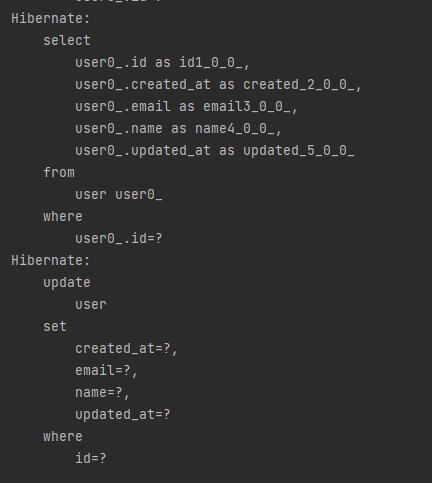
먼저 Data.sql 사용해보자.
Data.sql 파일을 리소스 하위에 두면 jPA가 로딩할때 해당 쿼리를 한번 실행해 준다.!!!!
Test할때 개 꿀~
call next value for hibernate_sequence;
insert into user (`id`,`name`,`email`,`created_at`,`updated_at`) values (1, 'martin','martin@fast.com',now(),now());
call next value for hibernate_sequence;
insert into user (`id`,`name`,`email`,`created_at`,`updated_at`) values (2, 'demis','demis@fast.com',now(),now());
call next value for hibernate_sequence;
insert into user (`id`,`name`,`email`,`created_at`,`updated_at`) values (3, 'sopia','sopia@slow.com',now(),now());
call next value for hibernate_sequence;
insert into user (`id`,`name`,`email`,`created_at`,`updated_at`) values (4, 'james','james@slow.com',now(),now());
call next value for hibernate_sequence;
insert into user (`id`,`name`,`email`,`created_at`,`updated_at`) values (5, 'martin','james@another.com',now(),now());이렇게 미리 들어갈 dml을 넣어준다.
Caused by: org.h2.jdbc.JdbcSQLSyntaxErrorException: Sequence "HIBERNATE_SEQUENCE" not found; SQL statement: 😡😡
nested exception is org.h2.jdbc.JdbcSQLSyntaxErrorException: Table "USER" not found; SQL statement:
insert into user (id,name,created_at,updated_at) values (1, 'martin','martin@fast.com',now(),now()) 😡😡😡😡
😡만약 위의같은 애러가 나면 아래와 같이 설정해주면 된다.😡
application.yml 설정을 변경해준다.
spring:
h2:
console:
enabled: true
jpa:
hibernate:
ddl-auto: create // 버젼 이슈때문에 넣었음..ddl을 자동으로 만들어줘야함..
show-sql: true
properties:
hibernate:
format_sql: true
defer-datasource-initialization: true // 버젼 이슈때문에 넣었음..
😡 버전이 맞지 않는다면 고생 할 수 있다 오류를 잘 보고 고쳐보자...ㅠㅠ내 3시간...
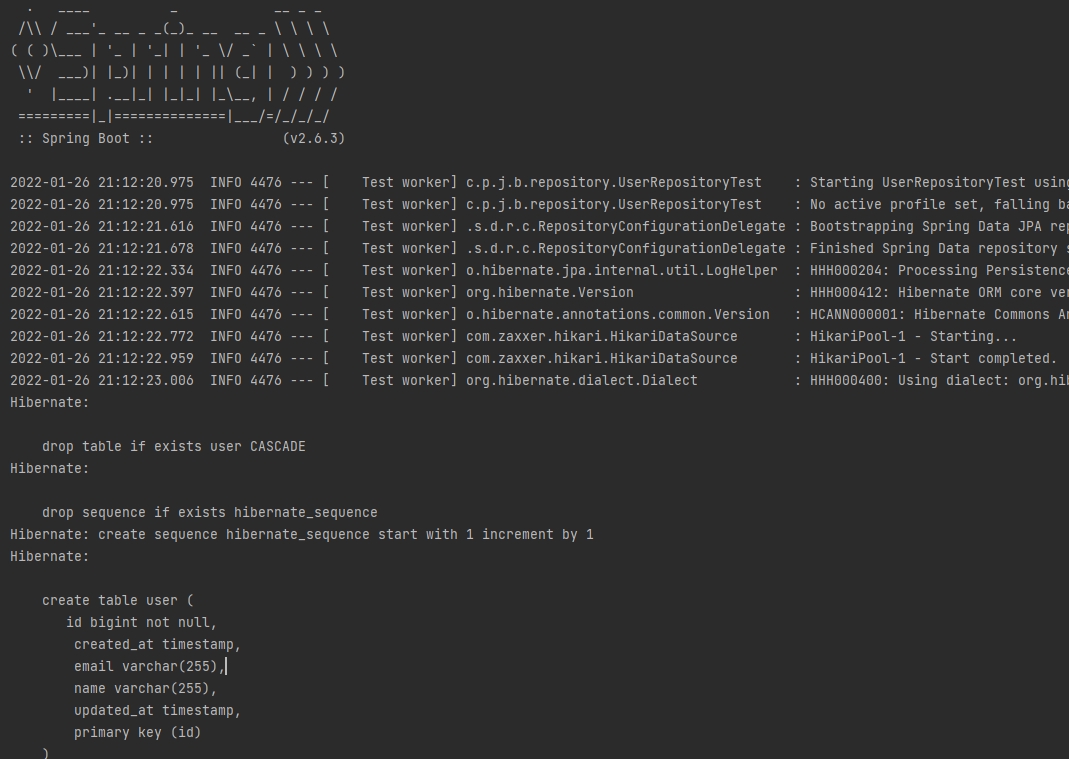
✅실행하면서 DDL 생성되고
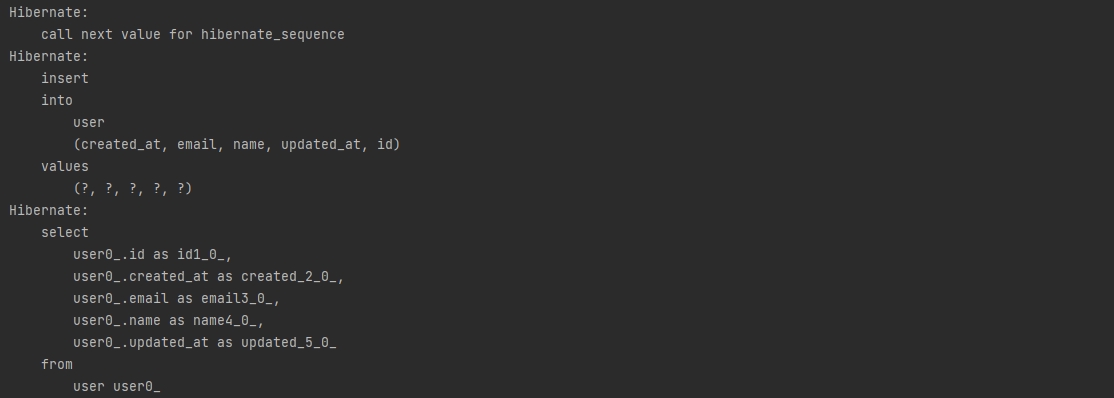
✅data.sql 잘 읽었고!!

✅Test 출력 값 잘 나온다. 휴.....
😎 JPA Repository Interface 상세 1에서 살펴봤던 JPA 기능들 사용해보자!!
기능의 설명은 JPA Repository Interface 상세 1 에 있으니 참고바라며
이 결과 값의 포인트는
사용한 메서드별로 Hibernate가 무슨 쿼리를 만들었는지
결과값이 어떻게 나오는지가 중요하다!!!😎😎
FIND
/*FIND = SELECT */
List<User> users = userRepository.findAll(Sort.by(Sort.Direction.DESC,"name"));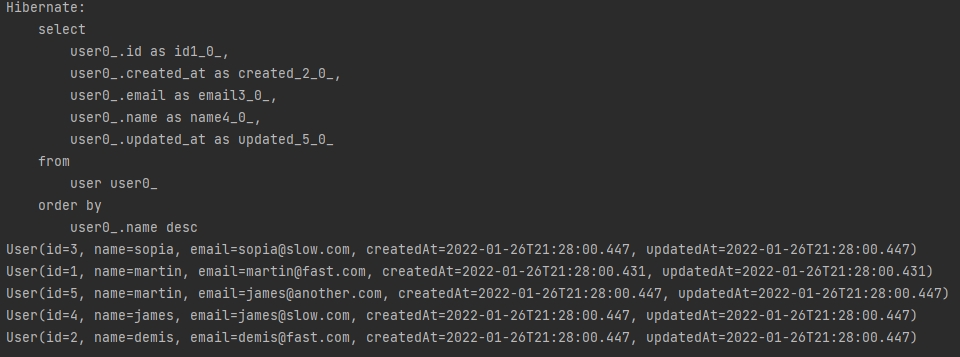
List<User> users = userRepository.findAllById(Lists.newArrayList(1L,3L,5L));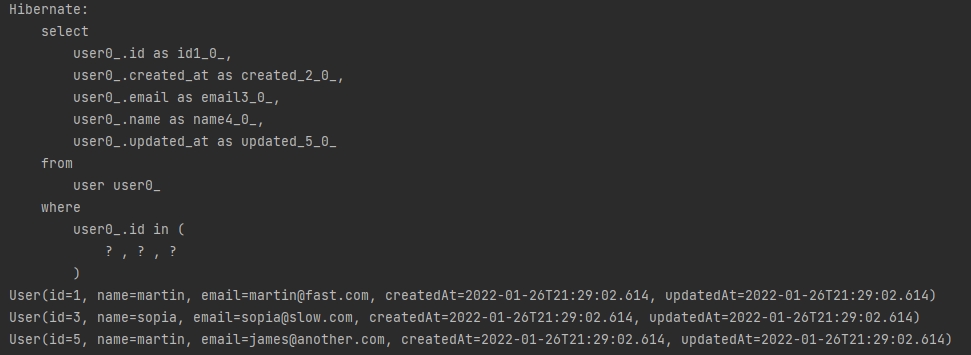
SAVE
/*SAVE = INSERT*/
User user1 = new User("jack","jack@fast.com");
User user2 = new User("steve","steve@fast.com");
userRepository.saveAll(Lists.newArrayList(user1,user2));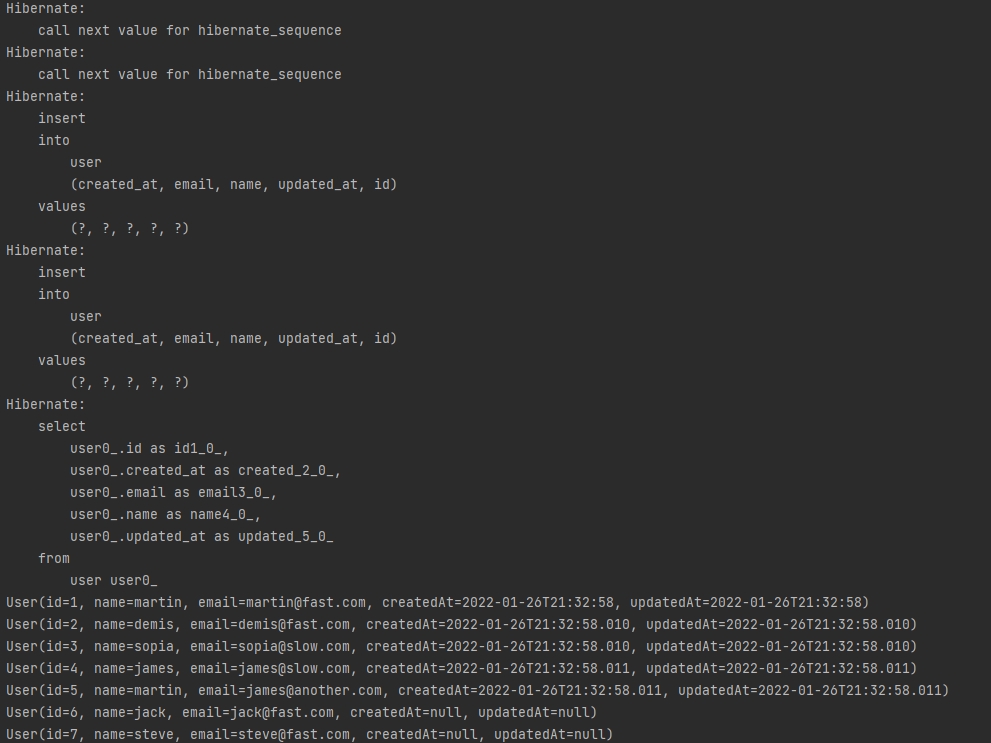
userRepository.save(user1);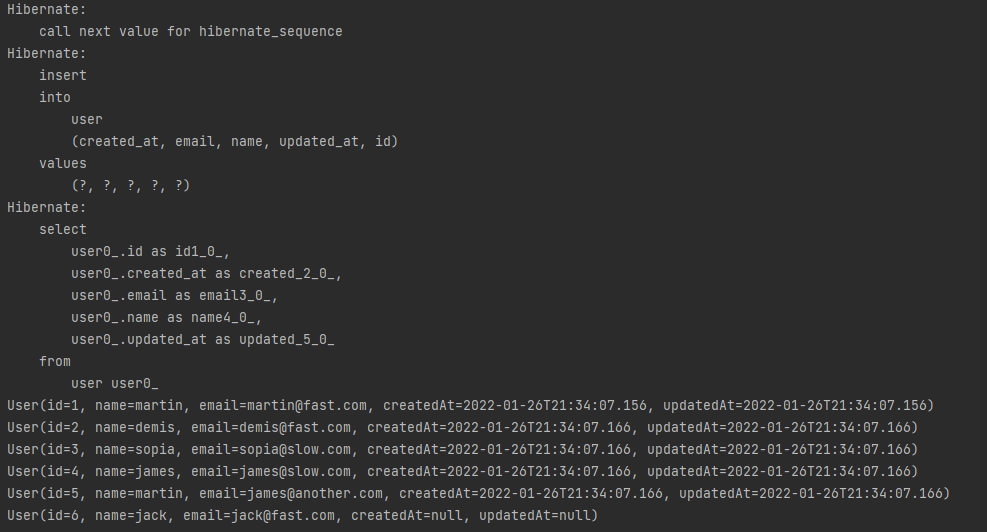
*** GET & FIND
/*GET*/
User user = userRepository.getOne(1L);
System.out.println(user);😡😡😡 에러가 뜰꺼다.
could not initialize proxy [com.practice.jpa.bookmanager.domain.User#1] - no Session
중요한건 getOne는 Lazy한 패치를 지원하고 있다.
그래서 @Transactional을 메서드 위에 붙여주면 된다.
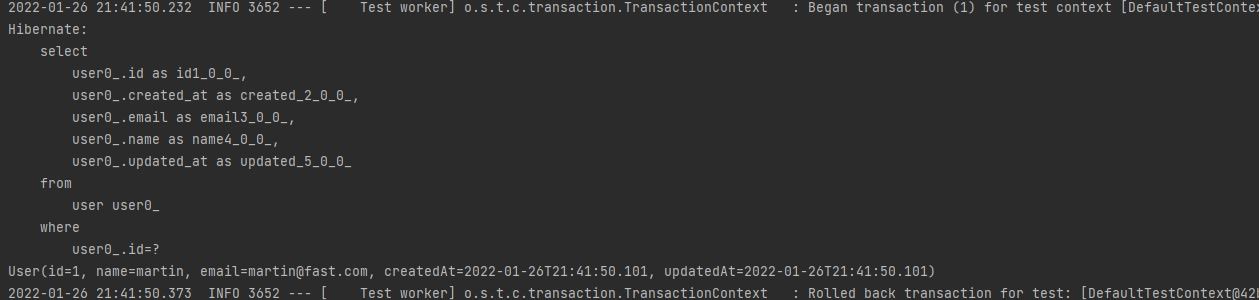
User user = userRepository.findById(1L).orElse(null); //orElse는 "결과값이 없으면 널로 보여줘" 라는 뜻이다. 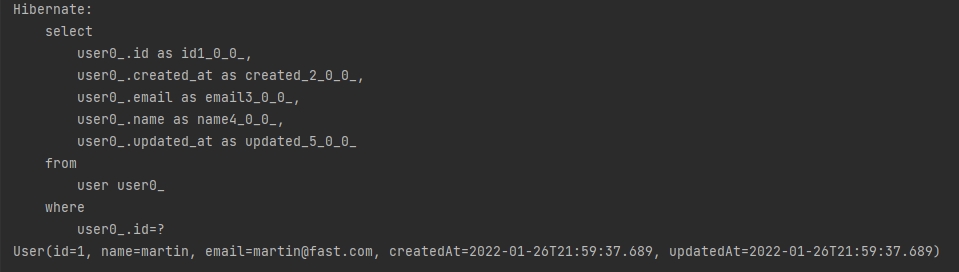
GET의 getOne과 findbyId는 Lazy Loading과 Eager Loading 차이가 있는데 이건 나중에 자세히 다뤄야 할거 같다.
FLUSH & COUNT
/*flush*/
userRepository.flush(); // flush는 쿼리에 영향을 가지 않는데 다음에 배울 영속성 파트에서 더 자세히 알아볼수 있다./*count*/
long count = userRepository.count();
System.out.println(count);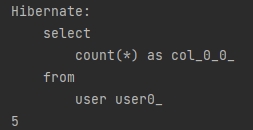
EXISTS
/*exists */
boolean exists = userRepository.existsById(1L);
System.out.println(exists);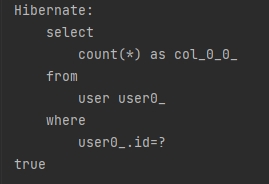
🤔 exists(존재) 함수를 썼는데 왜 쿼리는 count(*)를 쓸까?
existsById 메서드를 구현해놓은 라이브러리에 들어가서
QueryUtils 클래스의 getExistsQueryString 메서드가 리턴하는 걸 보면,
return String.format(COUNT_QUERY_STRING, countQueryPlaceHolder, entityName) + whereClause;COUNT_QUERY_STRING을 사용하여 호출한다.
COUNT_QUERY_STRING = "select count(%s) from %s x"; 이렇게 정의 되어있다.
그러니 count가 나오는 거 같다.
DELETE
🤚 delete는 Null이면안됨. delete 쿼리 실행하기전 Select 쿼리로 존재 여부를 확인하기때문!!
// entity를 사용하여 지우는 쿼리
userRepository.delete(userRepository.findById(1L).orElseThrow(RuntimeException::new)); 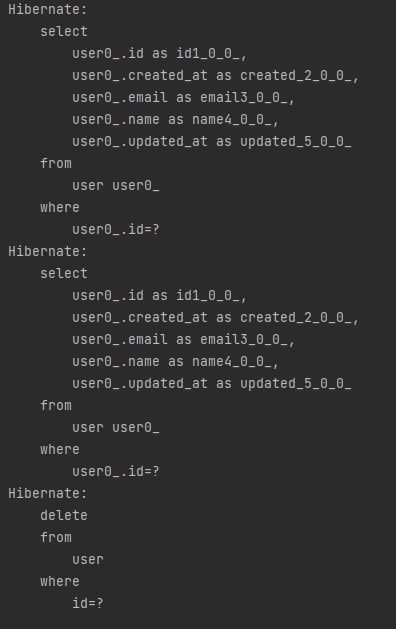
📝 실행 쿼리를 보면 딜리트 되기전엔 그 엔티티를 찾는다.
🤔🤚 하지만, 엔티티를 찾는 쿼리를 한번 더 실행하니.... 그럼 하나만 지울때는 ID(PK)를 사용하는게 좋겠다.
// ID 값을 이용하여 삭제
userRepository.deleteById(1L);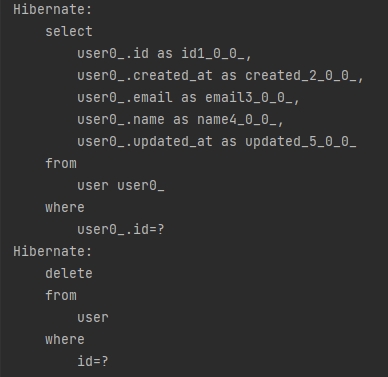

📝 이렇게 하면 엔티티를 찾는쿼리를 안한다. 그럼 하나만 지울때는 ID(PK)를 사용하는게 좋겠다.
🤔🤚 그럼 여러게 지워 볼까?
// ID를 사용하여 여러 컬럼 지우기
userRepository.deleteAllById(Lists.newArrayList(1L,3L));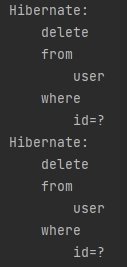
🤔🤚 잠깐만... deleteAllById 하니까 entity개수 만큼 쿼리를 때려버리네??? 성능이슈가 발생하겠군! 딜리트 하나 할때 마다 셀렉트도 하니... 컬럼 5개 지우면 쿼리를 10번 때려??
// 다 지우기
userRepository.deleteAll();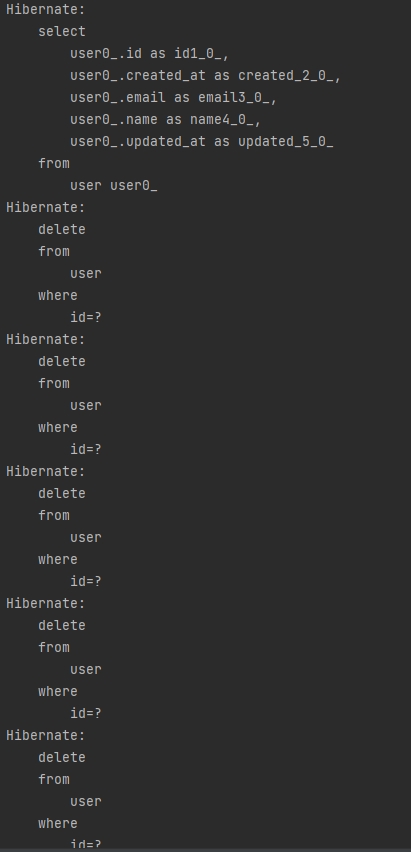
🤔🤚 잠깐만... 위랑 똑같이 deleteAll을 하니까 entity개수 만큼 쿼리를 때려버리네??? 성능이슈가 발생하겠군! 어떻하지????
✅ 그래서 사용하는 deleteAllInBatch
// 모든 엔티티 지우기
userRepository.deleteAllInBatch();
// ID를 사용하여 여러 컬럼 지우기
userRepository.deleteAllInBatch(userRepository.findAllById(Lists.newArrayList(1L,3L)));
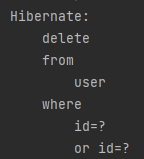
✅📝 deleteAllInBatch를 사용하여 모든 컬럼 다 지울때 깔끔하게 하나의 쿼리로 지워준다. 그리고 여러 id값을 이용하여 지울때도 where절에 OR문을 사용하여 깜끔하지 지워준다.
PAGEING
✅ 페이징은 정말 많은 곳에서 사용된다. 하지만 직접 페이징을 하려면 야간 복잡한 과정을 거쳐야한다. 하지만 이 페이징 기능을 사용 하면 편하고 쉽게 페이징이 가능하다.
// paging !!! 사용
Page<User> users = userRepository.findAll(PageRequest.of(1,3)); // page는 0페이지 부터 시작한다.
System.out.println(" 페이징 정보 : " + users);
System.out.println(" Size(한 페이지에 들어갈 컬럼 수) : 한 페이지에 " + users.getSize() + "개의 게시물이 들어가도록 해뒀다.");
System.out.println(" totalElements(총 컬럼 수) : 총 " + users.getTotalElements() + "개의 게시물이 있다.");
System.out.println(" totalPages(전체 페이지 수) : 총 " + users.getTotalPages() + "페이지가 있다.");
System.out.println(" Number(현재 페이지) : 지금 선택된 페이지는 " + users.getNumber() + "페이지 이다.");
System.out.println(" numberOfElements(내가 선택한 페이지의 컬럼개수) : 현재 이 페이지에는 " + users.getNumberOfElements() + "개의 게시물이 있다.");
System.out.println(" Sort(정렬 정보) : " + users.getSort() + "정렬 되어있다.");
users.getContent().forEach(System.out::println); // 현재 선택한 페이지의 컬럼들.
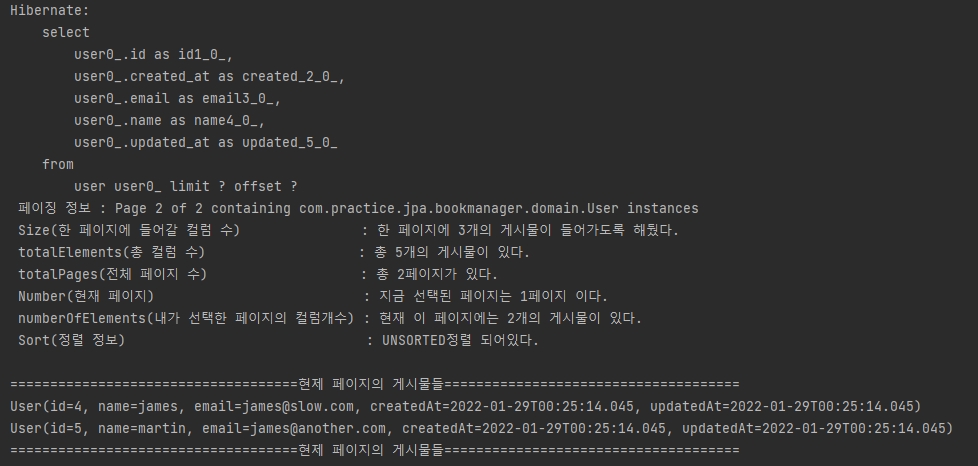
JPA 페이징 하기. 정말 간단하구나!!
QueryByExample (QBE)
✅ 쿼리바이이그젬플익스큐터 (QBE) : 엔티티를 이그젬플로 만들고 메쳐를 선언해 줌 으로서 필요한 쿼리를 만드는 방법
✅ 검색 조건문
/*exampleMatcher*/
ExampleMatcher matcher = ExampleMatcher.matching() //
.withIgnorePaths("name") // name은 매칭 하지 않겠다.
.withMatcher("email",endsWith()); // email에 대해서 확인하겠다. 끝에있다는걸
Example<User> example = Example.of(new User("ma","fast.com"),matcher); //
userRepository.findAll(example).forEach(System.out::println);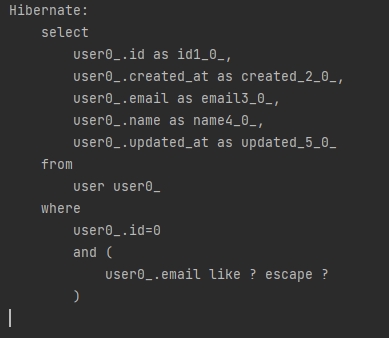
음... 이해가 잘 안되는데.... 다른 방법으로 예시를 보자...
User user = new User();
user.setEmail("slow");
ExampleMatcher matcher = ExampleMatcher.matching().withMatcher("email",contains());
Example<User> example = Example.of(user, matcher);설명을 들어보니 ... 검색을 할때는 QueryDSL 같은거 사용한다고 한다. 그게 뭔지 모르겠지만. 일단 Example은 문자만 가능하다는 한계가 있어서 안쓴다고 한다. 다행인건가?
UPDATE
/*UPDATE*/
userRepository.save(new User("david", "david@fast.com"));
// 만약 존재하는 엔티티이면 UPDATA를 한다.
// 존재하지 않는 엔티티이면 insert한다.
User user = userRepository.findById(1L).orElseThrow(RuntimeException::new);
user.setEmail("david-update@fast.com");
userRepository.save(user);