Download : https://www.nuscenes.org/nuscenes#download
dev-kit : https://github.com/nutonomy/nuscenes-devkit?tab=readme-ov-file
colab : https://colab.research.google.com/github/nutonomy/nuscenes-devkit/blob/master/python-sdk/tutorials/nuscenes_tutorial.ipynb
설치
데이터셋 설치하고
pip install nuscenes-devkit사용
인스턴스 선언
from nuscenes.nuscenes import NuScenes
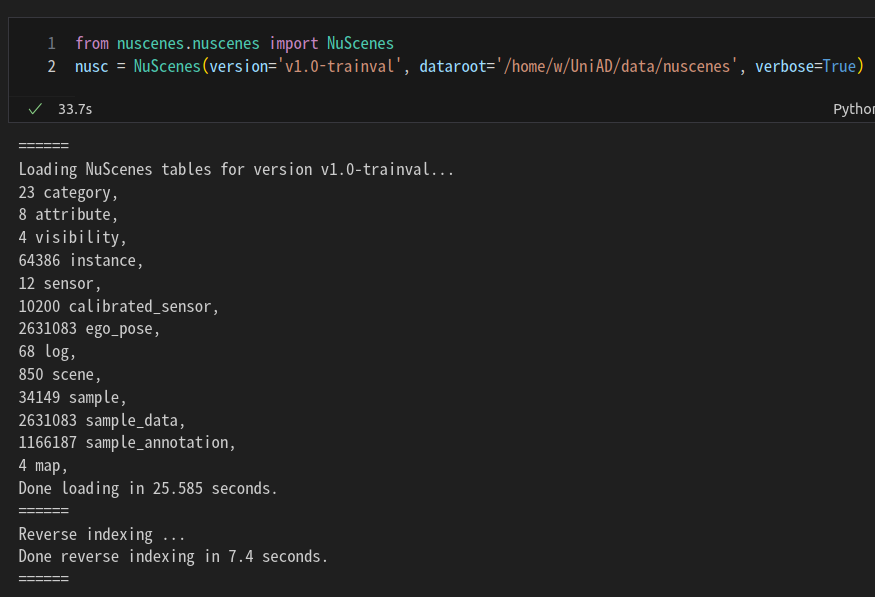
nusc = NuScenes(version='v1.0-trainval', dataroot='./my/data/path', verbose=True)버전은 v1.0-mini, v1.0-trainval, v1.0-test가 있다
테스트 할때는 mini 사용하는게 정신 건강에 좋을듯ㅎㅎ
v1.0-trainval에는 다음과 같은게 있다.
1. Scene
colab에서는 1000 scenes of approximately 20 seconds each 라는데
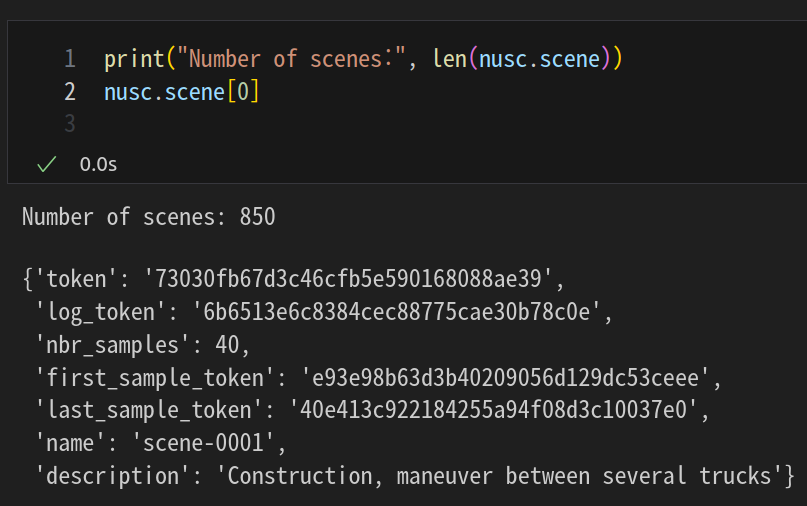
실제로 찍어보면 850까지만 존재한다.
print(len(nusc.scene))
nusc.scene[0]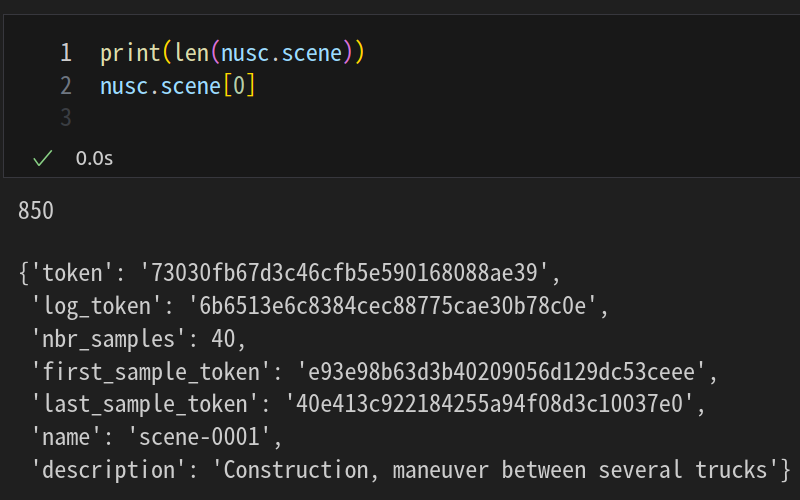
2. Sample
Scene에서 2Hz마다 annotation을 달았다.
작성자는 sample을 특정 타임스탬프에서 장면의 주석이 달린 키프레임(keyframe) 라고 정의했다.
'키프레임이란 모든 센서로부터 수집된 데이터의 타임스탬프가 해당 샘플이 가리키는 타임스탬프와 매우 가까운 프레임을 의미함' 라고 설명했는데 무시하고
- 하나의 Scene은 20초의 영상이다.
- Scene에서 2hz마다 이미지를 캡처했다.
--> 총 40장의 이미지(Sample)이 존재
34,149 Sample이 있네요??
Scene[0]의first_sample_token값은sample[0]의token값과 같으며,
Scene[0]의token값은sample[0]의scene_token값과 같다.
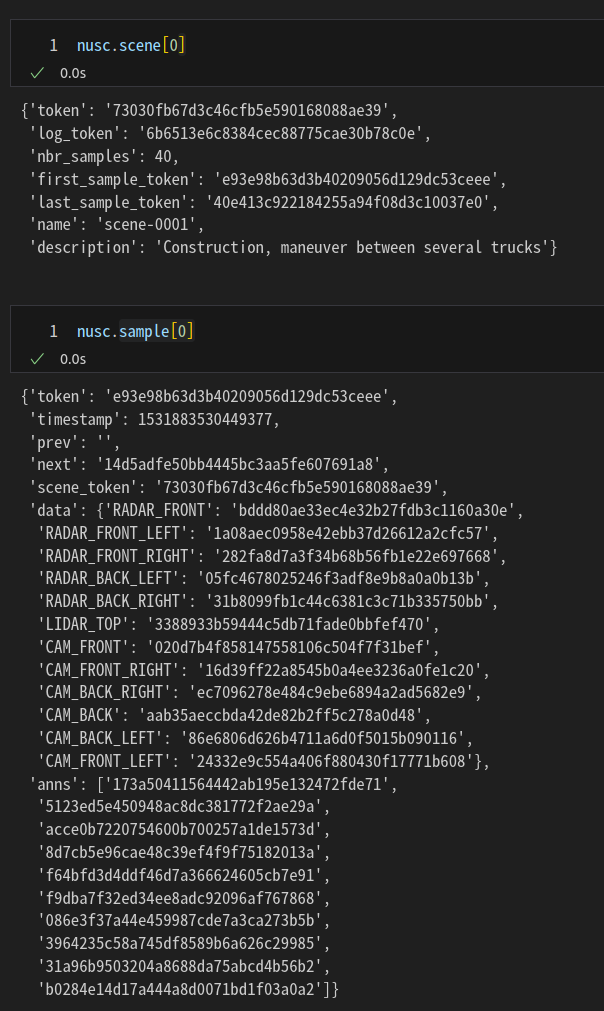
first_sample_token 값 확인
my_scene = nusc.scene[0]
first_sample_token = my_scene['first_sample_token']
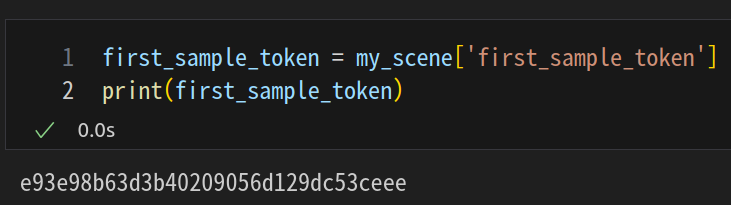
my_sample = nusc.get('sample', first_sample_token)
my_sample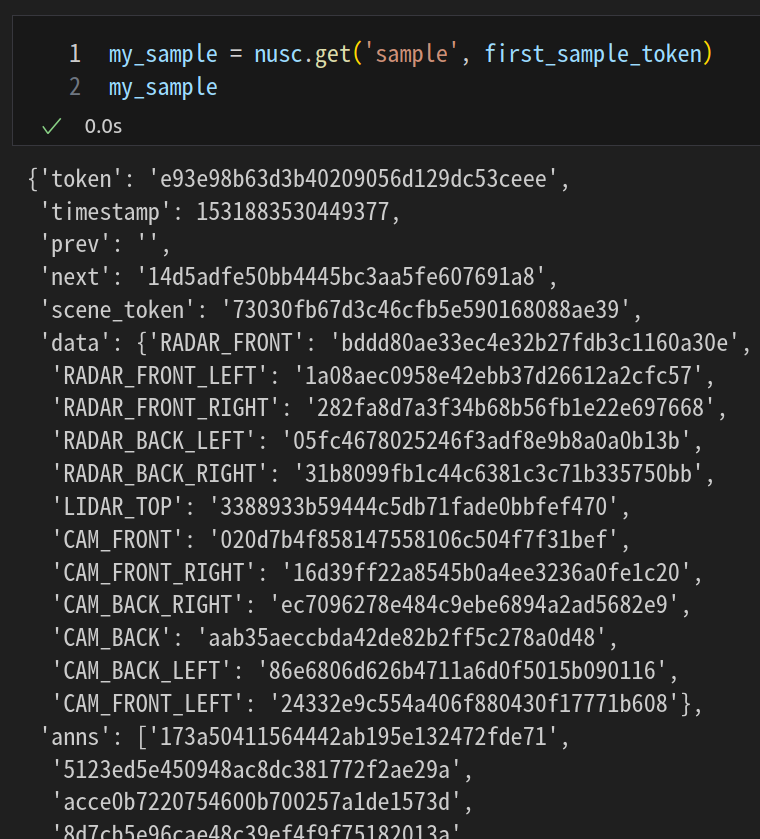
sample에는 data와 anns가 있다.
data는 camera, lidar, radar 데이터가 있으며
anns는 주변 객체 데이터가 있다. (movable_object, vehicle, human)
메서드 list_sample()은 샘플과 관련된 sample_data,sample_annotation을 나열함
nusc.list_sample(my_sample['token'])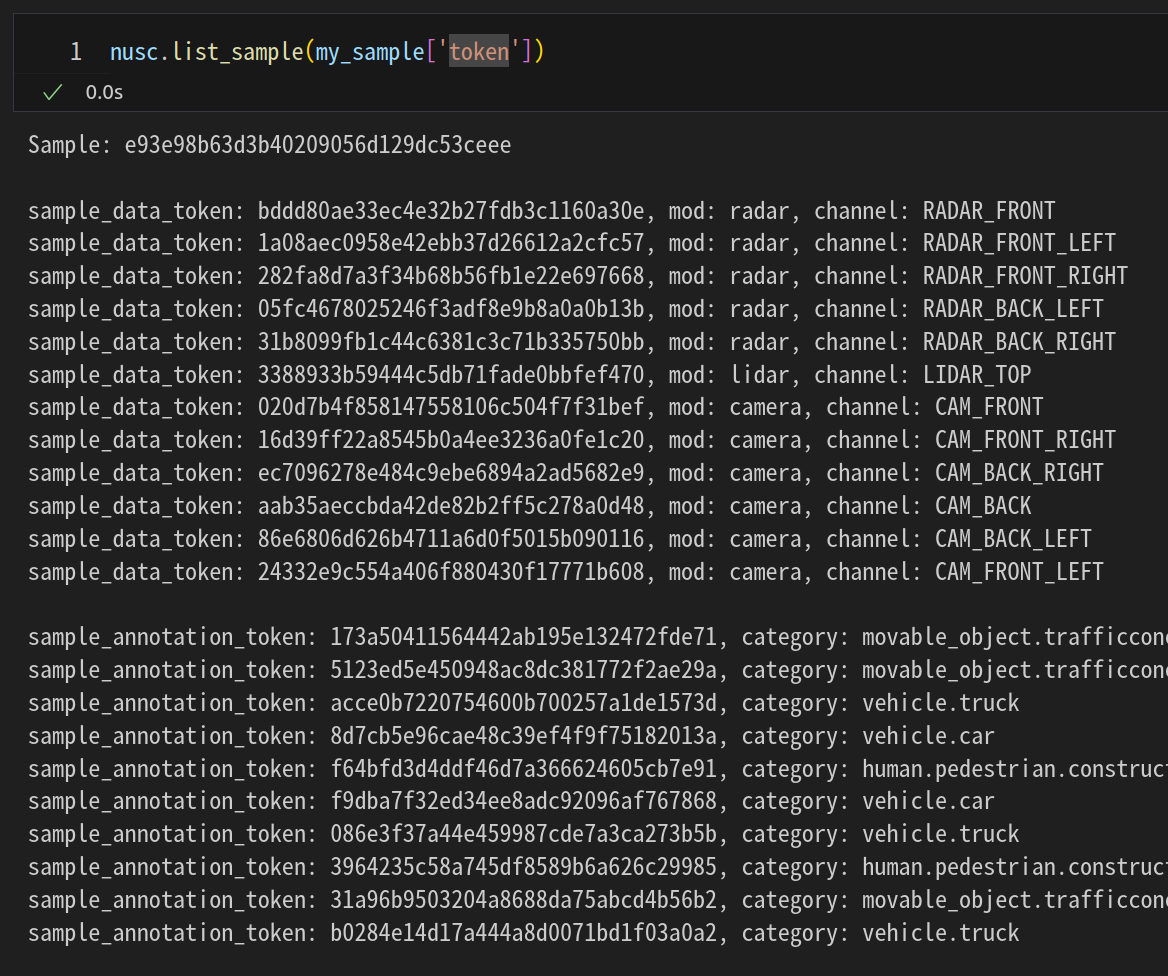
850개 있는 scene중 scene[0]의 첫 장면인 first_sample_token 관련된 data와 anns의 정보가 담긴 정보들을 출력
3. Sample_data
my_sample['data']
sensor = 'CAM_FRONT'
cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])
cam_front_data4. sensor
sensor = 'CAM_FRONT'
cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])
cam_front_data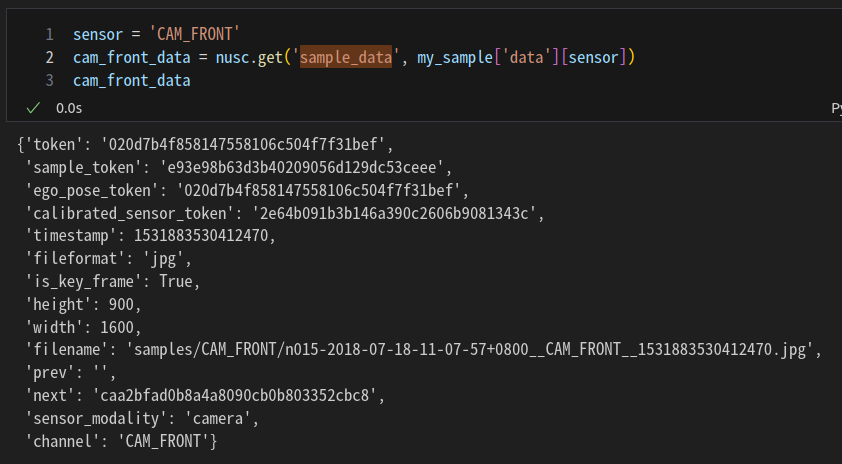

빨리 작성해주세요