
✍ 코틀린과 친해지자
PS문제를 하나씩 풀다보니 공부가 필요한 문법에 대해서 정리한 글입니다.
들어가기 전
Kotlin으로 PS 문제를 풀 때 항상 빠른 입출력을 활용합니다.
이번 포스트에는 왜 이런 빠른 입출력이 가능하고
어떻게 사용하는 지에 대해 알아보려고 합니다.
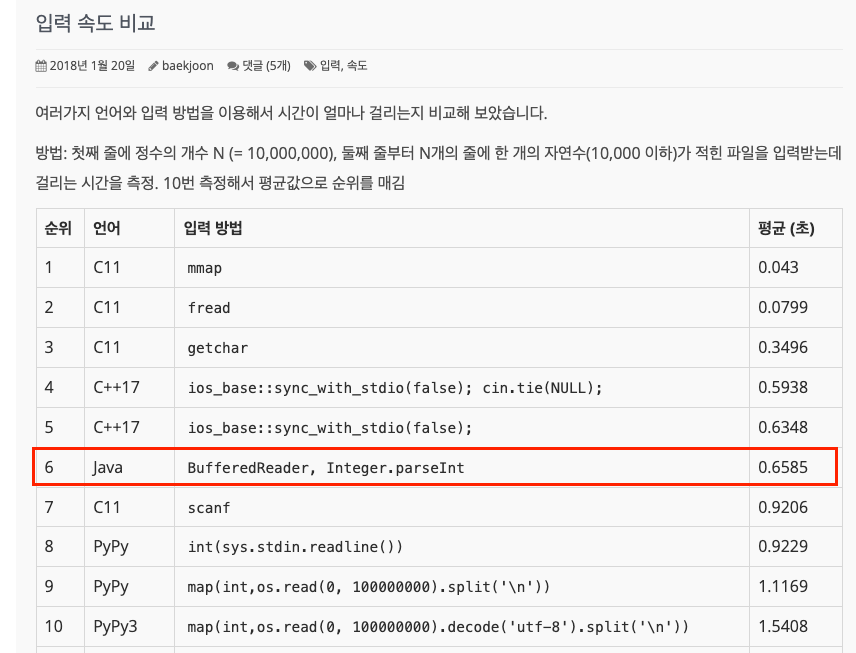

입력에서는
bufferedReader를
출력에서는bufferedWriter,StringBuilder등이 상위권에 포함되어 있습니다.
기본 입출력
코틀린 공식문서에 따르면 표준 입력은 다음 readLine과 Scanner를 정의합니다.
1. readln()
코틀린은 기본적으로 모든 코드가 자바를 근간으로 하기 때문에
자바의 입출력을 따라갑니다.
사용 방법
fun main(){
val n = readLine()
print(n)
}
readLine을 사용하면 문자열로써 받으며
숫자로 입력받기 위해서는 형변환을 통해 바꾸어 주며 받게 됩니다.
또한println이나 줄바꿈이 필요없는 문자에 대해서는하지만 공백 구분은 불가능 하기 때문에 문제에서 공백을 분리해서 받는 경우
fun main(){
val (x,y) = readln().split(" ").map { it.toInt() }
println("$x $y")
}다음과 같이
.split(" ")을 통해 공백을 분리하여 받아주어야 합니다.
그리고 형변환이 필요한 경우.map뒤 스코프를 통해 이것이 int 형이라는 형변환을 통해
x, y를 int형으로 사용할 수 있습니다.
2. Scanner
Scanner는 Java에서의 표준 입출력 방법입니다.
표준 입력에서는 일반적으로System.in객체를 통해 액세스합니다.
사용 방법
import java.util.Scanner
fun main(){
val scanner = Scanner(System.`in`)
val line = scanner.nextLine()
println(line)
}scanner 변수를 하나 만들어 scanner를 호출할 때 nextLine 메서드를 사용하게 되면
한줄을 받게 되며 형에 따라 문자열은next, 정수는nextInt를 사용하게 됩니다.또한
Scanner는 띄어쓰기와 개행문자를 경계로 하여 입력 값을 인식하기 때문에
따로 가공할 필요가 없어 편리합니다.
그래서 바로 원하는 타입의 입력을 받을 수 있습니다.하지만 버퍼 사이즈가 1KB로 1024Byte밖에 받을 수 없으니
많은 입력을 필요로 할 경우에는 성능상 좋지 못합니다.
빠른 입출력
그럼 이제는 빠르게 입출력을 할 수 있도록 도와주는
BufferedReader,BufferedWriter,StringBuilder,StreamTokenizer에 대해서 알아봅시다.
1. BufferedReader/BufferedWriter
이것을 이해하기 위해 먼저
버퍼(buffer)를 이해해봅시다.
버퍼는 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리 영역입니다.
Scanner와 달리BufferedReader는 개행문자만 경계로 인식하고
입력받은 데이터가 String으로 고정됩니다.
즉 버퍼를 사용하지 않는Scanner는 키보드의 입력이 키를 누르는 순간 바로 프로그램에게 전달되지만
버퍼를 사용하는BufferedReader는 키보드의 입력이 있을 때마다 한 문자씩 버퍼로 전송한 후
버퍼가 가득 차거나 줄 바꿈이 나타나면 버퍼에 쌓인 내용을 한 번에 프로그램에 전송합니다.때문에 바로바로 입력을 보내는 것보다 한 번에 보내주는 것이 더 효율적이고
속도차이가 날 수 있는 것입니다.
속도 또한 10,000,000개의 0~1023 범위의 정수를 한 줄씩 읽고,
입력으로 받은 정수의 합을 출력하는 프로그램을 돌렸다고 가정할 때
훨씬 빠르다는 것을 알 수 있습니다.
| 입력 방식 | 수행시간(초) |
|---|---|
| java.io.BufferedReader | 0.934 |
| java.util.Scanner | 6.068 |
그리고 버퍼 사이즈도
Scanner는 1024kb에 비해BufferedReader는 8192kb(16,384byte)이기에
입력이 많을 때 또한 BufferedReader가 유리합니다.
사용 방법
fun main(){
val br = System.`in`.bufferedReader()
val bw = System.`out`.bufferedWriter()
val n = br.readLine()
bw.write("$n")
br.close()
bw.flush()
bw.close()
}먼저 버퍼를 사용하겠다고 선언해야 하기 때문에 br 변수에는 입력인 bufferedReader를
bw 변수에는 출력인 bufferedWriter를 선언해줍니다.그 다음 입력을 받기 위해서
.readLine()메소드를 통해 입력을 받아줍니다.
이후 버퍼에 받아졌다면 .write() 메소드를 통해 출력해줍니다.
이 때 .write 메소드는 문자열로 받아지기 때문에 괄호 안에 변수를 감싸 출력합니다.
버퍼 출력이 끝났다면 버퍼안에 데이터를 비워줘야하는데
.flush()를 통해 비워주고 .close()를 통해 버퍼를 닫아줍니다.
BufferedReader Method
| Method | 설명 |
|---|---|
| .close() | 입력 스트림을 닫고, 사용하던 자원을 방출 |
| .read() | 한 글자만 읽어 정수형으로 반환 |
| .readLine() | 한 줄을 읽음 |
BufferedWriter Method
| Method | 설명 |
|---|---|
| .newLine() | \n의 역할을 함 |
| .flush() | 출력 스트림을 비움 |
| .close() | 출력 스트림을 닫음 |
2.StringBuilder
StringBuilder는 문자열을 다룰일이 많을 때 빠르게 작업할 수 있는 문자 시퀀스입니다.
먼저 이것을 알기 위해 String 문자열의 작업방식을 이해해야합니다.
`String 문자열은 참조 타입으로써 만약 문자열 뒤에 문자열을 추가하는 것 같은 수정하는 작업이 필요하다면
기존 참조하고 있던 곳에 추가하는 것이 아닌 새로 String을 생성 후 참조를 바꾸는 형식입니다.
그렇다면 String 타입으로 문자열 작업을 할 때 비효율적이라는 것이 느껴질 것입니다.
또한 연산이 많아질수록 자원 관리가 어려워질 것입니다.
이때 사용할 수 있는 것이StringBuilder이며 이는 String처럼 참조를 바꾸는 식이 아닌
참조하고 있는 값을 바꾸는 식입니다.
사용 방법
fun main(){
val br = System.`in`.bufferedReader()
val bw = System.`out`.bufferedWriter()
val str = br.readLine()
val sb = StringBuilder()
sb.append(str)
sb.append('a')
print(sb)
}만약 문자열을 하나 받고 그것에 a를 넣어야하는 것을 까먹어서 추가해야 하는 작업을 해야합니다.
StringBuilder()의 빈 생성자를 선언하며
문자열을.append()메서드로 추가하고 한 줄을 받을 때는.appendLine()을 이용하여
문자열 작업을 할 때 속도를 높일 수 있습니다.
3.StreamTokenizer
StreamTokenizer는 입력 스트림을 가져와 Token으로 구문을 분석하여
토큰을 한 번에 하나씩 읽을 수 있도록 합니다.
즉 파일에서 데이터를 읽을 때 각 항목을 토큰단위로 나누어 읽는 자바의 클래스입니다.
StreamTokenizer는 스트림 기반으로 동작하여, 대량의 데이터를 처리할 때
메모리 사용량이 적습니다.
그래서 단순한 입력 처리인 PS문제에서 유용하게 사용할 수 있습니다.
in kotlin
import java.io.InputStreamReader
import java.io.StreamTokenizer
fun main(){
val tokenizer = StreamTokenizer(InputStreamReader(System.`in`))
print("입력 (Ctrl+D 입력 시 종료) : ")
while(true){
val tokenType = tokenizer.nextToken()
when(tokenType){
StreamTokenizer.TT_NUMBER -> {
println("입력이 정수면? : ${tokenizer.nval.toInt()}")
}
StreamTokenizer.TT_WORD -> {
println("입력이 문자열이면? : ${tokenizer.sval}")
}
StreamTokenizer.TT_EOF -> {
println("입력 종료.")
break
}
else -> {
println("Char : '{${tokenizer.ttype.toChar()}}'")
}
}
}
}토큰을 생성하는 방법은
.nextToken()을 통해서 생성할 수 있으며
.nval,.sval,ttype메소드로 토큰을 불러올 수 있습니다.
장점에는 간단한 텍스트 파싱 작업을 빠르게 수행할 수 있어
PS 문제풀이에서 유용합니다.
StreamTokenizer Method
| Method | 설명 |
|---|---|
| .nval | 현재 토큰이 숫자인 경우 해당 값을 double형으로 값을 저장한다. |
| .sval | 현재 토큰이 단어인 경우 해당 값을 문자열로 값을 저장한다. |
그럼 궁극적으로 뭐가 제일 빠를까?
이 글을 다 봤으면 궁금증이 생기지 않나요?
필자의 생각은 전체를 다 합치는 게 가장 빠르지 않을까.. 생각하여
궁극적으로 제일 빠른 입출력을 생각해 보았습니다.
그래서bufferedreader와StreamTokenizer를 합친 코드입니다.
import java.io.StreamTokenizer
fun main() = with(StreamTokenizer(System.`in`.bufferedReader())){
fun nextInt() : Int { nextToken(); return nval.toInt() }
fun nextString() : String { nextToken(); return sval }
val n = nextInt()
println(n)
val str = nextString()
println(str)
}먼저 메인 함수에
with()를 사용하여StreamTokenizer를 불러준 뒤
표준 입력을 나타내며bufferedReader로 래핑해주어StreamTokenizer전달해 줍니다.
이후 메인 함수 안에 정수의 입력을 토큰으로 받을nextInt()를 nval로 반환하는데
이는 Double형으로 반환하니.toInt()를 통해 정수형으로 바꾸어 줍니다.
또nextString함수를 만들어 이는 문자열만 받을 것이니sval로 반환하게 만듭니다.
그래서 변수하나를 입력 받을 때마다 이 함수를 불러오면 가장 빠른 입출력을 받을 수 있습니다.
BOJ 1000
가장 간단한 문제로 입출력 속도를 비교해 보겠습니다.
1. readln
fun main() {
val (a, b) = readln().split(" ").map { it.toInt() }
println(a+b)
}
2. scanner
import java.util.Scanner
fun main(){
val sc = Scanner(System.`in`)
val (a, b) = sc.nextLine().split(" ").map { it.toInt() }
print(a+b)
}
3. bufferedReader
fun main() {
val br = System.`in`.bufferedReader()
val bw = System.`out`.bufferedWriter()
val (a, b) = br.readLine().split(" ").map { it.toInt() }
bw.write("${a + b}")
br.close()
bw.close()
}
4. StreamTokenizer + bufferedReader
import java.io.StreamTokenizer
fun main() = with(StreamTokenizer(System.`in`.bufferedReader())){
fun nextInt() : Int { nextToken(); return nval.toInt() }
val a = nextInt(); val b = nextInt()
print(a+b)
}
속도는 BOJ의 채점 프로그램의 CPU 성능에 따라 달라져
정확한 시간 측정은 어렵지만
필자의 채감 상으로는Scanner<readln<bufferedReader<
StreamTokenizer + bufferedReader순서 였습니다.
문자열을 많이 다룬다면StringBuilder()도 사용해 봅시다!
📌결론
현재 포스트의 빠른 입출력이 정답은 아니지만
PS 문제를 좋아하는 사람의 입장에서 한번은 정리가 필요하다고 생각했습니다.
문제의 의도에 따라 제일 빠른 입출력을 받아봅시다! 😊
참고자료
kotlin Standard input
[Java] 빠른 입출력을 위한 BufferedReader, BufferedWriter, StringTokenizer, StringBuilder
Kotlin StringBuilder - 문자열 효율적으로 다루기
StringBuilder 공식문서
StringTokenizer와 StreamTokenizer(feat.StringTokenizer뜯어보기🔨)
