[KAFKA] Cloud Server에 Kafka 설치하기 (with. Oracle Server)
Cloud Server에 Kafka를 설치하는 방법에 대해 기술 할려고 한다.
들어가기 전 Kafka에 대한 간략한 설명을 하고 가자.
Apache Kafka는 분산 스트리밍 플랫폼으로, 대량의 데이터를 실시간으로 처리하고, 저장하며, 전송할 수 있는 기능을 제공한다.
| 장점 | 단점 |
|---|---|
| 고가용성: 브로커와 파티션의 복제를 통해 장애 발생 시에도 데이터 손실 없이 시스템을 운영할 수 있다. | 복잡성: 설정과 운영이 복잡할 수 있으며, 특히 대규모 클러스터를 운영할 때 관리 부담이 커질 수 있다. |
| 확장성: 클러스터에 노드를 추가하거나 제거하여 쉽게 확장할 수 있으며, 데이터의 분산 처리를 통해 대규모 데이터 처리에 적합하다. | 메시지 순서: Kafka는 파티션 내에서 메시지 순서를 보장하지만, 여러 파티션에 걸친 메시지 순서는 보장하지 않는다. 따라서 메시지 순서가 중요한 경우, 설계 시 주의가 필요하다. |
| 실시간 처리: 실시간 데이터 스트리밍과 처리 기능을 제공하여 빠른 응답 시간과 실시간 데이터 분석을 지원한다. | 메시지 크기 제한: 기본적으로 메시지 크기에 제한이 있으며, 대용량 메시지를 처리할 때 성능에 영향을 줄수 있다. |
| 내구성: 디스크에 로그를 저장하고, 복제를 통해 데이터의 내구성을 보장한다. | 리소스 소모: 높은 성능과 내구성을 제공하기 위해 상당한 메모리와 디스크 공간을 소모할 수 있다. |
이러한 특징과 장단점을 고려하여 Kafka를 도입하여야 효율을 낼 수 있다.
같이 프로젝트를 진행하는 팀원이 이기종 서비스를 구현하였다면 정말 좋겠지만, 우린 서로 Java · Spring 으로 개발하기로 하였으므로 아쉽게된 상황이였다.
무엇보다 Kafka를 경험 해보고 공부 하는 것에 대해 의미를 두기로 하였다.
Cloud Server (Oracle)
먼저 Kafka를 설치하기 전 가용성을 위하여 Cloud Server가 필요했다.
필자는 Oracle Cloud를 선택하였다. (평생 무료라서)
Oracle Cloud는 예전에 생성 해둔 서버가 있어, 가볍게 설명하고 넘어가겠다.
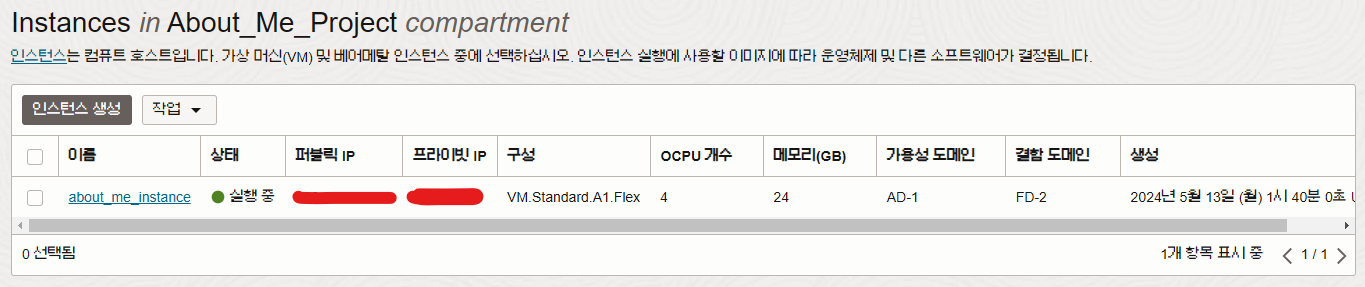
인스턴스는 무료로 최대 4개 까지 생성이 가능하다. 하지만 CPU 4개와 메모리 24GB를 배분하여 인스턴스를 생성 해야 하므로, 나는 하나의 서버에 모든 자원을 쏟아부었다.
다음으론, VCN 설정이 필요하다.
이것을 설정 해야 외부에서 접근할 수 있다.
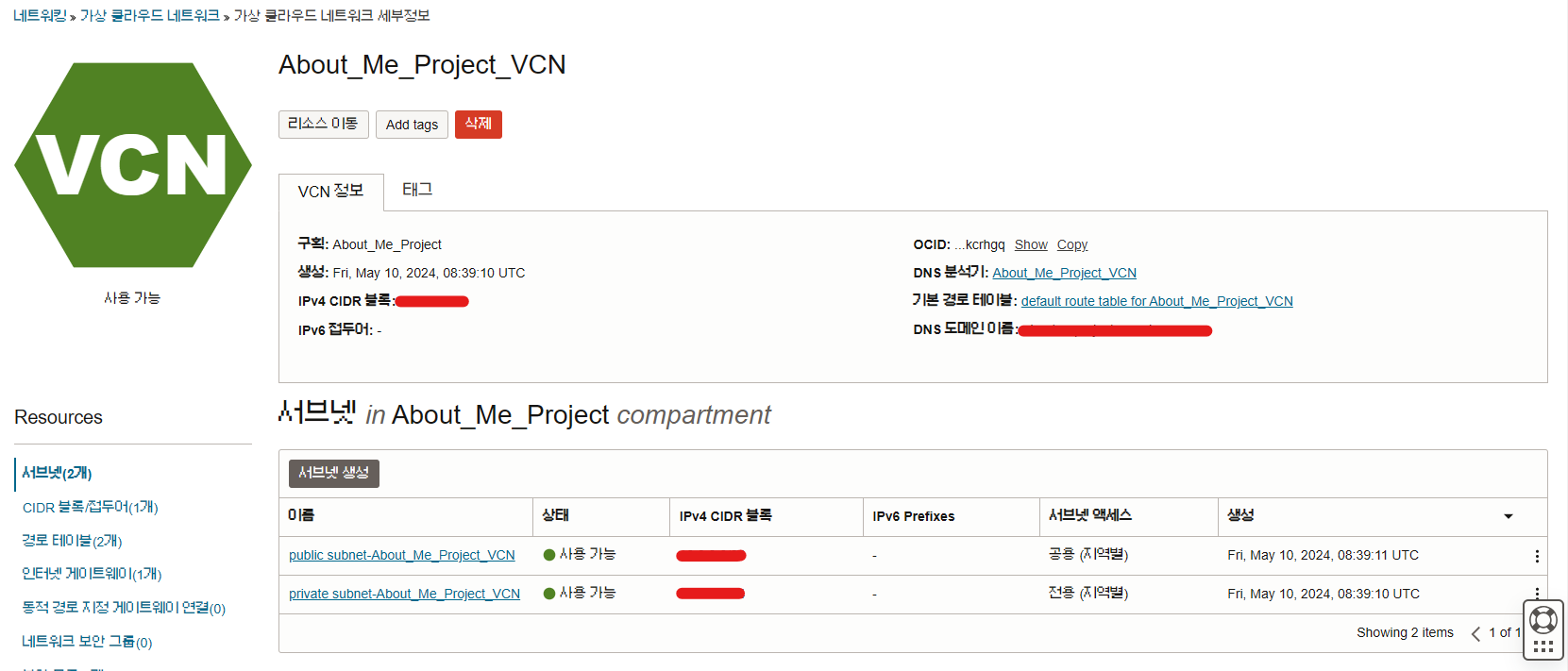

- SSH 접속용 규칙 추가

- Kafka용 규칙 추가
Putty를 사용하다가, MobaXterm으로 갈아탔다. MobaXterm을 사용하면 FileZilla가 필요 없어서 아주 편하다. 강추
다운로드 및 설치
Kafka는 공식 사이트에서 다운로드가 가능하다.
https://kafka.apache.org/downloads
자고로 Kafka는 Java로 개발되었기 때문어 먼저 Java를 설치 해야 한다. 일반적으로 Kafka는 Java 8 이상을 지원한다. 참고하자.
-
다운로드
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz필자는 3.7.0 버전을 설치 하였다. (당시 최신 버전)
-
압축 해제
tar -xzf kafka_2.13-3.7.0.tgz다운로드한 Kafka 파일의 압축을 풀어준다.
-
디렉토리 이동
cd kafka_2.13-3.7.0Kafka 디렉터리로 이동한다.
실행하기
1. ZooKeeper 실행
Kafka를 실행하기 전에 ZooKeeper를 먼저 시작해야 한다.
아니, 난 Kafka를 사용할려는데 왜 ZooKeeper를 실행 해요?
Kafka가 Zookeeper를 사용하는 이유는 Kafka의 아키텍처와 관련이 있다. 기본적으로, Kafka는 분산 메시징 시스템으로 여러 서버에 걸쳐 데이터를 관리하고 처리한다. Zookeeper는 Kafka의 이러한 분산 환경에서 중요한 역할을 한다.
-
메타데이터 관리
- ZooKeeper는 Kafka의 클러스터 상태, 브로커 정보, 토픽, 파티션, 리더 정보 등을 저장하고 관리한다.
-
리더 선출
- Kafka의 파티션은 여러 복제본을 가질 수 있으며, 이들 중 하나가 리더(leader) 역할을 맡는다.
- ZooKeeper는 리더 선출과 관련된 조정을 담당한다.
-
클러스터 상태 관리
- Kafka 브로커가 시작되거나 종료될 때, ZooKeeper는 이름 감지하고 클러스터의 상태를 업데이트 한다.
그렇다면 ZooKeeper 없이 실행할 수 없나요?
아니다. 최근에는 Kafka가 ZooKeeper 의존성을 줄이기 위해 노력하고 있으며, 특히 Kafka 2.8.0부터는 KRaft라는 새로운 모드가 도입되었다. KRaft 모드에서는 ZooKeeper를 사용하지 않고도 Kafka 자체가 클러스터의 메타데이터를 관리할 수 있다. 하지만 필자는 익숙한 ZooKeeper를 사용하였다. (다음에 KRaft Version을 따로 작성하겠다.)
본론으로 다시 돌아와, ZooKeeper를 실행하기 전 properties를 설정 해야 한다.
vi config/zookeeper.properties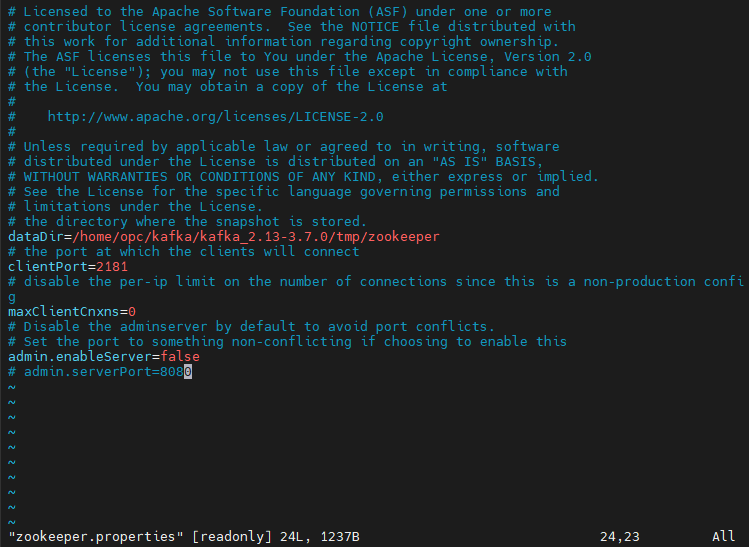
dataDir: 스냅샷 파일과 트랜잭션 로그 저장 디렉터리 경로clientPort: ZooKeeper 클라이언트가 연결할 포트 번호maxClientCnxns: 하나의 클라이언트 IP 주소에서 동시에 연결할 수 있는 최대 연결 수admin.enableServer: ZooKeeper의 관리자 서버를 활성화할지 여부
설정을 완료 하였다면, ZooKeeper를 실행시키자
sh $KAFKA_HOME/bin/zookeeper-server-start.sh config/zookeeper.properties2. Kafka 실행
Kafka 서버 또한 설정이 필요하다.
vi config/server.properties설정 내용이 너무 길어, 이번엔 스크린샷은 제외 하였다.
broker.id=0
listeners=PLAINTEXT://xxx.xxx.xxx.xxx:9092
advertised.listeners=PLAINTEXT://xxx.xxx.xxx.xxx:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/opc/kafka/kafka_2.13-3.7.0/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0broker.id: 클러스터 내에서 각 브로커를 식별하는 고유 IDlisteners: 브로커가 클라이언트 연결을 수신할 호스트와 포트advertised.listeners: Producer와 Consumer가 접근할 호스트와 포트num.network.threads: 네트워크 요청을 처리하는 스레드의 수num.io.threads: I/O 작업(디스크 및 네트워크)을 처리하는 스레드의 수socket.send.buffer.bytes: 소켓 송신 버퍼의 크기를 바이트 단위로 설정socket.receive.buffer.bytes: 소켓 수신 버퍼의 크기를 바이트 단위로 설정socket.request.max.bytes: 클라이언트 요청에서 수신할 수 있는 최대 바이트 수를 지정log.dirs: 로그 데이터를 저장할 디렉터리 경로num.partitions: 기본적으로 생성되는 토픽의 파티션 수num.recovery.threads.per.data.dir: 데이터 디렉터리당 복구 작업을 처리하는 스레드 수offsets.topic.replication.factor: 오프셋 주제의 복제 계수 설정transaction.state.log.replication.factor: 트랜잭션 로그의 복제 계수transaction.state.log.min.isr: 트랜잭션 로그 파티션의 최소 ISR 수 설정log.retention.hours: 로그 데이터를 유지할 최대 시간을 시간 단위로 설정log.retention.check.interval.ms: 로그 삭제 작업이 실행되는 간격을 밀리초 단위로 설정zookeeper.connect: Kafka 브로커가 연결할 ZooKeeper 서버의 호스트와 포트를 지정zookeeper.connection.timeout.ms: Kafka가 ZooKeeper와의 연결을 시도할 때 최대 대기 시간을 밀리초 단위로 설정group.initial.rebalance.delay.ms: 새로운 Consumer Group이 시작될 때 초기 Rebalancing을 지연시키는 시간
설정을 완료 하였다면, Kafka를 실행시키자
sh $KAFKA_HOME/bin/kafka-server-start.sh config/server.properties사용하기
이제 Kafka를 사용하여 토픽을 생성하거나 메시지를 전송할 수 있다.
- 테스트로 test 토픽을 생성
sh $KAFKA_HOME/bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1- 생성된 토픽을 확인
sh $KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server localhost:9092생성된 토픽을 확인 할 수 있다.
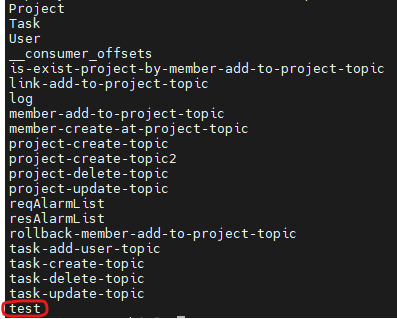
이제 메시지를 전송 해 보자
- 메시지 전송
sh $KAFKA_HOME/bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
안녕하십니까?를 전송 해 보았다.
이제 메시지를 읽어(소비)보자
- 메시지 소비
sh $KAFKA_HOME/bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092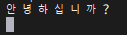
안녕하십니까? 메시지가 정상적으로 소비 된 것을 확인 할 수 있다.
다음 포스트에는, Kafka를 활용한 MSA 서비스 개발에 대하여 작성하도록 하겠다.
