Pandas : 가장 유명한 데이터 분석 파이썬 라이브러리
판다스 라이브러리를 사용하려면, 일단 라이브러리를 import 해야한다
import pandas as pddata 만들기
pandas에는 가장 핵심이 되는 두 가지 데이터 형식이 있다.
바로 DataFrame과 Series이다
DataFrame
DataFrame = 표
DataFrame은 일종의 표이다.
데이터프레임에는 각각의 특정 값을 갖는 개별 entry 의 배열이 있다.
각 entry는 행(또는 레코드)와 열(column)에 해당한다.
예시 :
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})[결과]
| Yes | No | |
|---|---|---|
| 0 | 50 | 131 |
| 1 | 21 | 2 |
이 예시에서, "0, No" entry는 131이라는 값을 갖는다.
"0, Yes" entry는 50의 값을 갖는다.
등등
DataFrame의 entry들은 정수만 될 수 있는 것은 아니다.
예를 들어, entry 값은 문자열이 될 수도 있다 :
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})[결과]
| Bob | Sue | |
|---|---|---|
| 0 | I liked it. | Pretty good. |
| 1 | It was awful. | Bland. |
pd.DataFrame() 생성자로 이런 DataFrame 객체를 만들 수 있다.
이 예시에서 새 객체를 선언하는 구문은
- key : "열 이름" (Bob, Sue)
- value : entry 리스트
이게 바로 새로운 데이터프레임을 생성하는 표준 방법이자 가장 흔하게 접할 수 있는 방법이다.
dictionary-list 생성자는 값들을 column label들에 할당한지만,
row label에는 0부터 시작하는 오름차순 개수만 사용한다.
가끔은 이게 괜찮지만, 우리는 종종 이 label들을 내 마음대로 설정하고 싶을 것이다.
DataFrame에 사용되는 row label 리스트를 Index라고 한다.
생성자에서 index 파라미터를 사용하여 값을 할당할 수 있다 :
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])[결과]
| Bob | Sue | |
|---|---|---|
| Product A | I liked it. | Pretty good. |
| Product B | It was awful. | Bland. |
Series
반면, Series는 데이터 값들의 연속이다.
DataFrame이 표라면,
Series = list
실제로, list만으로 Series를 만들 수 있다.
pd.Series = ([1, 2, 3, 4, 5])[결과]
0 1
1 2
2 3
3 4
4 5
dtype: int64Series의 본질은 DataFrame의 단일 column이다.
따라서, index 파라미터를 사용하여 DataFrame과 동일한 방법으로 Series에 row label을 할당할 수 있다.
그러나 Series에는 열 이름이 없고, 그 자체를 일컫는 하나의 이름만 있다.
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')[결과]
2015 Sales 30
2016 Sales 35
2017 Sales 40
Name: Product A, dtype: int64
Series와 DataFrame은 밀접하게 연관되어 있다.
DataFrame을 실제로 "함께 붙어있는" Series의 묶음으로 생각하면 된다.
data file 읽어오기
DataFrame이나 Series를 직접 만들 수 있다는 건 매우 편리한 일이지만,
대부분의 경우 직접 만들지 않고 이미 있는 데이터로 작업한다.
가장 기본적인 것은 CSV 파일이다.
이름에서도 알 수 있듯, CSV(Comma-Separated Values) 파일은 쉼표로 구분된 값들의 표이다.
ex)
Product A,Product B,Product C,
30,21,9,
35,34,1,
41,11,11pd.read_csv() 함수를 이용하면 실제 csv 데이터셋을 DataFrame 형태로 읽을 수 있다.
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")또, shape 속성을 통해 데이터프레임의 크기를 알 수 있다.
wine_reviews.shape[결과] (129971, 14)
이 데이터프레임에는 14개의 서로 다른 열에 걸쳐 약 13만개의 레코드가 분할되어 있는데,
이는 거의 2백만 개의 entry이다.
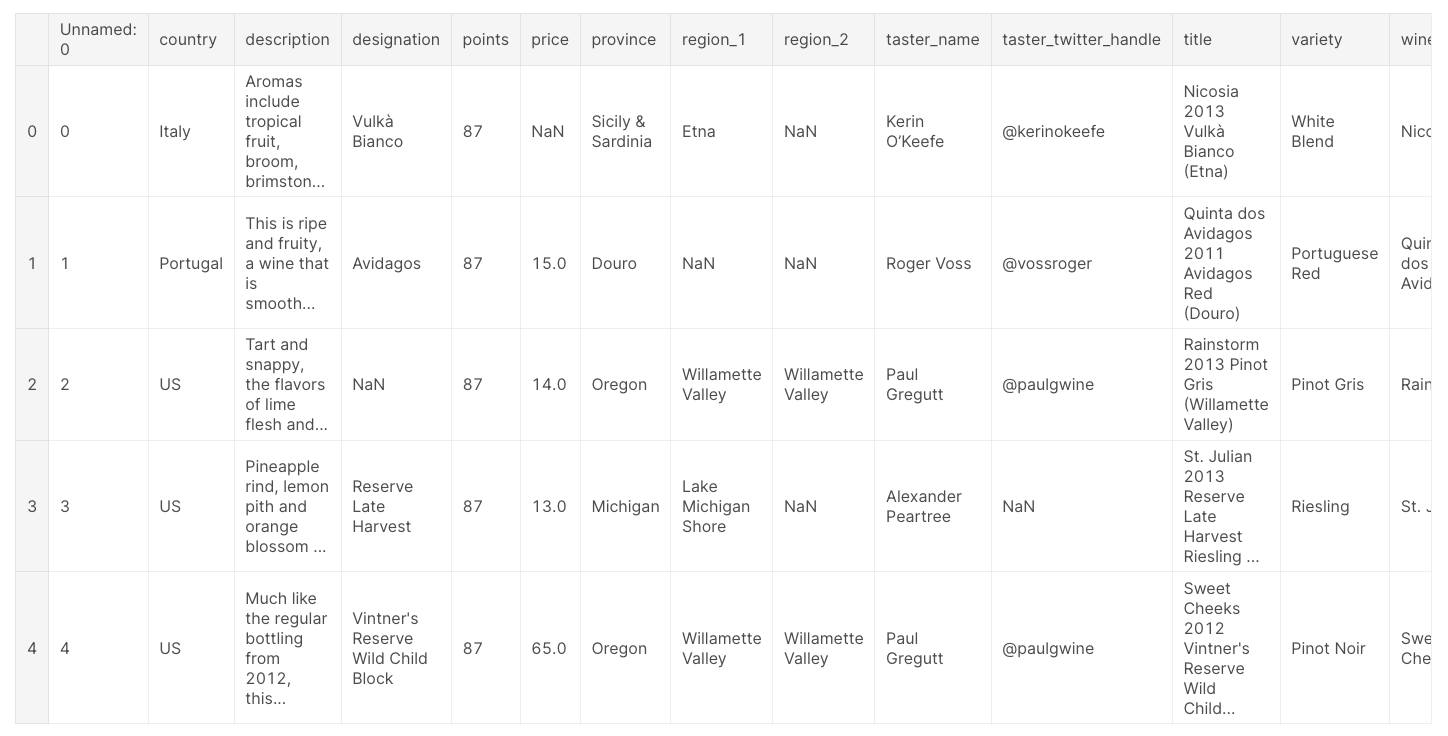
DataFrame의 내용을 검사할 땐 head()를 이용하여 첫 5개의 행에 대한 값을 표로 가져올 수 있다.
head() 함수 내부에 숫자 값(N)을 넣으면 처음부터 N개의 행을 가져온다는 뜻이다.
wine_reviews.head()[결과]
pd.read_csv() 함수에는 지정할 수 있는 30개 이상의 파라미터가 있다.
예를 들어, 이 데이터셋에서 CSV 파일에 Pandas가 자동으로 지정하지 않는 내장 index가 있음을 확인할 수 있다.
Pandas가 index에 해당 열을 사용하도록 하려면, 처음부터 새 열을 만드는 대신 index_col을 지정할 수 있다.
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()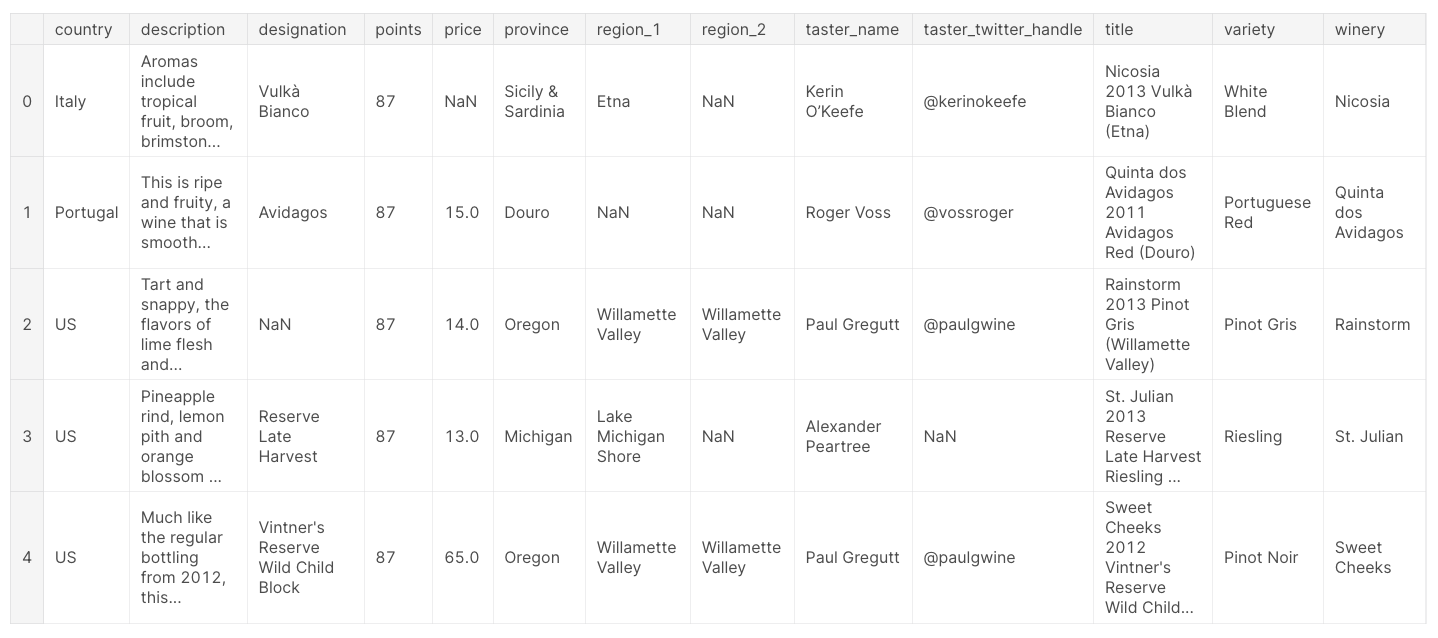

2개의 댓글

The foundation of Pass4early's offering is their extensive collection of SSCP Exam Questions. With a staggering 1074 questions and answers, their PDF resource provides an in-depth review of the entire syllabus. This wealth of content is not only comprehensive but also regularly updated and verified by skilled industry experts. By studying these materials, you can be confident that you are learning from a source that is both current and aligned with the actual exam content.
https://www.pass4early.com/SSCP-questions.html
It seems like you're diving into the basics of Pandas, which is an excellent choice for data analysis! While the tutorial covers the foundational steps for creating, reading, and writing data with Pandas, for those who might also need help in structuring academic or professional reports involving data analysis, websites https://literaturereviewwritingservice.com/ like this one could be beneficial. They provide services for literature reviews and other academic writing tasks, which might come in handy when you're preparing research papers that require data handling and interpretation. Both learning Pandas and mastering research writing are essential skills!