이전 사이드 프로젝트에서 AWS RDS 서비스를 활용하여 데이터베이스 이중화를 구축하였다. 당시에는 AWS의 간편한 이중화 지원 덕분에 주로 스프링 애플리케이션 단에서의 구현에 집중했지만, 이번에는 MySQL 서버 단에서의 흐름을 살펴보려 한다.
Replication이란
Replication은 한 DB에서 다른 DB로 데이터가 동기화되는 것을 말하며, 원본 데이터를 가진 서버를 master DB, 복제된 데이터를 가지는 서버를 replica DB라고 부른다.
Replication의 이점은 다음과 같다.
- Scale-out : 동일한 데이터를 가진 DB를 활용하여 트래픽 분산
- Back-up : master DB 문제 발생 시 대체 DB 역할
아키텍처
MySQL 서버에서 발생하는 모든 변경 사항은 별도의 로그 파일에 순서대로 기록되는데, 이를 바이너리 로그라고 한다. Replication은 master 서버에서 생성된 바이너리 로그가 replica 서버로 전송되어 해당 내용을 로컬 디스크에 저장한 뒤 replica의 데이터 파일에 반영함으로써 master 서버와 replica 서버 간에 데이터 동기화가 이뤄진다.
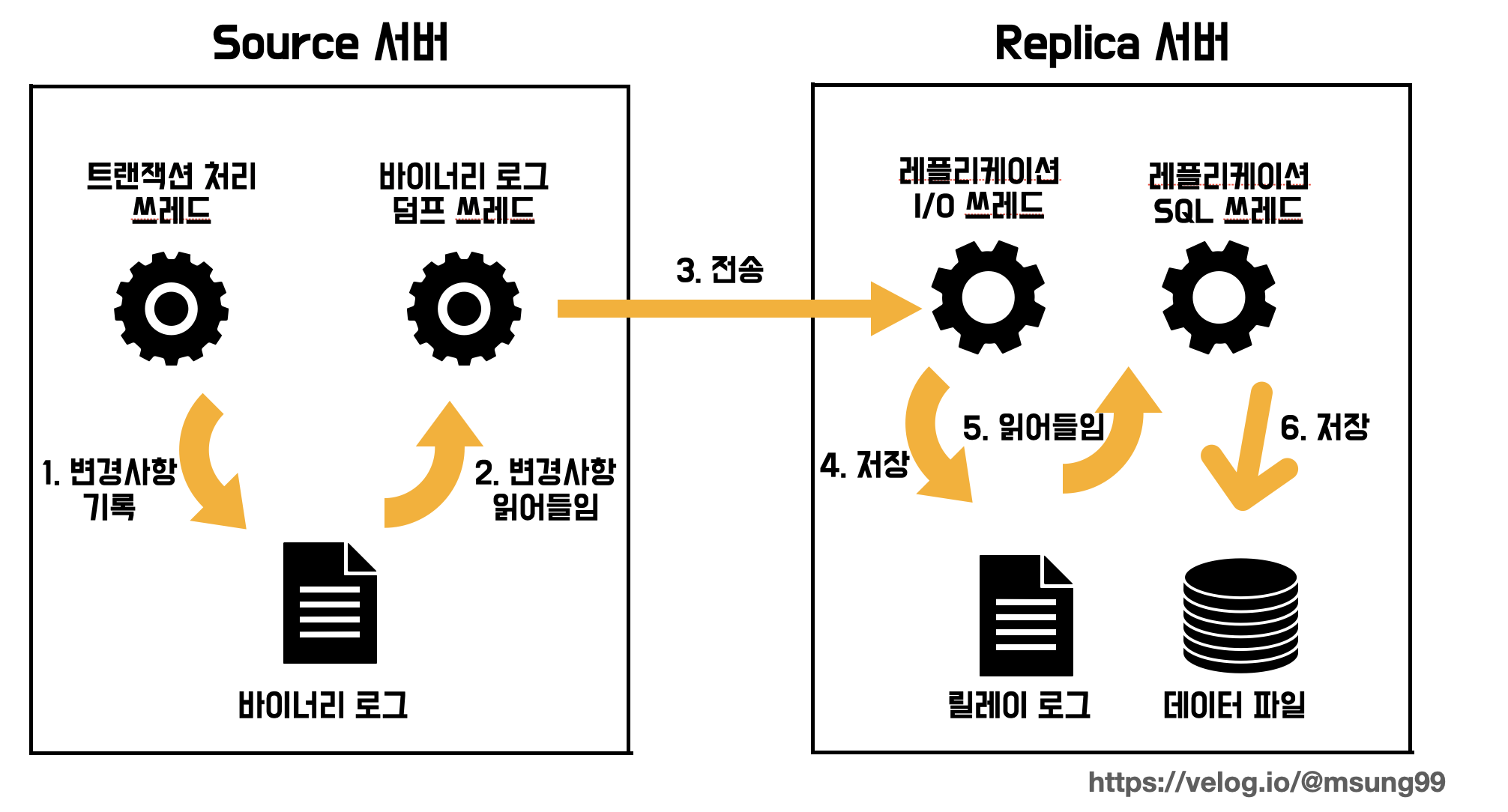
MySQL의 replication은 총 3개의 스레드에 의해 동작한다. 각 스레드의 역할은 다음과 같다.
-
바이너리 로그 덤프 스레드 : replica 서버가 master 서버에 접속해 바이너리 로그를 요청하면 master 서버에 바이너리 로그 덤프 스레드가 생성된다. 바이너리 로그 덤프 스레드는 바이너리 로그에 락을 걸어 replica 서버로 전송한다.
-
레플리케이션 I/O 스레드 : 복제가 시작되면 replica 서버는 I/O 스레드를 생성한다. I/O 스레드는 master 서버의 바이너리 로그 덤프 스레드로부터 바이너리 로그를 가져와 로컬 서버의 파일(릴레이 로그)로 저장한다.
-
레플리케이션 SQL 스레드 : 릴레이 로그 파일을 읽어 데이터 파일에 반영한다.
💡 데이터 포맷이 statement 또는 mixed일 경우 락이 필요하다. 데이터 포맷에 대한 것은 곧이어 설명한다.
참고 : 바이너리 로그에 락을 거는 이유
식별 타입
MySQL replication은 master 서버의 바이너리 로그에 기록된 변경 내역들을 식별하는 방식에 따라 1. 바이너리 로그 파일 위치 기반 복제, 2. 글로벌 트랜잭션 ID 기반 복제로 나뉜다.
1. 바이너리 로그 파일 위치 기반 복제
바이너리 로그 파일 위치 기반 복제는 replica 서버에서 master 서버의 바이너리 로그 파일명과 파일 내에서의 위치 값(offset)의 조합으로 식별한다.
[로그 파일명][offset]
Binary-log.000002:320하지만 이 방식은 토폴로지 변경에 취약하다는 문제가 있다. 예를 들어 master 서버에 문제가 생겨 A replica 서버가 승격되었다. 이 경우에 다른 B, C, D replica 서버는 복제를 위해 기존 식별 값인 파일명, offset을 사용할 수 없다. 왜냐하면 기존 식별 값인 파일명, offset은 장애가 발생한 master 서버 기준이기 때문이다. 따라서 이 방식은 종종 토폴로지 변경이 불가능하거나 많은 시간이 소요된다.
2. 글로벌 트랜잭션 ID 기반 복제
글로벌 트랜잭션 ID 기반 복제는 replica 서버에서 복제 토폴로지 내에서 고유한 글로벌 트랜잭션 ID(GTID)로 식별한다.
GTID = [source:id]:[transaction_id]GTID는 물리적인 파일의 이름이나 위치가 아닌 논리적인 의미로서 기존 master 서버에 장애가 발생해 replica 서버를 승격시켜도 앞서 이야기한 호환성 문제가 발생하지 않는다. 따라서 MySQL 8.0은 글로벌 트랜잭션 ID 기반 복제를 default로 사용한다.
데이터 포맷
MySQL replication은 각 이벤트가 바이너리 로그에 저장되는 포맷 형태로 1. Statement 기반, 2. Row 기반, 3 Mixed 기반 방식을 지원한다.
1. Statement 기반
Statement 기반 방식은 실행된 SQL문이 바이너리 로그에 그대로 저장된다.
-
장점
- 여러개의 데이터를 수정하는 쿼리여도 바이너리 로그에 SQL문 하나만 기록되기 때문에 저장 공간에 대한 부담이 적다.
-
단점
- UUID, Random 등 비확정성 함수가 실행될 경우 master 서버와 replica 서버 간의 정합성 문제가 발생할 수 있다.
- 락을 많이 사용한다.
- 트랜잭션 격리 레벨이 repeatable read 이상에서만 사용할 수 있다.
2. Row 기반
Row 기반에서는 변경 값 자체가 바이너리 로그에 그대로 저장된다.
-
장점
- UUID, Random 등 비확정성 함수를 사용했다 하더라도 함수의 결과값만 전달하기 때문에 일관성이 유지된다.
- 모든 트랜잭션 격리 레벨에서 사용할 수 있다.
-
단점
- 데이터를 많이 변경하는 쿼리가 있을 경우 바이너리 로그 파일 크기가 커질 수 있다.
- MySQL 8.0은 binary_row_image, binary_transaction_compression 시스템 변수를 통해 용량 최적화 기능을 제공한다.
- 어떤 쿼리가 넘어왔는지 육안으로 확인이 힘들다.
- 데이터를 많이 변경하는 쿼리가 있을 경우 바이너리 로그 파일 크기가 커질 수 있다.
3. Mixed 기반
Mixed 기반에서는 statement, row 방식을 섞어 사용한다. 일반적인 쿼리는 statement 기반으로 처리하고 비확정 쿼리는 row 기반으로 처리한다.
- 장점
- 일반적인 쿼리는 statement 포맷, 비확정성 쿼리는 row 포맷으로 유연하게 처리할 수 있다.
- 단점
- MySQL 서버가 내부적으로 설정된 기준과 기술적인 측면을 고려해 자동으로 두 포맷을 번갈아 사용하므로 실제 사용자가 예상했던 것과 다르게 처리될 수 있다.
🤔 그렇다면 어떤 방식을 사용하면 좋을까?
MySQL 8.0에서는 row 기반 방식이 default로 설정되어 있다. 사용자는 자신이 사용하는 쿼리 형태에 따라 포맷을 변경하면 된다.
동기화 방식
MySQL에서는 master 서버와 replica 서버 간의 복제 동기화에 대해 1. 비동기 복제, 2. 반동기 복제 방식을 지원한다.
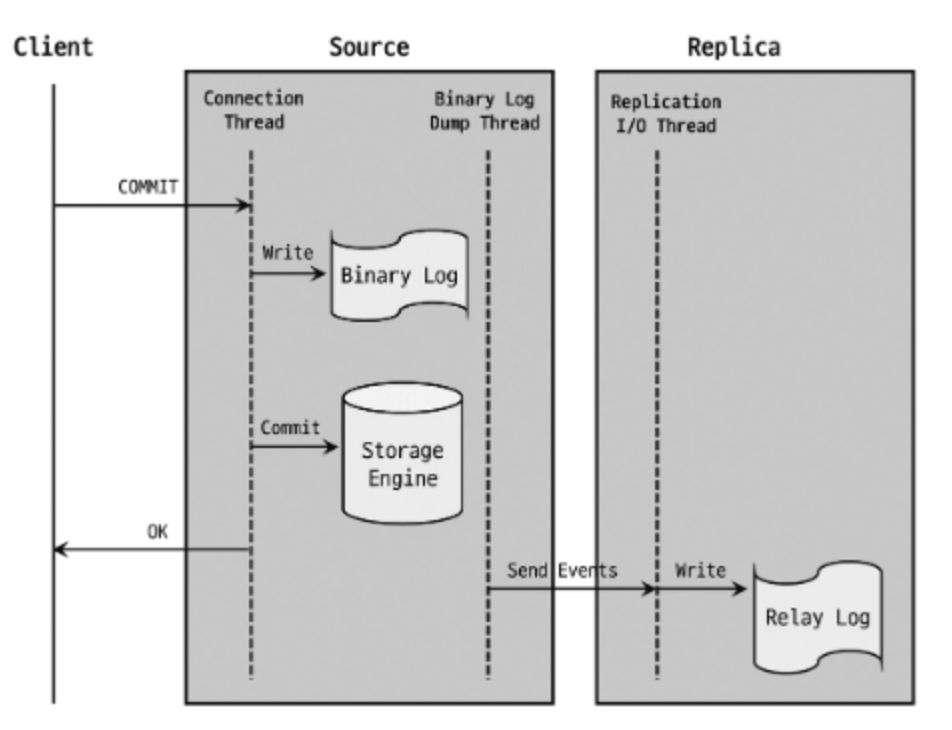
1. 비동기 복제
MySQL의 replication은 기본적으로 비동기 방식으로 동작한다. 비동기 방식이란 master 서버가 자신과 복제 연결된 replica 서버에서 변경 이벤트가 정상적으로 전달되어 적용됐는지를 확인하지 않는 것이다.
장점
- master 서버에서 replica 서버로 바이너리 로그를 전송하는 부분을 고려하지 않아도 되기 때문에 성능이 좋다.
- replica 서버에 문제가 발생해도 master 서버는 아무런 영향을 받지 않는다.
단점
-
master 서버에 장애가 발생하면 master 서버에서 최근까지 적용된 트랜잭션이 replica 서버에 누락될 수 있다.
2. 반동기 복제
반동기 복제란 replica 서버에서 master 서버로부터 바이너리 로그를 받았음을 전달하는 것이다. 따라서 반동기 복제에서는 master 서버에서 커밋되어 정상적으로 결과가 반환된 모든 트랜잭션들에 대해 적어도 하나의 replica 서버에는 해당 트랜잭션들이 전송됐음을 보장한다. 하지만 여기서 중요한 부분은 바로 replica 서버에 전송됐음을 보장한다는 것이지, 실제로 복제된 트랜잭션이 replica 서버에 적용되는 것까지 보장한다는 것은 아니다.
장점
- 하나 이상의 replica 서버에 변경 사항을 전송하는 것을 보장한다.
- 비동기 복제 방식보다 조금 더 향상된 데이터 무결성을 지원한다.
단점
- replica의 응답을 받기 때문에 성능이 떨어진다.
반동기 복제에서는 master 서버가 트랜잭션 처리 중 어느 지점에서 replica 서버의 응답(ACK)을 기다리냐에 따라 AFTER_COMMIT, AFTER_SYNC로 나뉜다.
- AFTER_COMMIT 방식
master 서버에서 트랜잭션을 바이너리 로그에 기록하고 스토리지 엔진에 커밋한다. 클라이언트에 결과를 반환하기 전에 replica 서버의 응답을 기다린다.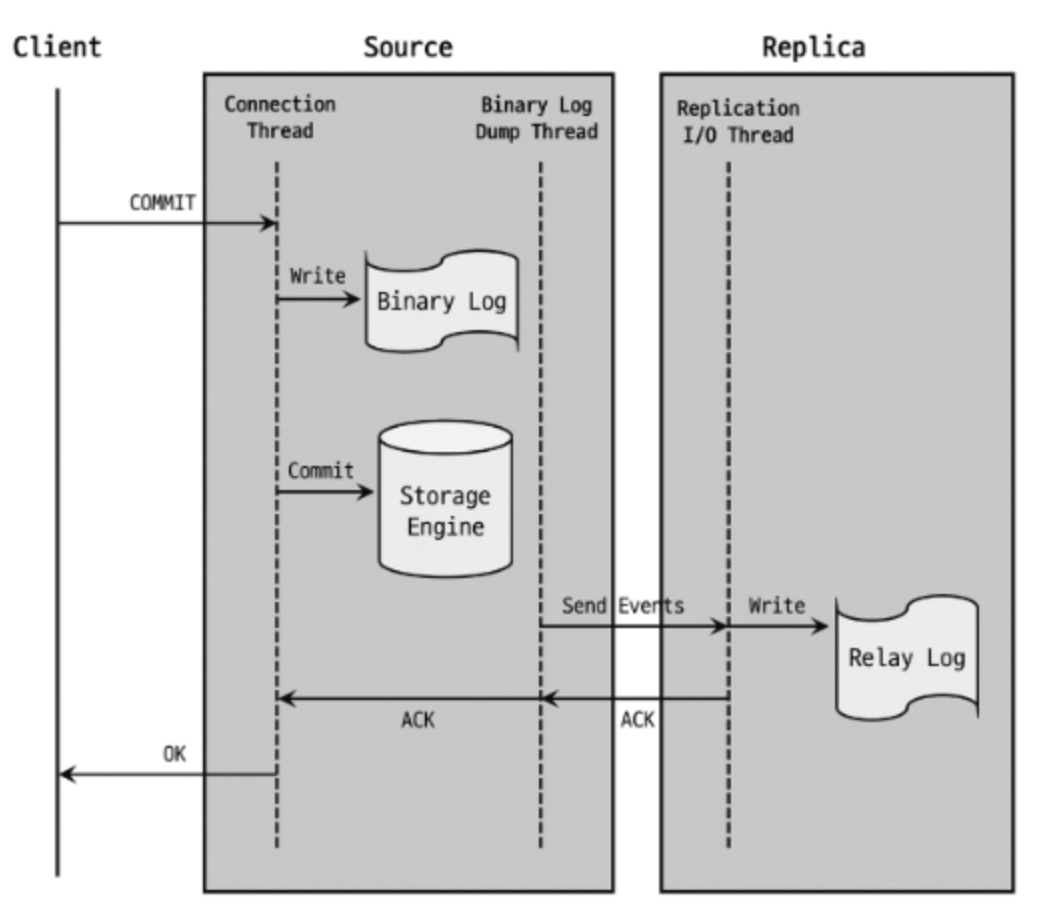
-
AFTER_SYNC 방식(default)
master 서버가 각 트랜잭션을 바이너리 로그에 기록한 후, replica 서버로 전송하고 해당 서버로부터 응답을 받을 때까지 대기한다. 응답을 받으면 스토리지 엔진에 트랜잭션이 커밋된다.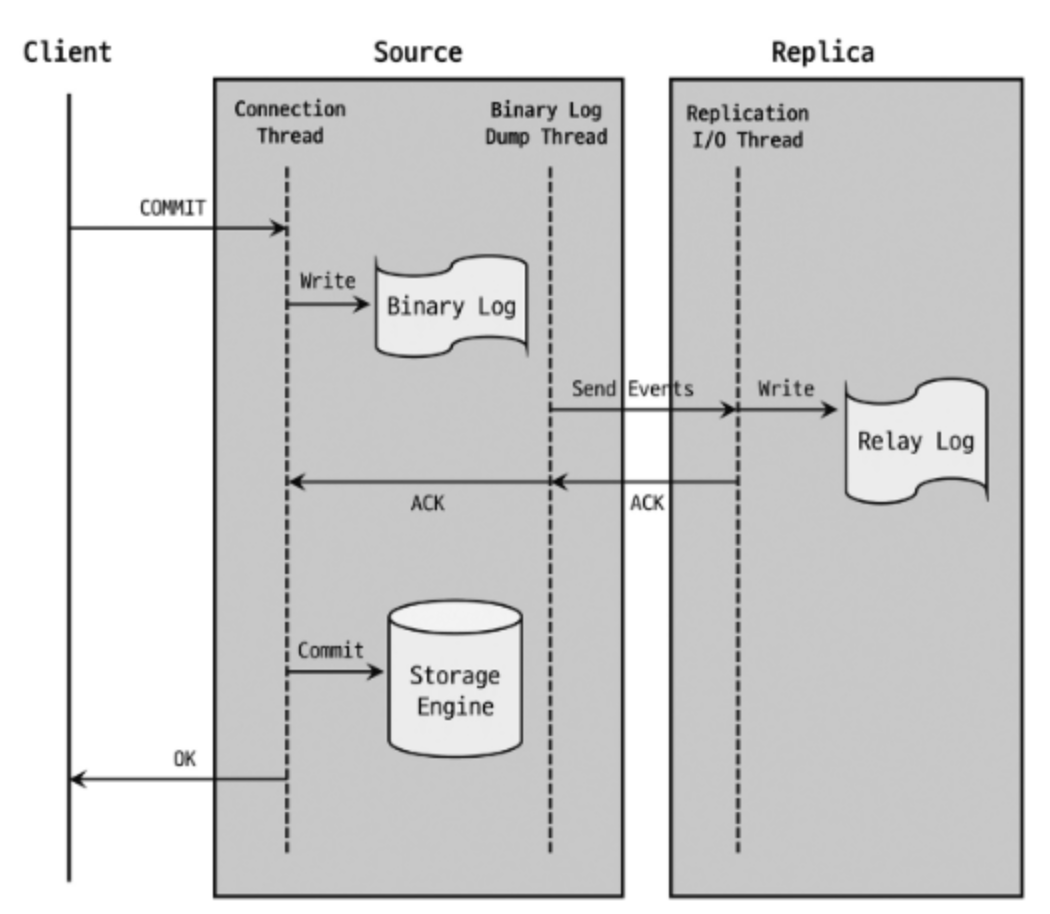
-
+ MHA (Master High Availability)
MHA는 master DB의 고가용성을 위해 개발된 오픈소스로서 replication 환경에서 master DB의 장애 발생시 master의 최신 로그가 가장 많이 적용된 replica를 master DB로 승격시켜 fail over를 수행한다.반동기 복제 방식의 AFTER_SYNC를 MHA와 함께 사용하면 마지막에 커밋된 릴레이 로그는 replica의 어딘가에 존재하기 때문에 master에 장애가 발생하더러도 릴레이 로그 복구 과정을 통해 동기화되기 때문에 데이터 유실이 발생하지 않는다.
-
🤔 어떤 동기화 복제 방식을 선택해야 할까?
서비스 특성을 고려해서 정합성 vs 성능간 트레이드 오프를 비교하여 결정하는 것이 중요하다. 참고로 반동기 복제도 완전한 동기 복제가 아니기 때문에 비동기 복제와 마찬가지로 master DB와 replica DB간 데이터 정합성 문제가 발생할 수 있다.
결론
MySQL Replication의 동작 원리에 대해 살펴보았다. 프로젝트에서는 AWS의 RDS 서비스를 활용하여 비교적 손쉽게 구축했지만, 그 이면에는 깊은 기술적 원리가 숨겨져 있었다. 앞으로 기회가 된다면 직접 MySQL 서버를 구축하여 보다 심도 깊은 이해를 쌓아가고자 한다.
참고
