anaconda prompt 사용법
conda activate ds_study
cd Documents
cd ds_study
cd .. : 상위폴더로 이동
code . : vscode 실행
jupyter notebook : 쥬피터노트북 실행
판다스 함수 사용법
구글링 : pandas read_excel documentation
F1 검색 select interpreter
CCTV 분석하기의 목표

데이터 읽기(엑셀 / csv 텍스트파일)
(p.23)
- 모듈에 대한 네이밍 규칙

import MODULE → MODULE.function
import MODULE as md → md.function
from MODULE import function → function
Pandas로 엑셀 및 텍스트파일 읽기
- Pandas DataFrame의 구조
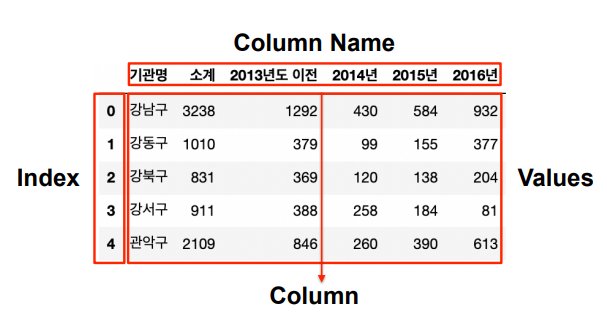

- 텍스트파일 읽기 (Seoul_CCTV.csv)
- 통상 csv는 띄어쓰기로 구분되니 그냥 read_csv 명령으로 읽기만 해도 된다.
(csv : comma_seperated_values) - 한글은 encoding 설정이 필수(utf-8)
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")
CCTV_Seoul.head()- column의 이름 조회하기
CCTV_Seoul.columns # 칼럼명 전체
CCTV_Seoul.columns[0] # 첫번째 칼럼만- column의 이름 바꾸기 (rename)
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
# inplace : 바뀐걸로 저장 (default = False)
CCTV_Seoul.head()pd.read_csv("경로", encoding="utf-8") 읽어오기
columns 컬럼 이름 조회하기
head() 처음5개
tail() 끝5개
header 날릴 열. 자료를 읽기 시작할 행(헤더) 지정
usecols 읽어올 엑셀의 컬럼을 지정. 일부만 사용할 때.
rename 이름 변경
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv")
CCTV_Seoul.head()
CCTV_Seoul.columns
CCTV_Seoul.columns[0]
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
CCTV_Seoul.head()
- 엑셀파일 읽기 (Seoul_Population.xls)
pd.read_excel("경로") 읽어오기
header 날릴 열. 자료를 읽기 시작할 행(헤더) 지정
usecols 읽어올 엑셀의 컬럼을 지정. 일부만 사용할 때.
rename 이름 변경
- 엑셀에서 일부 자료만 읽기 (header, usecols)
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B,D,G,J,N"
)
# 위에 2줄 날리고, BDGJN컬럼만 가져온다
pop_Seoul.head()- 엑셀에서 컬럼 이름 바꾸기(rename)
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True,
)
pop_Seoul.head()판다스 기초
(p.37)
- pandas는 통상 pd
- numpy는 통상 np (수치해석적 함수가 많음)
import pandas as pd
import numpy as np- pandas의 데이터형을 구성하는 기본은 Series이다
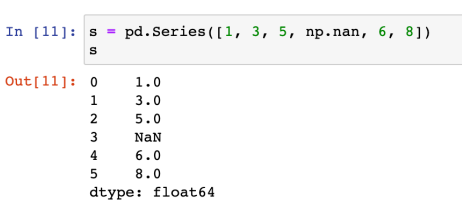
- 날짜(시간)을 이용할 수 있다
peiod : 일수

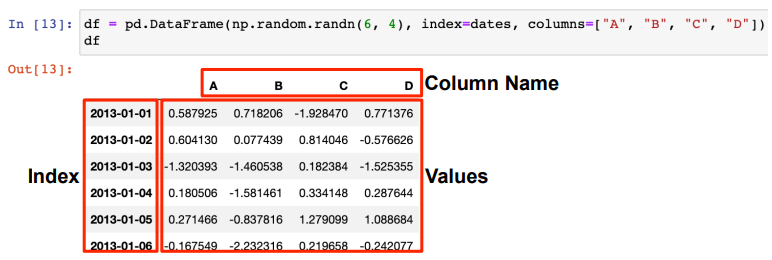
- Pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다.
index와 columns를 지정하면 된다.
: 6행 4열의 랜덤 숫자값, 인덱스와 컬럼명 지정
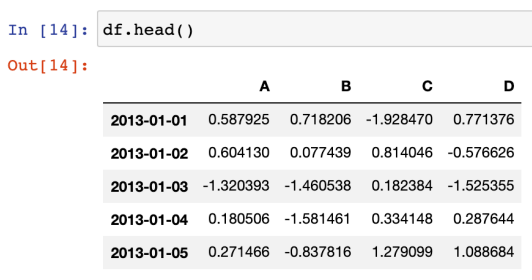
- head() : 기본 앞부분 5개의 데이터 확인 (숫자를 넣으면 그만큼)
- index : DataFrame의 index 확인

- columns : DataFrame의 컬럼 확인

- values : DataFrame의 밸류 확인
- info() : DataFrame의 기본정보 확인. (요약정리)
각 컬럼의 크기와, 데이터형태를 확인하는 경우가 많다
- describe() : DataFrame의 통계적 기본정보를 확인
(갯수, 평균, 표준편차, 미니멈, 1/4지점, 2/4지점, 3/4지점, 맥시멈)
- sort_values : 데이터를 정렬 (B컬럼 기준, ascending True/False : 오름차순/내림차순)
- 특정 컬럼(열)만 읽기

추가 메모
-
행 제거 : drop
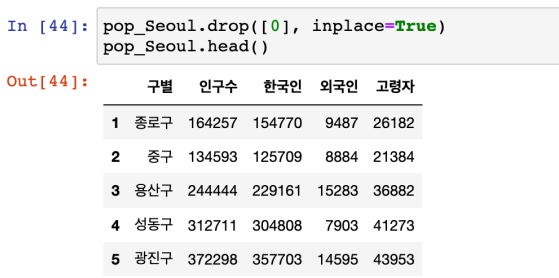
-
컬럼(열) 제거 : del
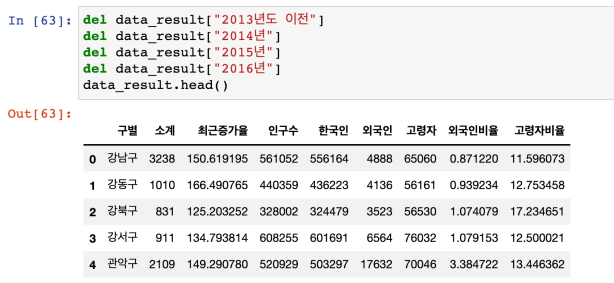
-
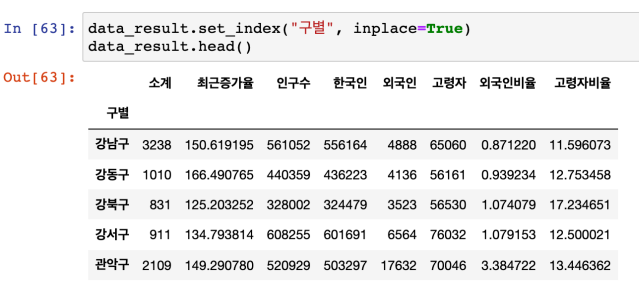
인덱스 재지정 : set_index
: unique한 값으로 잡기
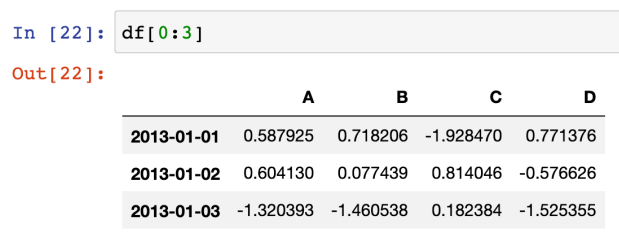
- 슬라이싱 [n:m] : 행을 n부터 m-1까지
그러나 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함함!
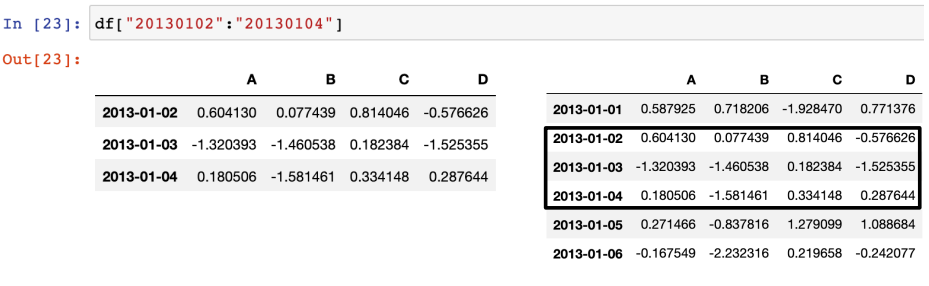
- 슬라이싱 - option LOC[행, 열] : 이름으로 지정
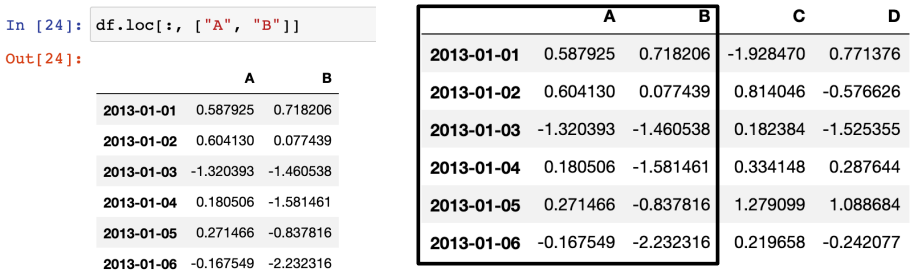
로케이션. 보편적인 slice 옵션. 이름으로도 사용 가능.
1) 모든 행 + A,B열
2) 행 구간 + A,B열

3) 특정 행 + A,B열

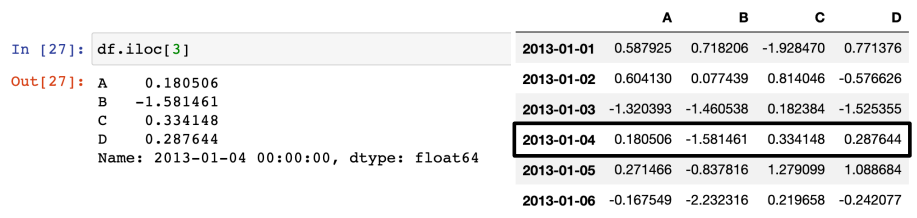
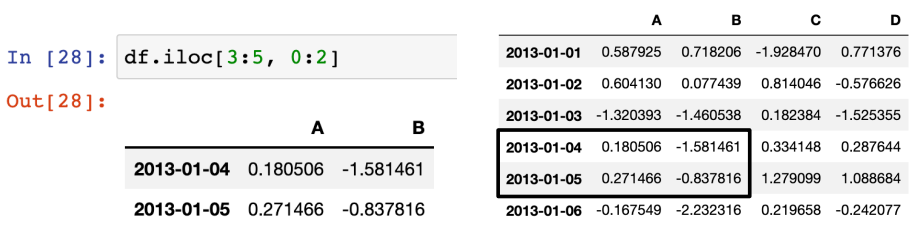
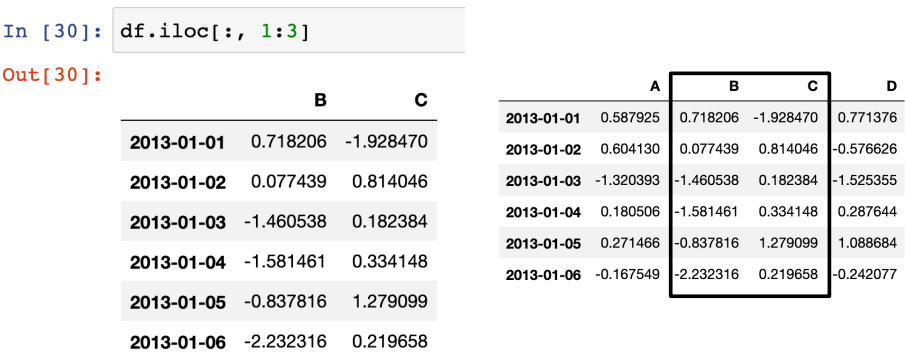
- 슬라이싱 - option iLOC[행, 열] : 번호로 지정
iLOC 옵션을 이용해서 번호로만 접근. n부터 m-1까지

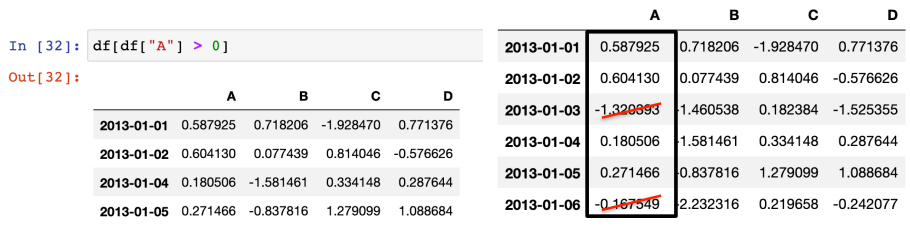
- 슬라이싱 under condition
df[condition] 과 같이 사용하는 것이 일반적.
pandas 버전에 따라 조금씩 문법이 다르다.
1) A칼럼이 0보다 큰 것들만
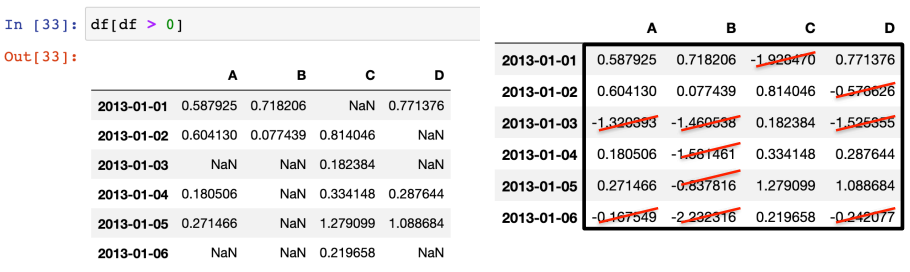
2) 값이 0보다 큰 것들만
3) E라는 컬럼을 새로 만들어라
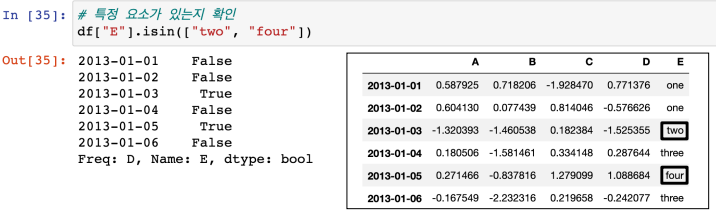
4) isin : E컬럼에 two나 four가 있느냐를 bool 타입으로 표시
5) E라는 컬럼에 two나 four가 있는 것(True인 것)만 표시해라

- del : 특정 컬럼 제거
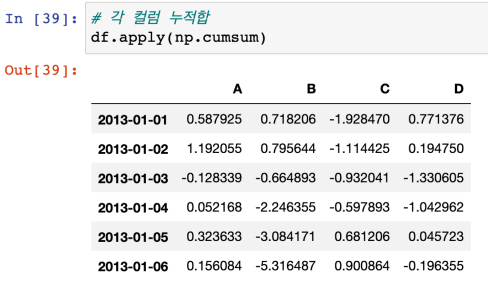
- apply를 써서 numpy가 제공하는 누적합계 함수를 적용
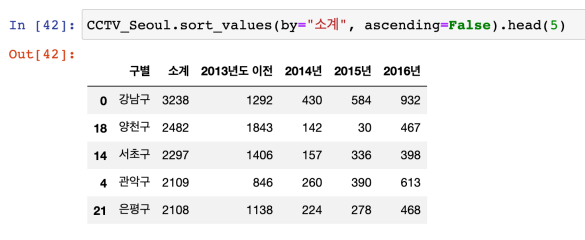
CCTV 데이터 훑어보기
(p.69)
-
많은 순서 : 내림차순
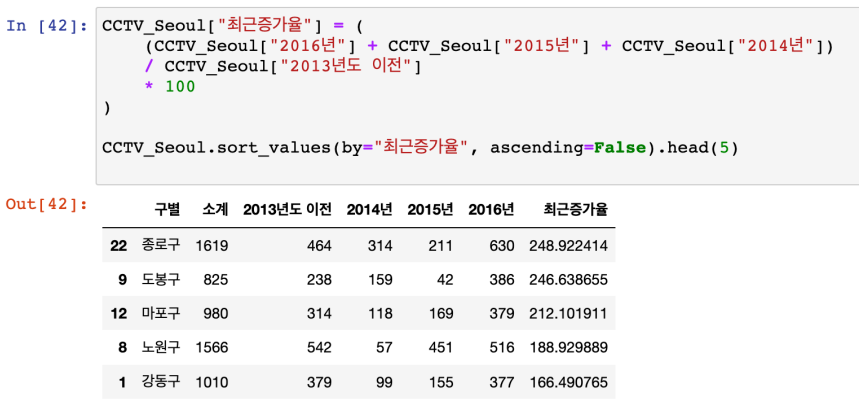
-
컬럼 연산해서 새 컬럼 만들기
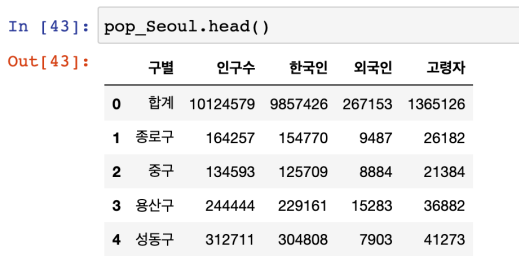
인구현황 데이터 훑어보기
(p.75)
-
행을 지우는 명령 : drop
합계 행만 지우기
-
unique 조사

두 데이터 합치기
(p.86)
- 데이터프레임 만들기
pd.DataFrame({"컬럼명":["0값", "1값", "2값"})

-
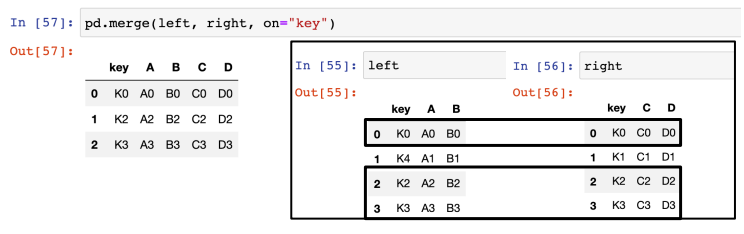
데이터 병합 : merge
on="key" : key를 기준으로 공통인 것만 (교집합)
즉, 기본적으로 how="inner"가 디폴트임
-
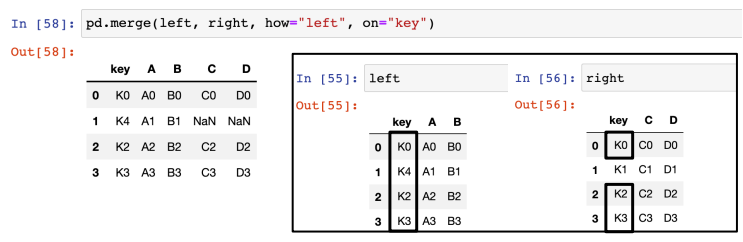
데이터 병합 - how 옵션 ( left / right )
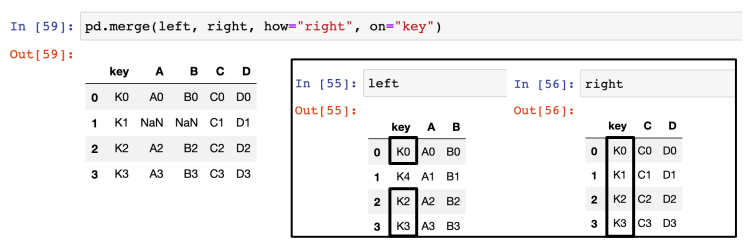
- 데이터 병합 - how 옵션 ( outer / inner )


상관관계
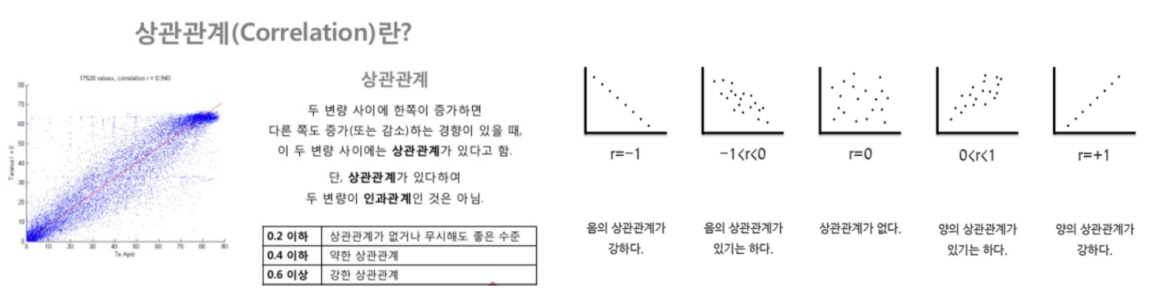
- 상관관계가 있다고 인과관계가 있는 것은 아니다
- 상관계수를 조사해서 0.2 이상의 데이터를 비교하는 것은 의미가 있다
- 상관계수 : 판다스에서 corr() 제공
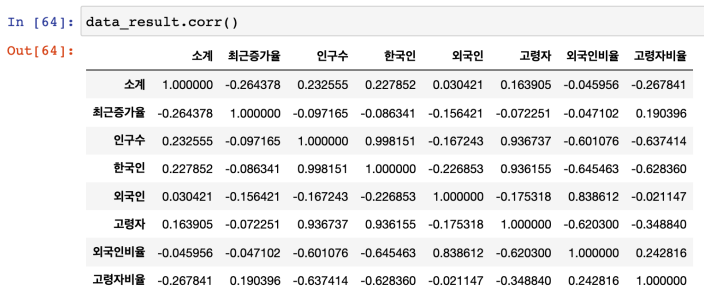
- 데이터 해석
: CCTV 소계(전체 수)와 가장 상관관계가 있는 데이터는 인구수이다
: 구별 인구대비 CCTV 현황을 분석해서 상대적으로 CCTV가 많고적음을 찾는 것은 의미를 가진다
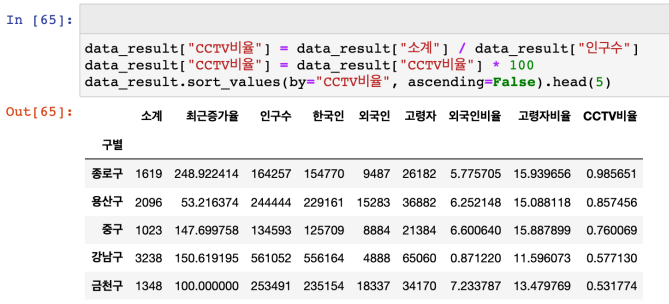
: CCTV 비율을 만들어보자
Matplotlib 기초
(p.104)
- 맷플롯 라이브러리. 파이썬의 대표 시각화도구. 매우 방대함!
- 2D 그래프를 담당하는 pyplot (파이 플럿)
→ plt로 많이 네이밍하여 사용한다 (import matplotlib.pyplot as plt) - 결과를 새 창으로 띄울 수도 있고,
쥬피터노트북에 바로 띄울수도 있다. (%matplotlib inline 옵션)
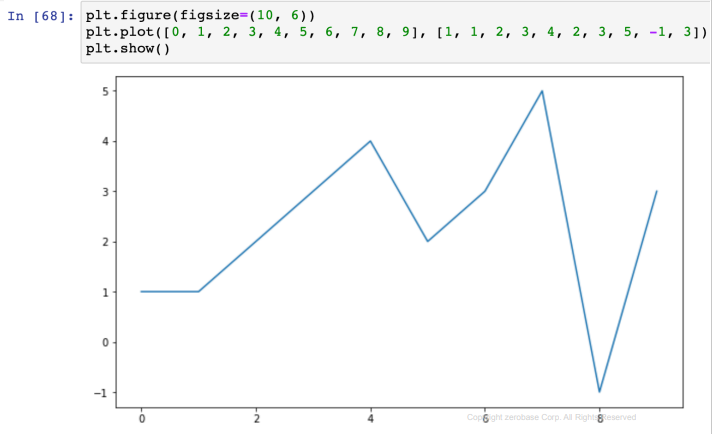
- figure로 열어서 show로 닫는다
- figure : 그래프 속성 설정 (사이즈 등)
- plot : 그림을 그려라 ( x, y 값 설정)
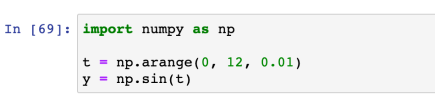
그래프 그리기 연습 : 삼각함수
numpy 함수
- 삼각함수 그리기
- numpy의 sin, cos 함수 가져오기
- np.arange(a, b, s) : a부터 b까지, s간격
- np.sin(value)
- np.cos(value)
다양한 plt 그래프 옵션
- 그래프 그리는 코드를 def()로 작성하기 (나중에 편리)
plt.블라블라~

범례 label, grid, legend, 축 제목 xlabel, ylabel, title
- 다양한 옵션
1)

"r--" : red dashed --
"bs" : blue squared
"g^" : green triange
2)

color, linestyle, marker, markerfacecolor, markersize, xlim, ylim
3)

scatter
4)

'^' : 위로 뾰족한 화살표
'>' : 오른쪽으로 뾰족한 화살표
- 구글에 "matplotlib" 검색해서
공식페이지의 examples 확인하기
데이터 시각화(그래프)
(p.119)
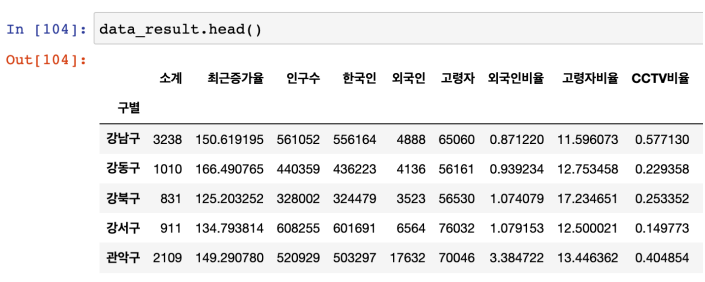

- Pandas DataFrame은 데이터변수에서 바로 plot() 명령을 사용할 수 있다
- 주피터노트북 마지막에 ; 세미콜론 붙여주기

- 데이터 보기 쉽도록 sort_values()로 정렬한 후 plot
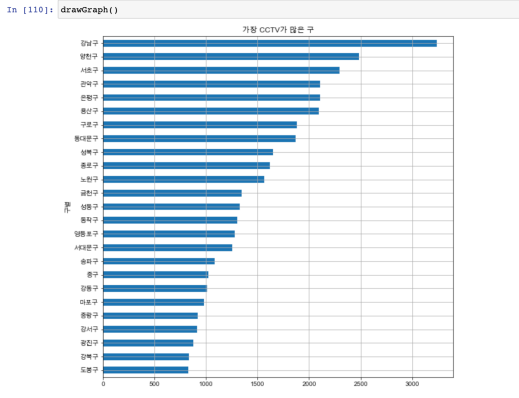
데이터의 경향 표시
(p.129)
- 데이터의 경향을 직선으로 표현하기
Linear Regression 선형회귀 (Numpy)
: 직선으로 표현
- numpy가 제공하는 함수를 이용해 1차 직선을 만들어 그래프로 비교하자
- np.polyfit : 직선을 구성하기 위한 계수 계산
(y = ax+b 에서 기울기와 y절편을 구함)
- np.poly1d : polyfit에서 찾은 계수로 함수로 만들어 줌

-
np.polyfit(x축데이터, y축데이터, 그래프 차수) -> 직선 1차식

-
함수 활용

-
그래프 그리기
linspace : 등간격 데이터 생성


-
fx, f1(fx)를 넣어 경향선 그리기
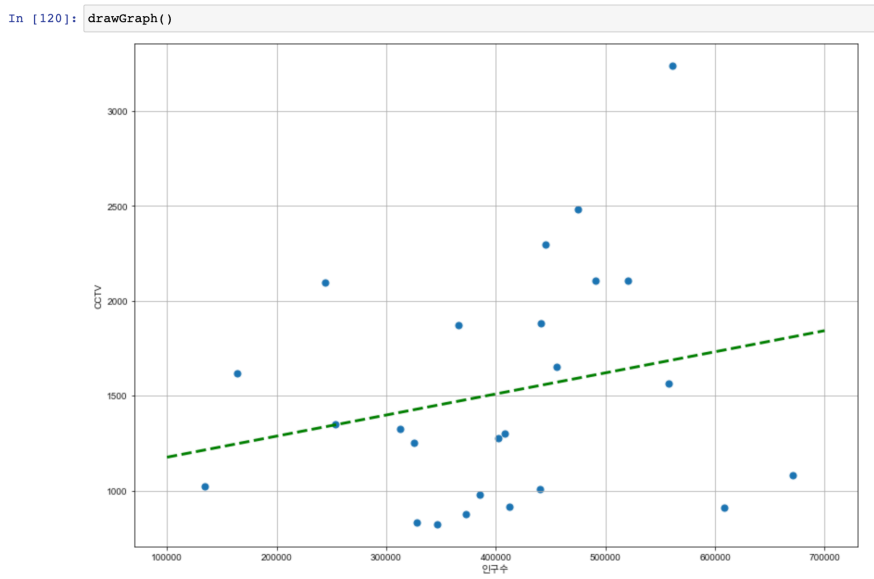
데이터 시각화. 강조
(p.141)
- 경향에서 벗어난 데이터 강조하기

: 위에서 만든 경향선 만든 것 활용해서
오차가 많이 나는 데이터를 내림차순/오름차순으로 정렬
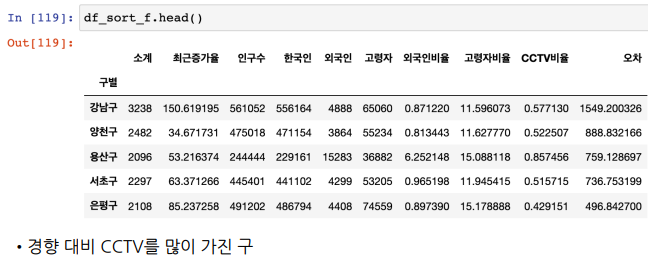
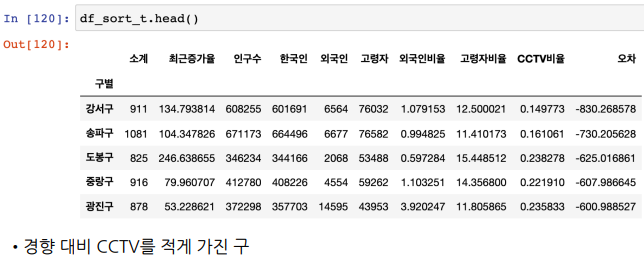
-
컬러맵 세팅

-
Matplot Color Map 종류 (Cmap)
https://jrc-park.tistory.com/155 -
그래프 그리기
반복문 : 내림차순/오름차순 각각 상위 5개씩, 글자를 찍을 x,y값 위치좌표 주고, 구 이름 찍기
(x1.02, x0.98을 하는 이유 : 마커랑 겹치지 않게 조금씩 벗어나라고)
plt.text() : 글자를 찍는 함수




- 데이터 저장

20-01 plotting기초 (plot)
https://wikidocs.net/159927
