S3 파일명 특수문자 Issue
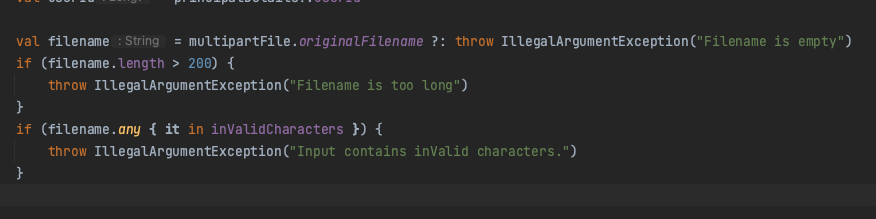
S3에 파일을 업로드했는데, 특정 파일이 호스팅이 되지 않는 이슈가 있다. 찾아보니, "+" 문자열이 원인이었다. 이밖에도 여러가지 인코딩이 필요한 특수문자 리스트가 있는데, AWS 공식문서에서 잘 나와있다.
https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/object-keys.html
공식문서에 언급된 가급적 피해야 되는 특수문자를 제외하고는 모든 특수문자를 허용하기로 했다. 원래는 DB나 S3에 전부 유니코드로 인코딩 한 후 저장을 할려 했으나, 직관적으로 한글 데이터를 확인할 수 없으니 불편할 것으로 예상되었다. 따라서 그대로 저장시키고 프론트단에서만 재생이 필요한 특정 라이브러리 호출 시 UTF-8 로 인코딩한 후 호출하는 걸로 합의를 봤다.

Wechat Oauth CORS Issue
wechat openPlatform을 이용해 소셜 로그인을 구현 중, 몇 가지 문제에 부딪혔다. 기존에 연동된 다른 소셜 로그인과 달리 엑세스 토큰을 받아는 오는데, 브라우저에서 가져오지 못하는 것이었다.
Access to fetch at '위쳇서버' from origin '우리쪽 웹 서버' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.문제는 역시 Same-Origin Policy 때문에, 받아올려면 요청한 위챗 서버에서 Access-Control-Allow-Origin header에 우리쪽 도메인을 넣어주던가, no-cors 로 비활성화 시키던가 해야된다. 그래서 Same-Origin Policy가 걸리는 브라우저가 아닌 서버 측에서 요청해서 accessToken을 받아오는 걸로 결정했다.
기존 다른 socialLogin들은 모두 최종적으로 프론트사이드에서 AccessToken만 전달해주면 벡엔드 사이드에서 그 토큰을 가지고 유정정보를 조회한 뒤 우리 쪽 DB와 검증하는 절차로 구현하였다. 프론트사이드에서 토큰을 가지고 로그인 api 를 호출하면, 우리 쪽 DB에 매칭되는 정보가 없으면 익셉션을 떨군다. 그럼 프론트는 다시 자동으로 회원가입 api를 호출해서, 회원가입 절차를 맞추고 로그인을 시도하게끔 설정되어있었다.
위챗은 QR 창을 띄워서 인증하면 code를 주는데, 이를 통해 accessToken을 조회할 수 있다. 처음에는 이 code를 재활용하려고 했는데, 안타깝게도 code가 1회용이라, 한번 조회를 하면 더 이상 쓸 수 가 없다. 그래서 최초 로그인 시도 시 유저정보가 없다면 익셉션을 떨구는데, 위챗의 경우, 에러의 바디에 AccessToken과 openId를 같이 떨구기로 결정했다. 프론트는 그 에러정보를 받아들여서 회원가입 API를 호출할 때 AccessToken과 openId 2개를 전달해주는 식으로, 위챗만 분기처리를 시켰다.
다른 소셜 로그인들과 통일되지 않는 규격 때문에 찜찜하긴 한데, 그나마 이 방법이 코드 변경 최소로 최대한 빠르게 구현방안이라 생각해 그렇게 구현했다.
https://evan-moon.github.io/2020/05/21/about-cors/
어노테이션을 활용한 AOP
DB에서 정보를 긁어와 엑셀파일로 내려주는 API 를 제공해주고 있는데, 이 로직이 여러 엔드포인트로 늘어남에 따라 중복코드가 발생하였다. 따라서 핵심 비즈니스 로직(해당 데이터를 찾아서 가져오는) 을 제외한 부가 로직(파일 다운로드)을 어노테이션과 런타임 프록시 객체를 사용해 분리하기로 했다.
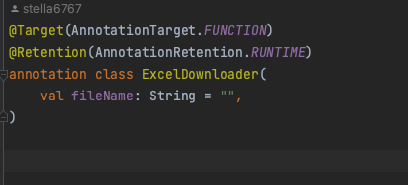
- 먼저 어노테이션을 하나 만들었다.
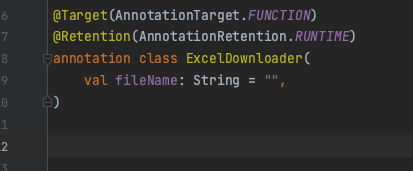
- 런타임 프록시(스프링 AOP)를 활용해, 부가로직을 담당하게 하였다.
- 파일을 다운로드 받는 엔드포인트 함수들에 붙여준다.
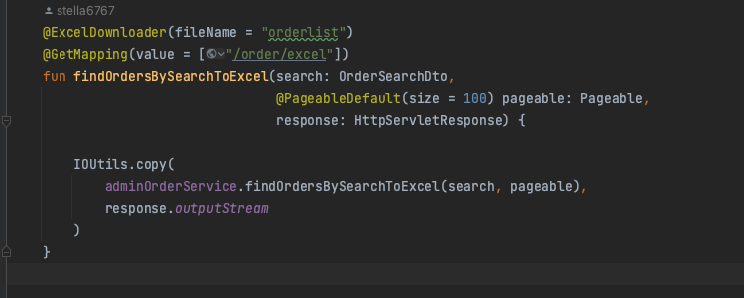
JDBC BatchUpdate 실행이 안 됨
Bulk insert를 위해서 JDBCTemplate의 batchUpdate를 이용해 함수를 하나 만들었다. 문제는 이 함수가 AWS Aurora/MySql 을 대상으로 했을 시 값을 뱉어내지 않고 무한로딩한다. (Local에 설치한 MariaDB는 잘 됨) 로그를 봐도 에러로그를 뿜어내지 않고, 중간에서 커넥션을 계속 문 채로 대기만 하고 있다. 이유가 뭘까.. 일단 JPA의 saveAll()을 사용하는 것으로 대체를 하긴 했는데, saveAll 메소드를 쓴다고 해도 트랜잭션을 재활용한다 뿐이지, 하나씩 쿼리가 실행되는 건 똑같다 보니, 만족스러운 해결책은 아니다. 그러다 원인을 알아냈는데,
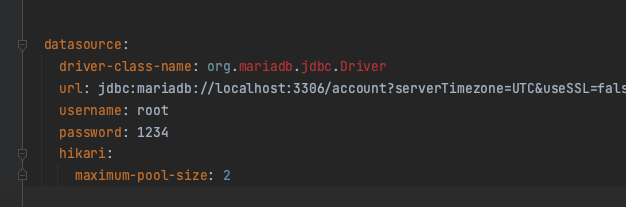
결론은 Driver 문제이다..
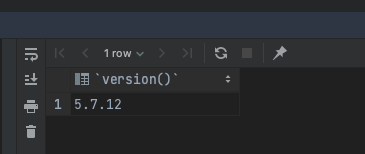
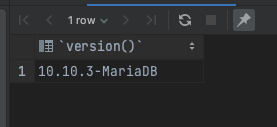
대부분 MariaDB Driver로도 Mysql 잘 호환돼서 MariaDB Driver로 사용하고 있었는데, 결국 100% 호환을 장담해주지는 않더라.
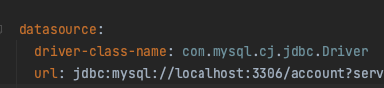
Mysql Driver로 교체해주고, Local도 운영환경의 DB 버전과 맞췄다.
due to: Unable to resolve name [org.hibernate.dialect.MySQL5InnoDBDialect] as strategy [org.hibernate.dialect.Dialect]
database-platform: org.hibernate.dialect.MySQLDialect 로 변경해주었다.. (springboot 2.7.6)는 저 방언으로도 잘 되는데, 다른 서버는(springboot 3.1.5) 는 에러로그를 뿜어내며 종료된다. 일단 스프링부트 버전 문제에 따른 호환성 이슈인 걸로 판단되는데 정확하지는 않다.
@TransactionalEventListener 핸들링
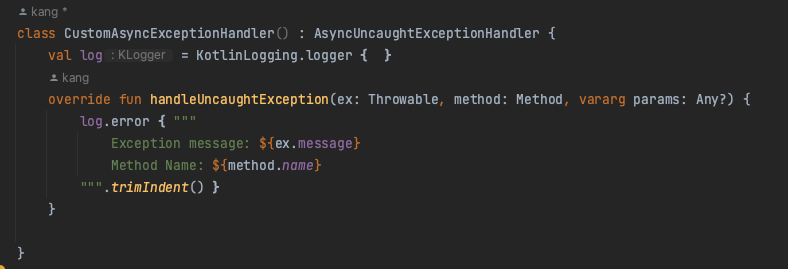
PG 서버에서 Callback 으로 결제 결과를 받으면 그 결과를 우리 쪽 DB에 저장시키고 이 후 이 결과를 바탕으로 처리를 하는 로직이 있다. 받은 정보를 바탕으로 처리하는 로직의 실패여부는 제쳐두고, PG 서버에서 온 데이터는 무조건 저장시키기로 하였기에, 받은 결과를 바탕으로 후 처리하는 로직을 별도의 함수로 분리하고, @TransactionalEventListener 를 활용해, 기존 트랜잭션과 별도로 분리를 하였다.
예외가 먹힌다..
관련 이슈는 아래링크에 자세히 설명되어있다.
https://lenditkr.github.io/spring/transactional-event-listener/index.html
나는 @Async 를 활용해, 비동기로 실행해서, 비동기익센션핸들러에서 로그를 찍게끔 처리했다.
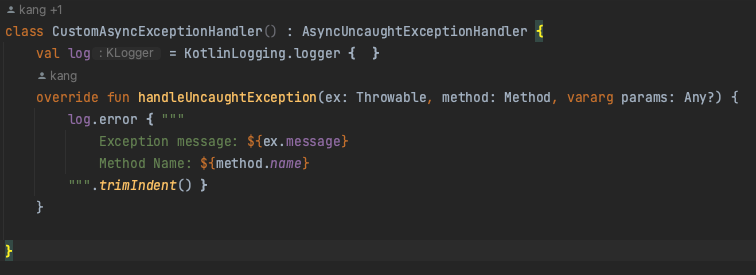
Propagation.REQUIRES_NEW
또 다른 문제는 이벤트를 받는 메서드에서 @Transactional를 달아줬음에도 DB에 저장 및 수정이 일어나지 않는다는 것이었다. 원인은 아래 링크에서 찾을 수 있었다. @TransactionalEventListener의 기본 설정 AFTER_COMMIT (default) 이므로, 커밋이 이미 끝나고 이벤트리스너 함수가 실행하니, 여기에 트랜잭션을 달아도 아무 소용이 없는 것이다. REQUIRES_NEW 옵션으로 주어진 범위에 대해 독립적인 새로운 트랜잭션을 시작하겠다고 선언하면 제대로 작동된다.
근데 딱히 해결책을 고민할 필요는 없었던 게 Propagation 옵션과 상관없이 비동기로 실행하니 @Transactional 만으로 잘 동작한다. @Transactional 전파 범위는 다른 스레드에게까지 미치지 않으니, @Async를 불여주는 것만으로도 해결 완료
https://newwisdom.tistory.com/75
그리고 항상 프록시를 활용한 스프링 마법을 사용할 때는 self-invocation 문제를 주의해야된다. @Transactional에도 당연히 그 문제가 존재하고, 이번에 테스트하면서 나도 헷갈려서 몇 번 실수를 하였다.
https://hungseong.tistory.com/81
https://findstar.pe.kr/2022/09/17/points-to-consider-when-using-the-Spring-Events-feature/
Dynamic Query 적용을 위한 노력들
개인적으로 API를 만들 때, 나는 유연한 API 설계를 지향한다. 물론 유연하게 만든다는 것이 꼭 장점만 있는 것은 아니다. 하지만 어쨌든 나는 중복 코드를 매우 싫어하는 놈이니, 해당 API를 가능한 유연하게 만들어서 최대한 재활용할 수 있도록 노력하는 편이다. 이렇게 하는 이유 중 하나는 나의 귀찮음을 해소하기 위해서도 있다. 프론트엔드 측에서 해당 API 를 통해 데이터를 뽑아올 수 있는 선택의 폭이 넒어짐에 따라, 특정 요구 조건을 구현할 때, 자체적으로 해결할 수 있게끔 유도하는 편이다. 예를 들어서 User List를 찾는다고 했을 때,
검색
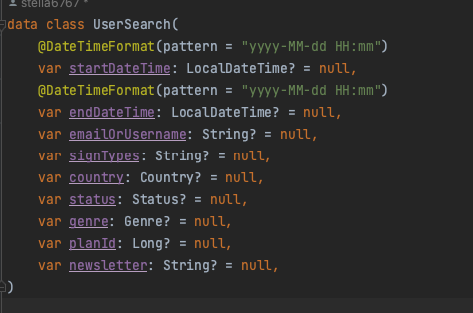
검색파라미터로 받을 DTO를 정의해준다. 전부 nullable 한 타입으로 만들어 준다. 알다시피 QueryDsl의 BooleanExpression을 활용하면 null 값을 무시할 수 있다. 참 편한 기능이다.
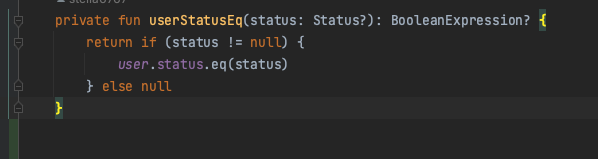
아무튼 요런 메서드들을 전부 정의해준 다음, Array<Predicate?>를 반환하는 통용 검색 메서드 하나를 정의해준다.
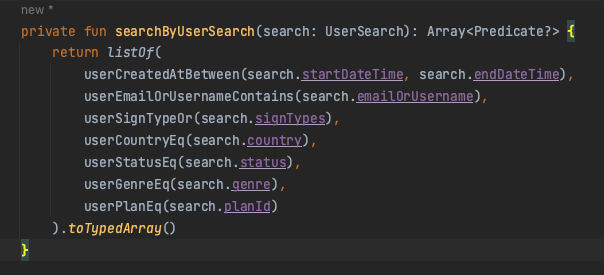
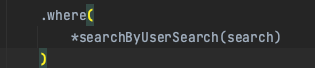
Sorting By Pageable
org.springframework.data.domain에는 Pageable 이라는 표준 인터페이스가 선언되어있다. 인터페이스를 까보면, sort 변수를 가져올 수 있다는 걸 알 수 있다. 이걸 활용해서 다이나믹하게 데이터를 sorting 할 수 있다.
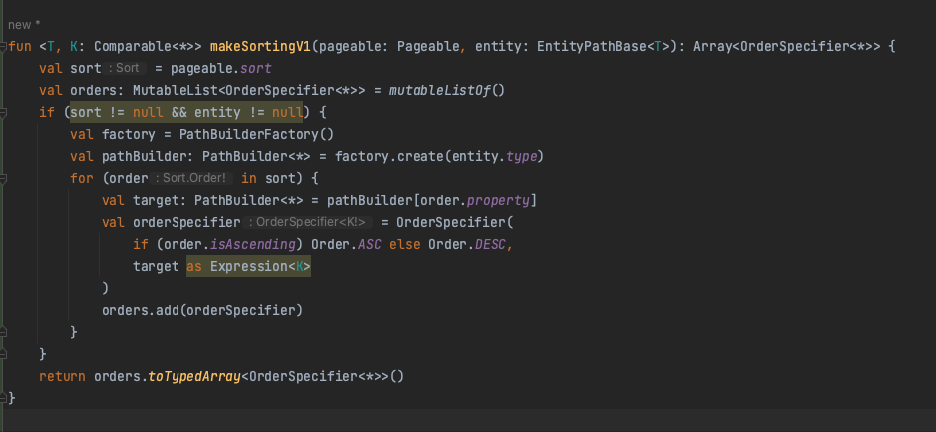
테스트를 해보면, 잘 동작하는 걸 확인할 수 있다.
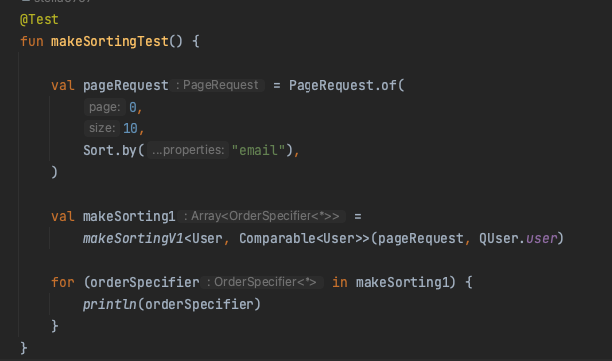
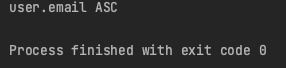
하지만 만약 엔티티 하나의 필드들을 Sorting 하는 게 아닌, 여러 엔티티를 조인해서 들고와야 하는 상황에도 동작시키고 싶으면?
리플렉션을 활용해서, 타입의 필드 이름들을 조회해 일치하는 것만 포함시키도록 조건을 걸어줄 필요가 있다.
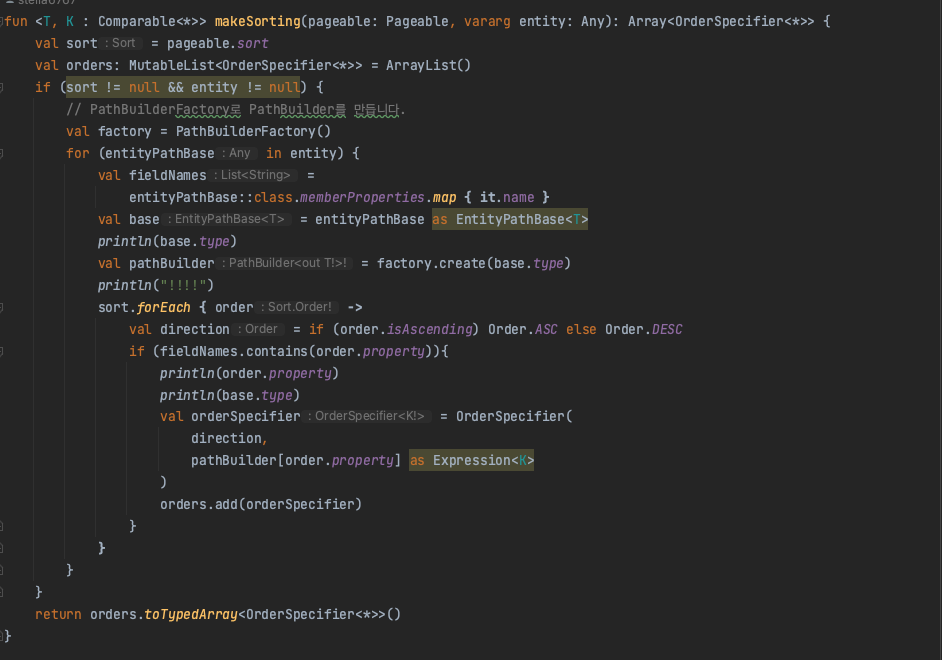
특정 큐 타입 객체의 필드명과, sorting으로 건네준 order 파라미터의 이름이 일치해야지만 추가하도록 조건문을 걸어줬다.
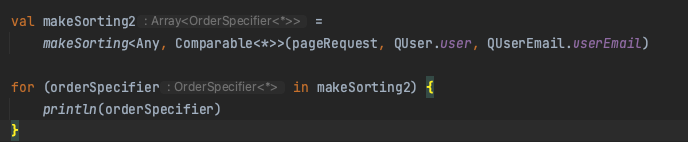
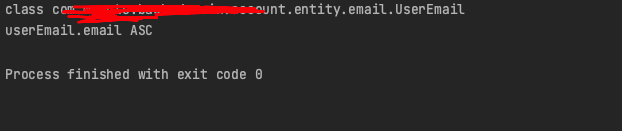
user 엔티티에는 email이라는 이름의 필드가 없으므로, userEmail의 email을 타겟팅하도록 추가된 것을 확인할 수 있다.

LocalDateTime 반올림 이슈
https://lenditkr.github.io/MySQL/fractional-seconds-rouding-problem/
WebClient 병렬처리
https://sunghs.tistory.com/142
io.netty.handler.timeout.ReadTimeoutException: null
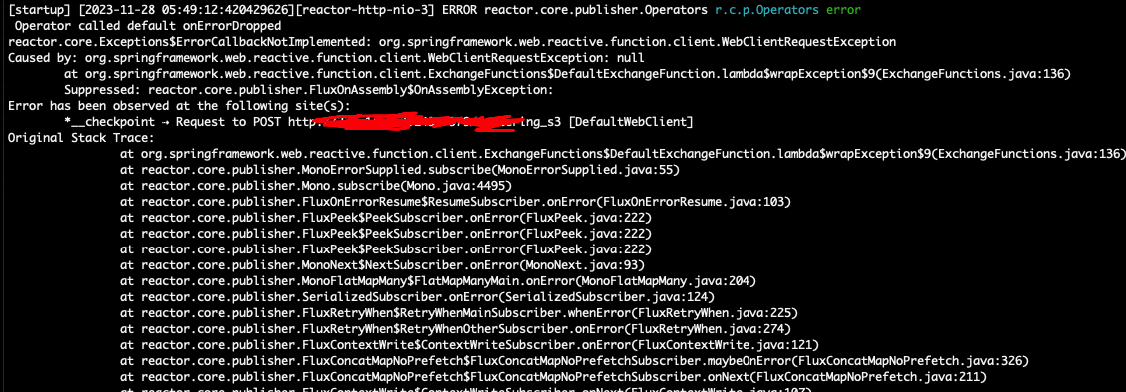
https://stackoverflow.com/questions/51433079/operator-called-default-onerrordropped-on-mono-timeout
해외 국가 차단 (CloudFront)
기존의 개발 서버 도메인으로 웹 사이트를 운영하고 있는데, 아무래도 전세계에서 접근가능하다보니, 외부 접근을 막아놓을 필요가 생겼다. 근데 아무래도 글 쓰는 게 힘들다. 별거 아닌 것에도 글 쓰는 게 너무 힘들어서 중단..
Conflicting getter definitions for property
MediaConvert State Listner SNS CloudWatch
https://devel-repository.tistory.com/20
https://github.com/aws/aws-sdk-java
미디어컨버팅 sdk는 비동기로 작동한다. 따라서 결과가 실패했는지 성공했는지 우리 쪽 DB에 기록하려고, 소스코드 내에서 while 문으로 결과를 알아올 때까지 blocking 하는 구문을 작성했다. 이번엔 cloudWatch를 통해서, 결과를 AWS SNS 와 연동해서 업데이트하도록 변경
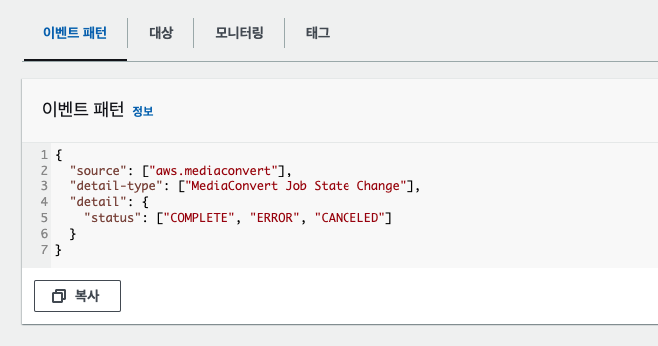
Connection prematurely closed BEFORE response
https://alden-kang.tistory.com/48
jstack Thread Dump
sudo jstack 174541 > thread.dump스레드 덤프 뜬 파일을 아래 사이트에 올려주면 편하게 시각적으로 확인할 수 있다.
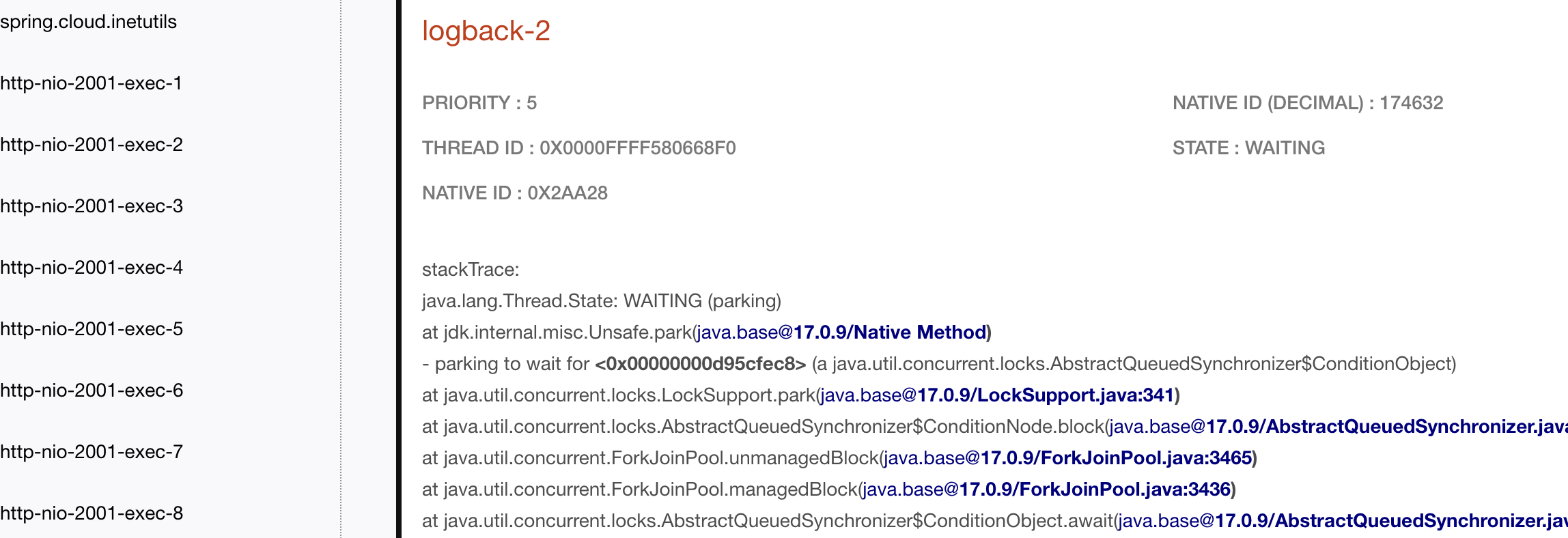
로그파일 작업 스레드에서 wating 이 무한으로 길어지면서 CPU 사용률 100%까지 치닫는 문제로 파악. 로그 파일경로와 파일명이 서로 다른 프로세스에서 중복 적용되고 있는 걸로 파악. 수정하고 재배포 하니 동일한 이슈가 생기지 않았다.
OOM Issue
파일 업로드를 하고 처리하는 API 의 부하테스트(Jmeter)를 진행했다. 대략 100MB 정도의 파일을 하나 잡고 동시 40건을 실행하니 3건 정도는 실패가 뜨더라. 로그를 안 봐도 에러원인은 아주 쉽게 짐작을 할 수 있었다.
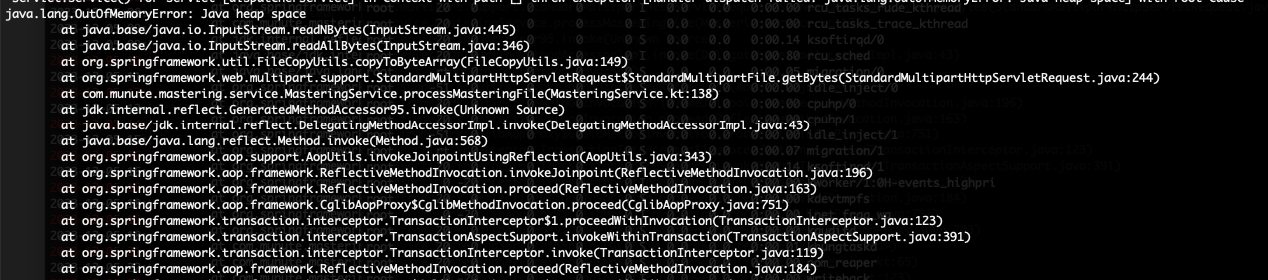
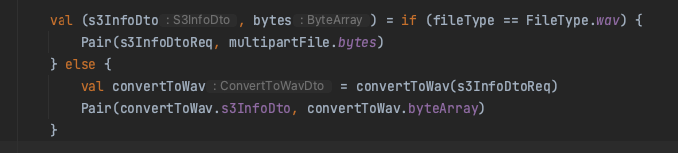
소스 코드의 이 부분, 여기서 해당 Heap Size를 넘어서는 (ByteArray) 메모리에 올리려 하니 OOM 이 터져버린 것이다. 급히 인스턴스에 접속해 JDK의 ㅡMAX heap size를 살펴봤다.

https://m.blog.naver.com/pcmola/221811360247
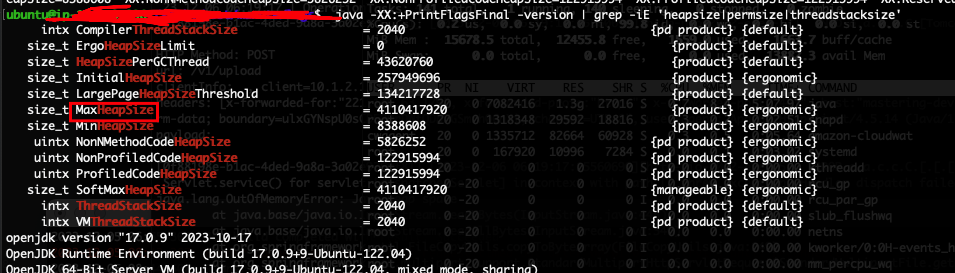
보통 최대 메모리는 현재 컴퓨팅 사양의 4/1 로 할당된다고 한다. 내 인스턴스 메모리가 16기가이니 대충 4기가 잡힌듯.
JAR 최대 힙 사이즈 변경
-Xms: 시작할 때 Java heap size 세팅
-Xmx: 최대 Java heap size 세팅
sudo nohup /usr/bin/java -Xmx5G -jar *.jar --spring.profiles.active=dev
일단 ec2 인스턴스 사양을 8기가짜리로 낮추고 맥스 힙사이즈를 5기가로 바꾸고 실행을 해보았다.
CloudWatch로 Memory Monitoring
그리고 정확한 지표를 그래프로 보기 위해, 메모리 지표를 수집하는 클라우드와치 에이전트를 설치하기로 했다.
wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
설치할 때 현재 내 인스턴스의 CPU 아키텍처를 고려해서 명령어를 실행해라
amd64 가 아니면 다른 걸로~
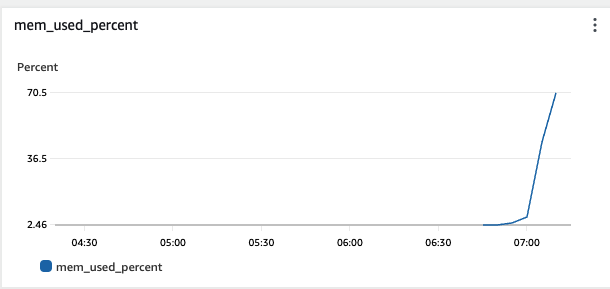
8기가로 낮춘 인스턴스 사양을 가지고 40개를 가지고 다시 부하테스트를 진행했다. 메모리가 거의 70% 까지 차는 것을 확인할 수 있다.

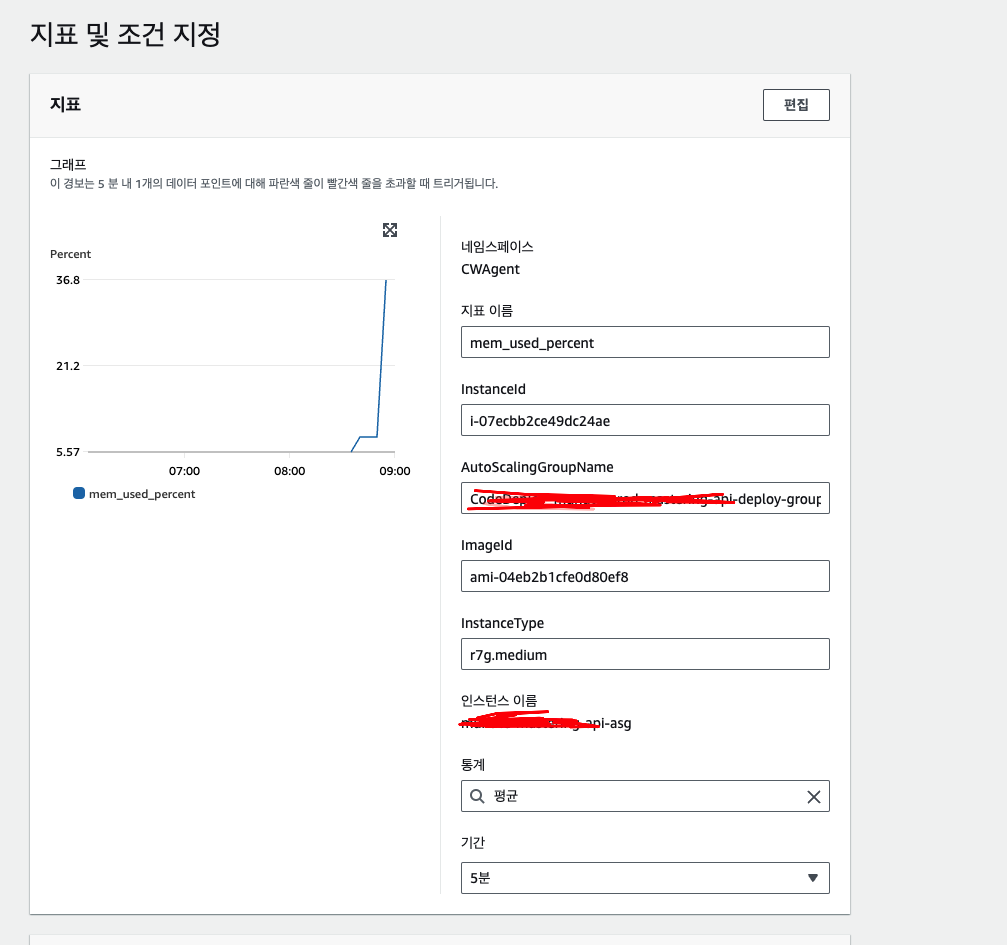
메모리 사용량 기반 오토스케일링 정책 수립
이제 운영서버에 메모리 사용량 기반으로 늘리도록 정책을 수정할 타이밍이다. 기존에는 EC2 스케일링 아웃이 CPU 기반으로 설정되었지만, 사실 CPU 사용률 지표는 지금 상황에서 큰 의미가 없다.
https://aws.plainenglish.io/hello-everyone-2eeb0515c0f5
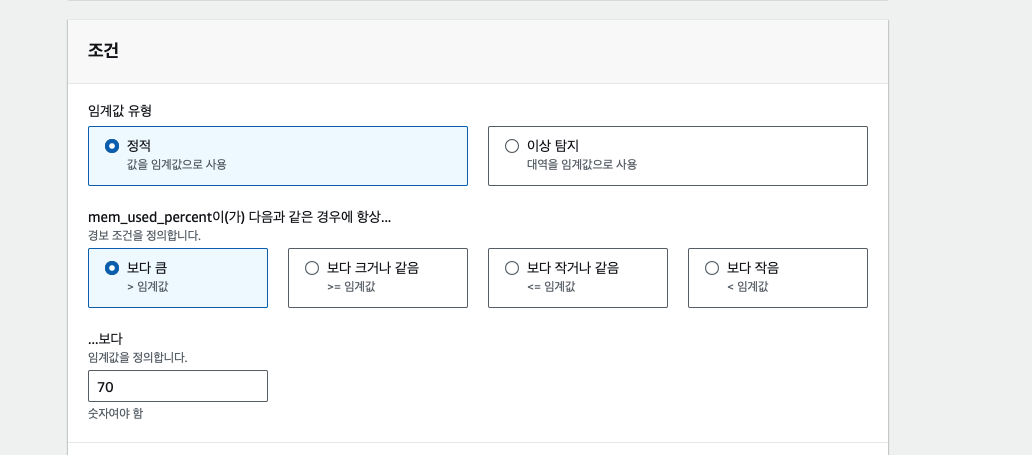
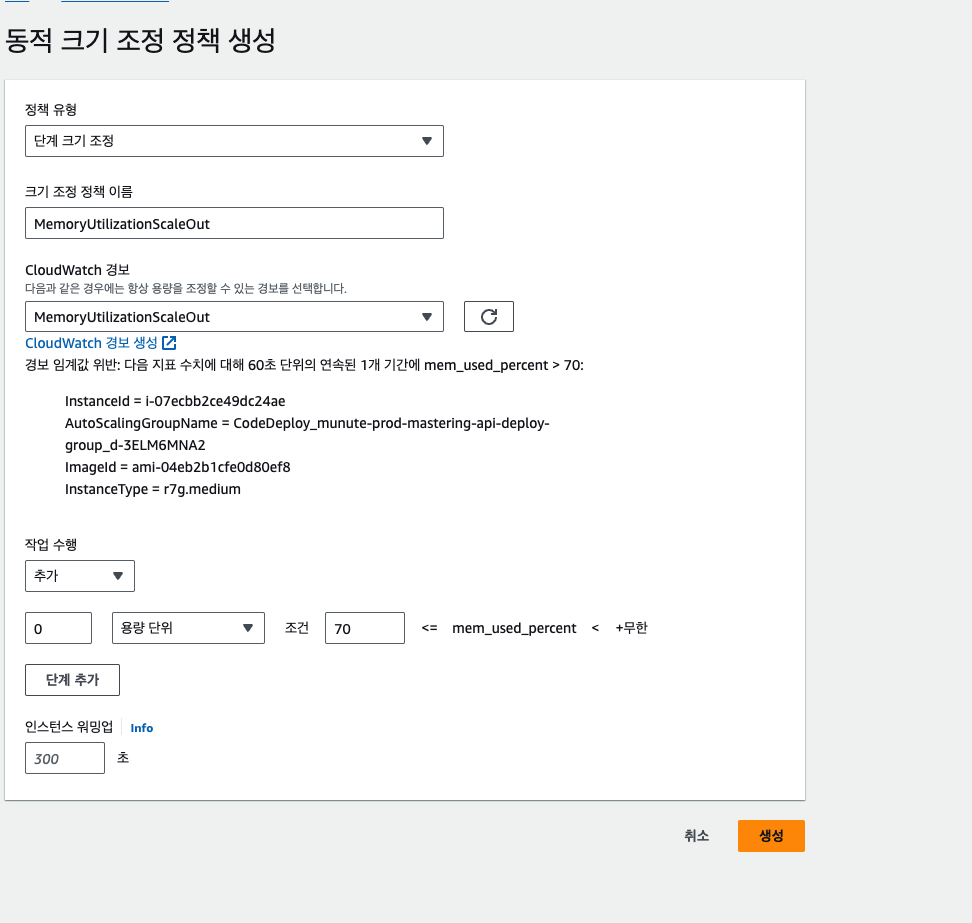
ASG 그룹 편집
소스코드 수정
그렇게 해도 결국 과도한 GC 문제가 발생하니.. 근본적인 해결책은 로직 자체를 다른 식으로 구현하는 것이다. 애초에 원인은 무엇이었나.. 그건 파일을 통째로 읽어서 Bytes로 메모리에 담아두는 코드 자체가 부하의 원인이었다. 이유는 외부 API를 호출하는데 인터페이스가 그렇게 설계되어있어서, 별 생각 없이 그렇게 맞추었는데. 타 서버 개발자와 연락해서 해당 로직을 수정하기로 합의했다.
FileUtils.readFileToByteArray(resultFile)
대충 요런 코드들을 다 찾아주고 다른 방식으로 구현
해당 로직 자체를 전부 다른 식으로 교체했다. 일단 ByteArray로 메모리에 통째로 읽어서 올려놓는 코드 자체를 전부 다 찾아냈다. 업로드 관련 코드 자체는 모두 교체할 수 있었는데, 다운로드 부분이 문제였다.
내 서버는 해당 파일들을 S3에 보관하고 있었는데, 클라이언트에게 내려주기 전 메모리에 일단 올려놓고 후처리 작업을 따로 하는 과정이 존재했다. 따라서 presigned Url 같은 방법은 제외. file 객체를 직접 불러와서 작업을 하도록 처리하고 ResponseEntity<Resource!> 로 내려주는 방식으로 대체 구현했는데, 문제는 클라이언트가 파일을 다운받고 나면 해당 파일을 삭제해줘야 되는 과정이 필요하다는 거다. 기존에는 ResponseEntity<ByteArray!> 로 바이트에 담은 다음 파일을 삭제해주고 내려주었는데, 방법을 교체하면서 이 임시파일을 삭제해주게 하는 로직을 어떻게 담을 지 고민이었다. 다행히 나와 비슷한 고민을 하는 사람들은 어디서든 찾아볼 수 있기 마련이다.
https://stackoverflow.com/questions/45694168/downloading-large-files-via-spring-mvc
https://stackoverflow.com/questions/77501017/rest-service-download-file-and-delete-it-after-that
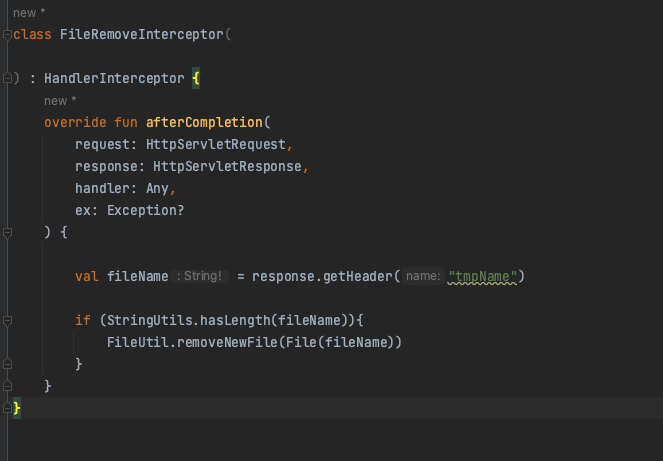

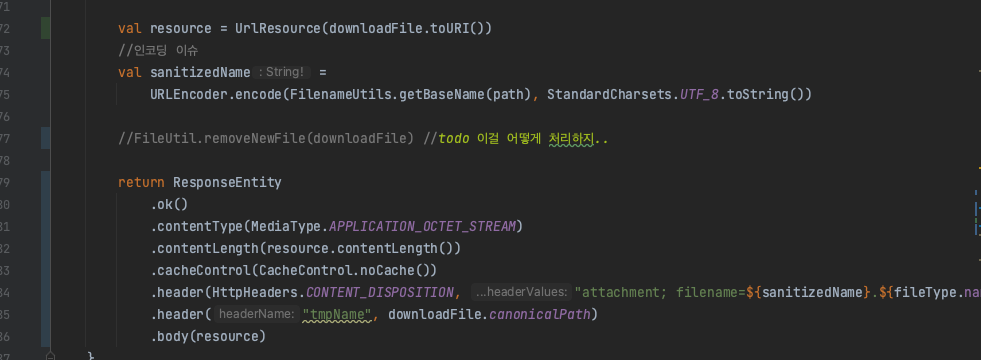
깔끔하게 작동한다 ㅎ
.. 유니코드 이슈가 존재한다.. 코드를 살짝 수정해주었다.


NoClassDefFoundError
