Auto encoder 의 시간에 따른 성능 열화 실험
요약
- 뉴스 기사의 multi lingual bert emb 를 차원 축소시키는데에 auto encoder를 이용하게 될 예정.
- model 의 학습에 쓰이는 feature를 정기적으로 재학습 시키고 update하는 과정을 꼭 해야만 할지 알아보기 위해 실험을 진행한다.
- 5월에 학습시킨 오토인코더를 6월부터 11월 데이터에 적용해보고, 성능 저하가 발견되는지(loss 값이 크게 증가하는지)확인한다.
- 시간이 지나도 loss 값은 크게 증가하지 않는 모습을 보인다.
- 즉, 5월 데이터로 학습한 오토인코더를 11월에 사용해도 성능은 뒤떨어지지 않음을 알 수 있다.
실험 목표
- 뉴스 기사 multi lingual bert embedding vector의 차원 축소시키는데에 auto encoder를 이용하게 될 예정.
- model 의 학습에 쓰이는 feature를 정기적으로 재학습 시키고 update하기 위해서는 준비해야할 부분이 너무 많다.
- 이 번거로운 준비를 해보기 전에, auto encoder의 성능 열화를 정량적으로 확인하고, 차원 축소 모델의 정기적 업데이트가 불가피한 일인지를 확인한다.
실험 방법
- 5월 데이터로 오토인코더를 학습시킨다.
- 학습시킨 오토인코더로 6,7,8,9,10,11월의 데이터를 encoding 후 decoding 했을때에 loss 가 얼마나 증가하는지를 확인하여, 오토인코더가 시간이 지남에 따라 그 성능이 얼마나 나빠질 수 있을지 확인한다.
- (차원 축소된 item vector를 이용한 ctr 실험으로 성능열화실험을 진행하려 했으나, 서로 다른 데이터에 대해서 ctr 예측 결과의 정확한 정도를 나누는 것이 합리적이지 않다고 여겨졌다. 또한 그럼에도 실험을 해보았을때에 데이터가 매우 튀어 비교가 불가능한 상태였다.)
auto encoder 학습
- 4단 stacked auto encoder 활용 (768 → 64 → 32 → 16 →5)
- 뉴스기사 제목과 내용의 270만개의 multi lang bert 결과로 학습
(2021-05-01 ~ 2021-05-05)
Loss 확인 대상 데이터
- 6,7,8,9,10,11월의 1일부터 15일까지의 뉴스기사 중 unique 한 25000개를 random 하게 추출한다.
- 위의 데이터를 AE 를 통과시킨 후의 loss 값이 얼마나 늘어나는지를 확인한다.
실험 결과
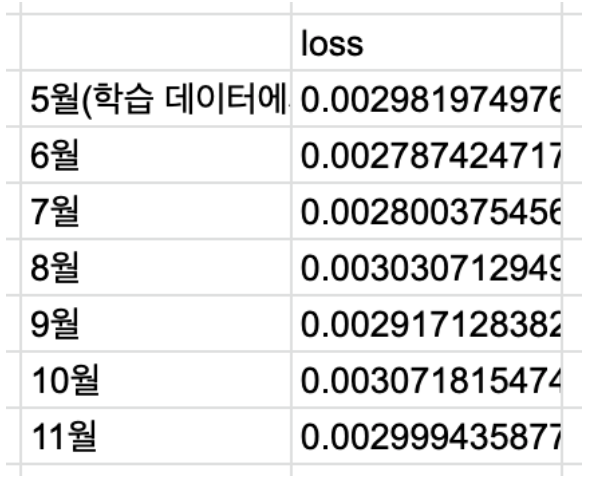
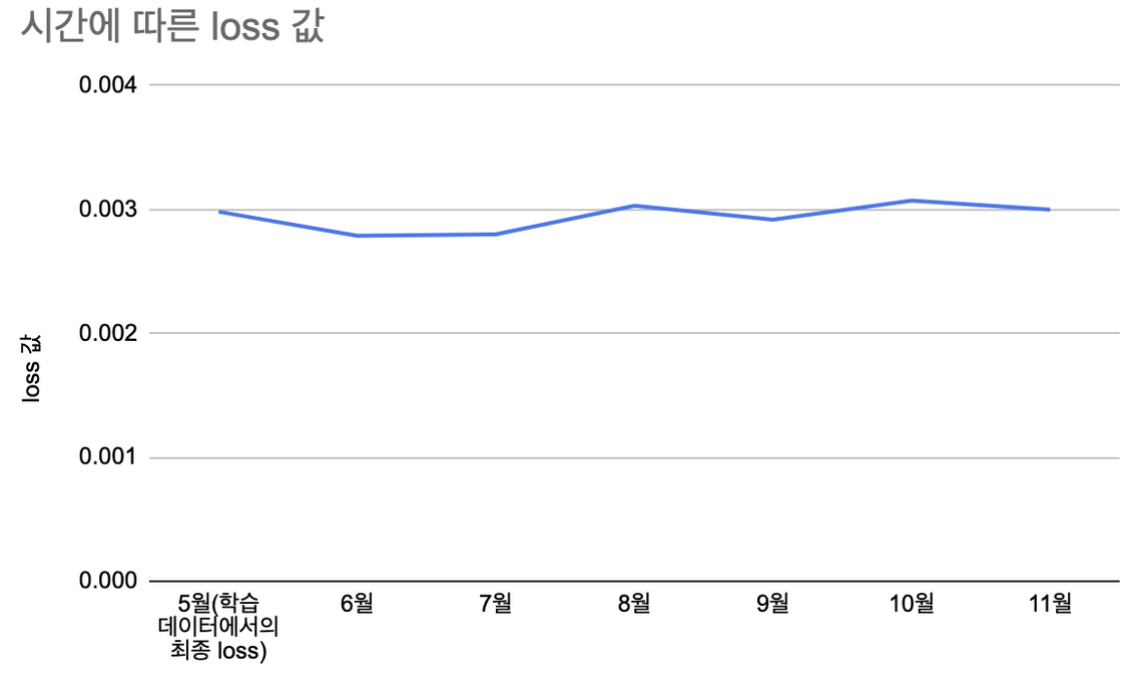
- 시간이 지나도 loss 값은 크게 증가하지 않는 모습을 보인다.
- 즉, 5월 데이터로 학습한 오토인코더를 11월에 사용해도 성능은 뒤떨어지지 않음을 알 수 있다.

data scientist