TIL
- Base64 인코딩
- 멘토링 회고(객체지향의 4대 특성)
- HTTP 요청/응답 메세지에 대해
1. Base64 인코딩
알아보고 정리는 안한 것 같아 급히 하는 내용 정리!
파일 형식의 통일, 처리 속도 향상, 보안, 공간 절약 등을 이유로 원래 데이터를 다른 정보 형식으로 바꾸는 과정을 "인코딩" 이라고 한다. Base64 인코딩은 원본데이터의 인코딩 결과를 Base64의 Text로 바꿔주는 인코딩 방식이다.
Base64는 64가 2의 제곱수라는 점, 화면에 표시되는 ASCII코드의 charset을 전부 포함하고 있다는 점 때문에 현재 www 리소스의 인코딩 방식으로 널리 사용되고 있다.
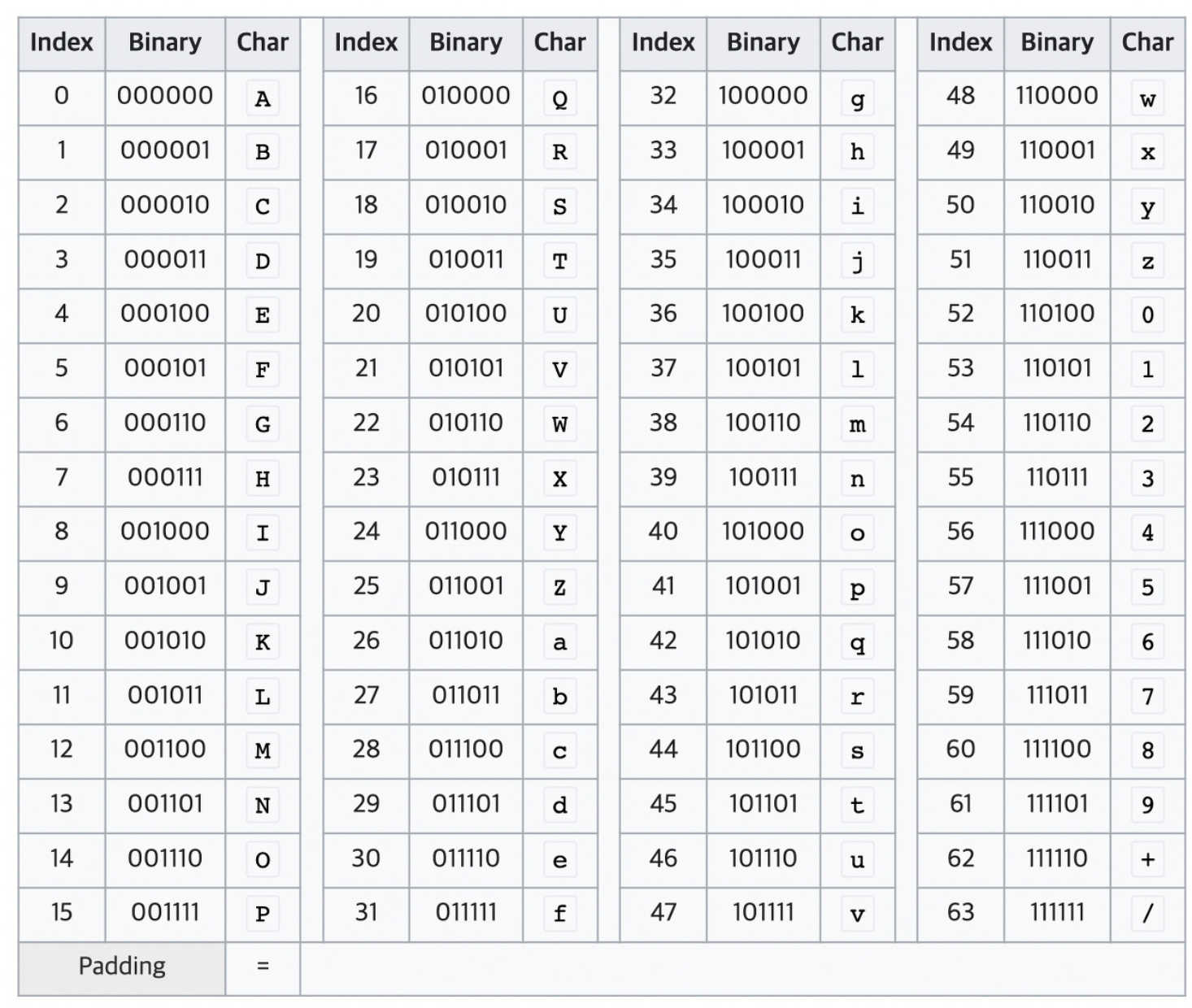 참고용으로, Base64에서 사용하는 charset은 위와 같다.
참고용으로, Base64에서 사용하는 charset은 위와 같다.
# encoding 과정
문자열 -> ASCII binary -> 6 bit 자르기 -> 인코딩
순서로 인코딩이 일어난다.
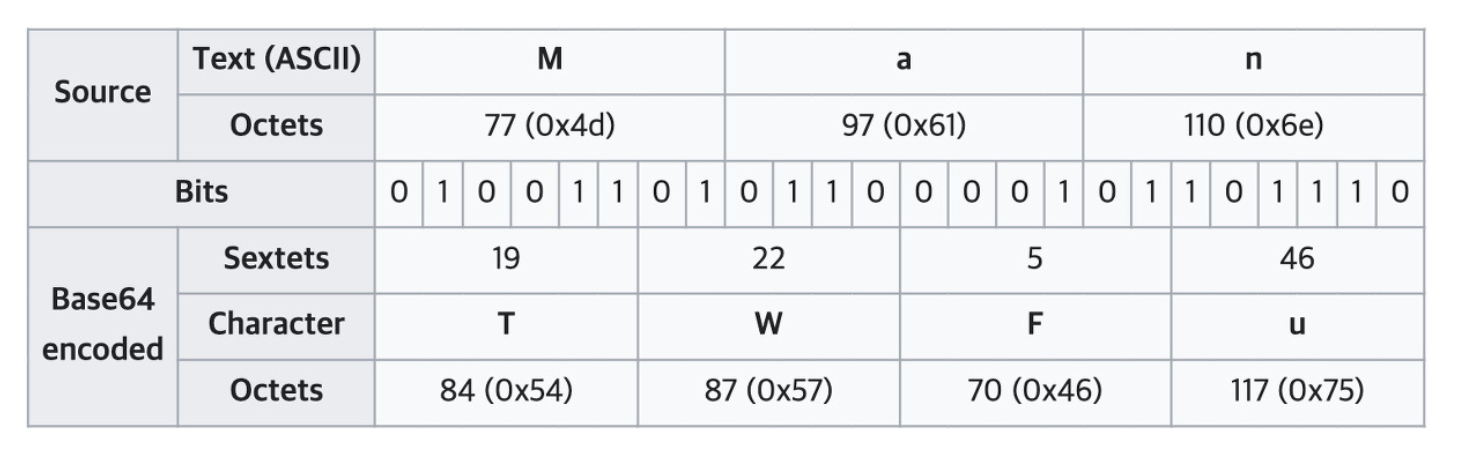
- ASCII binary로
M은 77,a는 97,n은 110이다. 이를 비트 단위로 나열하면010011010110000101101110이 된다. - 1번 결과를 6bit씩 끊는다.
010011,010110,000101,101110으로 나눠진다. - 각각을 base64 char에 매핑한다.
T,W,F,u가 된다.
보면 알다시피 ASCII -> Base64 인코딩을 위해 원본을 3글자씩 끊는 것을 알 수 있다. 인코딩 결과는 4글자다.
만약 원본 ASCII 데이터의 마지막부분이 3글자로 끊어지지 않고 1글자 혹은 2글자가 남는다면 옥텟 단위론 0을 채워넣고 인코딩 텍스트엔 =를 넣는다. 그럼 디코딩하는 쪽에서 = 패딩을 확인한 뒤 적절하게 8bit 데이터를 끊어 ASCII 문자열을 읽을 것이다.
# why base64?
Man -> TWFu가 되었다. Base64 인코딩을 사용하면 char 기준으로 3글자였던 데이터가 4글자가 된다. 33%의 데이터 추가가 일어나는 것이다. 왜.. 이런 인코딩 방식을 택했을까?
-
1비트의 문제 : ASCII에서 사용하는 심볼은 총 128개로 7bit의 범위를 가진다. 데이터 인코딩은 옥텟(8bit) 단위로 이뤄지는데, 하드웨어나 시스템마다 가장 앞의 1비트를 처리하는 방식이 다르다.
-
일부 항목 상이 : ASCII 코드의 일부 항목(ex.LF) 시스템별로 달리 설정되어있다고 한다. 따라서 문자 코드에 영향을 받지 않는 ASCII 부분만 따로 떼와 인코딩에 사용하는 Base64가 선호되었다.
네트워크를 통한 데이터 교환은 결국 서로가 합의하는 "프로토콜"을 맞추는 것이 중요하다. 비트를 처리하는 방식이나 데이터 처리의 일관성이 보장되지 않는 ASCII 인코딩 방식을 사용하면 깔끔한 데이터 교환이 불가능해질 수 있다.
2. 3주차 멘토링 회고
왜 이걸 진작에 안했는지... 이번주에 했던 멘토링 내용에 대해 간략히 생각하고 고민해보는 시간을 가져보겠다. 일단 앞의 패키지 구조에 관한건.. 오늘이나 내일 단축URL 구조 수정할 때 다시 보기로 하고!
# 객체 지향의 4대 특성
새로운 개념을 배우거나 기술을 도입할 때 왜 그것이 사용되는지, 그리고 사용하면 어떤 이점이 있는지 항상 생각하는 습관이 중요한 것 같다. 이번주는 일명 캡상추다, 라는 객체지향의 4대 특성에 대한 내용을 멘토링 시간에 학습했다.
프로그래밍 패러다임, 디자인 패턴 같은 방법론은 모두 실무에서 "어떻게 하면 더 효율적으로 문제를 해결할 수 있을까" "어떻게 하면 조금 덜 고생하고 요구사항에 맞게 코드를 수정할 수 있을까" "유지보수에 유리하게 프로젝트를 구성하는 방법엔 뭐가 있을까" 등의 고민에서 나온 것들이다. 그 해답을 이리저리 찾다보니 객체 지향이 괜찮은 것 같다는 아이디어가 나왔고, 그렇게 나온 설계적 방법론을 지금 배우고 있는 것이다.
왜 객체지향을 사용하죠? 캡슐화, 상속, 추상화, 다형성이 유지 및 보수에 어떤 이점이 있죠?
그렇기 때문에 객체 지향의 4대 특성을 배웠다면 위 질문에 대답을 잘 할 수 있어야 한다. 나는 못했다. 멘토님과 얘기하며 배우고, 내 나름대로 머릿속에 정리한 내용을 적어보겠다!
1) 캡슐화 : get() set() XXXXXX
초초초간단 지갑 클래스 한 개가 있다.
@Getter
@Setter
public class Wallet {
private int money;
}항상 궁금했다. value를 private로 선언해도 위와 같이 getter setter가 있으면 상관없는거 아닌가? 객체.필드으로 접근하냐, 객체.get필드() 혹은 객체.set필드()로 접근하냐의 차이가 아닌가? 필드값 보안이 어쩌고 하면서 캡슐화랍시고 private 접근 제어자를 사용하는 것의 의미가 없는거 아닌가!?!??!
맞.다. 의미 없다.
객체지향 캡슐화의 관점에서 getter setter가 있는 것은 좋지 않다. 왜 좋지 않느냐고 묻는다면, getter와 setter은 클래스 내부의 필드값을 외부에 더 드러냄으로써 코드의 결합도를 높인다.
더 자세하게 설명을 시도해보겠다... 유지보수가 좋은 코드는 변화의 전파를 최소화 해야한다. getter와 setter을 통해 직접 값을 참조하는 클래스나 모듈이 프로젝트 여기저기에 흩어져 있다면, 필드값의 수정/삭제가 일어나거나 뜻이 바뀌었을 때 흩어진 모든 곳들을 살펴봐야한다. 이같이 특정 필드가 이곳에서도 참조되고, 저곳에서도 참조되는 식으로 여기저기 결합되어 있는 상황을 "결합도가 높다"고 말한다. 때문에 결합도가 높은 코드는 좋지 않다.
캡슐화가 잘 된 클래스는 getter와 setter가 없고, 있어도 최소한의 곳에서만 사용되며, 필드값과 관련된 로직은 클래스 내부에서 대부분 처리된다. 객체 내부의 필드 값, 그리고 관련 로직은 되도록이면 클래스 내부에서 모두 처리하고 외부로 return하는 것은 최소화하는 것이 좋다.
캡슐화가 깨진 코드는 프로젝트 여기저기서 재사용된다.
커머스에서 상품을 나타내는 클래스가 [상품 이름] 그리고 [가격] 이라는 필드와 getter setter만 갖고있다면 해당 필드는 상품보기 주문 배송 할인적용 등등 프로젝트 모든 곳에서 쓰일테고 만약 필드의 추가/삭제나 수정이 이뤄진다면.. (이하생략)
getter setter을 쓰는 대신, 객체 내부에서 알아보기 쉬운 메소드 명을 사용해 도메인 로직을 처리하는 것이 좋다. 그 쪽이 코드 재사용률을 낮추고 가독성을 높일 수 있기 때문이다.
단적으로 정리하자면 getter와 setter을 최대한 없애고, 엔티티 내부 필드값을 사용하는 로직은 엔티티 코드 내에서 처리하자. 객체에 할 일을 객체에 맡겨 책임을 분산시켜 결합도가 낮고 가독성 좋은 코드를 만들자. 지금까지 @Entity 클래스를 그냥 DTO처럼 사용하고 필요한건 게터세터 남발했는데, 이것은 캡슐화에 대한 모독이었던 것이다. 꾸짖을 갈!!!!!!!
2) 상속과 다형성
상속을 사용하는 이유는 일반적으로 재사용과 확장이라고 말들 하지만, 더 확실하게 말하면 다형성을 이용하기 위해서다. (단순히 클래스의 코드를 이용하기 위해선 구성이 선호된다)
상속 관계가 연쇄적으로 일어날 때, 그러니까 A -> B -> C 같이 "조상"으로 불려도 될만한 클래스가 있을 때 주의해야 한다. A가 변하면 그를 상속하고 있는 하위 클래스들인 B, C... 들이 모두 영향을 받아버린다. 캡슐화에 대해 설명할 때 변화의 전파를 최소화해야한다, 언급했는데 이같은 동작은 변화의 영향이 하위클래스 전체에 쫙 퍼져버리니 객체 지향적이라고 말하기 힘들어진다.
당연한 얘기지만, LSP를 어긴 경우에 상속하면 안된다. 하위 타입에 상위 타입이 할 수 없는 일을 추가하거나, 상위타입이 할 수 있는 일을 하위타입이 할 수 없는 경우 다형성이 깨지기 때문이다. 상속을 이용할 때, 클라이언트 코드는 구상 클래스 타입을 신경쓰지 않고 해당 클래스 기능을 이용할 수 있어야 한다. 상위 참조타입으로 메소드를 호출해도 실제 생성된 객체의 @Overriding된 메소드가 호출된다-까지를 다형성의 개념으로 알았지만, 진정한 다형성은 현재 호출되고 있는 메소드가 어떤 구상 클래스의 메소드인지 상관없이 잘 동작하는 것이라고 할 수 있다. 이를 단적으로 알아볼 수 있는 것이 instanceof 키워드이다.
아래는 LSP와 다형성을 망가뜨리는 코드다.
for (Person person : people) {
if (person instanceof Man) {
person = (Man) person;
// Man 타입만 가능한 로직
} else {
person = (Woman) person;
// Woman 타입만 가능한 로직
}
}Person 타입으로 사용하고 있는데, 구상 클래스에 따라 if문으로 로직이 분기된다. 망한 다형성의 전형적인 예시다.
하나의 코드가 여러가지 일을 할 수 있는 특성을 이용해 코드를 간단하게 만드는 것이 다형성이고 이것을 구현하기 위한 방법이 상속 혹은 인터페이스인데, 위와 같이 클라이언트 코드가 타입을 신경써야하면 상속의 의미를 잃는다. 보통 특정 자식 객체가 들어오면 예외를 던진다든가 하는 식으로 다형성을 많이들 깨뜨린다고 한다., 상속을 이용할때는 "자식은 부모다","자식은 부모의 한 종류이다"의 LSP를 항상 유념하고 사용해야겠다!
아 추가로 상속과 인터페이스 외에도 자바의 enum을 이용한 다형성 구현이 있는데, 이곳을 참조하자! (전날 블로그 글에도 같은 내용이 존재한다)
3) 추상화
이전 모각코 글에서 "추상화는 모델링이다" 언급한 적이 있지만, 멘토님 가로되 추상화는 그것보다 훨씬 넓은 개념이라고 한다.틀렸습니다!
Message Passing
추상적인 존재(모듈, 클래스 등을 전부 포함)에 기능을 요청하고 결과를 돌려받는 "메세지 패싱"을 통해 얻는 장점을 모두 포함한 것이 추상화라고 말할 수 있다. 훨씬 넓은 개념이었던 것이다;
너.. 너무 넓은 개념이라 아, 그렇구나. 하고 말았는데 나름대로 정리해보겠다고 떠올려봤다.
Random random = new Random(System.currentTimeMillis());
int randomNumber = random.nextInt(10);자바의 랜덤 모듈을 위와 같이 쓴다고 할 때, 우리는 Random 클래스 안에서 어떤 일이 일어나는지 모른다. 그저 제공하는 nextInt() 메소드를 통해 10까지의 랜덤 정수값을 받을 뿐이다. 캡슐화된 내부의 메소드 동작 과정은 추상화되어 모르는 상태이지만 이쪽에서 책임지지 않아도 되니 오히려 편하다. 코드가 더 깔끔해지고, 가독성도 높아진다.
메세지를 정확히 어떤 일을 하는지 모르는 추상적 존재에게 던져준 후 원하는 결과를 받는다. 이것이 추상화를 제공하는 객체지향의 특성이다. 물론 현실 세계의 객체를 모델링하는 것 역시 추상화에 포함된다! 추상화를 어떤 측면에서 바라보냐에 따라 달라질듯.
이렇게 쭉 놓고 보니 캡슐화든 상속/다형성이든 추상화든, 프로그램을 말그대로 '객체'로 보고 적절히 캡슐화시켜 책임을 분할해서 변화의 전파를 최소화하고 읽기 쉬운 코드를 만드는데 목적이 있는 것 같다. 이 목적에 따라 만들어진 방법론이 객체지향이니 어떻게 보면 당연한 얘기지만?
3. HTTP 메세지에 대하여
HTTP 통신을 위해 클라이언트와 서버는 메세지를 교환한다. 메세지 자체는 텍스트 데이터지만, 줄바꿈으로 데이터와 종류를 구분하며 요청/응답 메세지에 대한 규약이 있다.
1) 요청 메세지
<메소드> <URL> <HTTP 버전>
<헤더1>
<헤더2>
...
<본문>메소드
같은 URL이라도 클라이언트가 어떤 메소드로 요청하는지에 따라 다른 동작을 한다. 일반적으로 다음과 같은 메소드들이 존재한다.
- GET : 단순히 서버에 리소스를 요청
- HEAD : GET과 같은 요청이나, 응답 메세지에 본문을 빼고 "헤더"만 포함할 것을 요청
- PUT : 서버에 문서를 씀. 기존에 존재하는 문서일 경우 교체
- POST : 서버에 입력 데이터 전송
- TRACE : 종단 서버가 자신이 받은 요청 메세지를 본문에 담아 클라이언트 입장에서 네트워크 통신 경로를 확인할 수 있는 메소드
- DELETE : 요청 URL에 대한 자원 삭제 요청.
각 요청 메소드를 100% 서버가 구현해야할 의무는 없다.
위 메소드중 요청 메세지에 body(본문)가 있는 것은 PUT과 POST이다. 생각해보면 당연한게, 서버 리소스를 수정하거나 입력을 제출할 것이라면 내용이 있어야하지 않나. 보통 폼 제출을 하거나 말 그대로 글을 써서 서버에 올릴때 POST 요청을, 특정 리소스를 수정할 때 PUT 요청을 날린다.
GET과 HEAD 메소드의 경우, 서버의 리소스를 단순히 받아오며, 무언가 제출하거나 수정하는 것이 아니다. 사용자 요청에 대해 서버 리소스에 영향이 가지 않는 이같은 메소드를 '안전(safe)한 메소드'라고 부른다.
추가로, 여러번 보낸 동일 요청에 대해 서버의 영향이 동일한 메소드를 멱등성있는(Idempotent) 메소드라고 부르는데, 여기엔 GET, PUT, DELETE가 있다. 당연히 안전한 메소드는 같은 URL에 여러번 GET 요청을 보내도 서버엔 영향이 없다. 그냥 요청에 대해 같은 리소스를 계속 응답하면 끝이기 때문이다. 그러나 POST의 경우, 사용자가 같은 요청을 계속 보냈을 때 서버에 같은 데이터가 계속 쌓인다. 서버의 리소스에 지속적으로 변화가 일어난다. 그렇기 때문에 POST는 멱등하지 않다. PUT은 리소스를 대체, PATCH는 수정한다는 차이가 있는데 PATCH의 경우 append하는 경우까지 포함하기 때문에 PUT만 멱등하다. 전반적인 설명은 아래 표를 참고하자!
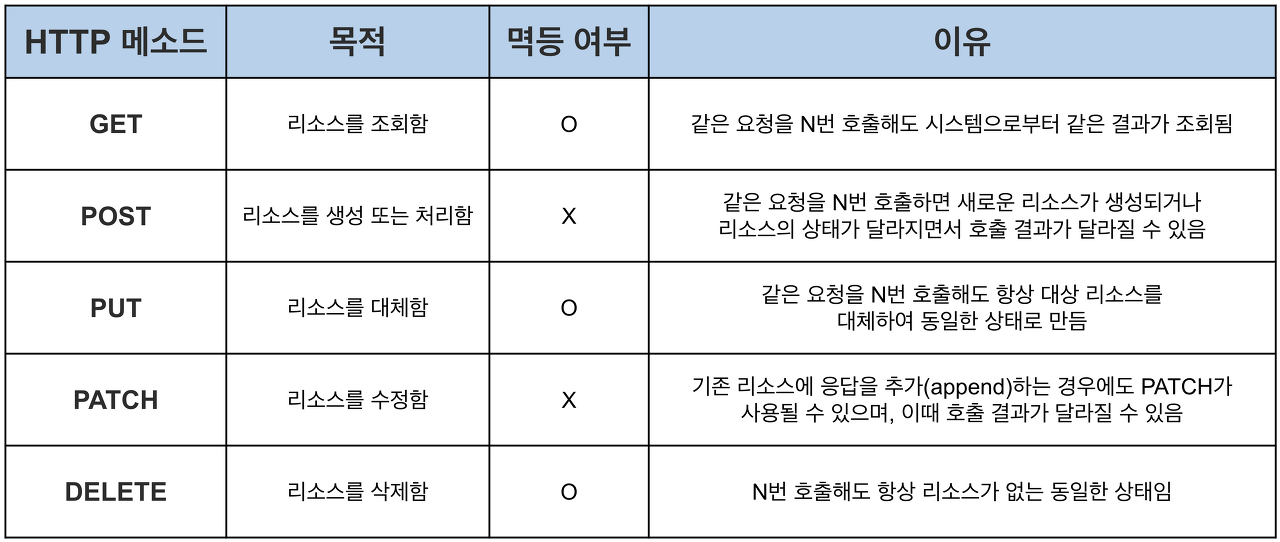 어? 왜 DELETE가 멱등하지?
어? 왜 DELETE가 멱등하지?
DELETE 요청을 보내 서버의 a리소스를 삭제했다고 해보자. 서버엔 a가 없는 상태다. 같은 요청을 한 번 더 보내보자. 서버엔 a가 없는 상태다. 한 번 더 같은 요청을 보내자. 서버엔 여전히 a가 없다. 여러번 DELETE 요청을 보내도 서버 리소스는 계속 같은 상태, 즉 a가 없는 상태이다. 그렇기 때문에 ! DELETE는 멱등하다.
요청 헤더
메세지에 대한 메타 정보를 담고있다. 콜론:쌍 개행 단위로 표시된다.
Date(현재 날짜)Content-type(body에 담고있는 MIME 타입)Host(현재 요청중인 서버의 IP)Referer(이전에 존재하던 문서 위치)Accept관련 항목들 : 어떤 타입의 charset,encoding, language 등을 선호하는지Cookie
등과 관련된 항목들이 존재한다.
2) 응답 메세지
<HTTP 버전> <상태 코드> <사유 구절>
<헤더1>
<헤더2>
...
<본문>상태코드
상태코드는 클라이언트에게 요청이 어떻게 처리되었는지 서버에서 알려주는 고지이다. 일반적으로 2xx는 성공을, 3xx는 리소스의 이사(?)를, 4xx는 클라 오류를, 5xx는 서버 오류를 나타낸다. 사유 구절은 상태코드에 대한 description같은 존재로, 오로지 사람에게 읽히기 위한 목적으로 만들어졌다.
- 200 Ok : 요청 성공
- 201 Created : 객체 생성 완료
- 300 Multiple Choice : 여러 리소스가 존재하는 URL에 대한 요청
- 301 Moved Permenantly : 리소스 옮겨짐. 헤더의
Location항목에 리다이렉트할 URL 제공 - 302 Found : 임시로 옮겨짐.
- 400 Bad Request : 서버가 처리할 수 없는 요청
- 401 Unauthorized : 로그인 필요. 정확히 말하면 "unauthenticated"
- 403 Forbidden : 권한 없는 요청. 정확히 말하면 "unauthorized"
- 404 Not Found : 존재하지 않는 리소스 요청
- 405 Method Not Allowed : 지원하지 않는 HTTP 메소드
- 500 Internal Server Error : 서버에서 핸들링 할 수 없는 에러가 발생했을 때 통상적으로 쓰이는 상태 코드
- 502 Bad gateway : 게이트웨이나 프록시로 작동하는 서버가 부모 게이트웨이로부터 적절한 응답을 받지 못했을 때 발생
응답 헤더
응답 데이터에 관한 부가, 메타 정보를 담고 있다. 요청 헤더에도 존재하는 Date, Content-type 항목을 포함해 대표적으로 다음과 같은 헤더 항목을 가지고 있다.
Server(서버 어플리케이션의 이름과 버전)Age(응답 객체를 내리는데까지 걸린 시간)
본문(body)
메세지 응답 본문에는 클라이언트가 요청하고 서버에 존재하는 리소스라면 무엇이든 올 수 있다. www에서는 주로 HTML, CSS, JS 파일이 들어있고 브라우저가 응답 본문 내용을 파싱해 렌더링하는 역할을 한다.
REFERENCE
HTTP 완벽 가이드 3장
https://mangkyu.tistory.com/251
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status#redirection_messages
