TIL
- Optional에 대하여
- 클라이언트에서 서버로 파라미터를 보내는 법
- 강의에서 건져간 SOLID의 예시와 안티패턴?
1. Optional
어떤 프로그래밍 상황에서든 null checking은 필수다. 존재하지 않는 변수의 메소드나 필드를 참조해서 발생하는 NPE는 깔짝깔짝 나타나 버그를 일으켜 개발자를 짜증나게 한다. 메소드 시작점에서 입구컷을 하거나, @NonNull같은 어노테이션을 사용하거나, null일 경우 아예 직접 인스턴스를 만드는 등의 여러 방법을 사용할 수 있다.
오늘은 그 중 하나인 Optional 클래스를 살펴보겠다!!
1-1) Optional이 없는 상황
Student 클래스가 있다.
@RequiredArgsConstructor
public class Student {
private final String name;
private final int num;
public boolean hasSameName(String name) {
return name.equals(this.name);
}
@Override
public String toString() {
return "학생이름 : " + name + ", 번호 : " + num;
}
}필드로 이름인 name, 출석번호인 num을 가지고 있다. 생성자로 각 필드값을 받을 것이다. toString() 메소드도 오버라이드했다. hasSameName()은 인자로 들어오는 String 값과 필드의 이름 값이 같은지 여부를 return한다.
이 Student 클래스에 대한 리스트를 담고있는 StudentRepository가 있다.
public class StudentRepository {
private final List<Student> attendance = new ArrayList<>();
AttendanceRepository() {
attendance.add(new Student("김부추",1));
attendance.add(new Student("박부추",2));
attendance.add(new Student("이부추",3));
attendance.add(new Student("전부추",4));
attendance.add(new Student("최부추",5));
attendance.add(new Student("한부추",6));
}
public Student findStudentByName(String name) {
for (Student student : attendance) {
if (student.hasSameName(name)) {
return student;
}
}
return null;
}
}일단 생성자로 리스트 자체를 구성했다. 이름이 김부추~한부추, 출석번호가 1번~6번인데 이건 일단 동작을 위해서 만든 더미데이터!
public한 findStudentByName() 메소드가 있는데, 메소드 이름 그대로 인자값으로 전달한 name으로 student를 찾는 메소드다. for문으로 요소를 돌아 hasSameName()을 통해 이름이 일치하는 값을 찾고 있으면 그 요소값을 return, 모든 요소를 돌아도 찾을 수 없으면 null을 return한다.
이를 사용하는 클라이언트 코드를 보자. "김부추"라는 이름을 가진 학생과, "황부추"라는 이름을 가진 학생을 각각 찾고싶다. 각각 findStudentByName()을 호출했다.
public class Client {
public static void main(String[] args) {
StudentRepository studentRepository = new StudentRepository();
Student kimBuchu = studentRepository.findStudentByName("김부추");
if (kimBuchu!=null) {
System.out.println(kimBuchu);
} else {
System.out.println("김부추라는 학생은 없는데요?");
}
Student hwangBuchu = studentRepository.findStudentByName("황부추");
if (hwangBuchu!=null) {
System.out.println(hwangBuchu);
} else {
System.out.println("황부추라는 학생은 없는데요?");
}
}
}보면 알겠지만, 참조변수에 대해 null checking이 이뤄짐을 알 수 있다. 아.. 보기싫다. findByName()을 호출할 때마다 이런식으로 null checking을 해줘야한다. 이 사실을 깜빡하고 이 메소드를 이리저리 쓰다가 NPE 한 번 뜨면 똑같이 if student!=null 작성하는데 손가락 움직일거 생각하니 힘이 빠진다.
1-2) Optional<Student>
유틸 패키지에 있는 Optional 클래스는 이와같은 null 처리를 "FANCY"하게 해준다. Optional은 "썬크림은 필수, 비비크림은 옵션!" 할 때 옵션이다(썩은 비유 죄송합니다). 그러니까 꼭 필수로 있어야하는 값은 아니고 null이 있을 수도 있다~~ 를 고지하는 용도의 클래스라고 받아들이면 된다.
Optional 객체의 생성은 크게 다음의 세가지 방법이 있다.
- Optional.of(<null이 아닌 객체>)
- Optional.empty()
- Optional.ofNullable(<null일 수도 있는 객체>)
StudentRepository를 Optional 객체를 return하도록 바꿔보겠다.
public class StudentRepository {
private final List<Student> attendance = new ArrayList<>();
StudentRepository() {
attendance.add(new Student("김부추",1));
attendance.add(new Student("박부추",2));
attendance.add(new Student("이부추",3));
attendance.add(new Student("전부추",4));
attendance.add(new Student("최부추",5));
attendance.add(new Student("한부추",6));
}
public Optional<Student> findStudentByName(String name) {
for (Student student : attendance) {
if (student.hasSameName(name)) {
return Optional.of(student);
}
}
return Optional.empty();
}
}원래 코드에서 Optional로 감싼 부분이 추가됐을 뿐이다. 그래서 뭐가 달라졌냐? 클라이언트 코드를 봐야한다.
public class Client {
public static void main(String[] args) {
StudentRepository studentRepository = new StudentRepository();
studentRepository.findStudentByName("김부추").ifPresentOrElse(
System.out::println,() -> {
System.out.println("김부추라는 학생은 없는데요?");
});
studentRepository.findStudentByName("황부추").ifPresentOrElse(
System.out::println,() -> {
System.out.println("황부추라는 학생은 없는데요?");
});
}
}if (kimBuchu!=null) 부분이 없어지고, ifPresentOrElse()라는 메소드를 쓸 수 있게 되었다. 해당 메소드는 첫번째 인자로 Consumer, 두번째 인자로 Runnable FunctionalInterface를 받는다. 람다식을 쓰도록 하는 것이다. 람다식에 대해 모른다면.. 참고.
Consumer는 Optional 객체가 null이 아닐 때 실행된다. Consumer 인자로 null이 아닌 Student객체가 들어가게 되고 해당 로직이 그대로 수행되는 것이다. System.out::println 형식의 메소드 참조를 이용했다. empty Runnable은 Optional 객체가 null일때 실행된다. 그래서 위 코드는 Optional을 쓰기 전과 100% 동일한 기능을 제공한다. 값이 있으면 해당 값을 System.out.println()하고, 없으면 "~~라는 학생은 없는데요?"라고 출력하는 것이다.
Optional<T> 객체가 null을 반환할 때, 처리할 수 있는 방법이 몇 가지가 있다.
- orElseThrow()를 통해 예외를 던지게 할 수 있다. Supplier 람다식으로 Exception 객체를 반환하게 한다.
- orElse()의 인자로 default 객체를 넣어 Optional이 null일 경우 반환할 객체를 지정할 수 있다.
- orElseGet()의 Supplier 람다식 인자로 default T타입 객체를 반환하도록 할 수 있다. 2번과 차이점은 객체 자체가 아닌 "람다식"이 들어갔다는 점이다. 만약 Optional 객체가 null이라면 해당 람다식에서 return한 값이 반환된다.
어렵지 않은 내용이지만, 각 예시를 적용한 코드를 보자.
public class DealWithOptional {
public static void main(String[] args) {
StudentRepository studentRepository = new StudentRepository();
// 1. 에러 던지기
Student null1 = studentRepository.findStudentByName("존재하지않는학생이름")
.orElseThrow(()-> new RuntimeException("존재하지 않는 학생 이름입니다!"));
// 2. default 객체 반환하기
Student null2 = studentRepository.findStudentByName("존재하지않는학생이름")
.orElse(new Student("이제존재하게된학생이름",7));
// 3. 일정로직 수행 후 default 객체 반환하기
Student null3 = studentRepository.findStudentByName("존재하지않는학생이름")
.orElseGet(() -> {
System.out.println("존재하지 않을 때 수행되는 Supplier 람다식입니다.");
return new Student("이제존재하게된학생이름",7);
});
}
}최초로 프로젝트다운 프로젝트를 했던 언어가 자바스크립트였고, Promise 관련한 콜백 기능이 재미있었기 때문에 이런 람다식 관련 기능을 살펴보는건 언제나 즐겁다 ㅋㅋ
1-3) Optional 주의.
Optional에서 사용하면 안되는 안티패턴이 있다.
public class Client {
public static void main(String[] args) {
StudentRepository studentRepository = new StudentRepository();
Optional<Student> kimBuchu = studentRepository.findStudentByName("김부추");
if (kimBuchu.isPresent()) {
System.out.println(kimBuchu);
} else {
System.out.println("김부추라는 학생은 없는데요?");
}
}
}왜인지는 알겠지? Optional의 isPresent()는 해당 Optional 객체의 객체값이 null이 아닐때 true를 반환한다. 코드를 위같이 쓰면 결국 Optional을 쓰지 않은 최초의 코드랑 똑같아진다. isPresent()는 분명 유용하게 쓰일 때가 있겠지만, 적어도 위와 같은 상황은 아니다. null 처리는 2번에서 설명한 방법중 상황에 맞는 것을 사용하도록 하자.
그리고 사실, StudentRepository에서 Optional을 반환한 것도 어떻게보면 안티패턴이다. 메소드에서 직접 Optional.empty()를 반환하는 것은 null을 반환하는 것과 크게 다르지 않기 때문이다. 그런 상황이라면 그쪽에서 예외를 던지거나 default 객체를 만드는 편이 낫다. Repository 코드를 좀 더 괜찮게 수정해봤다.
public class StudentRepository {
private final List<Student> attendance = new ArrayList<>();
StudentRepository() {
attendance.add(new Student("김부추",1));
attendance.add(new Student("박부추",2));
attendance.add(new Student("이부추",3));
attendance.add(new Student("전부추",4));
attendance.add(new Student("최부추",5));
attendance.add(new Student("한부추",6));
}
public Optional<Student> findStudentByName(String name) {
return attendance.stream()
.filter(student -> student.hasSameName(name))
.findAny();
}
}Steram API를 이용했다. filter()은 Predicate 람다식을 만족하는 객체만 다음 스트림으로 넘겨준다는 사실을 기억해라! findAny()를 통해 일치하는 값이 하나라도 있다면 그 값을 return하고, 없으면 null을 return할 것이다. 하는 일은 2번의 findStudnetByName() 메소드와 100% 동일하다. 그렇지만 더 짧고, 가독성있는 코드가 되었다!
2. 클라이언트에서 서버로 파라미터 보내기
2-1) 쿼리 파라미터
유튜브에 "메이플스토리"를 검색했다. URL을 살펴보자.
 일반적으로 웹 브라우저에서 가장 흔하게 사용하는 URL은 스킴-호스트-(포트)-path-(쿼리)-(frag) 구조를 띈다. 위 URL의 경우 분석을 해보면 다음과 같다.
일반적으로 웹 브라우저에서 가장 흔하게 사용하는 URL은 스킴-호스트-(포트)-path-(쿼리)-(frag) 구조를 띈다. 위 URL의 경우 분석을 해보면 다음과 같다.
- 스킴 : HTTPS
- 호스트 : youtube.com
- 포트 : 생략되었지만 HTTPS이므로 443
- path : /results
- 쿼리 :
search_query항목이 "메이플스토리"
/result path의 쿼리로 search_query 항목을 "메이플스토리"로 준 것이다. 아마 유튜브의 웹서버는 /result 요청에 대해, 쿼리 파라미터로 들어온 search_query 항목의 문자열과 맞는 동영상들을 찾아 화면을 구성한 뒤 나에게 응답으로 동영상 목록을 줬을 것이다. 만약 search_query 항목이 없다면? 해당 항목을 비워놓고 요청을 날려봤다.
 검색 결과가 없단다. 뭐 검색하는 동영상 글자가 없으니 당연한 일이다. 이렇게 URL의 쿼리 파라미터를 통해 서버로 데이터를 전송할 수 있다.
검색 결과가 없단다. 뭐 검색하는 동영상 글자가 없으니 당연한 일이다. 이렇게 URL의 쿼리 파라미터를 통해 서버로 데이터를 전송할 수 있다.
참고로 &을 이용해 여러 개의 쿼리 파라미터를 보낼 수도 있다. 아래와 같은 방법이다.
https://youtube.com/results?q1=첫번째&q2=두번째2-2) HTTP Body (PayLoad)
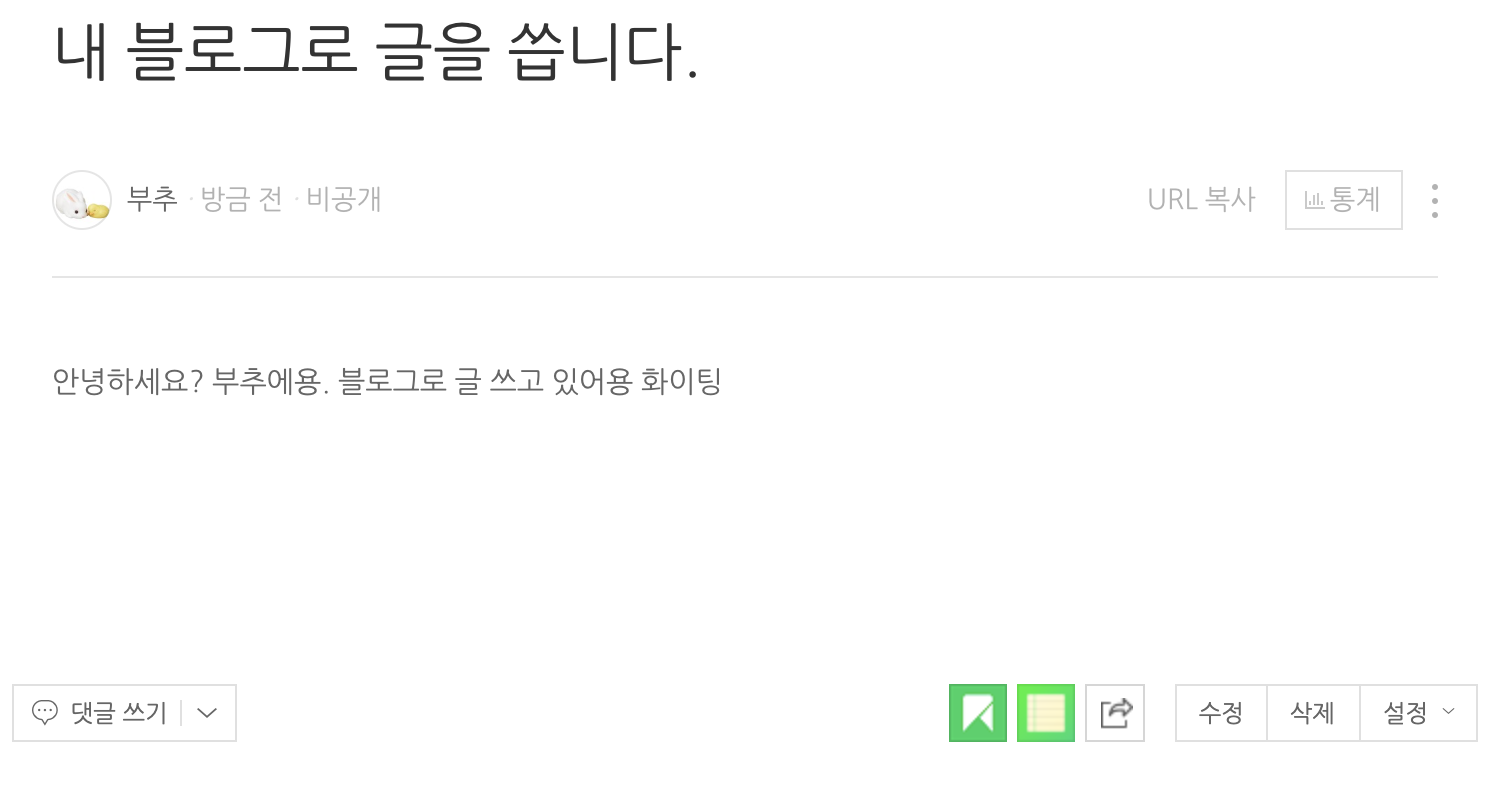
네이버 블로그 글에 다음과 같은 글을 썼다.(쓰고 난 뒤에 캡쳐인것에 대한 심심한 사과)
 그리고 제출한 뒤, HTTP 요청과 응답 메세지를 크롬을 이용해 재빨리 확인해봤다.
그리고 제출한 뒤, HTTP 요청과 응답 메세지를 크롬을 이용해 재빨리 확인해봤다.
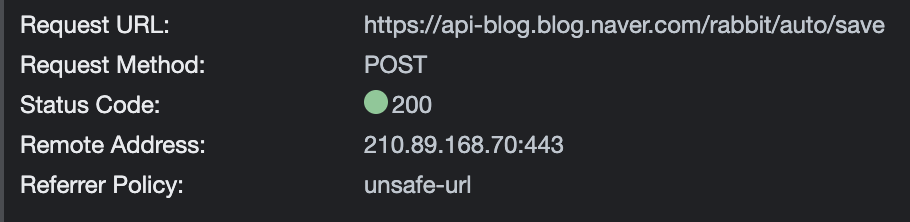
/rabbit/auto/save라는 path로 POST 요청이 보내졌다. 쿼리 파라미터를 통한 GET요청과 다른 모습이다. 이제 Payload, 즉 HTTP 요청 메세지의 "본문"을 살펴봤다.
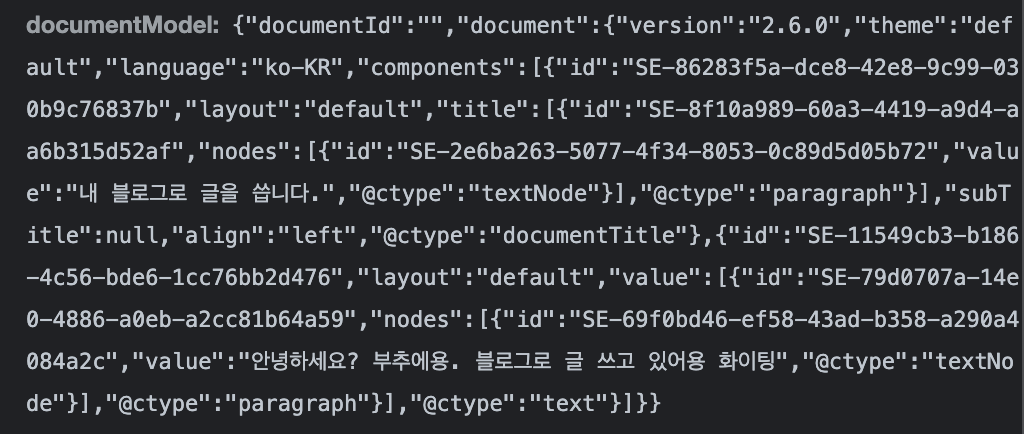 "documentModel"항목에 방금 작성한 블로그 제목과 본문 내용이 들어있는 것을 확인할 수 있다!
"documentModel"항목에 방금 작성한 블로그 제목과 본문 내용이 들어있는 것을 확인할 수 있다!
HTML 메세지의 바디를 통해 클라이언트 -> 서버 방향으로 데이터가 전송된 것이다. 해당 과정은 HTML의 <form>태그를 이용해서 이뤄진다. Content-type 항목은 application/x-www-form-urlencoded였는데, 작성한 블로그 글에 사진이 없었기 때문에 multipart/form-data가 아닌 모양이다..
아무튼 1) 쿼리 파라미터를 통해, 2) 메세지 바디를 통해 클라이언트에서 서버로 데이터가 이동될 수 있다는 사실을 배웠다.
# 둘이 뭔 차이인데요
喝!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
그냥 URL로 주는거랑 payload로 보내는거랑 같을리가 없잖아!!!!!
HTTPS는 암호화 통신이라는 것을 상기하자. 공개키를 통해 대칭키를 암호화하여 메세지 내용을 보낸다.
URL은 겉으로 드러나는 정보다. /results?search_query=메이플스토리라는 URL은 나 유튜브로 "메이플스토리" 검색했소~ 라고 광고하는 거나 마찬가지다. 그치만 서버에 POST할 내용을 body로 감싸면 암호화가 되어서, 이 URL로 뭘 제출하고 있는 것까진 알겠지만 정확히 어떤 내용을 제출하는지는 서버를 제외하고 아무도 모르게할 수 있다.
즉, 요청 정보가 보안에 민감하거나 단순 조회가 아닌 제출 목적의 데이터 전송이라면 메세지 body에 담는 것이 맞다. 반대로 예시로 들었던 유튜브 검색이라든가, 어떤 게시글 목록의 몇번째 페이지라든가, 하는 정보는 맘편히 쿼리 파라미터로 URL에 드러내도 된다. 털어서 뭐 어쩔건데? 하는 마인드.
3. SOLID(재)
존경하는 멘토님의 강의를 수강했다. 오브젝트 9장까지 읽은 입장에선 + 며칠간 같은 내용을 주구장창 생각해온 입장에선 역시나.. 같은 말을 빙빙... 도는 느낌이,, 😭
같은 말이라 함은 아래다.
결합도가 낮다 = 객체에 대해 알고 있는 정보가 적다 = 캡슐화와 추상화가 잘 되어있다 = 추상 클래스/인터페이스에 의존한다 = 의존성이 낮다 = 변경에 유연하다
개념적인 내용보다, 객체지향의 각 설계원칙이 따랐을 때 어떤 이점이 있으며 따르지 않았을 때 어떤 단점이 있는지, 그니까 왜 지켜야 하는지 위주로 한 번만 더! 정리해보도록 하겠다.
결론부터 말하자면, 객체지향에서 제일 무서워하는건 "변경"인 것 같다. SOLID 전부 "대충 변경을 최소화 하기 위함임ㅋ"하고 설명하면 얼추 들어맞는다;
# SRP : 응집력을 높이기 위해.
SRP는 하나의 클래스의 변경 이유는 오직 하나여야 한다라는 것이다.
프로그램의 모든 기능 ABCD를 수행하는 슈퍼-클래스가 하나 있으면, A 기능에 문제가 생길때나 B 기능에 문제가 생길때나 슈퍼-클래스를 수정해야한다. 커다란 슈퍼-클래스 안에서 문제가 있는 기능의 동작을 하는 코드를 일일이 찾아 수정하는건 번거롭다. 더 큰 문제는 A 기능과 관련된 코드를 수정한 결과가 BCD기능 전부에 퍼질 수 있다는 점이다. 변경에 대한 전파가 큰 것이다.
SRP를 지키지 못했다고 볼 수 있는 코드 예시가 흥미로웠다. 레이어드 아키텍처 패턴에서 Service 컴포넌트가 HTTP 프로토콜과 관련한 예외를 던지는 것이었다. 통신 프로토콜과 관련한 기능은 Controller단에서 끝내야하는데, Service 역시 HTTP 프로토콜과 관련한 책임을 수행하고 있으니 만약 프로토콜이 변경되면 Service 코드까지 수정이 일어나야 한다. 기능을 수행해야하는 책임이 있는 코드가 프로토콜 때문에 변경되었으므로 두 개 이상의 변경 이유가 생기는 것이다. SRP 위반!
SRP를 지키면 코드 응집력이 높아진다. 응집력이 높으면 하나의 기능을 수행하는 코드가 하나의 모듈에 몰려있으므로 기능의 수정을 위해 해당 모듈의 코드만 뜯어보면 된다. 응집력 높은 코드는 그 기능만 수행하고 있을 것이므로 변경 전파에 대한 걱정도 덜해도 되고, 특정 기능을 수행하고 싶을 때 해당 클래스를 여러번 재사용할 수 있어 편리하다.
# OCP : 수정을 최소화하며 확장.
구성으로 추상 인터페이스를 두는 것으로 달성할 수 있는 설계원칙이다. 인터페이스의 기능을 이용하는 클라이언트 코드는, 그것을 구현하는 구상 클래스가 어떤 변화가 있든지 상관하지 않는다. 호출한 상위 클래스의 메소드 결과가 잘 도착하기만 하면 클라이언트 코드는 문제없이 동작한다. 상위 인터페이스 / 추상 클래스라는 완충지대를 둠으로써 구상 클래스가 적절히 캡슐화되어 추상화된 기능을 제공할 수 있는 것이다.
추상 인터페이스는 구상 클래스보다 변화에 안전하다. 지난 수십 년간 휴대폰의 겉모습은 사람 얼굴만한 다이얼에서 손안에 들어오는 작은 휴대전화로 엄청난 변화를 겪었지만, 휴대폰이라는 개념 자체는 변하지 않았다. 전화와 문자 기능이 가능한 고수준 컴포넌트로서의 휴대폰은 사람들에게 항상 똑같이 인식되어왔지만, 폴더폰에서 터치 스마트폰에 이르기까지 휴대폰의 구상 구현체는 엄청나게 달라져왔던 것이다. 이것이 추상화의 위엄!
OCP를 통해 추상 인터페이스 타입의 컴포넌트를 추가하거나 삭제하는 식으로 간단하게 기능을 더하고 뺄 수 있다. 런타임때 구성요소 클래스를 바꿔서 실제 호출되는 메소드를 바꿀 수도 있다. 이런 기능들이 클라이언트에 영향을 미치지 않고 가능하니 굉장히 좋은 기능이라고 생각할 수 있다 !
# LSP : 다형성의 최대 이용
객체 지향적인 프로그램은 OCP를 위해 상위 추상 인터페이스가 제공하는 메소드를 사용한다. 즉, 클라이언트 코드는 그것의 구상 클래스가 무엇인지 상관하지 않고 상위 인터페이스의의 메소드를 사용하고 있다. 그런데 하위 클래스가 상위 클래스의 메소드를 수행하지 못한다면? 클라이언트는 난감해진다.
진정한 의미의 다형성은 추상인터페이스의 구현체가 무엇이든 상관없이 일정한 동작이 수행되는 것이다. 상위 인터페이스가 제공하는 메소드를 하위 클래스가 제대로 수행하지 못한다면 그것은 다형성이 이뤄졌다고 볼 수 없다.
개인적으로 계약에 의한 설계 설명이 흥미로웠는데, 설계 사전조건이 하위 타입에서 더 강해지면 안된다는 것이다. 나는 상위타입에서 숨겨놓은 private을 자식에서 public으로 짠! 하면 안될거라 생각했는데 오히려 그 반대였다. 상위 클래스의 public을 하위 클래스에서 private으로 바꾸면 상위 인터페이스에 맞춰 설계된 코드들에서 당혹감을 느끼게 된다. 다시 생각해보니 당연한 얘기인듯?;;
# ISP : 기능을 최소로 제공
SRP와 LSP의 내용이 다 들어있다. 인터페이스에 내용이 너무 많으면 SRP를 위반한 인터페이스일 확률이 높다. 그러면 여러 개의 책임을 가지게되고, 한쪽 기능을 위한 수정이 다른쪽 기능에 영향을 미칠 가능성이 높아진다. 그리고 그것을 구현하는 구상 클래스에게도 너무 많은 일을 하게 한다. 겉으로 드러나는 인터페이스 메소드가 많아진다는 사실 자체도 캡슐화 정도를 떨어뜨리는 요인이 될 수 있다.
인터페이스는 하나의 기능을 수행하는데 정말 필요한 메소드들만, 구현 노출을 최소화하는 식으로 제공하도록 하자. 오죽하면 @FunctionalInterface로 구현 메소드가 1개인 인터페이스들까지 나왔겠니!
# DIP : 캡슐화된 고수준 컴포넌트 사용
- 저수준 컴포넌트 : 구체적 기술에 의존하는 컴포넌트
- 고수준 컴포넌트 : 구체적 기술에 의존하지 않는 컴포넌트
여기서 말하는 컴포넌트란, 하나의 클래스일 수도 있고 어떤 패키지일 수도 있고.. 어쨌든 묶일 수 있는 모듈단위라고 생각하면 된다.
DIP는 의존 역전 원칙으로, 고수준 컴포넌트가 저수준 컴포넌트에 의존하면 안된다라는 원칙인데, 이러면 안되는 이유는 OCP에서 설명한 것과 같은 이유다. 구체적 클래스는 쉽게 변한다. 저수준 컴포넌트같이 쉽게 변하는 것에 의존하면 고수준 컴포넌트도 그 변화에 휩쓸리게 된다.
전날 TIL 글에서 사용한 의존성 방향은 아래와 같다. Phone-KakaoPay 사이에 고수준 컴포넌트가 저수준 컴포넌트에 의존하는 것을 확인하자..
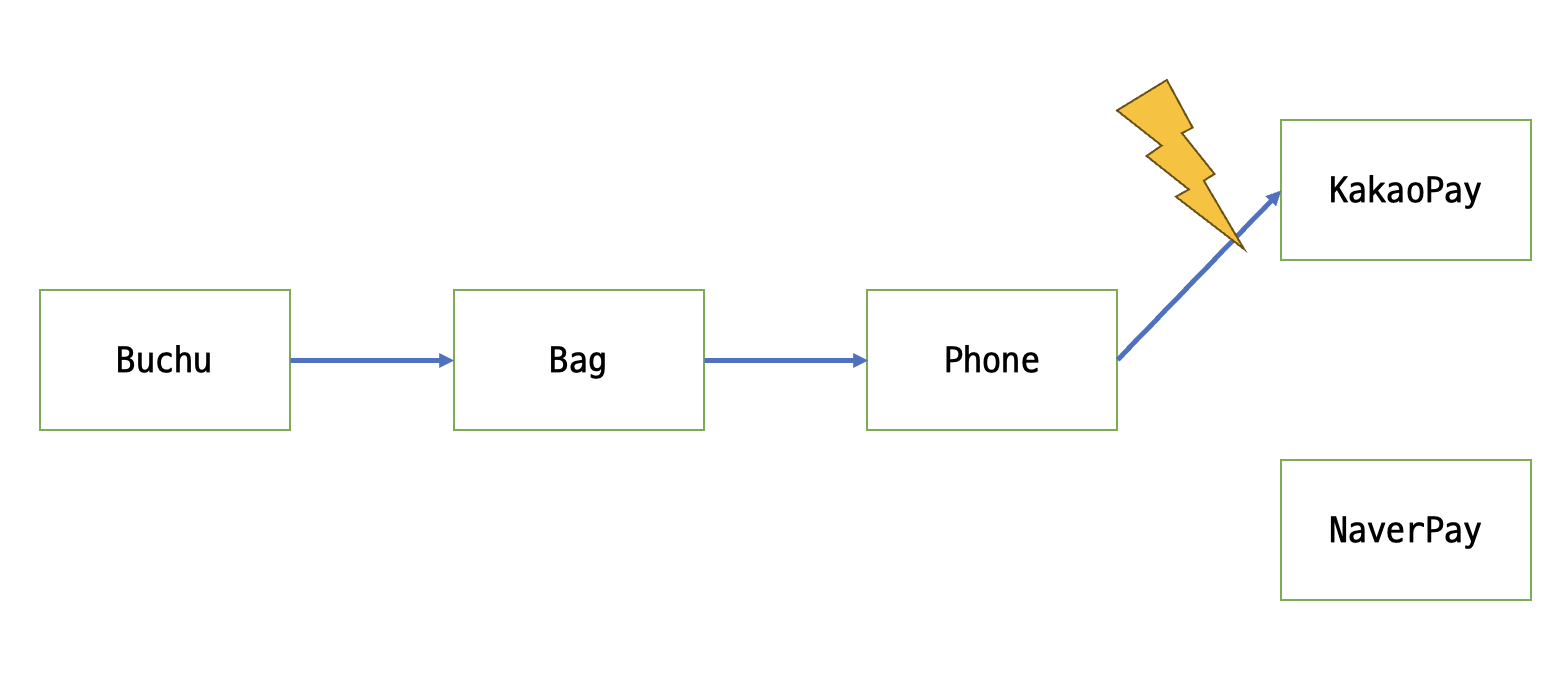 위와 같은 상황에선 네이버페이를 이용하고 싶을 때
위와 같은 상황에선 네이버페이를 이용하고 싶을 때 Phone 코드를 일일이 수정해야하고, 구상 클래스인 KakaoPay가 변할때 Phone에게까지 영향이 크게 미친다.
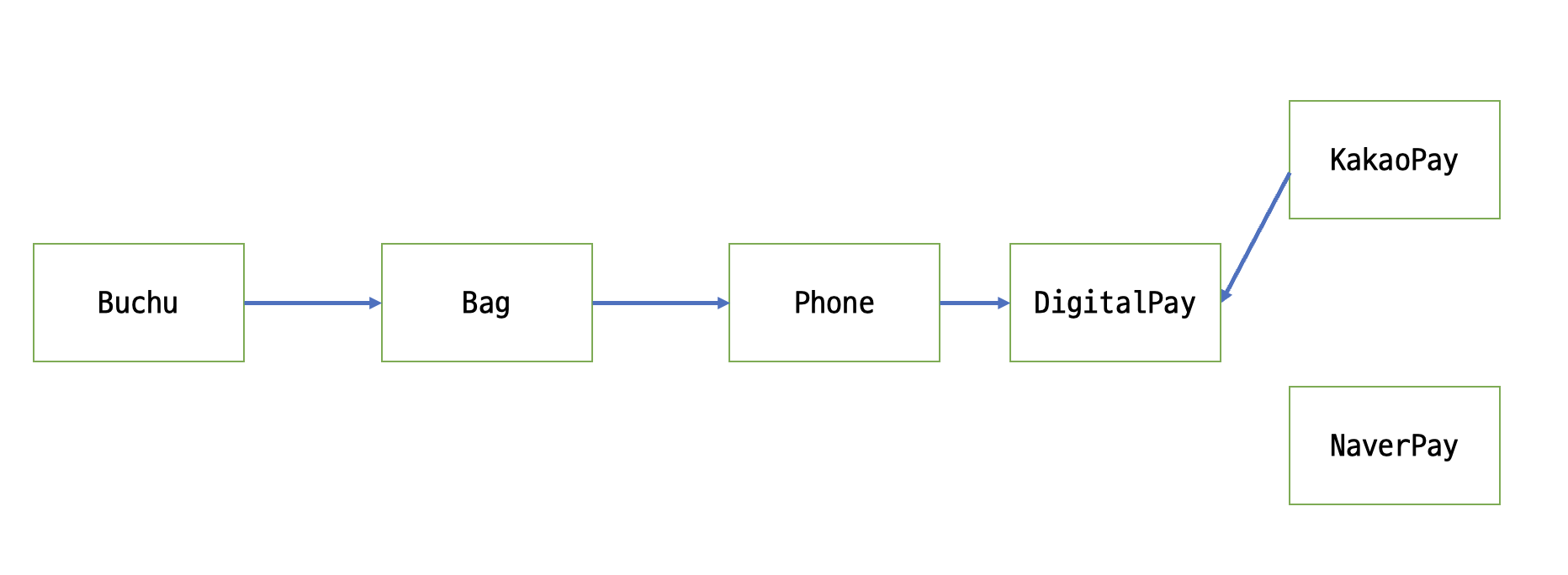 원래 오른쪽으로만 향하던 의존 방향이
원래 오른쪽으로만 향하던 의존 방향이 DigitalPay를 기준으로 역전되었다. 이래서 원칙 이름이 Dependency "Inversion" Principle이다.
REFERENCE
https://school.programmers.co.kr/app/courses/17778/dashboard
https://www.baeldung.com/java-optional
