GoogleMaps, Folium, Seaborn, Pandas의 Pivot_table
범죄현황 데이터 개요 및 읽어오기


- 옵션 thousands="," : 데이터의 숫자값들이 콤마를 사용하고 있어서 문자로 인식될 수 있다. 천단위 구분을 알려주면 콤마를 제거하고 숫자형으로 읽는다
- encoding = "euc-kr"
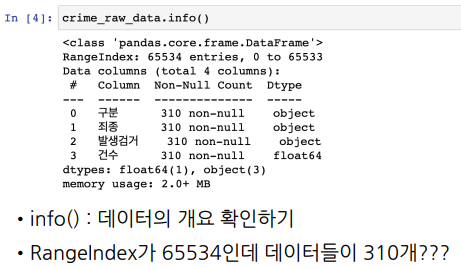
- 데이터 읽어온 후 head(), info() 찍어보기
- index가 0 to 65533이라고 써있는데, 데이터값은 310개 → "이상하구나" 생각, 원인찾기
데이터 정리하기
- 특정 컬럼의 unique 조사 → '죄종' 컬럼에 NaN 값이 있구나

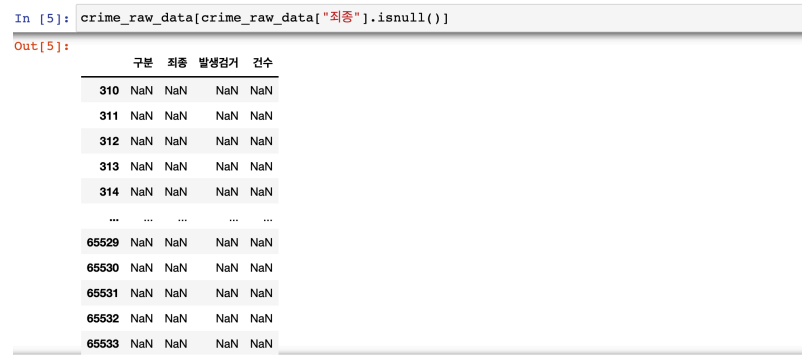
- isnull() : NaN만 검색해서 추출해보기 → 이게 원인이 맞구나!
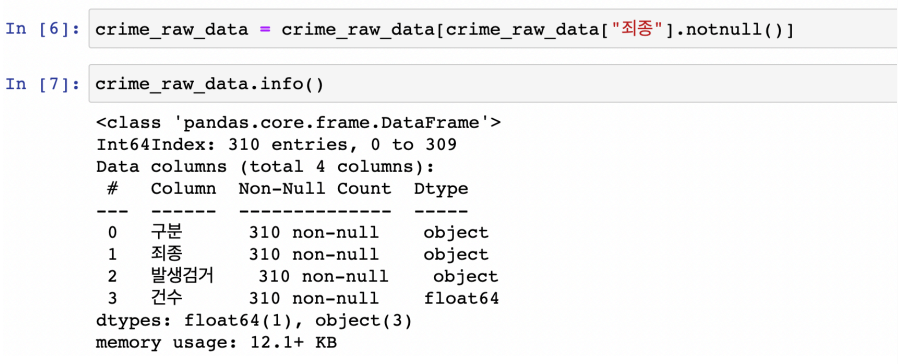
- notnull() : NaN이 아닌 데이터만 가져오기 → 용량도 확 줄어들었다
데이터 확인
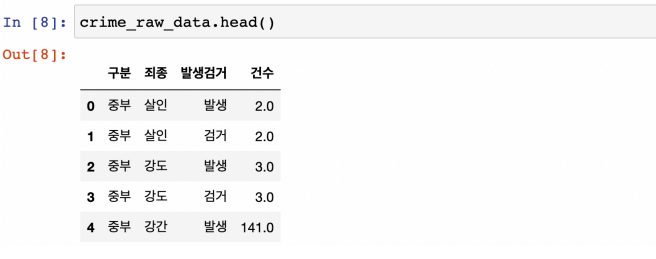
- 세로축에 서울시 구이름, 가로축에 5대 범죄 수치가 있으면 좋겠다
- 즉, raw data를 원하는 데이터 열로 재배치할 필요가 있다
→ pivot table 하기!
- Pandas의 pivot_table
- 예제 : sales-funnel.xlsx
- raw data
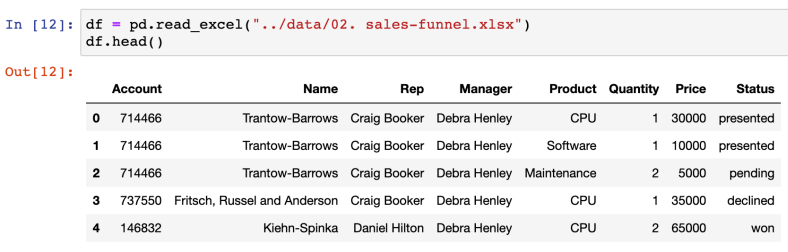
- pivot_table
: 특정 인덱스(컬럼)을 중심축(기준)으로 하여 데이터를 그룹화하고 정리
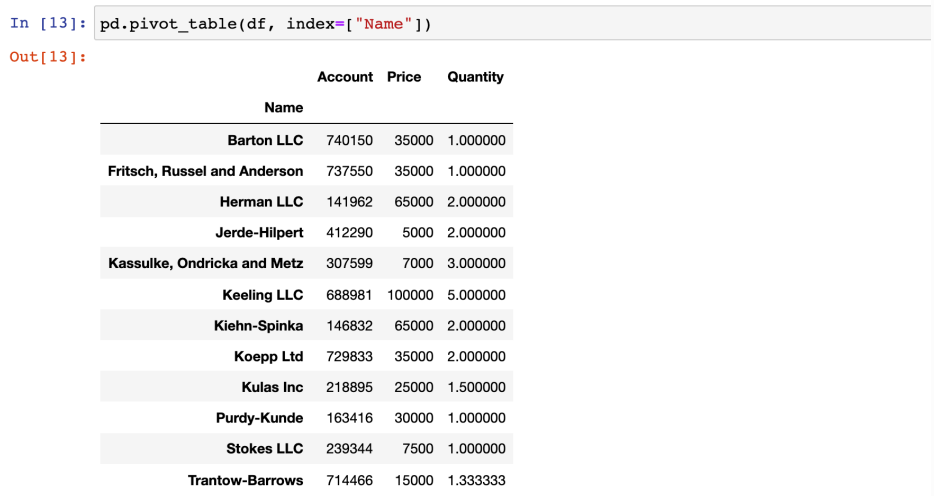
- index를 여러개 지정할 수 있음
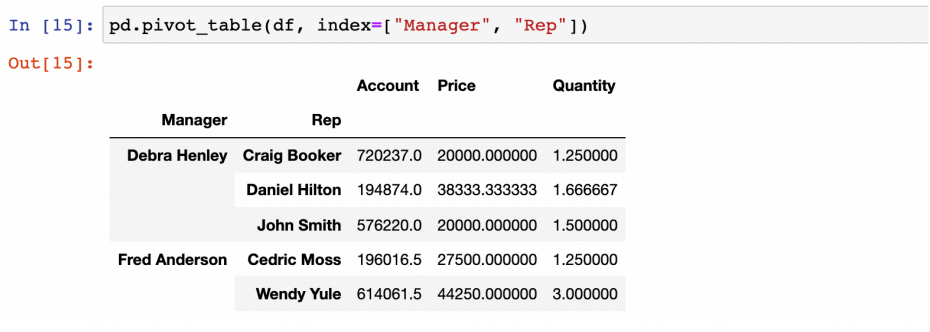
- value를 지정할 수 있음
(중복된 데이터는 디폴트로 평균 연산하여 표시)
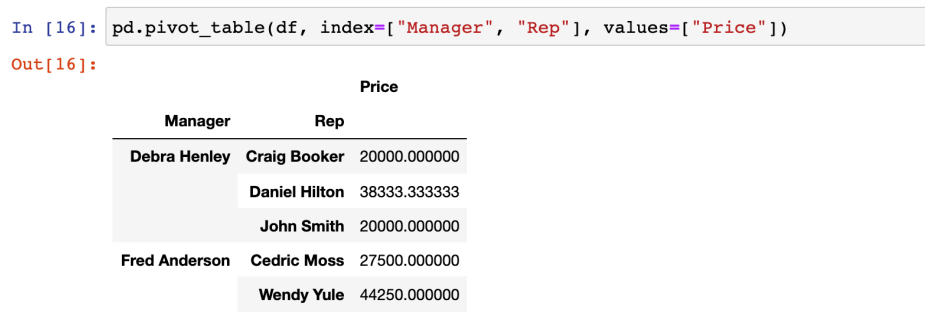
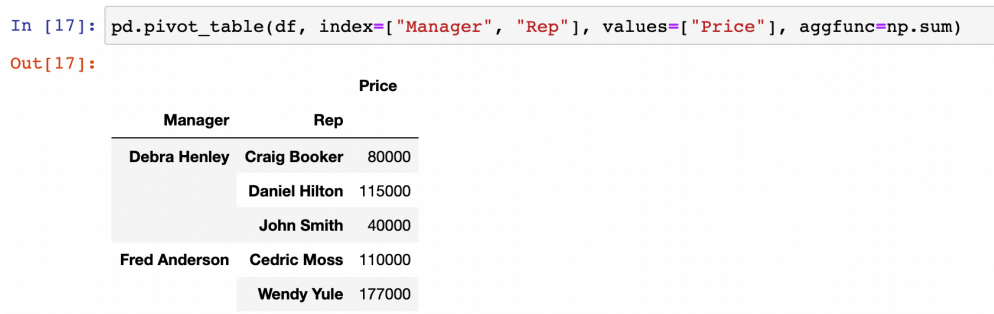
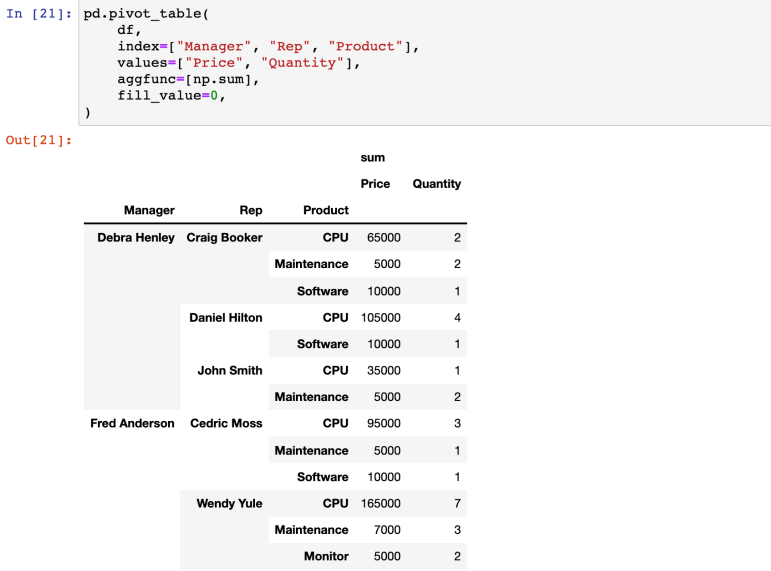
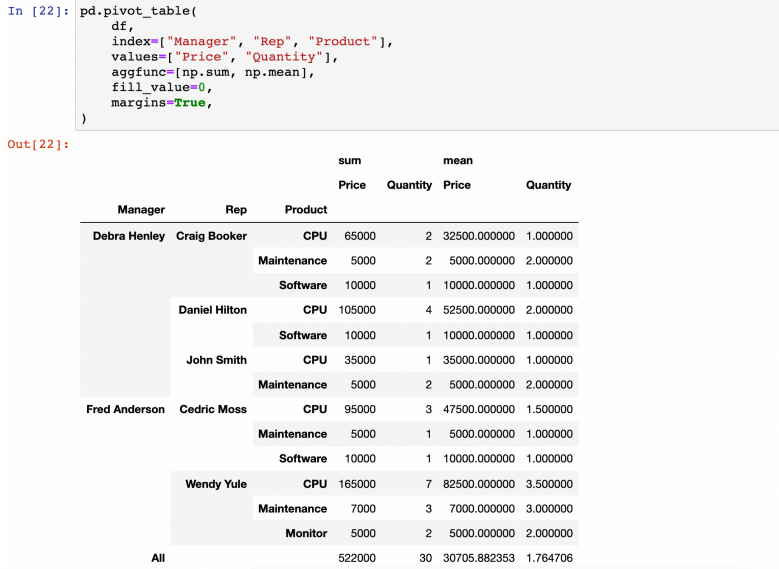
- values에 함수를 적용할 수 있다
(aggfunc 옵션 지정, 디폴트는 평균)
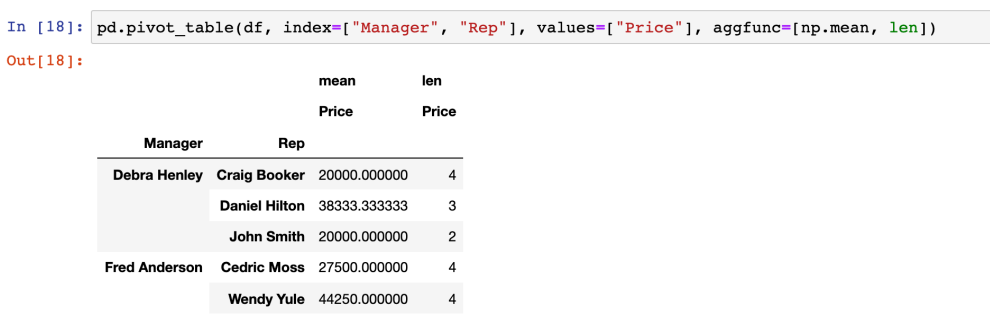
- 갯수 적용 : len
- 분류를 지정 : Columns 옵션
(Product 컬럼 안의 내용으로 분류해서 각각의 가격을 보기)
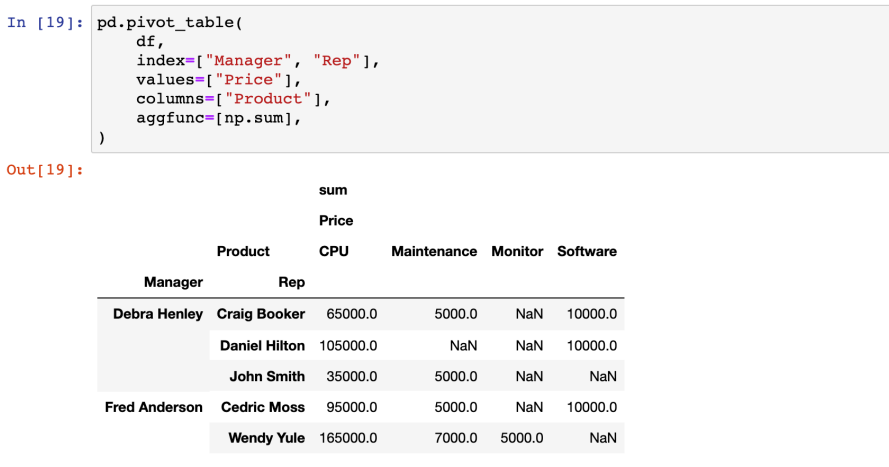
- NaN 값에 대한 처리 : fill_value 옵션
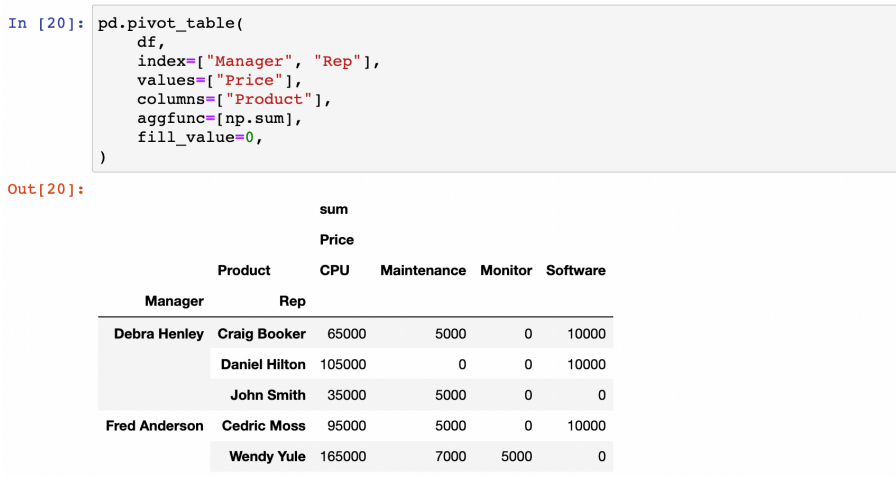
활용 sample
서울시 범죄현황 데이터 정리
- raw data

-
경찰서 이름을 index로 하고, 죄종과 발생/검거를 나누어 표시하도록 정리
: crime_station -
사건의 합을 기록하기 위해 aggfunc 옵션에 sum 사용

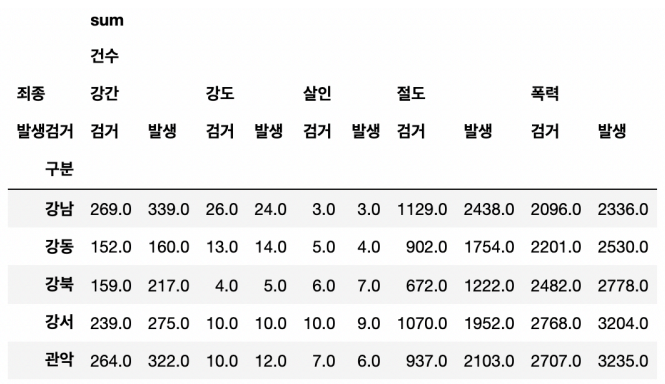
-
피봇테이블을 적용하면 column이나 index가 다중으로 잡힌다는 함정!
: MultiIndex에 무려 4개가 잡힌다

-
multi index에 접근하는 방법
ex: 구별 강도 검거 건수의 합계
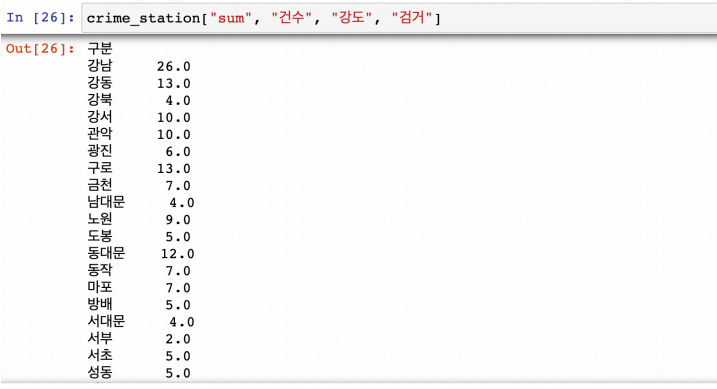
-
다중 컬럼에서 특정 컬럼 제거 : droplevel()
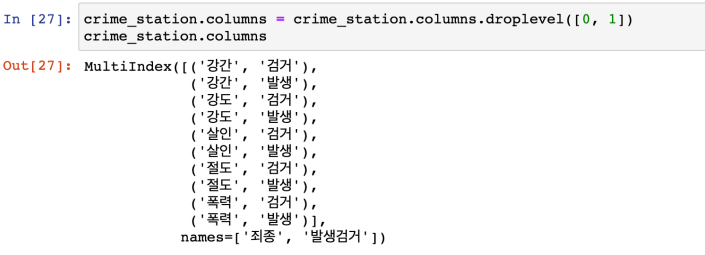
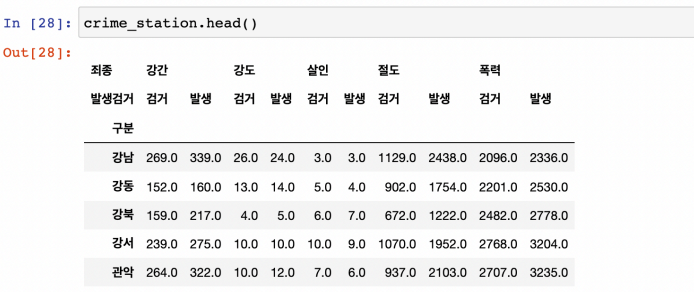
-
index 찍어보기 : 경찰서 이름으로 되어있다 → 목적에 맞게, 경찰서 이름으로 구이름을 알아내야 한다

- 파이썬 모듈 설치
Python 자체가 항상 사용할 모듈은 직접 설치해야 한다
anaconda에 많은 모듈이 포함되어 있는 덕분에 하지 않지만, 직접 설치도 할 수 있어야 한다
pip명령과 conda명령
- pip 명령 : 파이썬의 공식 모듈 관리자
- pip list : 현재 설치된 모듈 리스트 반환
- pip install (module_name) : 모듈 설치
- pip uninstall (module_name) : 모듈 제거
- 두 가지 방법
!pip list
get_ipython().system("pip list")
- conda 명령 : 아나콘다에서 배포한 모듈 관리자. 채널이 존재
- conda list
- conda install (module_name)
- conda uninstall (module_name)
- conda install -c (channel_name) (module_name) : 지정된 배포 채널에서 모듈 설치
- google maps api 사용 준비
- index 찍어보기 : 경찰서 이름으로 되어있다 → 목적에 맞게, 경찰서 이름으로 구이름을 알아내야 한다

- python의 for문
- for문 : 들여쓰기(indent)

- list comprehension

- iterrows()
Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면, n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때 iterrows() 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
google maps에서 구별 정보를 얻어서 데이터를 정리
- 구글맵 import

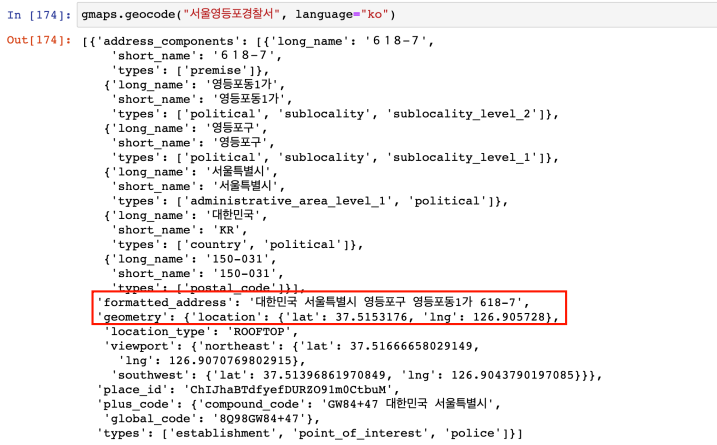
- 구글맵 API 테스트
- 전체 결과 크기가 1인 리스트 → 인덱스로 접근 (tmp[0])
- 큰 리스트 안에 dict형 구조 → dict 데이터를 얻는 get명령을 사용
- 원하는 데이터 뽑아내기

- 전체 주소에서 구이름만 가져오기
- split() : 띄어쓰기 기준으로 나눔

- split() : 띄어쓰기 기준으로 나눔
- 추출한 정보를 담을 컬럼 생성 (구이름, 위도, 경도)
- 우선 nan값으로 채워넣기
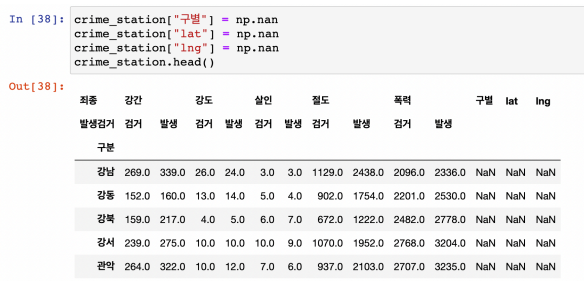
- 우선 nan값으로 채워넣기
- 반복문을 이용해서 위 표의 NaN을 모두 채우자
- crime_station에서 인덱스(idx)와 나머지(rows)를 받아서 반복문을 수행
- google maps에 던져줄 검색어 (station_name) 만들기
- loc 옵션을 사용 : 구글 검색에서 얻은 정보로 칸채우기
(슬라이싱, df.loc[행인덱스값, 열인덱스값] 으로 접근)

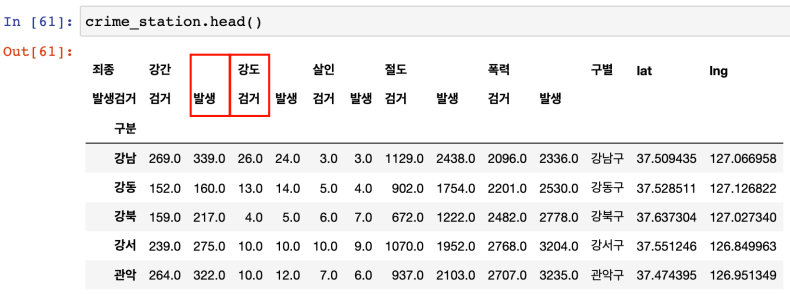
- 보기 좋게, 컬럼 합쳐서 재지정하기
- tmp라는 리스트에 합치기
- get_level_values 이용
- list comprehension 이용
- 컬럼명 지정 : df.columns = [리스트]
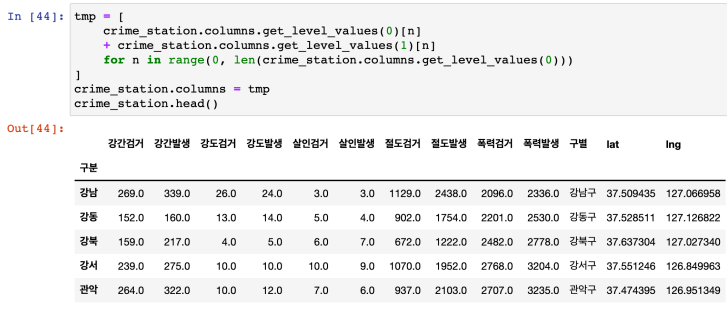
- 저장

구별 데이터로 변경하기
- 경찰서별 데이터 → 구별 데이터로 바꾸고 싶다
- 서울은 한 구에 경찰서가 두 곳인 구가 있음에 유의
- 바로 위에 저장한 것 다시 읽어와서 'crime_anal_station'으로 다루자. 경찰서별로 저장된 데이터.
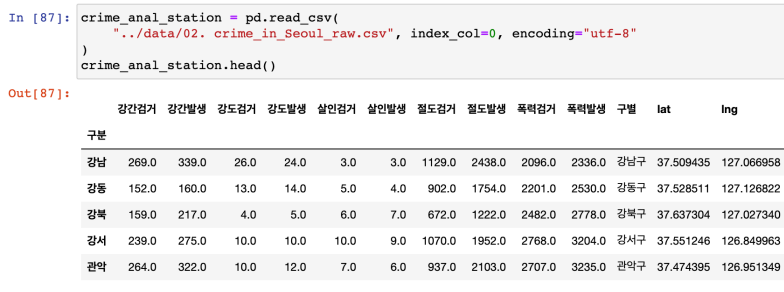
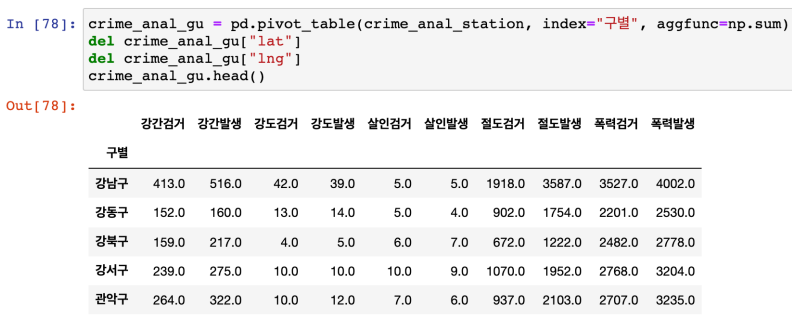
- pivot_table을 이용해 '구별'을 index로 바꾸고, 필요없는 컬럼 삭제.
구별로 정리한건 'crime_anal_gu'로 저장
- 검거율 생성 : 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu["강도검거"] / crime_anal_gu["강도발생"]- 다수의 컬럼값을 특정 컬럼값으로 나눗셈
crime_anal_gu[["강도검거", "살인검거"]].div(crime_anal_gu["강도발생"], axis=0).head(3)
# 가로축 연산 axis=0
- 다수의 컬럼을 다수의 컬럼으로 각각 나누기
- 분자 numerator / 분모 denominator
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[num].div(crime_anal_gu[den].values).head()target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()
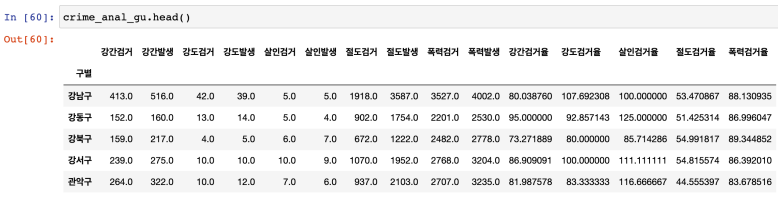
- 필요 없는 컬럼 제거 : 2가지 방법
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
crime_anal_gu.drop(["살인검거", "절도검거", "폭력검거"], axis=1, inplace=True)
crime_anal_gu.head()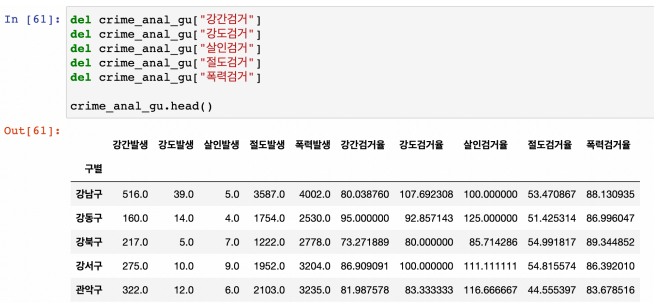
-
그래프를 그리기 위해(heatmap) 100 이상의 수치는 100으로 만든다
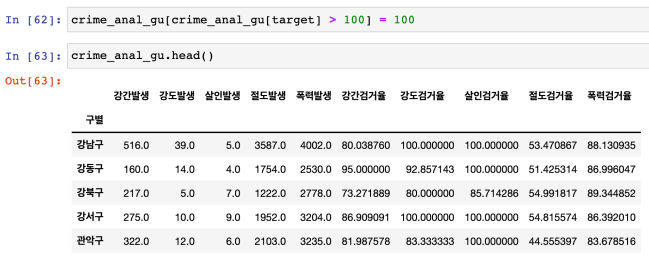
-
컬럼 이름 변경 : rename()
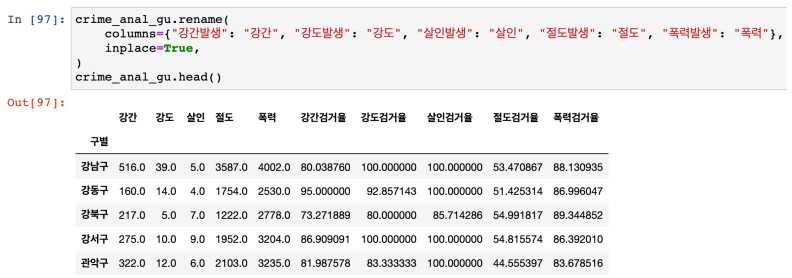
서울시 범죄현황 데이터 최종 정리
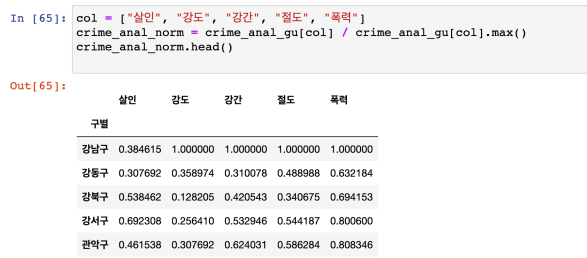
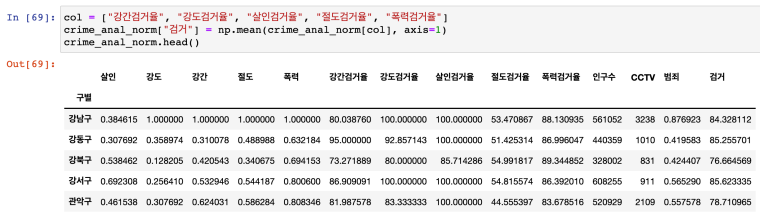
- 정규화 데이터 생성
: max 값으로 나누기 (최소값 0 ~ 최고값 1), 전체 양수인 경우
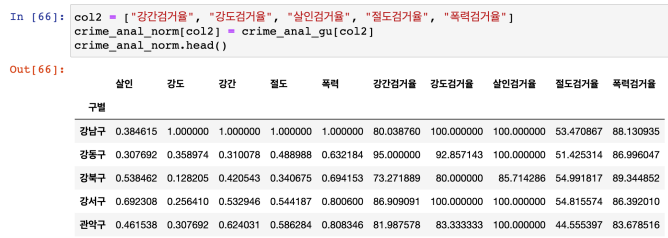
- 검거율 컬럼 가져와서 합치기
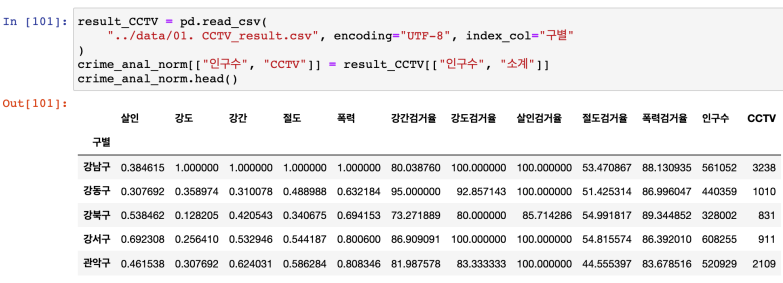
- EDA01에서 했던 CCTV 자료에서 인구수와 CCTV 수 가져오기
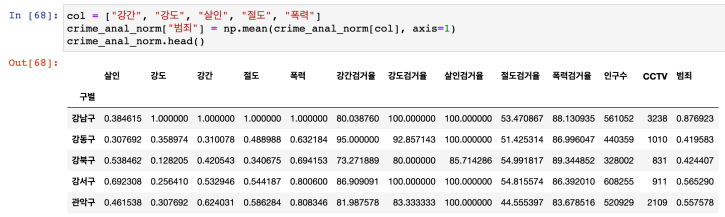
- '범죄' 컬럼 : 정규화된 5대 범죄발생건수 전체의 평균
'검거' 컬럼 : 검거율 전체의 평균
seaborn
- matplotlib으로 하기 복잡한 걸 seaborn에서 더 편하게 할 수 있다
- seaborn은 matplotlib과 함께 실행된다
(둘다 import해서 쓰기)

- import 하기만 해도 그래프 스타일이 바뀐다
set_style : 배경색
sns.set_style("white")
sns.set_style("dark")
sns.set_style("whitegrid") : 격자
despine
sns.despine() : 테두리가 x,y축에만
sns.despine(offset=10) : 축에서 간격 떨어지는 효과
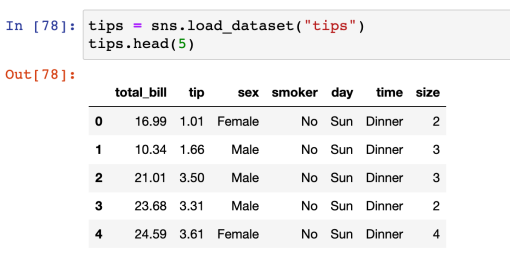
- 실습(tips)
- 내장된 실습용 데이터 중 하나인 tips
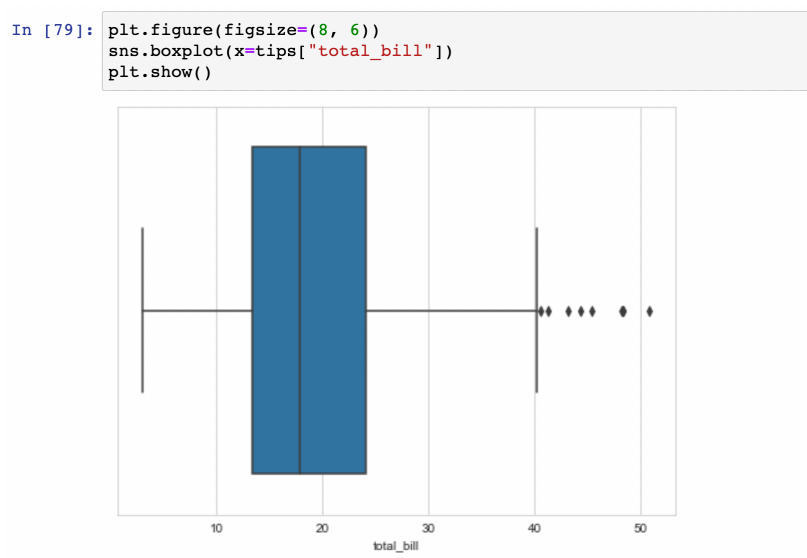
boxplot
- total_bill 컬럼만 가지고 그리기
- 가운데 선 : median값 (평균x)
- 왼쪽/오른쪽 끝 : lower/upper fence
- 그 이상 값 : outlier (표본 중 다른 대상들과 확연히 구분되는 값)
- boxplot에 컬럼을 지정(x,y축)
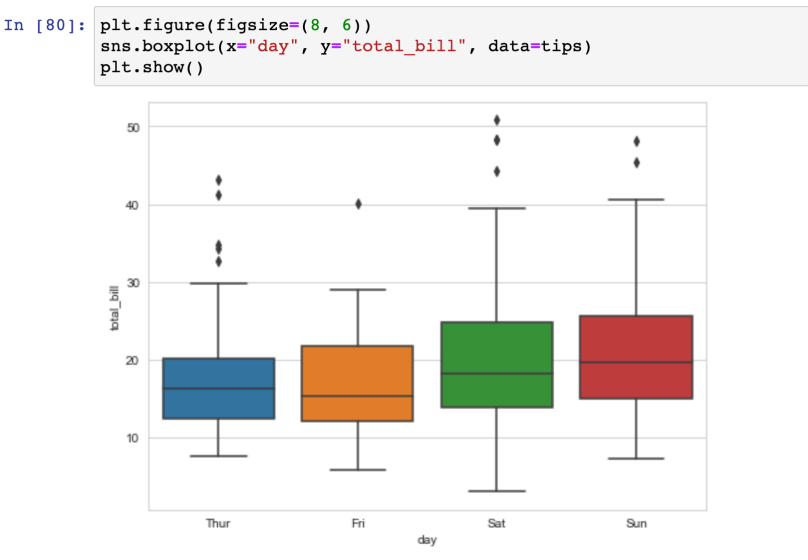
- 컬럼을 지정하고 구분할 수 있다 (hue 옵션)
- palette 옵션 : 색상 지정
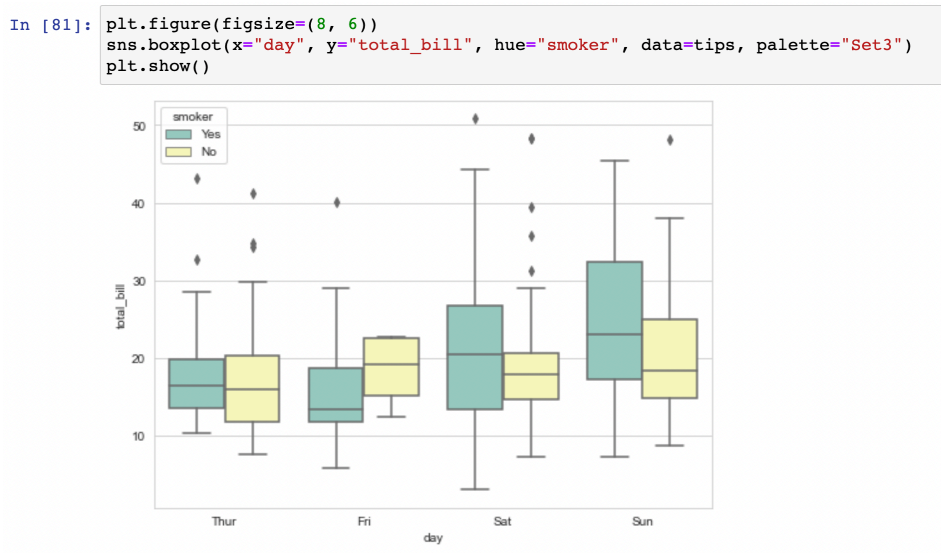
- palette 옵션 : 색상 지정
swarmplot
- boxplot과 겹쳐쓰면 좋다
- color : 점의 진하기 설정
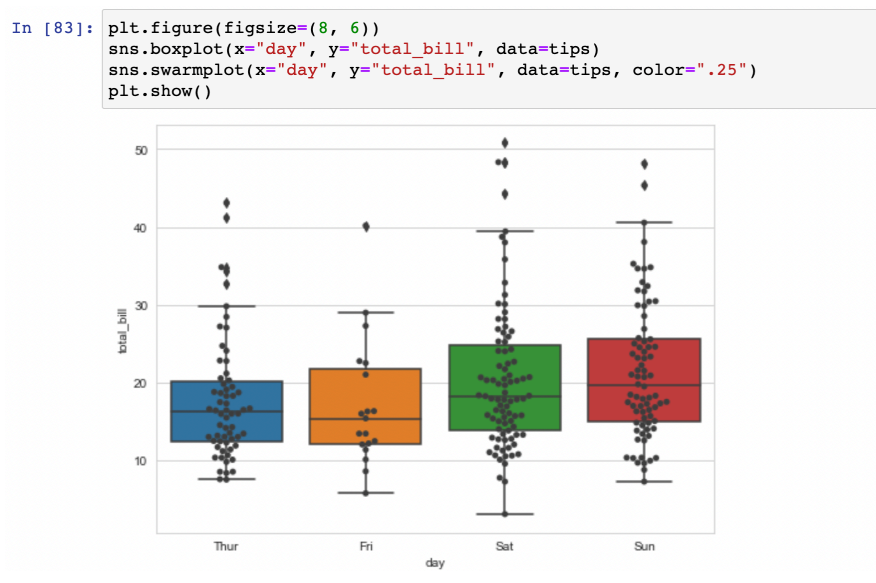
- color : 점의 진하기 설정
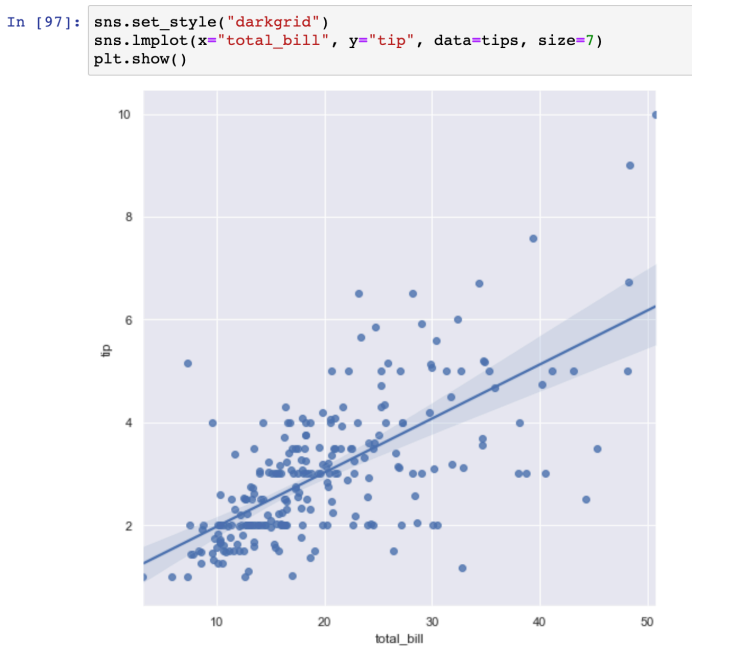
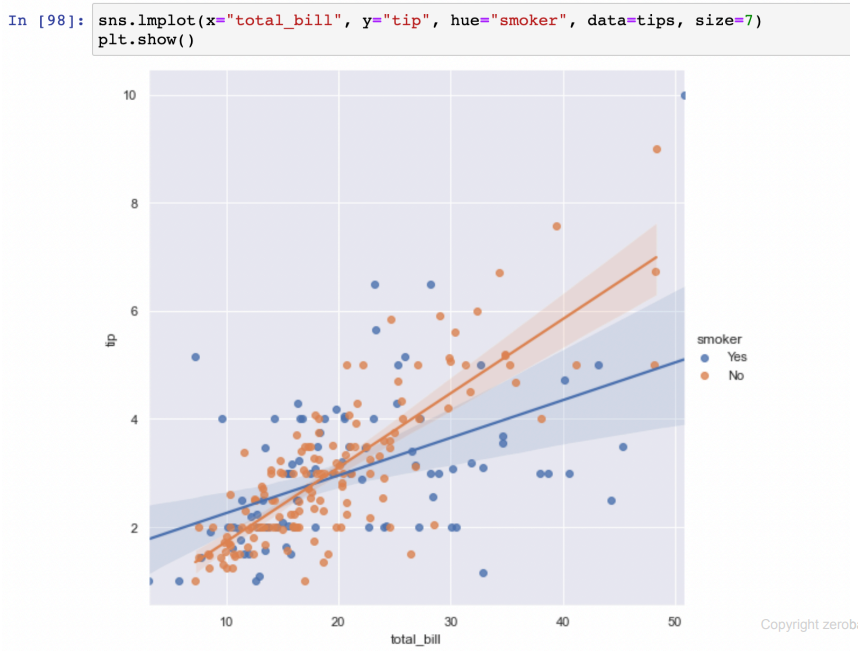
lmplot
- linear regression plot을 그려줌
- 기본적으로 scatter + 경향선 + 음영
- 음영이 좁을 수록 강한 상관관계를 가지고 있는 부분
- hue 옵션 사용 가능
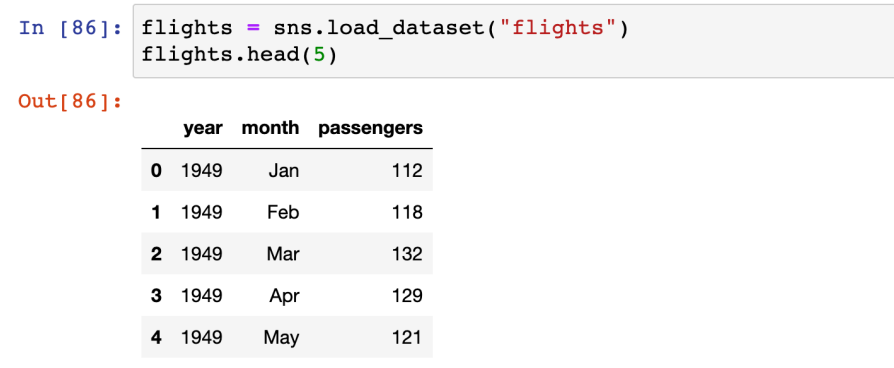
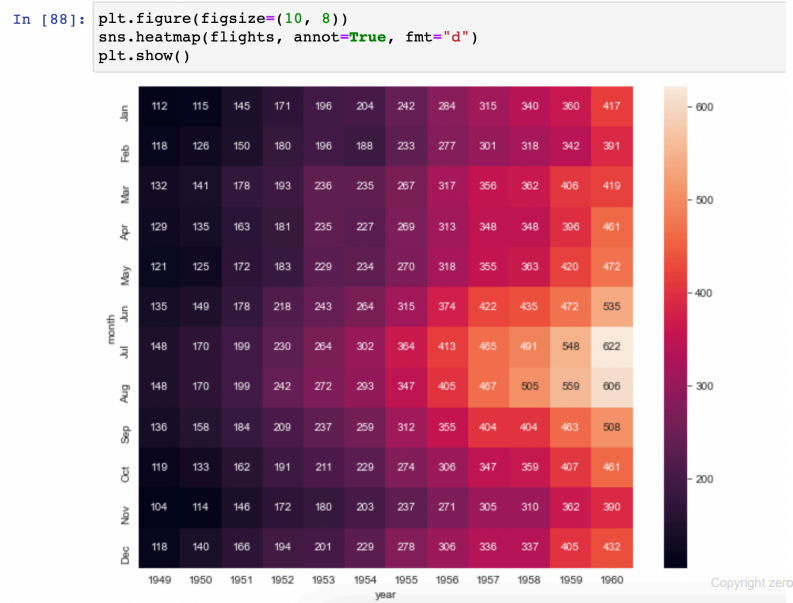
- 실습(flights)
- 어떤 항공사의 연도, 월, 승객수
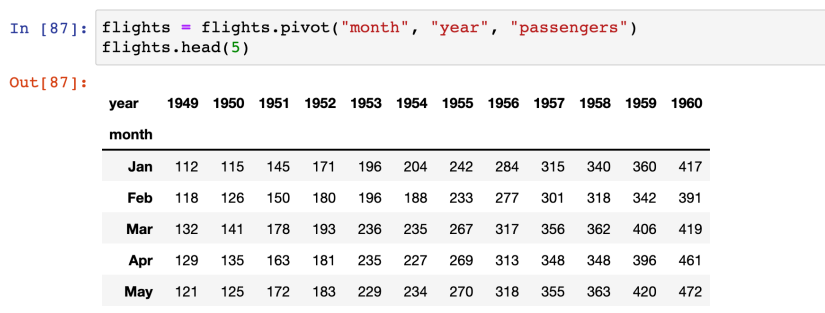
- pivot 사용해서 가공하기 (pivot_table 아니고 걍 pivot으로 가능)
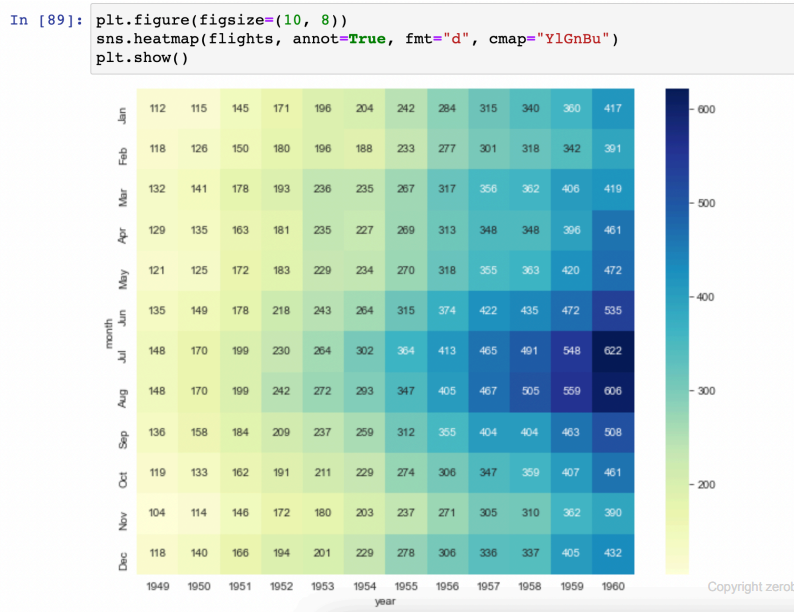
heatmap
- 전체 경향을 알 수 있다
- annot=True : 값을 표기
- fmt="d" : 소숫점 표기 옵션. d : 정수
- cmap : colormap 옵션 (색상표 검색해서 사용)
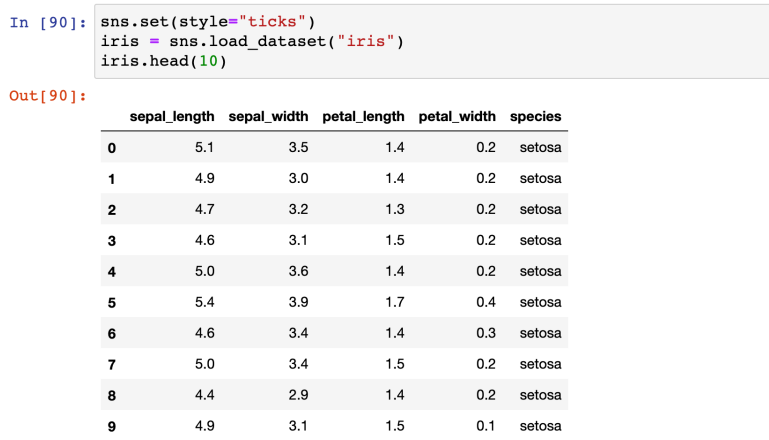
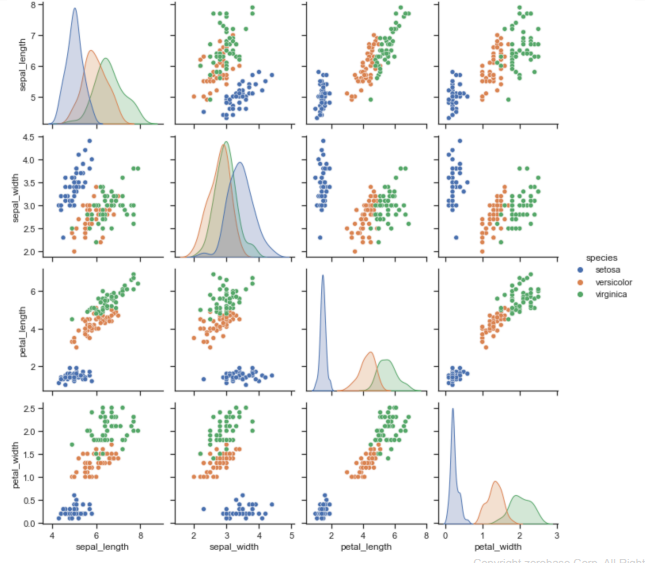
- 실습(iris)
- 꽃의 품종에 따라 꽃잎과 꽃받침의 가로세로 길이
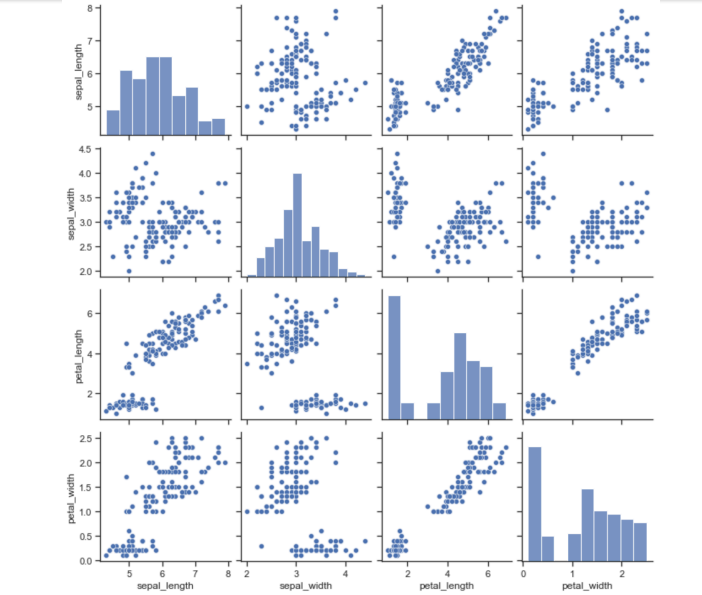
pairplot
- 특성별로 상관관계를 파악하기 쉬움

- hue 옵션 적용

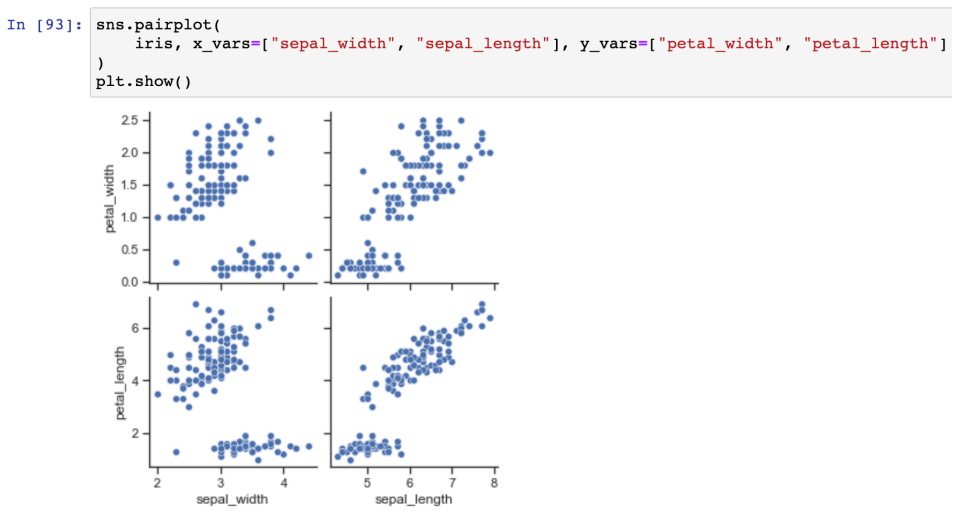
- 원하는 컬럼만 pairplot
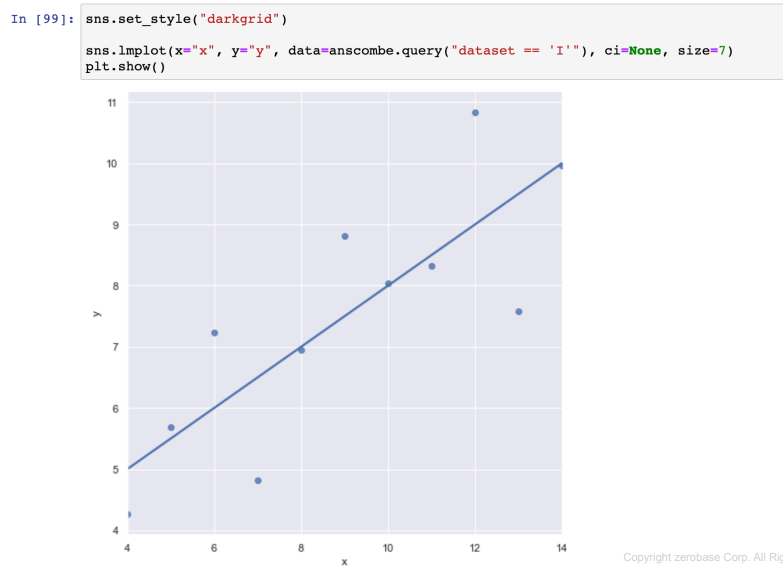
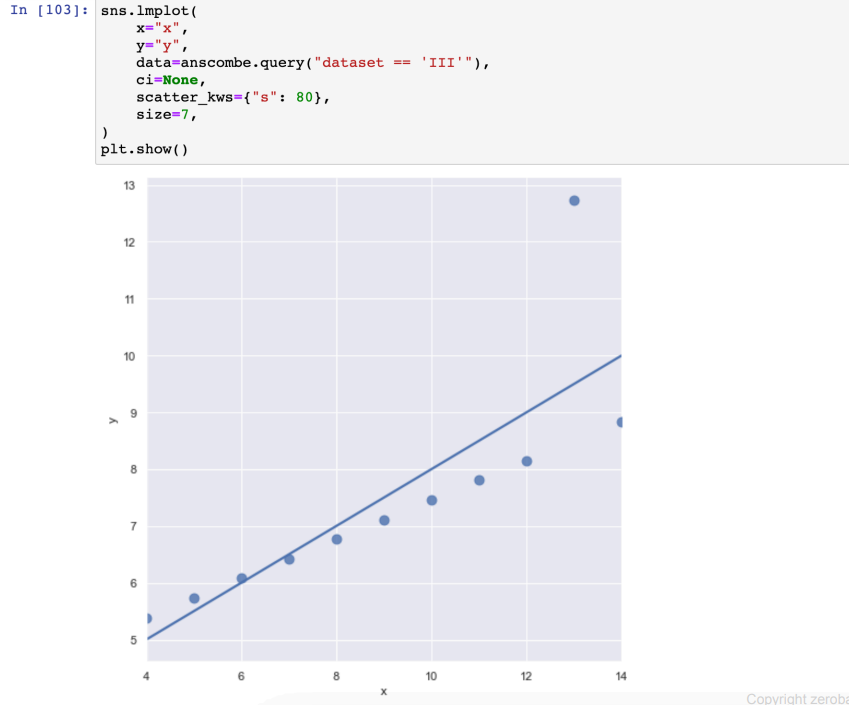
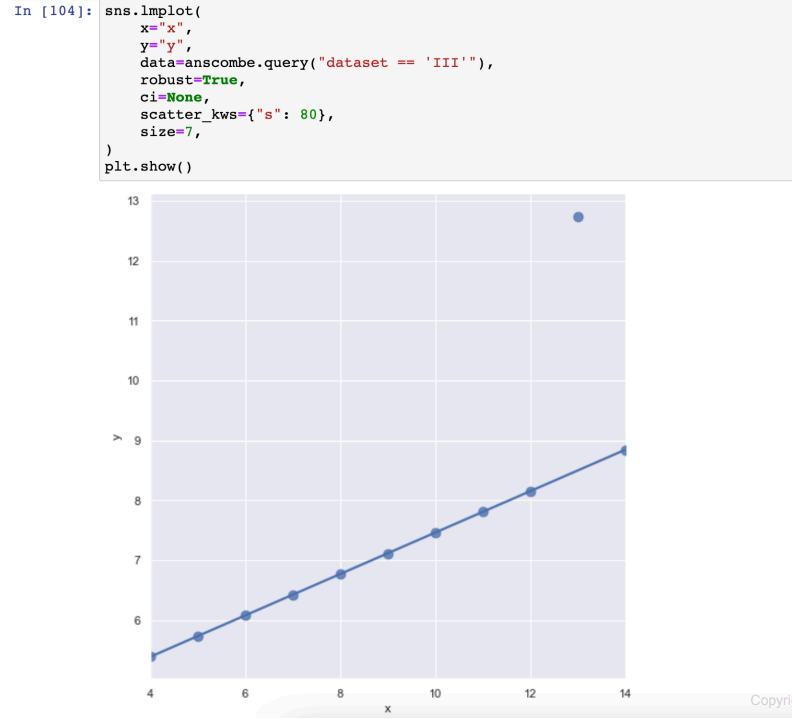
- 실습(anscombe)
-
dataset에 따라 1차식, 2차식

-
lmplot
- query : 데이터 지정
- ci=None : 음영부분 끄기
- scatter_kws : 마커 사이즈
- order=1/2 : 1/2차식
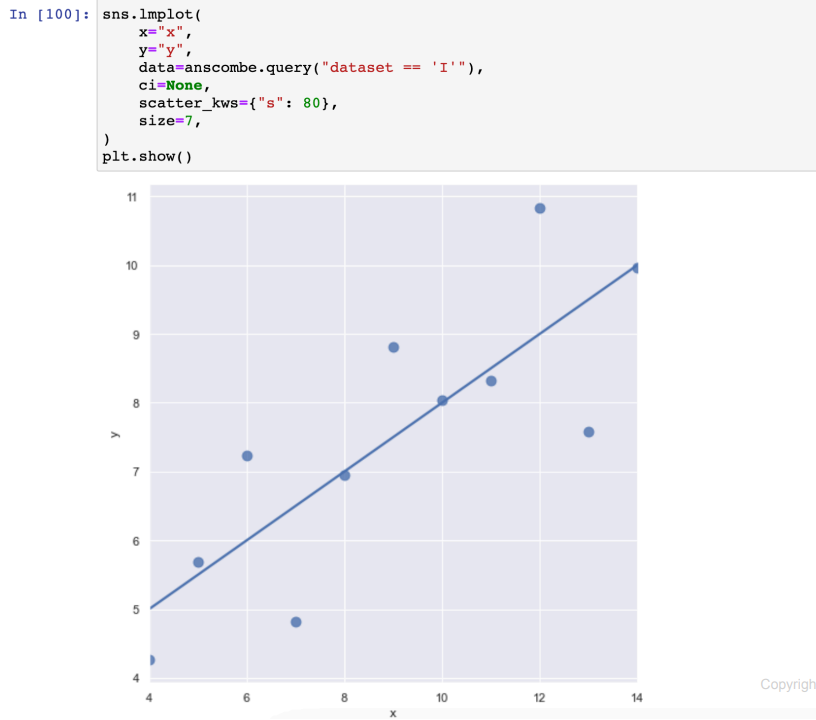
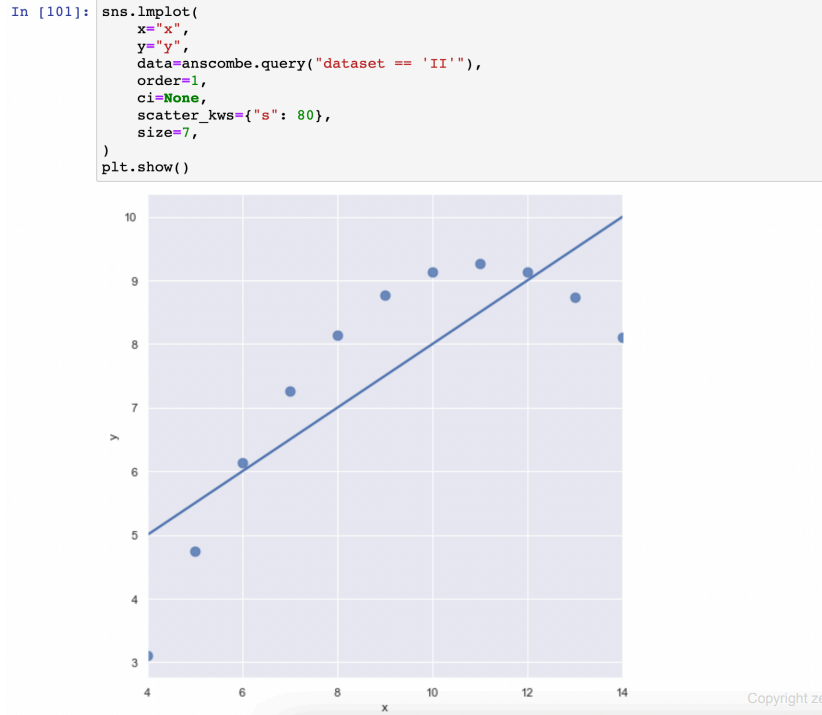
-
robust=True : 많이 벗어난 데이터 (outlier)는 없는 셈 친다
범죄현황데이터 시각화
Folium 지도 시각화
서울시범죄현황 지도시각화
서울시범죄현황 장소별 분석
특정 컬럼 제거
df.columns.droplevel()
del crime_anal_gu["강도검거"]
crime_anal_gu.drop(["살인검거", "절도검거", "폭력검거"], axis=1, inplace=True)
crime_station.columns.droplevel([0, 1]) pandas의 date_range
반복문에서 사용하는 iterrows()함수
- idx, rows 인자
- 컬럼 이름을 바로 사용할 수 있어서 가독성에 도움을 준다
- DataFrame을 행 단위로 한줄씩 반복문에서 사용하도록 반환한다
- pandas에서 csv파일을 읽어올 때, 한글이 깨지는 경우 주는 옵션 : euc-kr
- 컬럼명 전체 조회 : df.columns
