😎1:N 연관관계를 알아보자.
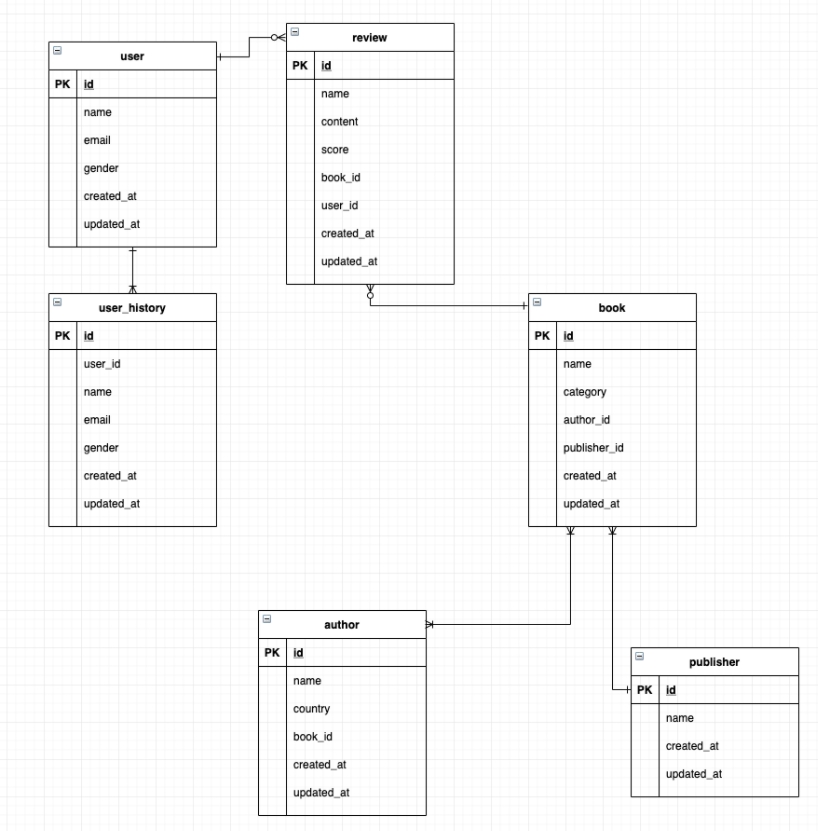
위의 user Table과 user_history는 1대 N 관계를 가진다.
✅ 이전에 만든 User와 User_history 엔티티들을 그대로 사용하면된다. Test 해보자.
@Test
void userRelationTest(){
User user = new User();
user.setName("david");
user.setEmail("david@fast.com");
user.setGender(Gender.MALE);
userRepository.save(user);
userHistoryRepository.findAll().forEach(System.out::println);
}결과
UserHistory(super=BaseEntity(createdAt=2022-02-08T14:23:00.755, updatedAt=2022-02-08T14:23:00.755), id=1, userId=null, name=david, email=david@fast.com)UserHistory의 userId 값이 null로 들어가게 되는데.. 이유는 PrePersist를 사용하여 디비에 들어가기 전에 쿼리를 때려서 그런거 같다. 그럼 PostPersist로 변경해주자.
public class UserEntityListener {
@PostPersist
@PostUpdate
public void prePersistAndPreUpdate(Object o) {
...
...
...✅ 같은 유저에 대해서 userhistory를 추가적으로 entity 릴레이션을 확인해보자.
void userRelationTest(){
User user = new User();
user.setName("david");
user.setEmail("david@fast.com");
user.setGender(Gender.MALE);
userRepository.save(user);
user.setName("danielll");
userRepository.save(user);
user.setEmail("daniel@fast.com");
userRepository.save(user);
userHistoryRepository.findAll().forEach(System.out::println);
}출력하면.
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:05:10.094, updatedAt=2022-02-08T15:05:10.094), id=1, userId=6, name=david, email=david@fast.com)
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:05:10.141, updatedAt=2022-02-08T15:05:10.141), id=2, userId=6, name=danielll, email=david@fast.com)
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:05:10.141, updatedAt=2022-02-08T15:05:10.141), id=3, userId=6, name=danielll, email=daniel@fast.com)✅ 여러 히스토리중 id값을 특정해서 볼수 있도록 findByUserId 메서드를 만들고 Test해보자.
public interface UserHistoryRepository extends JpaRepository<UserHistory, Long> {
List<UserHistory> findByUserId(Long userId);
} @Test
void userRelationTest(){
User user = new User();
user.setName("david");
user.setEmail("david@fast.com");
user.setGender(Gender.MALE);
userRepository.save(user);
user.setName("danielll");
userRepository.save(user);
user.setEmail("daniel@fast.com");
userRepository.save(user);
// userHistoryRepository.findAll().forEach(System.out::println);
// Table 관계로 가져오기.
List<UserHistory> result = userHistoryRepository.findByUserId(userRepository.findByEmail("daniel@fast.com").getId());
result.forEach(System.out::println);
}✅ 위 처럼 Table 관계로 값을 가져왔지만 Jpa 기능은 사용하지 않았다. JPA에서 제공하는 @OntToMany어노테이션을 이용해보자.
@OneToMany
private List<UserHistory> userHistories
= new ArrayList<>(); //getUserHistoryes를 했을때 NullPointException이 뜨지 않게 기본리스트 넣어주자.
// Jpa에서 해당값이 존재하지 않으면 빈 리스트를 자동으로 넣어주기는 하지만, persist하기 전에 해당 값이 Null이기 때문에 로직에 따라 오류가 생길수있다.그럼 유저 Id값을 가져와서 userHistory를 다시 조회하는 부분을 수정할수 있다.
@Test
void userRelationTest(){
User user = new User();
user.setName("david");
user.setEmail("david@fast.com");
user.setGender(Gender.MALE);
userRepository.save(user);
user.setName("danielll");
userRepository.save(user);
user.setEmail("daniel@fast.com");
userRepository.save(user);
// userHistoryRepository.findAll().forEach(System.out::println);
// Table 관계로 가져오기.
// List<UserHistory> result = userHistoryRepository.findByUserId(userRepository.findByEmail("daniel@fast.com").getId());
List<UserHistory> result = userRepository.findByEmail("daniel@fast.com").getUserHistories();
result.forEach(System.out::println);
}이렇게 하고 Test를 하면 LazyInitializationException 오류가 난다. 하지만 다음 챕터에서 배울 내용이기 때문에 일단, FetchType을 EAGER로 변경해주자.
@OneToMany(fetch = FetchType.EAGER)
private List<UserHistory> userHistories
= new ArrayList<>();@JoinColumn??
위와 같이 Test하고 console(DDL)을 확인해보면
create table user_user_histories (
user_id bigint not null,
user_histories_id bigint not null
)😈 user_user_histories라는 중간 맵핑 테이블이 생성되어있다. 이때 사용하는것이 @JoinColume이다.
@JoinColume은 Entity가 어떤 컬럼으로 join하게 될지 지정하는 어노테이션이다.
😈 이렇게 하면 user_user_histories 테이블은 사라지지만 user_history테이블의 user_id에 Join이 되어야하는데 user_histories_id 컬럼이 새로생길 것이다.
그러니 @JoinColumn(name="user_id")라고 지정해서 user_id로 조인할꺼라고 명시적으로 표현해둬야한다.
😈 
이렇게 오류가 뜨는데 컬럼 네임이 user_id를 쓸지 userId로 쓸지 모호하다는 뜻 이다.
그러니 UserHistory에도 명시적으로 해준다.
public class UserHistory extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "user_id")
private Long userId;TEST 하면
Hibernate:
create table user (
id bigint generated by default as identity,
created_at timestamp,
updated_at timestamp,
email varchar(255),
gender varchar(255),
name varchar(255),
primary key (id)
)
Hibernate:
create table user_history (
id bigint generated by default as identity,
created_at timestamp,
updated_at timestamp,
email varchar(255),
name varchar(255),
user_id bigint,
primary key (id)
)
위와같이 DDL이 재대로 생성된걸 볼 수 있다.
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:35:57.741, updatedAt=2022-02-08T15:35:57.741), id=1, userId=6, name=david, email=david@fast.com)
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:35:57.819, updatedAt=2022-02-08T15:35:57.819), id=2, userId=6, name=danielll, email=david@fast.com)
UserHistory(super=BaseEntity(createdAt=2022-02-08T15:35:57.819, updatedAt=2022-02-08T15:35:57.819), id=3, userId=6, name=danielll, email=daniel@fast.com)결과도 잘 나온다.
insertable, updatable
History라는 값은 User 엔티티에서 수정하거나 추가하면 안된다. 즉, ReadOnly 조회전용 값이 되어야 한다.
@JoinColumn(name = "user_id", insertable = false, updatable = false)🤔 이후에 cascade,트랜젝션에서 배우겠지만..
🤔 JPA는 자동으로 많은 쿼리를 나 대신 처리해준다. 하지만 나도 모르는 사이에 쿼리를 만들어 실행하기 때문에, 불필요한 쿼리를 만들어 오작동이나, 잠재적인 성능 이슈를 만들수 있다.
Table Entity를 열심히 설계해서 개발자가 원하는 최적의 쿼리를 설정하는 것이 JPA고수의 길이다. 🤔