보를 위와 같이 만들었다. naver.com에 매핑된 정보는 실제 IP주소가 아닌 naver.com의 별칭이다. naver.com의 질의로 DNS는 www.naver.com을 반환하고, 별칭에 대한 연쇄된 질의로 www.naver.com의 실제 IP 주소가 반환된다.
하위 도메인이나 상위 도메인에 대한 별칭을 이렇게 지정해줄 수 있다. naver.com이라는 도메인의 하위 도메인인 www.naver.com, mail.naver.com, blog.naver.com 등등은 모두 naver.com을 구매한 사람의 마음이다. A레코드와 CNAME을 이용해 각각의 도메인에 여러 호스트를 마음 내키는대로 매핑할 수 있다.
장단점
- A레코드
- 장점 : 질의 한 번으로 원하는 IP 주소를 응답받을 수 있으므로 빠르다
- 단점 : 만약 매핑된 호스트의 IP 주소가 바뀌면 매핑된 모든 A레코드의 수정 작업이 필요하다
- CNAME
- 장점 : IP 주소가 바뀌는 상황에, 연결된 CNAME의 IP 매핑 정보만 바꾸면 되므로 번거롭지 않다.
- 단점 : IP 주소를 얻기 위해 DNS 추가 질의가 필요하므로 느릴 수 있다.
CNAME이 필요한 상황에 적절하게 사용해야할 것 같다.
2.라우팅
IP 프로토콜을 통해 실제로 패킷이 출발지에서 목적지까지 가는 과정에 대해 알아보자. 이 과정 중 가장 중요한 것은 당연 라우터이다(포트포워딩과 NAT에서도 중요했는데.. 라우터 이자식)
출발지에서 시작한 패킷은 출발지 네트워크와 가장 가까운 라우터에 도착한다. 라우터는 패킷의 IP 주소를 확인하고, 해당 주소에 맞는 다음 라우터에게 패킷을 전달한다. 패킷을 전달받은 다음 라우터는 또다시 패킷의 IP 주소를 확인하고 해당 주소에 맞는 다음 라우터에게 패킷을 또다시! 전달한다. 패킷이 목적지 네트워크에 도착할 때까지 라우터 -> 라우터 -> 라우터 -> ... 의 과정을 반복한다.
이를 위해 라우터에는 라우터와 직접 연결된 다른 라우터들, 혹은 호스트들의 IP 주소를 가지고 있어야 한다. 그리고 [특정 IP주소 - 해당 IP 주소를 가진 패킷을 전달할 다음 라우터] 쌍을 가져야 하는데, 이를 "라우팅 테이블"이라고 한다. 그리고 당연히, 라우팅 테이블의 row 개수는 최소한 연결된 라우터 개수 이상이어야 한다. 라우팅 테이블에 패킷의 목적지 IP 주소가 없는 경우를 대비해 각 라우터에는 디폴트 라우터(0.0.0.0/0)가 존재해, 해당 패킷을 디폴트 라우터로 전달한다.
라우팅 테이블을 설정하는 방법에는 정적 라우팅과 동적 라우팅 두 가지가 있는데, 라우팅 테이블이 한 번 설정된 뒤 바뀌지 않는 정적 라우팅은 거의 쓰이지 않는다. 동적 라우팅은 실시간으로 네트워크의 상태를 파악하고 패킷에게 최적의 경로가 되는 방향으로 라우팅 테이블을 업데이트하여 전달한다. 이렇게 라우팅 테이블을 구성하기 위한 프로토콜엔 어떤 것들이 있을까?
1) RIP (Routing Information Protocol)
단순히 현재 패킷의 목적지까지의 거리를 살펴보고 가장 짧은 거리를 안내하는 방식이다. 이 때 사용되는 거리는 "홉"이라는 단위로, 목적지까지 경유하는 라우터의 수를 의미한다.
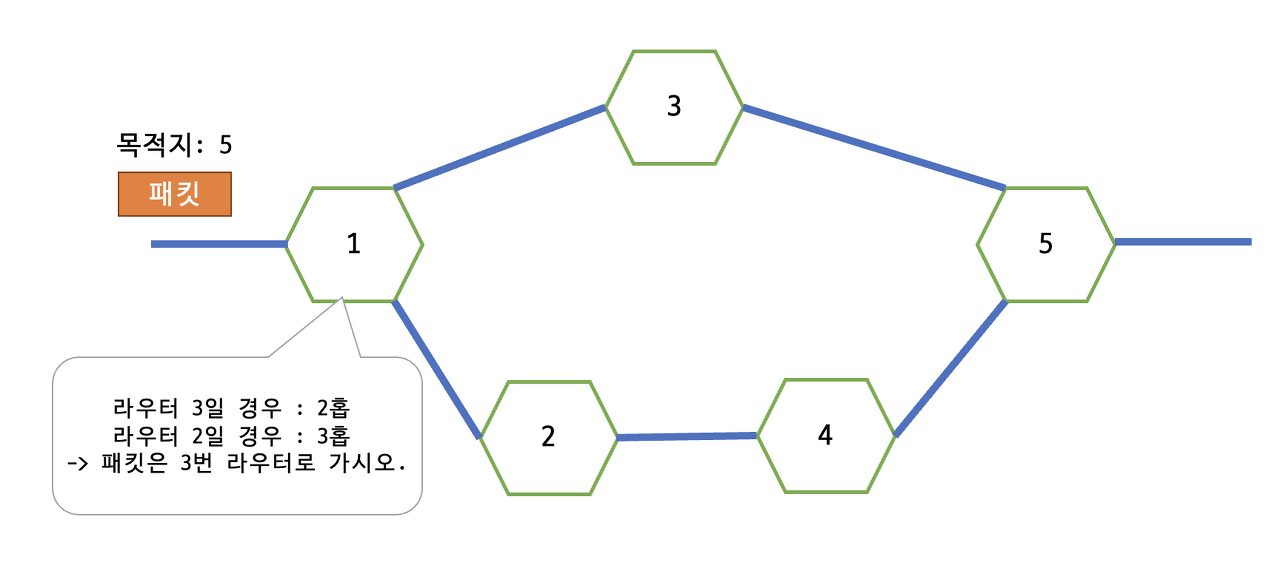
위 그림에서, 왼쪽 패킷의 목적지가 라우터 5번이라고 하면 5번으로 가기 위한 방법은 1->3->5, 1->2->4->5 두 가지가 있다. 첫 번째의 방법이 2홉으로 더 빠르므로 라우터는 패킷을 3번 라우터로 보낸다.
2) OSPF (Open Shortest Path First)
역시 목적지까지의 거리를 고려하여 최적의 경로를 안내하지만, 단순히 홉의 개수가 아니라 상태가 가장 좋은 경로를 선택한다.
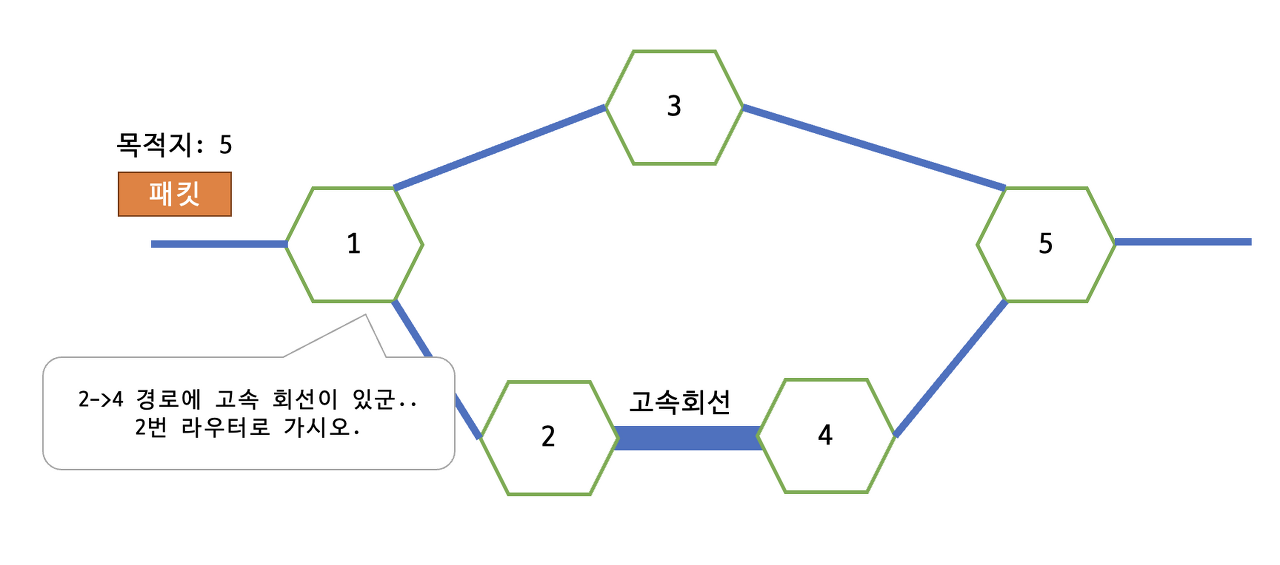
위의 그림은 기본적으로 RIP와 같은 상태이지만, 라우터 2->3의 경로가 고속회선으로 대체되어있다. 고속 회선을 이용할 경우, 3번 라우터를 선택하는 것에 비해 라우터를 한 번 더 거쳐야 하지만 고속 회선을 이용한 패킷 전송이 더 빠르므로 1번 라우터는 패킷을 2번 라우터로 보낸다.
라우터는 고속 회선을 포함해 네트워크 혼잡 등의 통신 상태 정보를 맵 형태로 관리한다. 이 정보를 이용해 실시간으로 패킷에게 최적의 경로를 안내하여, 복잡하고 변화가 잦은 네트워크 구성에 많이 이용된다.
4-3) BGP (Border Gateway Protocol)
논리 자체는 RIP와 비슷하다. 홉수를 고려해서 패킷에게 다음 라우터를 안내한다.
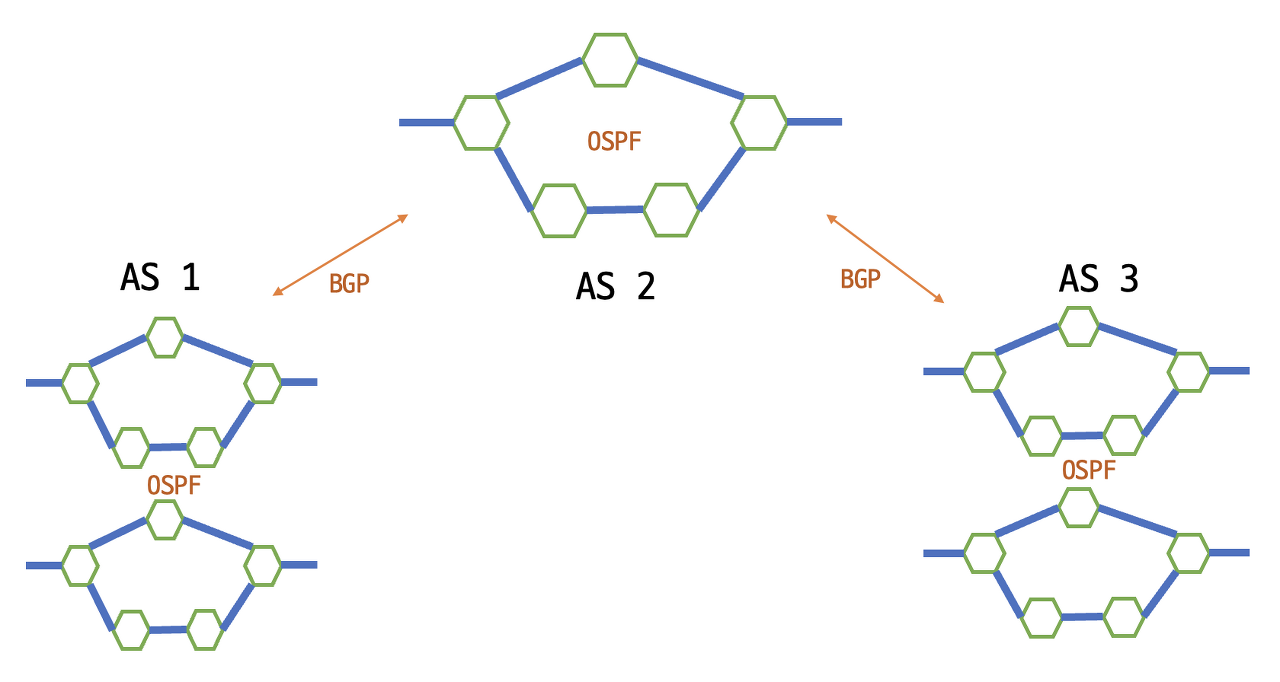
앞선 두 프로토콜(RIP, OSPF)은 하나의 라우터 무리 안에서(AS, Autonomous System) 패킷을 전달하기 위해 사용하는 프로토콜이다. 그러나 BGP는 다른 AS 사이에 패킷을 전달하기 위해 사용한다는 특징이 있다.
3. Exception
자바를 공부했다고 한다면 몰라선 안되는 Exception에 대해 훑어보겠다. 자바는 클래스에 미친 언어인 만큼(내 의견이며 오라클과는 관련X), 오류와 예외까지 클래스로 관리한다.
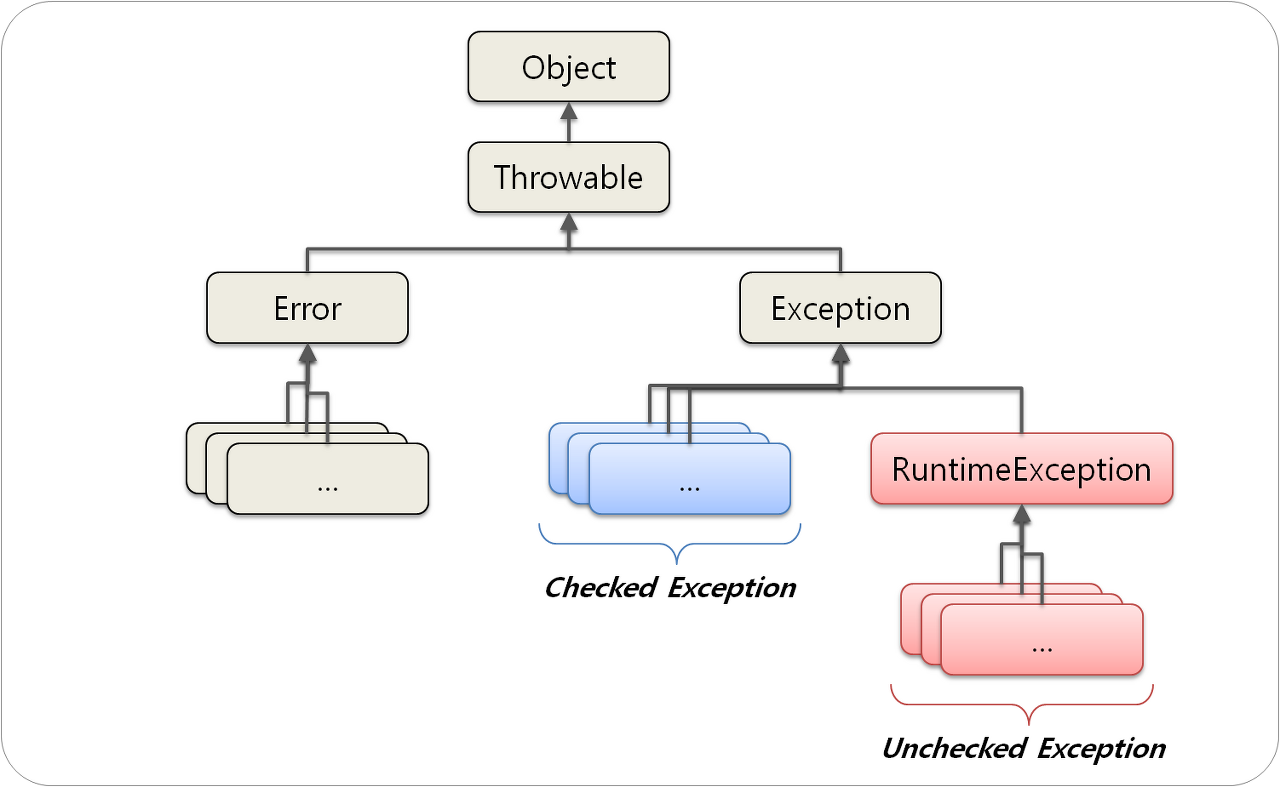
1. Error VS Exception
자바의 malfunction은 크게 두 가지, Error(오류)와 Exception(예외)로 나뉜다.
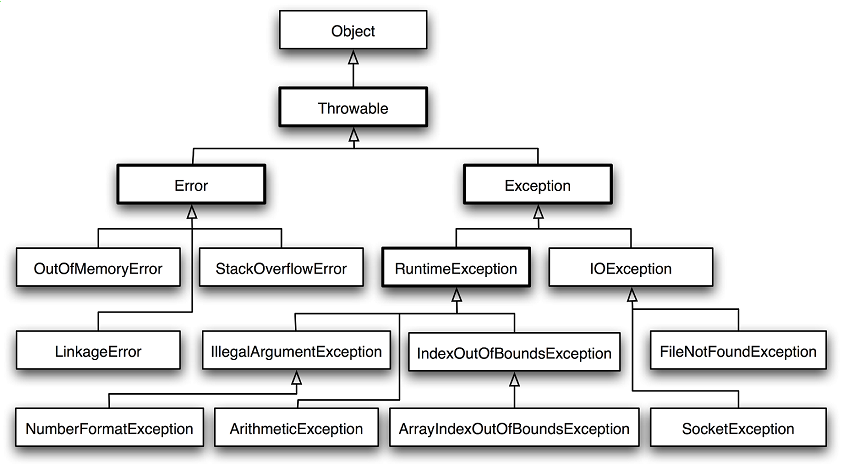
# Error : 프로그램 외적으로 발생하는 오류
OOM(Out Of Memory) 났는데 램 할당량 늘려야할듯요?
스택 오버플로 났는데 무한재귀 없나 확인해봐!
자바 프로그램 시작이 안되는데요.. 포트 문제인지 뭔지 감이 안잡혀.
앞선 내용들은 자바 프로그램이 아닌 하드웨어와 관련해서 문제가 생긴 예시들이다. (잘못 쓰여져 무한루프 도는 프로그램으로 인해 발생하는 경우도 있지만 어쨌든 하드웨어가 영향을 받아 에러를 일으킴) 자바에선 이런 문제들을 "Error"라고 칭한다. 이러한 에러와 관련해선 소프트웨어 개발자가 딱히 할 수 있는 일이 없다.
# Exception : 프로그램 내부에서 발생하는 예외
ArrayIndexOutOfBoundsException은 개발자로 인생을 살아간다면 한 번 쯤은 맞딱뜨렸을 예외일 것이다. NullPointerException은 최선의 주의를 기울여 대처해야하는 예외이고, 자바를 이용해 IO작업을 할 때 IOException을 처리하지 않았습니다! 하는 IDE의 경고문 역시 본 적이 있을 것이다.
이처럼 자바 소스코드와 관련해서, 프로그램 내부에서 발생하는 malfunction을 "예외(Exception)"라고 한다. 에러와는 다르게 예외는 개발자가 손 닿을 수 있는 범위라면 모두 고려하여 처리하는게 좋다. 예외를 가볍게 생각했다가 프로그램의 어떤 부분에서 대참사가 날지 모르기 때문이다.
2. Checked Exception , Unchecked Exception
CheckedException과 UncheckedException의 가장 큰 차이점은, 해당 예외를 처리하지 않았을 때 컴파일이 되냐 안되냐의 차이이다. 이는 각 예외의 용어적 뜻을 생각해보면 쉽게 유추할 수 있다. 사전에 체크되었기 때문에 Checked Exception, 사전에 체크되지 않았기 때문에 Unchecked Exception인 것이다. 컴파일 때 체크되는 Checked Exception은 그 자체로 Exception이지만, 컴파일때 체크되지 않고 JVM의 동작 과정중에 일어나는 예외는 JVM의 런타임에 발생하므로 Runtime Exception이라고 한다.
실제로 자바의 예외들은 모두 Exception 클래스를 상속받는데, 그 중에서도 RuntimeException 클래스를 상속받은 예외들을 Unchecked Exception이라고 부른다.(글의 첫머리와 비슷한 그림)
정말 checked exception은 먼저 체크되어야 할까? checked exception 상황을 만들어서 확인해보자. 존재하지 않는 파일을 읽는 fileReader 객체를 만들어봤다.
public class CheckedException {
public static void main(String[] args) {
FileReader fileReader = new FileReader(new File("존재하지않는파일.txt"));
}
}위 코드를 javac로 컴파일 하려고 하면, 컴파일 에러가 난다.
error: unreported exception FileNotFoundException; must be caught or declared to be thrown
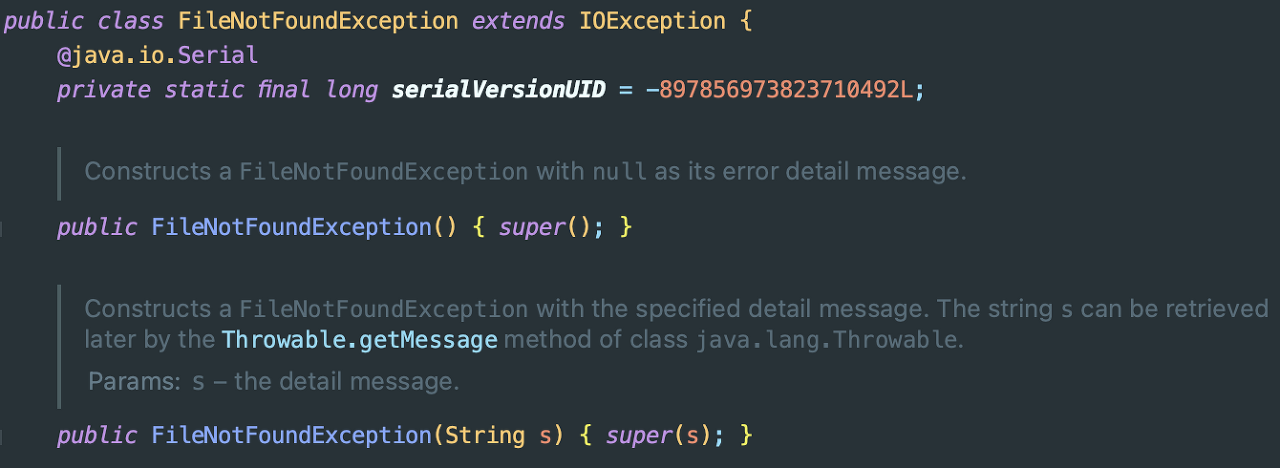
FileReader fileReader = new FileReader(new File("buchu.txt"));"FileNotFoundException"이 처리되지 않았다는 뜻이다. FileNotFoundException은 IOException을 상속받은 클래스이고, IOException은 대표적인 checked exception이다.
이렇듯 checked exception은 컴파일 전에 예외 처리를 해줘야 한다.
그럼 대표적인 unchecked exception인 NPE를 발생시켜보자.
public class UncheckedException {
public static void main(String[] args) {
String myString = null;
System.out.println(myString.length());
}
}이렇게 뻔하게 예외가 발생할게 보이는 코드인데도 컴파일이 잘 된다! 그리고 run하면?
java.lang.NullPointerException: Cannot invoke "String.length()" because "myString" is null역시 NullPointerException이 발생했다.
그렇다면 왜? Checked Exception과 Unchecked Exception을 굳이 이런 식으로 나눠놓은 것일까? 그것은 효율성을 위해서이다.
말했듯, 예상 가능한 예외는 처리할 수 있을만큼 사전에 처리하는 것이 베스트이다. 그러나 참조 타입의 포인터, 배열의 인덱스, 숫자간 계산 등 프로그램에서 빈번히 일어나는 작업 모두에 예외 처리를 강제한다면 프로그램은 프로그램 자체 코드보다 예외 처리 코드가 훨씬 길어질 것이다. 때문에 예외 처리가 critical한 상황이 아니라면 대부분의 예외들을 RuntimeException으로 빼서 개발자가 편한 방식대로 예외를 처리할 수 있도록 한 것이다.
3. try-catch로 예외 핸들링
예외를 핸들링하는 것은 기본적으로 try-catch 블록으로 할 수 있다. try 안에 예외가 발생할 가능성이 있는 로직의 코드를 넣어두고, catch 조건문 안에 처리할 예외 클래스를 집어넣어 해당 예외 클래스가 발생했을 때 실행할 코드를 작성하는 방식이다.
앞선 CheckedException의 코드를 다음과 같이 try-catch 블락으로 묶을 수 있다.
public class CheckedException {
public static void main(String[] args) {
try {
FileReader fileReader = new FileReader(new File("존재하지않는파일.txt"));
} catch (IOException e) {
// IOException 발생됐을 때 실행될 블록
e.printStackTrace();
}
}
}printStackTrace() 메소드를 호출해 발생한 예외와 관련 정보들을 콘솔창에 쫙 출력하도록 했다. 실행해보면 아까완 다르게 컴파일이 잘 된다! 그리고 결과는.
java.io.FileNotFoundException: 존재하지않는파일.txt (No such file or directory)
at java.base/java.io.FileInputStream.open0(Native Method)
at java.base/java.io.FileInputStream.open(FileInputStream.java:216)
at java.base/java.io.FileInputStream.<init>(FileInputStream.java:157)
at java.base/java.io.FileReader.<init>(FileReader.java:75)
at org.example.exception.basic.CheckedException.main(CheckedException.java:11)"존재하지않는파일.txt"는 존재하지 않는다고 잘 말해주고 있다!
if-else if처럼, catch 블록을 연달아서 쓸 수 있다. 위쪽의 catch엔 조금 더 특수한 예외로, 밑으로 갈수록 일반적인 예외로 구성한다. 그리고 가장 마지막에 finally 블록을 추가할 수 있는데, 이는 catch블록의 실행 여부와 상관없이 무조건 실행되는 코드가 작성되는 블락이다. try-with-resource가 없었을 시절 열린 파일이나 소켓 객체를 닫는 용도로 사용했다.
public class CheckedException {
public static void main(String[] args) {
try {
FileReader fileReader = new FileReader(new File("존재하지않는파일.txt"));
} catch (IOException e) {
// IOException 발생됐을 때 실행될 블록
e.printStackTrace();
} catch (Exception e) {
// IOException 외, 일반적인 예외가 발생했을 때 실행될 블록
e.printStackTrace();
} finally {
// 무조건 실행될 블록
System.out.println("finally executed");
}
}
}이제 조금 재밌는 실험을 해보자. Checked 클래스와 Unchecked 클래스를 만들건데, Checked 클래스는 Exception 클래스를 상속받고 Unchecked 클래스는 RuntimeException 클래스를 상속받도록 했다.
public class Checked extends Exception {
public Checked(String message) {
super(message);
}
}
public class Unchecked extends RuntimeException {
public Unchecked(String message) {
super(message);
}
}상속 구조는 아래 그림과 같다.
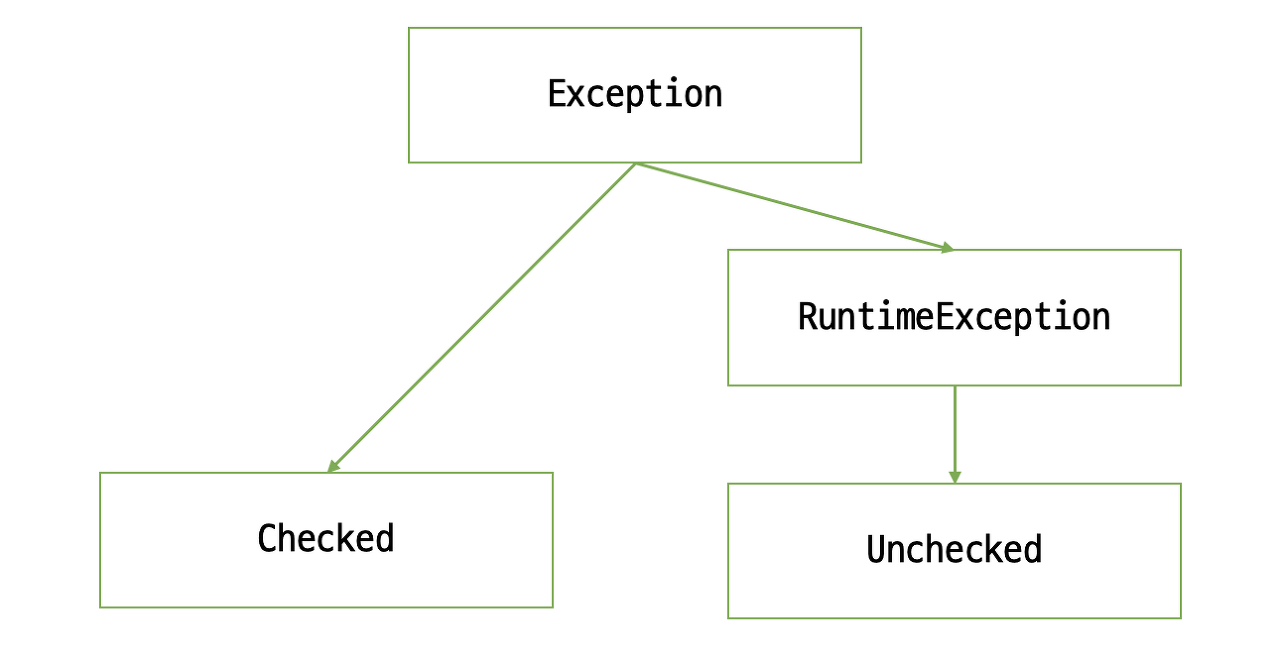
글의 초반에 나왔던 상속 지도가 맞다면 클래스 이름대로 Checked는 checked excepton, unchecked는 unchecked exception이 될 것이다. 정말 각각의 예외를 throw 했을 때 컴파일 성공의 차이가 있을까?
자바에서 예외를 던지기 위해선 throw 키워드 뒤에 예외 객체를 넘기면 된다.
public class ThrowingExceptions {
public static void main(String[] args) {
// 됨
throw new Unchecked("unchecked exception");
// 안됨
throw new Checked("checked exception");
}
}Unchecked만이 던져질 땐 컴파일이 되었지만, Checked가 추가된 순간 컴파일 에러를 뱉는다. 이제 각 예외를 try-catch 블락으로 묶어 처리해보겠다.
public class ThrowingExceptions {
public static void main(String[] args) {
try {
throw new Unchecked("unchecked exception");
} catch (Unchecked unchecked) {
unchecked.printStackTrace();
}
try {
throw new Checked("checked exception");
} catch (Checked checked) {
checked.printStackTrace();
}
}
}이제 컴파일도 되고 실행도 된다.
org.example.exception.throwing.Unchecked: unchecked exception
at org.example.exception.throwing.ThrowingExceptions.main(ThrowingExceptions.java:7)
org.example.exception.throwing.Checked: checked exception
at org.example.exception.throwing.ThrowingExceptions.main(ThrowingExceptions.java:14)실제로 RuntimeException을 상속받았는지, Exception을 상속받았는지에 따라 컴파일이 되는지 여부까지 살펴봤다!
REFERENCE
https://dev.plusblog.co.kr/30
https://joonius.tistory.com/19
https://devlog-wjdrbs96.tistory.com/351
