MNIST Classification with MLP
MNIST : 사람의 손글씨(0~9)의 이미지를 저장하고 있는 데이터셋
Torchvision
- PyTorch를 설치하면 자동으로 따라 설치되는 library
- computer vision 관련 도구들을 모아놓은 library
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
dataset = datasets.MNIST(root='data', train=True, download=True) # 해당 디렉토리에 'data'라는 폴더를 새로 만들고 그 안에 데이터셋을 다운로드 받음Looping on MNIST Dataset
from torchvision.datasets import MNIST
dataset = MNIST(root='data', train=True, download=True)
# MNIST 클래스는 dataset object를 만들어주고
# dataset object는 for loop을 돌면서 이미지와 정답을 돌려줌
for img, label in dataset:
print(type(img)) # <class 'PIL.Image.Image'>
print(type(label)) # <class 'int'>
break결과:
<class 'PIL.Image.Image'>
<class 'int'>
Image 확인해보기
이미지를 다룰 때 PIL.Image를 그대로 사용하지 않고, PyTorch의 Tensor나 NumPy의 ndarray로 바꿔서 사용함
from torchvision.datasets import MNIST
dataset = MNIST(root='data', train=True, download=True)
for img, label in dataset:
img.show() # PIL의 Image 객체는 show라는 메서드를 가지고 있고, 이를 실행하면 이미지가 뜸
print(type(label))
break결과 :<class 'int'>
Image 스펙 살펴보기
import numpy as np
from torchvision.datasets import MNIST
dataset = MNIST(root='data', train=True, download=True)
for img, label in dataset:
img = np.array(img)
print(img.shape, img.dtype) # (28, 28) uint8
break
# (28, 28)의 이미지가 uint8로 들어있는 것을 알 수 있음
# 즉, feature가 28 * 28 = 784개인 데이터결과 :
(28, 28) uint8
샘플 이미지 확인해보기
import matplotlib.pyplot as plt
from torchvision.datasets import MNIST
dataset = MNIST(root='data', train=True, download=True)
fig, axes = plt.subplots(2,5, figsize=(10,5))
for ax_idx, ax in enumerate(axes.flat):
img, label = dataset[ax_idx]
ax.imshow(img, cmap = 'gray')
ax.set_title(f"Class {label}", fontsize=15)
ax.axis('off')
if ax_idx >= 9: break
fig.tight_layout()
plt.show()
Dataset Preparation
ToTensor는 데이터를 PIL.Image 객체가 아니라 PyTorch의 Tensor 객체로 자동으로 변환해줌
- [참고] uint8에서 normalization해줘서 float32로 자동으로 변환해주는 기능 포함
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
BATCH_SIZE = 32
dataset = MNIST(root='data', train=True, download=True, transform=ToTensor())
dataloader = DataLoader(dataset, batch_size = BATCH_SIZE)
n_samples = len(dataset)len(dataset)은 데이터셋에 들어있는 전체 샘플의 개수
Model Implementation
import torch.nn as nn
class MNIST_Classifier(nn.Module):
def __init__(self):
super(MNIST_Classifier, self).__init__()
self.fc1 = nn.Linear(in_features = 784, out_features = 512)
self.fc1_act = nn.ReLU()
self.fc2 = nn.Linear(in_features = 512, out_features = 128)
self.fc2_act = nn.ReLU()
self.fc3 = nn.Linear(in_features = 128, out_features = 52)
self.fc3_act = nn.ReLU()
self.fc4 = nn.Linear(in_features = 52, out_features = 10)
def forward(self, x):
x = self.fc1_act(self.fc1(x))
x = self.fc2_act(self.fc2(x))
x = self.fc3_act(self.fc3(x))
x = self.fc4(x)
return xTraining Setting
import torch
from torch.optim import SGD
LR = 0.003
EPOCHS = 10
if torch.cuda.is_available(): DEVICE = 'cuda'
elif torch.backends.mps.is_available() : DEVICE = 'mps'
else: DEVICE = 'cpu'
model = MNIST_Classifier().to(DEVICE)
loss_function = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=LR)Training
losses, accs = [], []
for epoch in range(EPOCHS):
epoch_loss, n_corrects = 0., 0
for X_, y_ in dataloader:
X_, y_ = X_.to(DEVICE), y_.to(DEVICE)
X_ = X_.reshape(BATCH_SIZE, -1)
pred = model(X_)
loss = loss_function(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() * len(X_)
n_corrects += (torch.max(pred, axis=1)[1]==y_).sum().item()
epoch_loss /= n_samples
losses.append(epoch_loss)
epoch_acc = n_corrects / n_samples
accs.append(epoch_acc)
print(f"Epoch: {epoch+1}")
print(f"Loss: {epoch_loss:.4f} - Acc: {epoch_acc:.4f}")결과 :
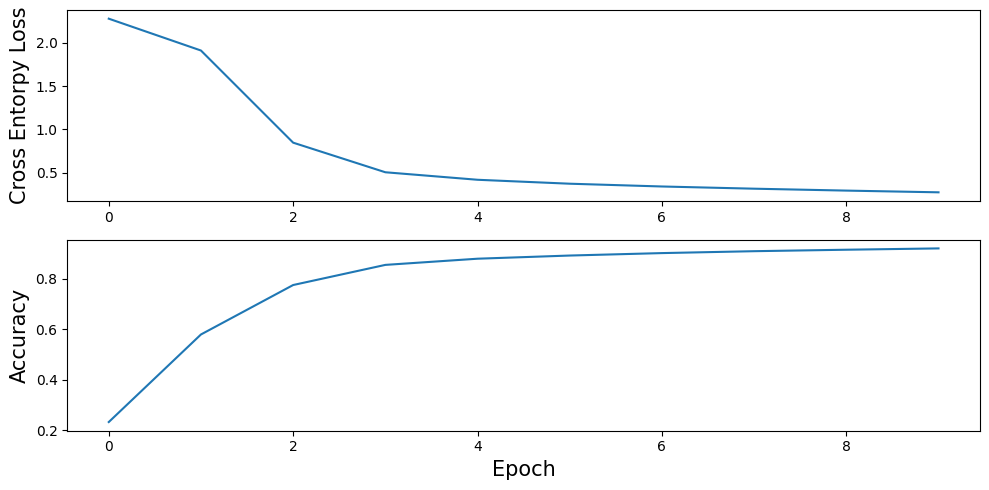
Epoch: 1
Loss: 2.2750 - Acc: 0.2319
Epoch: 2
Loss: 1.9084 - Acc: 0.5794
Epoch: 3
Loss: 0.8476 - Acc: 0.7756
Epoch: 4
Loss: 0.5069 - Acc: 0.8556
Epoch: 5
Loss: 0.4205 - Acc: 0.8801
Epoch: 6
Loss: 0.3751 - Acc: 0.8927
Epoch: 7
Loss: 0.3431 - Acc: 0.9024
Epoch: 8
Loss: 0.3177 - Acc: 0.9099
Epoch: 9
Loss: 0.2958 - Acc: 0.9157
Epoch: 10
Loss: 0.2760 - Acc: 0.9210
Visualization
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 1, figsize=(10, 5))
axes[0].plot(losses)
axes[1].plot(accs)
axes[1].set_xlabel("Epoch", fontsize=15)
axes[0].set_ylabel("Cross Entorpy Loss", fontsize=15)
axes[1].set_ylabel("Accuracy", fontsize=15)
axes[0].tick_params(labelsize=10)
axes[1].tick_params(labelsize=10)
fig.tight_layout()
plt.show()결과:
tqdm
- tqdm을 사용하면 epoch에 대한 학습 경과를 보여준다
- conda install -c conda-forge tqdm
- [참고] Colab에는 tqdm이 자동으로 깔려있음
<training 코드 수정>
from tqdm import tqdm
losses, accs = [], []
for epoch in range(EPOCHS):
epoch_loss, n_corrects = 0., 0
for X_, y_ in tqdm(dataloader):
X_, y_ = X_.to(DEVICE), y_.to(DEVICE)
X_ = X_.reshape(BATCH_SIZE, -1)
pred = model(X_)
loss = loss_function(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() * len(X_)
n_corrects += (torch.max(pred, axis=1)[1]==y_).sum().item()
epoch_loss /= n_samples
losses.append(epoch_loss)
epoch_acc = n_corrects / n_samples
accs.append(epoch_acc)
print(f"Epoch: {epoch+1}")
print(f"Loss: {epoch_loss:.4f} - Acc: {epoch_acc:.4f}")
FashionMNIST Classification with MLP
FashionMNIST Dataset
: 옷 이미지를 분류하는 MLP 모델 만들기
- 이 때, 최대한 코드를 함수로 만들어 main.py를 간단히 만들기
utils.py
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
def get_dataset(batch_size):
dataset = FashionMNIST(root='data', train=True, download=True, transform=ToTensor())
def train(dataloader, n_samples, model, loss_function, optimizer, device):
epoch_loss, n_corrects = 0. , 0
for X_, y_ in tqdm(dataloader):
X_, y_ = X_.to(device), y_.to(device)
X_ = X_.reshape(X_.shape[0], -1)
# batch_size를 입력받지 않고, X_를 이용하여 샘플 수 계산
pred = model(X_)
loss = loss_function(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() * len(X_)
n_corrects += (torch.max(pred, axis=1)[1] == y_).sum().item()
epoch_loss /= n_samples
epoch_acc = n_corrects / n_samples
return epoch_loss, epoch_acc
def vis_losses_accs(losses, accs):
fig, axes = plt.subplots(2, 1, figsize=(10, 5))
axes[0].plot(losses)
axes[1].plot(accs)
axes[1].set_xlabel("Epoch", fontsize=15)
axes[0].set_ylabel("Cross Entorpy Loss", fontsize=15)
axes[1].set_ylabel("Accuracy", fontsize=15)
axes[0].tick_params(labelsize=10)
axes[1].tick_params(labelsize=10)
fig.tight_layout()
plt.show()
models.py
import torch.nn as nn
class FashionMNIST_Classifier(nn.Module):
def __init__(self):
super(FashionMNIST_Classifier, self).__init__()
self.fc1 = nn.Linear(in_features=784, out_features=512)
self.fc1_act = nn.ReLU()
self.fc2 = nn.Linear(in_features=512, out_features=128)
self.fc2_act = nn.ReLU()
self.fc3 = nn.Linear(in_features=128, out_features=52)
self.fc3_act = nn.ReLU()
self.fc4 = nn.Linear(in_features=52, out_features=10)
def forward(self, x):
x = self.fc1_act(self.fc1(x))
x = self.fc2_act(self.fc2(x))
x = self.fc3_act(self.fc3(x))
x = self.fc4(x)
return xmain.py
import torch
import torch.nn as nn
from torch.optim import SGD
from utils import get_dataset, train, vis_losses_accs
from model import FashionMNIST_Classifier
BATCH_SIZE = 8
LR = 0.01
EPOCHS = 100
if torch.cuda.is_available(): DEVICE = 'cuda'
elif torch.backends.mps.is_available(): DEVICE = 'mps'
else: DEVICE = 'cpu'
dataloader, n_samples = get_dataset(BATCH_SIZE)
model = FashionMNIST_Classifier().to(DEVICE)
loss_function = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=LR)
losses, accs = [], []
for epoch in range(EPOCHS):
epoch_loss, n_corrects = 0., 0
epoch_loss, epoch_acc = train(dataloader, n_samples, model, loss_function, optimizer, DEVICE)
accs.append(epoch_acc)
print(f"Epoch: {epoch + 1}")
print(f"Loss: {epoch_loss:.4f} - Acc: {epoch_acc:.4f}")
vis_losses_accs(losses, accs)
호랑이기운