1. 소개
survival analysis는 관찰시작 ~ 사망까지 생존시간을 추정하는 통계적 분석법이다.
성별, 흡연 여부 등의 데이터로부터 생존시간을 예측한다.
scikit-learn 에 scikit-survival라는 패키지가 따로 있기도 하고 pycox 등 다양한 툴들이 존재한다.
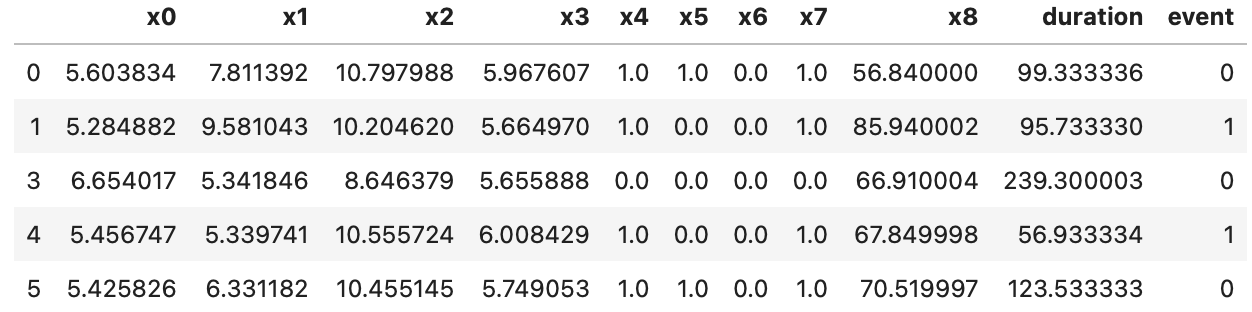
- 데이터 예시
2. 주요 용어
- Event(사건) : 죽음, 사고발생 , 장애 등 생존분석으로 분석하려는 대상 , 고객 이탈분석에서는 이탈이 사건이다.
- Time(Duration) : 환자의 생존시간 , 특정 사건(event)이 발생할 때 까지의 시간
- Censored(중도절단) : 연구 종료, 추적 실해로 중도절단될 수 있다.
- right censored: 아직 사건이 발생하지 않았거나 다양한 이유로 관찰이 종료된 경우
- left censored: 대상을 관찰하기 전에 사건이 발생했거나 기대했던 최소 기간보다 생존 기간이 더 짧았던 경우
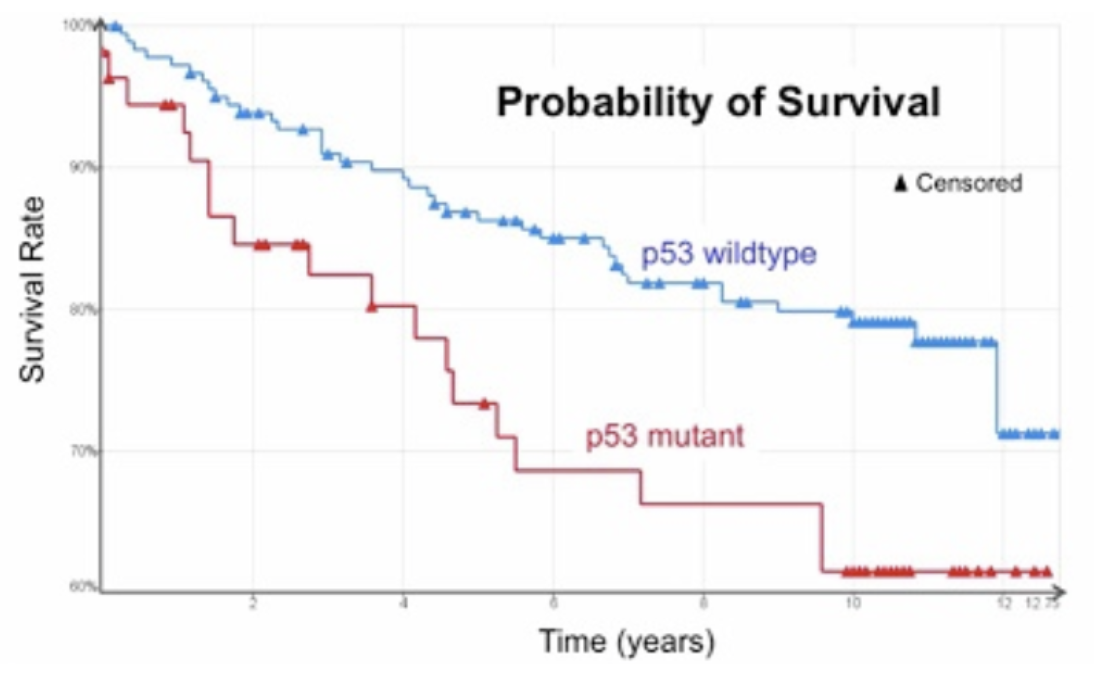
- survival function(생존함수) : 환자가 t 시간을 초과하여 생존할 확률
, 단조감소
- 마지막 시점에서 0이 아닐 수도 있음 <- 중도 절단 때문
3. c-index
생존분석에서 가장 많이 사용되는 정확도 지표입니다.
대상의 정확한 생존 시간을 평가하지 않고 두 환자를 쌍을 지어 상대적으로 비교해준다.
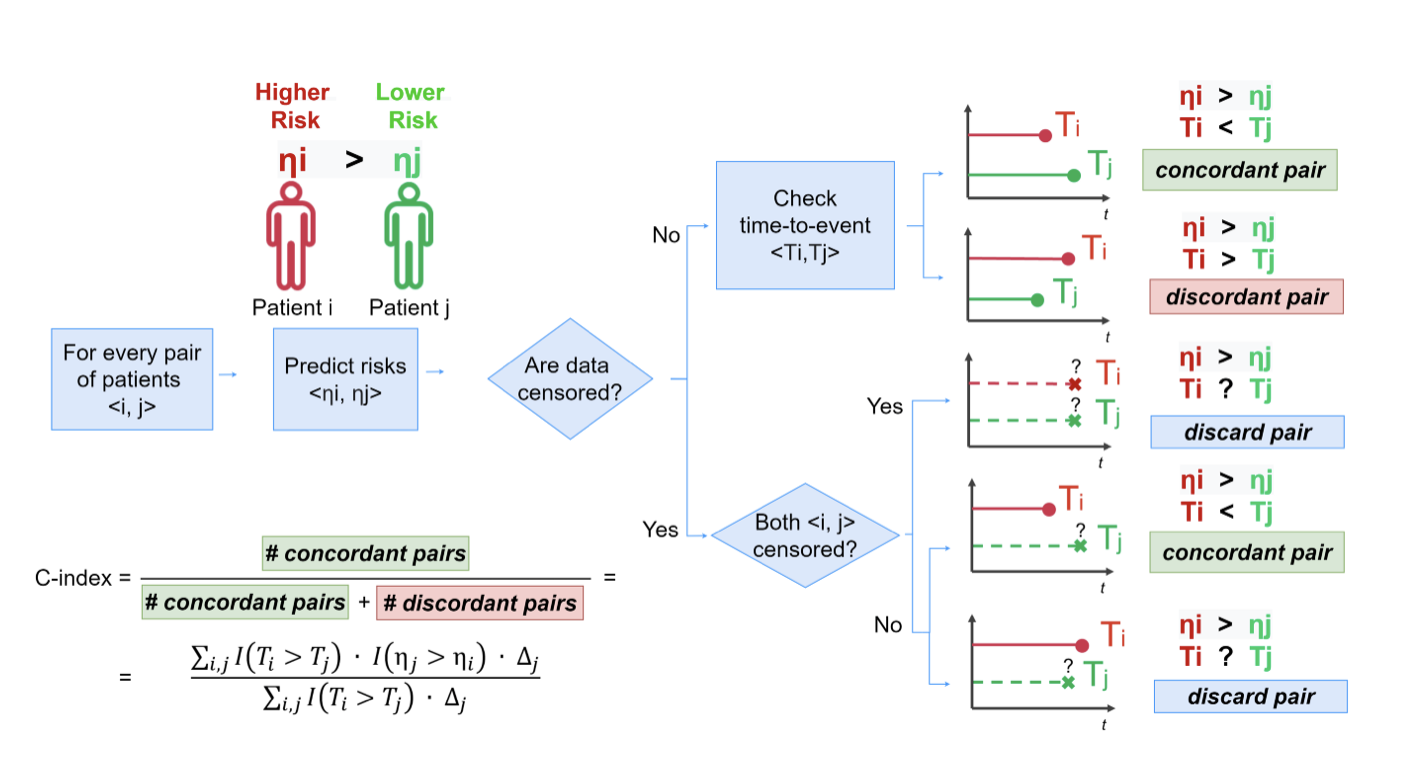
출처 : https://towardsdatascience.com/how-to-evaluate-survival-analysis-models-dd67bc10caae
두 데이터 중 censored data 가 없으면 더 위험도가 높은 환자의 생존시간이 짧은지 확인한다.
더 높은 위험도의 환자 생존기간 < 더 낮은 위험도의 환자 생존기간 : dicordant pair
더 높은 위험도의 환자 생존기간 < 더 낮은 위험도의 환자 생존기간 : concordant pair
dircordant인 경우 식에서 가 0 이 되어 c-index에 포함되지 않는다.
두 환자가 모두 중도절단 되었을 경우, 한 환자의 사건 발생보다 더 일찍 중도절단되었을 경우에는 비교가 되지 않아서 c-index 구할 때는 무시된다.
수식으로 표현하면 다음과 같다.

C-index 해석 방법

C-index는 censored 데이터의 양이 많을 수록 커지는 경향이 있어서 변형된 다른지표들도 있다.
배이스 라인 모델이는 time-continuous model, time-discrete model 이 있는데 모델 종류에 맞는 평가 지표를 써주어야 할 것 같다.
다른 평가 지표들과 다양한 생존 분석 방법에 대해서도 추가로 정리할 것이다!!
참고
https://github.com/havakv
http://bigdata.dongguk.ac.kr/lectures/med_stat/_book/생존분석-survival-analysis.html
https://bioinformaticsandme.tistory.com/223
