TIL
- 행렬 테두리 회전 : 2차원 배열의 조작
- 다단계 칫솔 판매 : 딕셔너리 자료구조를 이용한 재귀
- Hash를 사용하는 자료구조 1 - HashMap
1. 행렬 테두리 회전
rows x columns 크기의 2차원 배열로 구현된 행렬이 존재한다. 행렬은 1행 1열의 1부터, rows행 columns열의 rows * column까지의 값을 가진다.
문제의 예시로서 다음과 같은 6 * 6 행렬을 그림으로 나타내주었다.
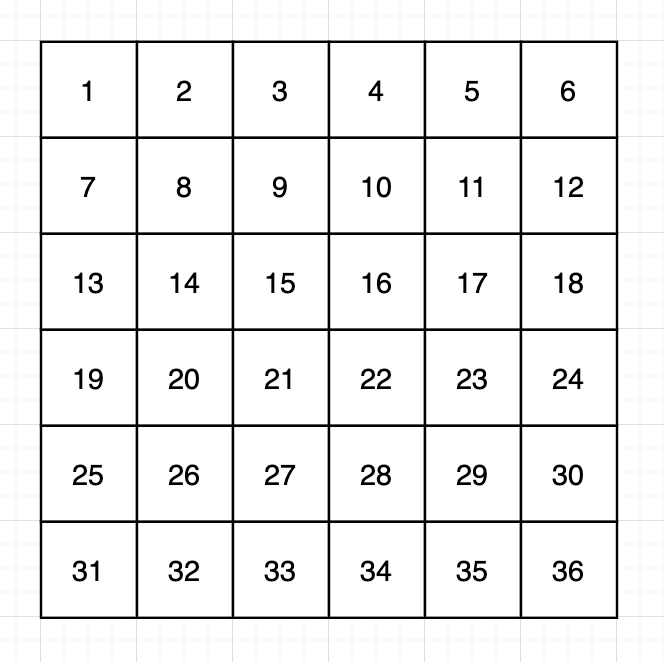
[x1,y1,x2,y2]로 행렬의 일정 범위를 지정해주는 좌표를 queries로 제공한다.
두 좌표로 표현되는 중첩 배열의 테두리 부분을 시계방향으로 회전했을 때, 회전하게 되는 원소의 최소값을 구하는 문제이다.
어떻게 보면 단순한 구현문제다. 근데 삑나면 끝없는 삽질이 필요한!
- 값을 이동시킨다는 것을 잘 구현할 수 있는가
- 2차원 배열을 잘 다룰 수 있는가
시간 안에 배열과 그 index를 적절하게 사용할 수 있는가가 관건인 듯하다.
아주 정직하게 문제를 풀었다. x1,y1으로 표현되는 좌표는 예시의 그림상에서 왼쪽 위를, x2,y2는 오른쪽 아래의 좌표를 나타낸다.
- 행이
x1으로 고정된 가장 윗줄을 오른쪽으로 한 칸씩 옮긴다. - 열이
y2로 고정된 가장 오른쪽 줄을 아래로 한 칸씩 옮긴다. - 행이
x2로 고정된 가장 아랫줄을 왼쪽으로 한 칸씩 옮긴다. - 열이
y1로 고정된 가장 왼쪽 줄을 위쪽으로 한 칸씩 옮긴다.
열거한 과정들을 하나씩 진행했다.
def solution(rows, columns, queries):
answer = []
graph,c = [[] for _ in range(rows)],1
for i in range(rows):
for _ in range(columns):
graph[i].append(c)
c += 1
for x1,y1,x2,y2 in queries:
x1 -= 1
y1 -= 1
x2 -= 1
y2 -= 1
res = graph[x1][y1]
# 맨 윗줄을 오른쪽으로
tmp = graph[x1][y1]
for y in range(y1,y2):
t = graph[x1][y+1]
res = min(t,res)
graph[x1][y+1] = tmp
tmp = t
# tmp : 오른쪽 위
# 맨 오른쪽 줄을 아래로
for x in range(x1,x2):
t = graph[x+1][y2]
res = min(t,res)
graph[x+1][y2] = tmp
tmp = t
# tmp : 오른쪽 아래
# 맨 아래줄을 왼쪽으로
tmp2 = graph[x2][y1]
res = min(res,tmp2)
for y in range(y1,y2-1):
res = min(res,graph[x2][y])
graph[x2][y] = graph[x2][y+1]
res = min(res,graph[x2][y2-1])
graph[x2][y2-1] = tmp
# tmp2 : 왼쪽 아래
# 맨 왼쪽 줄을 위로
for x in range(x1,x2-1):
res = min(res,graph[x][y1])
graph[x][y1] = graph[x+1][y1]
res = min(res,graph[x2-1][y1])
graph[x2-1][y1] = tmp2
answer.append(res)
return answer구현할 때 가장 문제였던 것이 꼭짓점 값이었다. 코드 상에선 tmp, tmp2 값으로 두고 열거한 과정이 끝날 때마다 꼭짓점의 바로 옆 값에 추가해주는 식으로 구현했다.
값을 이동시킬 때마다 res변수를 min()함수로 비교해서 queries가 일어날 때마다 리스트에 추가하여 답을 냈다.
2. 다단계 칫솔 판매
트리로 표현된 다단계 구조(...)가 있다. 각각의 판매원과 그 판매원이 영입한 자식(트리로 표현되었으므로 이 용어를 사용하겠다) 판매원이 존재한다. 자식 판매원을 영입한 판매원을 부모 판매원이라고 하겠다.
수익이 발생할 때마다 판매원은 자신의 부모 판매원에게 수익의 10%를 납부해야 한다. 이런 식으로 부모 판매원이 수익을 얻은 경우 역시 수익이 발생했다고 친다.
10%는 내림으로 표현된다. 만약 200원의 수익이 난다면 부모 판매원에게 10%인 20원을 납부해서 판매원의 실질적 수익은 180원이다. 부모 판매원은 20원을 받았지만, 또다시 부모 판매원에게 10%인 2원을 납부해서 실질적 수익은 18원이다. 2원을 받은 부모의 부모 판매원은 또다시 10%인 0.2원을 납부해야 하지만.. 1원 밑의 단위는 취급하지 않는다. 2원은 온전히 수익을 가진 본인의 몫으로 친다.
실수하기 쉬운 문제였다! 자식 판매원의 총수익이 아닌, seller 및 amount 리스트로 표현되는 수익이 발생할 때마다 수익-납부 연산이 발생한다는 점 때문에 더이상 자식 판매원이 존재하지 않는 판매원의 수익을 모두 더해서 하나씩 올려보내는 식으로 구현해서 틀렸다.
판매원은 이름을 가지고 있으므로 문제 해결을 위한 구성을 딕셔너리로 구현했다.
children: key의 자식들을set으로 보관한다.parent: key의 부모를 value로 갖는다.money: key의 총 수익이다. 답을 낼 때 사용한다.
위의 딕셔너리를 가지고 다음과 같은
children,parent딕셔너리를 구성한다.- 각각의
seller - amount이벤트가 발생할 때마다 수익을 부모에게 전달하는 아래 과정을 반복문으로 수행한다.- 현재 판매원
person에게 발생한 수익은profit이다.money[person]에 수익을 추가한다. up변수에profit의 10%를 내림한 값을 담는다. 이것은 현재 판매원의 수익에서 빠지는 값이며 부모 판매원의 새로운 수익이 될 값이다.up은 부모 판매원, 즉parent[person]의 새로운 수익이다. 현재 판매원person과profit을 업데이트 하고 다음 반복문을 돈다.- 현재
person이"-"가 될 때까지, 즉 최상단의 부모 판매원이 될 때까지 반복한다.
- 현재 판매원
- 구성된
money딕셔너리를 답으로 내놓는다.
def solution(enroll, referral, seller, amount):
children,money = {p:set() for p in enroll},{p:0 for p in enroll}
parent = {enroll[i]:referral[i] for i in range(len(enroll))}
for i in range(len(enroll)):
if referral[i]!="-":
children[referral[i]].add(enroll[i])
for i in range(len(seller)):
person, profit = seller[i], amount[i]*100
while (person!="-"):
money[person] += profit
up = int(profit * 0.1)
# *** 중요!! ***
if (up==0):
break
money[person] -= up
profit = up
person = parent[person]
return [money[p] for p in enroll]"중요"라고 표시된 부분을 보자! 왜 up==10으로 break조건을 달아줬냐면..
문제 조건에 판매원(enroll)의 길이는 최대 1만이고 판매 이벤트(seller)의 길이는 최대 10만이다. 만약 모든 판매원들이 1만개의 부모-자식 판매원 관계를 맺은 상황에서 가장 자식 판매원이 10만개의 판매를 올린 상황이라면 시간 복잡도는 1만 * 10만 = 10억이 되어 시간 초과가 난다.
그러나 판매량, 즉 amount의 범위는 1~100이다. 실질적 수익은 100~10,000의 값을 가지는데 이렇게 되면 위 코드의 while문을 5번만 돌아도 up 변수가 0이 된다. 그러면 더이상 반복문을 돌 필요가 없어지게 되므로 break를 사용했다. 최대 1만번 부모 판매원에게 profit을 전달하는 과정을 5번으로 줄이는 작업이었다.
3. Map
1. Map이란?
Key - Value 페어의 자료구조
ADT 관점에서의 Map은 key-value 페어의 자료구조이다. 중복되지 않는 key가 가지는 value 값을 저장하면 좋다(value는 중복 가능). 어떤 투표를 한다고 했을 때 각 항목(key)의 득표 수(value), 전화번호(key)에 따른 사람의 이름(value) 등의 예시가 있겠다.
Map은 이렇게 중복되지 않는 각 key를 빠른 시간(일반적으로 O(1))에 접근하는 편리함을 제공한다. Map 자료구조에서 특정 key로 value를 찾으면 일반적으로 상수 시간 안에 접근이 가능하다는 것이다. key가 될 수 있는 값은 무궁무진한데, 어떻게 빠른 접근 시간을 보장할까?
hash function 이용
hash function, 한국어로 해시 함수란 임의의 길이를 가진 데이터를 고정된 길이의 데이터로 매핑하는 함수이다. 다양한 길이를 가질 수 있는 key에 hash function을 적용해서 일정한 길이나 포맷을 가진 것으로 변환하고, 이를 실제 Map을 구현하는데 사용한다.
'Map은 key 해시 결과값을 일종의 index로 사용하여 상수 시간 안에 데이터를 접근한다'로 이해할 수 있다.
2. HashMap : 자바의 map 구현체
자바에서 Map의 가장 대표적인 구현체로 HashMap<K,V>가 있다. key의 타입 T, value의 타입 V를 제네릭 타입으로 지정했다.
HashMap의 기본적인 동작을 살펴보자. 영화 이름(String)과 영화의 점수(Integer)를 담는 HashMap<String, Integer> 객체를 생성했다.
HashMap<String,Integer> movies = new HashMap<>();put()의 인자로 key와 value값을 넣어줄 수 있다.
movies.put("슈퍼 마리오 브라더스",100);
movies.put("범죄도시",80);
movies.put("기생충",50);get()의 인자로 key 값을 넣으면 해당하는 key에 대한 value 값을 반환한다. 만약 key가 없다면 null을 반환한다.
// 100
System.out.println(movies.get("슈퍼 마리오 브라더스"));replace()로 key와 수정하고자 하는 새로운 value값을 전달하여 value를 수정할 수 있다.
movies.replace("기생충",1000);
System.out.println(movies.get("기생충")); // 1000remove()의 인자로 key값을 전해줘 key-value 쌍을 삭제할 수 있다.
movies.remove("범죄도시");
System.out.println(movies.get("범죄도시")); // null3. HashMap의 동작 과정
Map은 value 값을 버킷이라 불리는 곳에 저장한다. 저장할 버킷 인덱스는 key의 해시값이 결정한다. 해시 결과를 map 크기로 모듈러 연산을 하여 저장할 인덱스를 구하는 과정을 거친다.
초기 capacity가 8인 Map 자료구조를 예시로 들어보겠다.
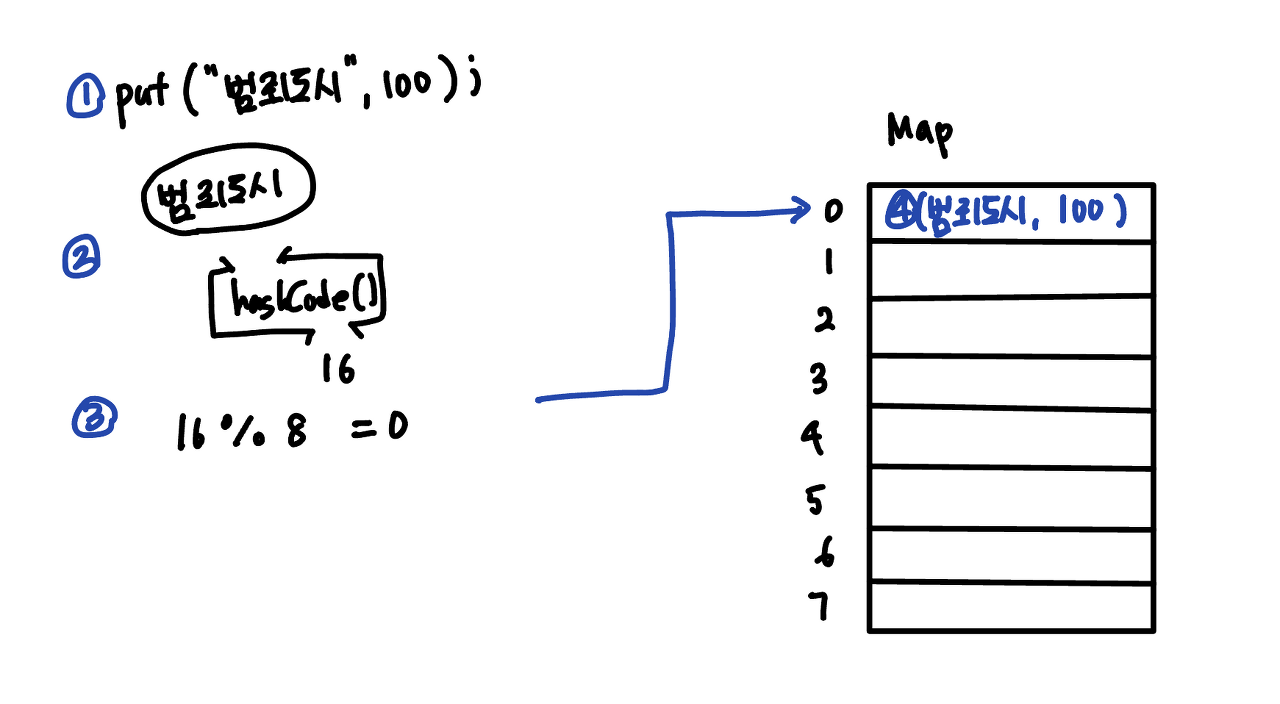
- put() 메소드가 호출된다.
- key 인스턴스의 hashCode() 메소드를 호출하여 결과를 받는다. 위의 예시의 경우 16이 결과값이라고 하자.
- 해시 값을 Map의 capacity로 모듈러 연산을 한다. 결과값은 0이다.
- 모듈러 연산의 결과값을 Map의 인덱스로 사용한다. 0번 버킷에 put의 인자로 넣어준 key-value 쌍이 들어간다.
# hashCode()
여기서 중요한 것은 key의 해시값을 얻기 위해 hashCode() 메소드를 사용한다는 점이다. hashCode() 메소드는 toString(), equals()와 더불어 자바랭의 Object 클래스가 기본으로 갖고있는 메소드로, 일반적으로 객체 주소의 해시 값을 반환한다. (Primitive 타입의 경우 값 자체를 반환)
이 hashCode의 결과가 HashMap이 실제로 사용하는 해시 값이다!
실제로 Object의 hashCode 메소드 주석을 보면, HashMap에서 사용하기 위한 hash code를 반환한다고 써져있다.

HashMap 클래스의 put(), get() 등의 메소드를 따라가다 보면 key의 hashCode() 메소드를 호출하는 부분을 찾을 수 있다.

실제로 hashCode()를 Override하여 hashCode()가 호출되었는지 확인해보자.
public class MyKey {
@Override
public int hashCode() {
System.out.println("hashCode() 메소드 호출");
return super.hashCode();
}
}
public class HashCodeEx {
public static void main(String[] args) {
HashMap<MyKey,Integer> hashMap = new HashMap<>();
MyKey myKey = new MyKey();
System.out.println("put() 호출");
hashMap.put(myKey,1);
System.out.println("get() 호출");
hashMap.get(myKey);
}
}결과값은 깔끔하게 나온다.
put() 호출
hashCode() 메소드 호출
get() 호출
hashCode() 메소드 호출4. hash collision
key가 가진 값은 무궁무진한데 반해, Map이 가질 수 있는 버킷의 개수는 제한되어있다. 또한 만들 수 있는 객체의 수는 무궁무진한데 반해, 해시 결과값은 int 자료형으로 표현할 수 있는 2^32개가 최대이다. 이렇게 되면 해시 충돌이 불가피하다. 분명 다른 key 값이지만, 해시 값이 같거나 해시 값의 모듈러연산 결과가 같아 같은 인덱스의 버킷을 가리키게 되는 경우 hash collision(해시 충돌)이 발생했다고 한다.
해시 값이 각각 10, 26인 key1과 key2가 있고 map의 capacity는 8이라고 가정하면, 모듈러 연산의 결과는 모두 2이다. key의 값이 다른데 같은 버킷 인덱스를 가지는 문제가 발생했다.
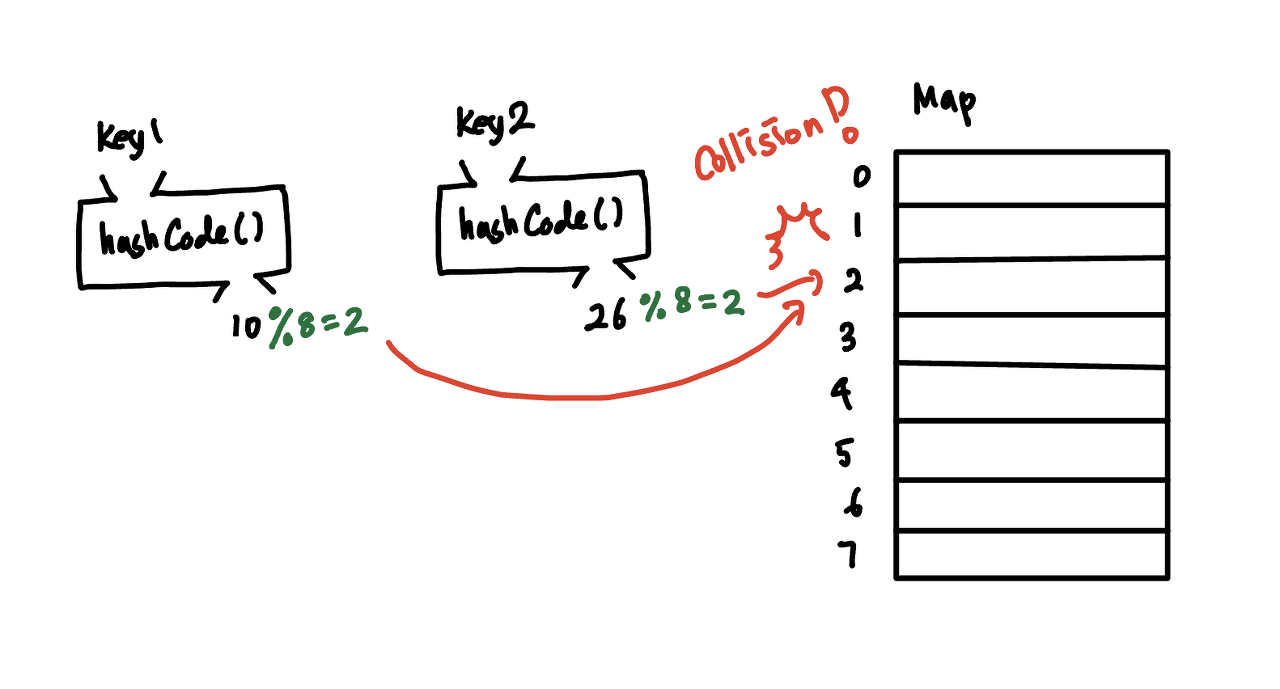
보통 Map에선 이런 해시 충돌을 두 가지 방식으로 해결한다.
1) Seperate Chaining
버킷을 Node 기반의 LinkedList로 구현하는 방식이다. 해시 충돌로 인해 같은 map 인덱스를 가진 key-value 쌍들이 LinkedList 구조로 연결되어있다.
key-value 노드를 저장하고자 하는 버킷에 이미 노드들이 존재한다면 기존 tail 노드의 next 값을 새로운 노드로 바꿔주는 것이다.
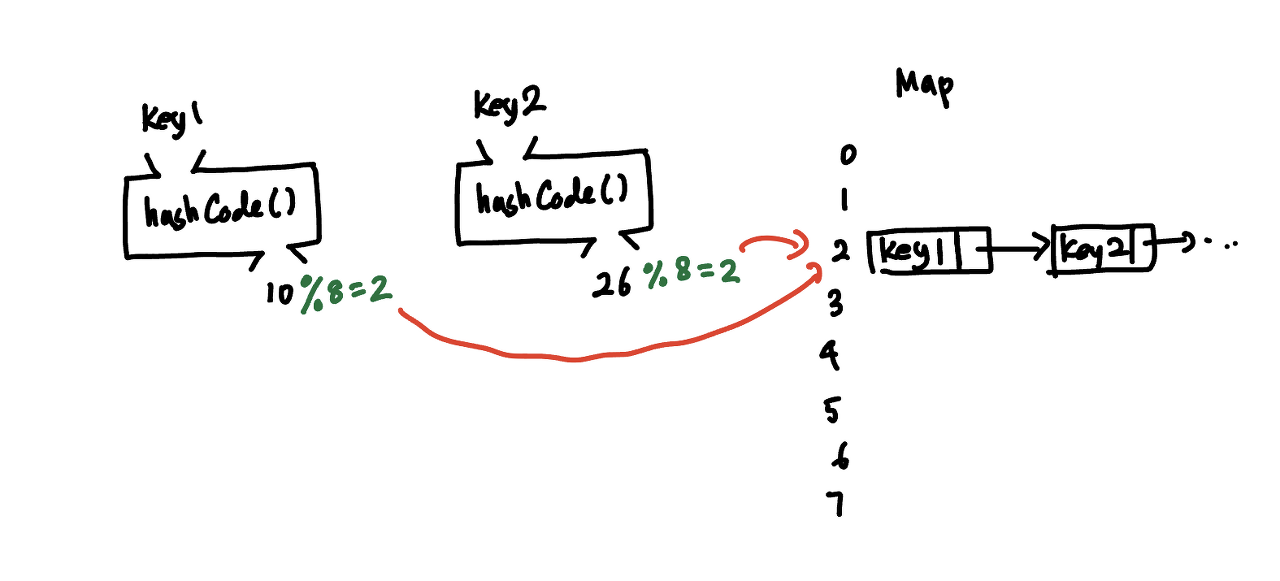
get()을 통해 key에 따른 value값을 찾을 때엔 버킷 연결 리스트에 있는 모든 노드를 순회한다.
실제로 자바의 HashMap이 이 방식을 채택한다. put() 메소드의 내부 구현을 살펴보면, 특정 인덱스의 버킷 연결리스트가 일정 길이 이하일 경우 p.next = newNode()를 통해 연결리스트의 꼬리에 새 노드를 추가하는 부분을 발견할 수 있다.
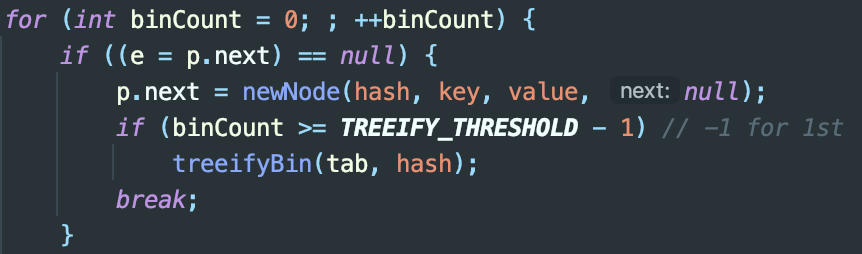
버킷 연결리스트가 TREEIFY_THRESHOLD를 넘어가면 treeify를 시켜 해시 충돌이 일어난 요소들을 트리 구조로 저장한다. 같은 버킷 내에서 찾고자 하는 요소를 더 효율적으로 찾기 위함이다. (탐색 시간은 O(logN)인 tree가 O(N)인 list보다 유리하다) 참고로 threshold는 8이다.
그리고 get()의 내부 구현을 살펴보면, 버킷의 연결 리스트에 여러 노드가 존재할 경우 equals() 메소드를 호출하여 일치하는 key 값을 찾을 때까지 버킷의 리스트를 iterate함을 알 수 있다.

이러한 HashMap의 구현 때문에, equals()와 hashCode()는 같이 Override되어야 한다. 같은 객체에 대해서 같은 hashCode 값을 반환하도록 하여 Map의 같은 버킷에 보관될 수 있도록 하고, 해시 충돌이 일어났을때 key를 구분하기 위해 equals() 메소드를 호출하기 때문이다.
의도적으로 해시 충돌이 일어나는 상황을 만든 뒤 equals()와 hashCode() 메소드가 원하는대로 호출되는지 실험해보자!
public class CollisionKey {
private final int key;
public CollisionKey(int key) {
this.key = key;
}
@Override
public boolean equals(Object obj) {
System.out.println("equals() 호출");
return super.equals(obj);
}
@Override
public int hashCode() {
System.out.println("hashCode() 호출");
return key;
}
}
public class CollisionEx {
public static void main(String[] args) {
CollisionKey key1 = new CollisionKey(10);
CollisionKey key2 = new CollisionKey(10);
HashMap<CollisionKey,Integer> hashMap = new HashMap<>();
hashMap.put(key1,1);
hashMap.put(key2,1);
System.out.println();
hashMap.get(key2);
}
}- hashCode(), equals()가 호출될 때마다 확인할 수 있도록 Override했다.
hashCode() 호출 // key1 버킷 인덱스
hashCode() 호출 // key2 버킷 인덱스
equals() 호출 // key2 저장을 위해 key1과 일치 여부 확인
hashCode() 호출 // get(key2)
equals() 호출 // key2 찾는 과정중 key1과 일치 여부 확인- key1, key2를 put하는 과정에서 버킷 인덱스를 구하기 위해 hashCode()가 호출되었다.
- key2가 저장될 때, 이미 버킷에 key1이 존재한다. key1과 key2가 동일 객체임을 확인하기 위해 equals()가 호출되었다. false가 return되었을 것이다.
- get(key2)가 호출되고, key2의 버킷인덱스를 찾기 위해 hashCode()가 호출되었다.
- key2의 버킷리스트엔 key1이 이미 있다. key1이 key2와 같은지 확인하기 위해 equals()가 호출되었다.
2) Open Addressing
버킷 자체는 값을 저장하는 그대로 놔두고, 버킷의 비어있는 다른 공간을 활용하는 방식이다. 가장 간단한 Linear Probing 방식의 경우, 저장하고자 하는 버킷 인덱스에 다른 값이 있다면 비어있는 버킷이 나올 때까지 다음 버킷 인덱스를 탐색한다. 최초로 나온 empty 버킷에 value 값을 저장하는 방식이다.
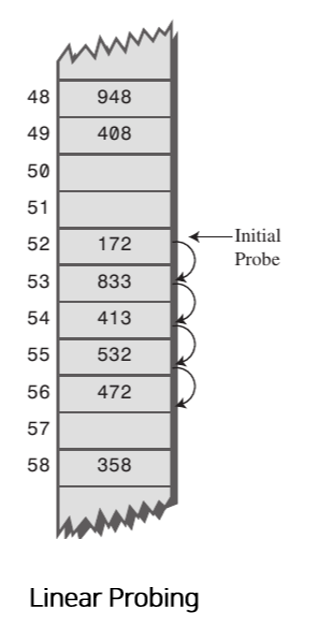
key를 검색할 땐 데이터가 존재하는 연속된 버킷 인덱스에 대해 일치하는 key가 나올때까지 탐색하고, 특정 인덱스의 값을 삭제할 땐 dummy data를 넣거나 인덱스 뒤의 값들을 앞으로 이동시키는 작업이 일어난다.
5. Resizing
자바 HashMap의 생성자는 다음과 같다.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
}기본 capacity는 16이고, 로드팩터 값이 0.75이다. 이는 기본적으로 Map이 16개의 버킷으로 이뤄져 있으며, 로드팩터 값이 0.75를 넘어가면 capacity의 확장이 일어난다는 뜻이다. 로드팩터란 맵에 존재하는 데이터 개수를 맵 전체의 버킷 개수로 나눈 값을 말한다. 간단히 Map 공간의 3/4 이상이 차면 2배의 확장이 일어난다.
HashMap의 노드에는 key, value, next값 이외에 해당 key의 해시값도 들어있어서 확장이 일어날 땐 간단하게 노드의 해시값을 새로운 capacity로 모듈러 연산을 해서 새 인덱스를 구한다.
그러나 resizing 자체가 Map의 모든 요소에 대해 새로운 인덱스 계산을 하고 Node들을 새로이 배치하는 작업이라 오랜 시간이 걸린다. 따라서, Map을 사용할 때 크기가 큰 맵을 사용할 것 같다고 사전에 생각이 들면 생성자로 initial capacity를 주어 resizing 작업을 최소화 시켜주는 것이 좋다.
REFERENCE
https://www.youtube.com/watch?v=ZBu_slSH5Sk&list=PLcXyemr8ZeoR82N8uZuG9xVrFIfdnLd72
