
학습 샘플
: 추출해 놓은 데이터셋의 85%를 학습에 사용하는 학습샘플
(=트레이닝 샘플, 트레이닝 데이터 셋)테스트 샘플
: 모아놓은 데이터셋의 15% 가량으로 가중치 업데이트마다 성능을 평가하기 위한
데이터로 사용되는 테스트 데이터셋
과소적합
: 인공지능 모델이 학습 샘플의 어떠한 특징이나 복잡성을 파악하지 못하여
분류 상태가 좋지 않은 경우
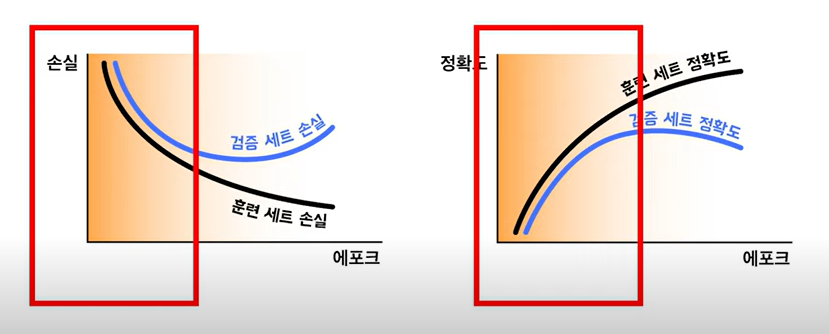
과적합
: 인공지능 모델이 지나치게 학습 샘플과 유사하게 분류하도로고 학습이 되어서
테스트 샘플에 대해서는 성능이 좋지 못한 경우
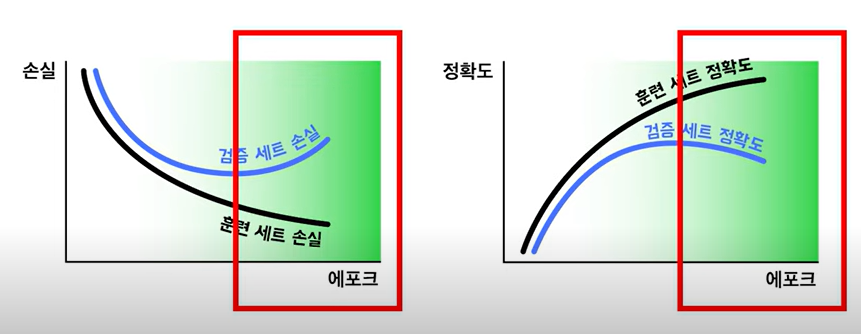
과적합 해결 방법
전체 데이터셋을 85%, 15%로 나누어 비슷한 데이터 샘플끼리 섞일 수 있도록
많은 양의 데이터를 모은다.
성능 향상을 위한 방법
- 배경 소음 데이터 확보하기
- 데이터 수집량 늘리기
- 데이터 특징이 잘 드러나도록 정제하기
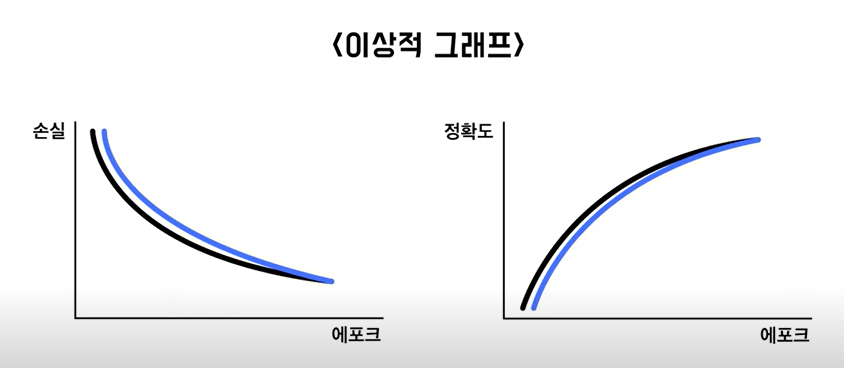
성능 평가 방법
- 정확도 함수 그래프
- 손실 함수 그래프
