
프로젝트의 첫 시작인 계획 세우기 후에 이제 크롤링 시간
나는 한국은행 의사록 크롤링을 맡았다.
크롤링 페이지
[https://www.bok.or.kr/portal/bbs/B0000245/list.do?menuNo=200760]
한국은행 의사록은 pdf로 되어있다.
그래서 pdf를 원하는 기간만큼 다운받아서 tika 라이브러리를
이용해 텍스트 추출을 한다.
홈페이지 의사록 목록에서 pdf를 다운받을 수 있다.
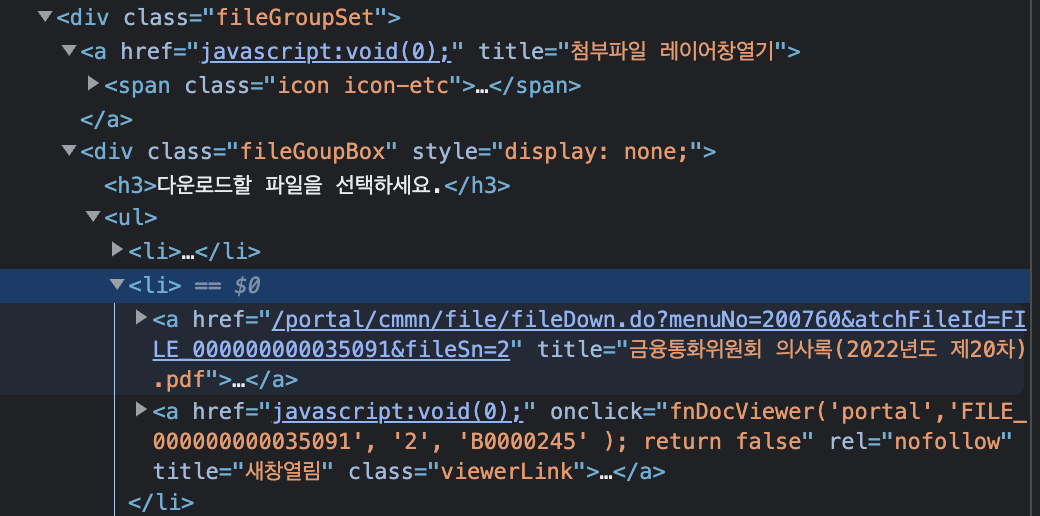
처음에는 문서뷰어로 바로 크롤링 해오면 좋겠다고 생각했는데
두-둥!

여기 보이는 것처럼 문서뷰어는 javascript:void(0)이라고 되어있다 ㅎ..
그래서 그 위에 href 속성에 있는 다운로드 링크를
크롤링해와서 한번에 다운받으려고 한다.
크롤링 코드 작성
- 일단 아나콘다에서 프로젝트만을 위한 가상환경을 만들어줬다.
conda activate -n project1- 그리고 스크래피를 다운받는다
conda activate projrct1
pip install scrapy- 다운받았으면 이제 프로젝트 파일 생성
scrapy startproject minutes- 파일 구조가 생성됐으면 이제 크롤링 코딩 시작!
import scrapy
from minutes.items import MinutesItem
class Minutes(scrapy.Spider):
name = 'minutes'
def start_requests(self):
urls = [
'https://www.bok.or.kr/portal/bbs/B0000245/list.do?menuNo=200761&pageIndex='+ str(i) for i in range(1,25)
]
for url in urls:
yield scrapy.Request(url = url, callback = self.parse)
def parse(self, response):
item = MinutesItem()
for i in range(1, 10):
try:
item['file_url'] = response.xpath(f'//*[@id="content"]/div[3]/ul/li[{i}]/div/div[1]/div/div/ul/li[2]/a[1]/@href').extract()
item['date'] = response.xpath(f'//*[@id="content"]/div[3]/ul/li[{i}]/div/div[2]/div/span[1]/text()').extract()
item['file_url'] = 'https://www.bok.or.kr' + item['file_url'][0]
yield item
except:
pass-
이렇게 하고 item.py에 아이템 만들어줬다.
item['file_url']에 앞에 호스트 주소를 붙여줘야 다운이 된다.
이렇게 하고 -
스크래피 실행
scrapy crawl minutes해주면
로그 파일과 함께 다운로드 링크 파일 생성!
스크래피 처음엔 어려웠는데 편리한 것 같다 !
오늘도 잘 배웠다 ^A^
Deciphering Monetary Policy Board Minutes through Text Mining Approach: The Case of Korea
(텍스트 마이닝을 활용한 금융통화위원회 의사록 분석)
- 박기영(연세대), 이영준(연세대), 김수현
논문을 기반으로 배워보는 텍스트 마이닝 프로젝트 입니다.
