1. ACID에 대해 설명해주세요.
ACID : 데이터베이스 내에서 일어나는 하나의 transaction의 안전성을 보장하는데 필요한 성질이다.
-
Atomicity(원자성)
- 시스템에서 한 transaction의 연산들이 모두 성공하거나, 반대로 모두 실패돼야 한다.
- 작업이 모두 반영되거나 모두 반영되지 않음으로써 결과를 예측할 수 있어야 한다.
-
Consistency(일관성)
- 데이터베이스의 상태가 일관되어야 한다.
- 하나의 transaction 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다.
- 다시 말해, transaction이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다.
-
Isolation(격리성)
- 모든 transaction은 다른 transaction으로부터 독립되어야 한다.
- concurrency control의 주된 목표가 isolation이다.
-
Durability(지속성)
- commit된 transaction은 DB에 영구적으로 저장한다.
- 즉, DB system에 문제가 생겨도 commit된 transaction은 DB에 남아 있다.
- '영구적으로 저장한다'라고 할 때는 일반적으로 '비휘발성 메모리(HDD, SSD)에 저장함'을 의미한다.
- 기본적으로 transaction의 durability는 DBMS가 보장한다.
ACID 원칙을 strict 하게 지키려면 동시성이 매우 떨어져서 DBMS는 ACID 원칙을 희생하여 동시성을 얻을 수 있는 방법으로 isolation level을 제공한다.
2. Autocommit에 대해 설명해주세요.
Autocommit이란?
- 각각의 SQL 문을 자동으로 transaction 처리해 주는 개념.
- SQL 문이 성공적으로 실행되면 자동으로 commit 한다.
- 실행 중에 문제가 있었다면 알아서 rollback 한다.
- MySQL에서는 default로 autocommit이 enabled 되어 있다.
- 다른 DBMS에서도 대부분 같은 기능을 제공한다.
Autocommit 확인하기
mysql에서는 default로 활성화 되어 있어서 1이 조회된다.
select @@ autocommit;Autocommit 설정하기
활성화 시=1, 비활성화 시 =0을 입력하자.
set autocommit=0;자바/스프링에서 확인하기
public void transfer(String fromId, String toId, int amount) {
try {
Connection connection = ...;
connection.setAutoCommit(false);
...
...
connection.commit();
} catch (Exception e) {
...
connection.rollback();
...
} finally {
connection.setAutoCommit(true);
}
}자바/스프링에서는
- DB 커넥션을 조회
- autoCommit = false로 초기화(트랜잭션 시작)
- 비즈니스 로직 수행
- 성공적이라면 커밋
- 실패면 롤백
- autocommt = true로 다시 초기화
트랜잭션 관련된 부가적인 코드들 때문에 서비스 로직의 가독성이 저하된다. 우리가 흔히 사용하는 @Transactional을 통해 transaction 관련된 코드들을 함축시킬수 있다.
@Transactional
public void transfer(String fromId, String toId, int amount) {
...
...
}3. 트랜잭션 격리수준에 대해 설명해주세요.
트랜잭션 격리수준이란 동시에 여러 트랜잭션이 처리될 때 트랜잭션끼리 얼마나 서로 고립되어 있는지 나타내는 것을 의미한다.
READ_UNCOMMITED : 가장 낮은 격리 수준이며 가장 빠르다. 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 있다.
- 이상현상 : phantom reads, Non-repeatable Reads, Dirty Reads
READ COMMITED : 커밋 완료된 데이터에 대해서만 조회할 수 있으며 커밋이 되지 않은 정보는 읽지 못한다. PostgreSQL, SQL Server, Oracle에서 기본값으로 설정되어 있다. 가장 많이 사용되는 격리 수준이다.
- 이상현상 : phantom reads, Non-repeatable Reads
REPEATABLE_READ : 커밋 완료된 데이터에 대해서만 조회할 수 있으며 반복해서 행을 조회하더라도 똑같은 행을 보장하는 단계이다. 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않는다. 따라서 똑같은 범위 쿼리를 실행했을 때 이후에 추가된 행이 발견될 수도 있다. 이는 MySQL8.0의 innoDB 기본값이다.
- 이상현상 : phantom reads
SERIALIZABLE : 커밋 완료된 데이터에 대해서만 조회할 수 있으며 트랜잭션을 순차적으로 진행시키는 것을 말한다. 여러 트랜잭션이 동시에 같은 행에 접근할 수 없다.
- 이상현상 : X
4. 트랜잭션의 격리수준에 따른 이상 현상
Dirty Reads : 한 트랜잭션이 다른 트랜잭션의 아직 커밋되지 않은 데이터를 읽는 현상을 의미한다.
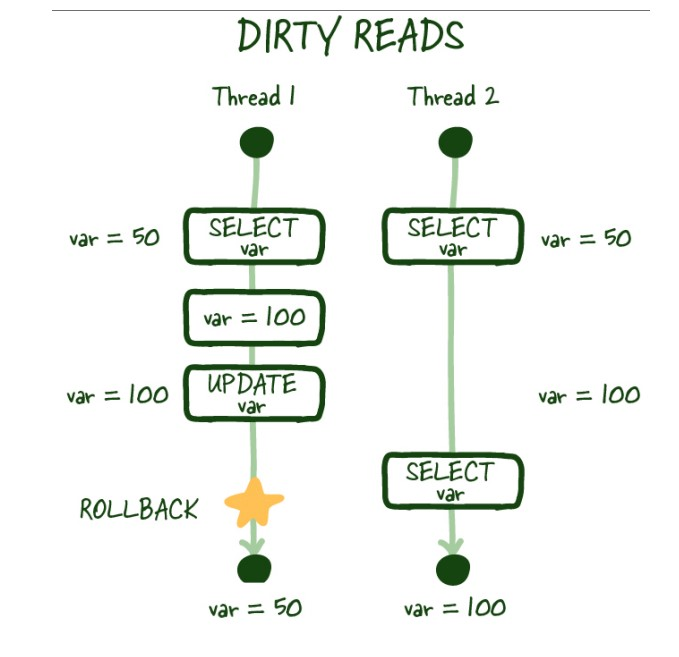
Nonrepeatable Reads : 한 트랜잭션이 같은 쿼리를 2번 실행하는데 그사이에 다른 트랜잭션이 수정/삭제하여 같은 쿼리에 다른 값이 나오는 경우를 의미한다.
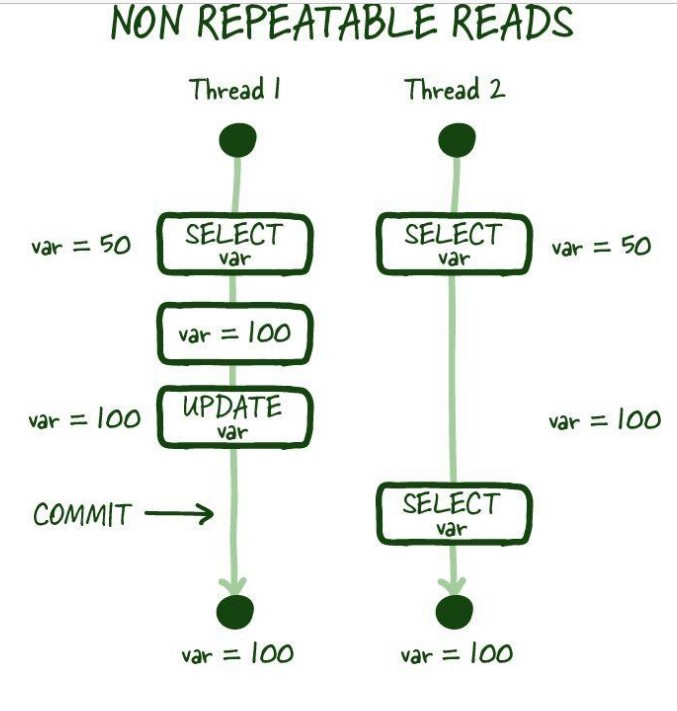
phantom reads : 한 트랜잭션이 같은 쿼리를 2번 실행하는데 그사이에 없던 레코드가 추가되어 같은 쿼리에 다른 값이 나오는 경우를 의미한다.
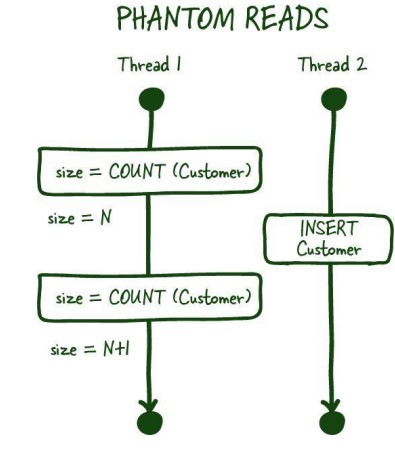
5. 공유락 vs 배타락
데이터베이스는 transaction의 ACID 원칙과 동시성을 최대한 보장하기 위해 다양한 종류의 lock을 사용한다.
데이터베이스의 Lock은 크게 두가지가 있다.
-
Shared Lock (공유락) : 읽기 O , 쓰기 X, 다른 트랜잭션에서의 Shared Lock은 허용되지만 Exclusive Lock은 허용하지 않음
-
Exclusive Lock (배타락) : 읽기 X, 쓰기 X, 다른 트랙잭션에서의 Shared Lock, Exclusvie Lock 은 허용하지 않는다.
6. Mysql 사용시 쿼리에 따른 locking 유뮤
select : X
update, delete, insert : 배타락
7. Key의 종류
- 기본키(Primary Key) : 유일성과 최소성을 만족하는 키.
- 자연키 : 중복되는 것을 제외하고 자연스럽게 뽑아 결정하는 기본키, 언젠가 변함.
- ex) 주민등록번호
- 인조키 : MySQL의 auto increment 등 인조적으로 유일성을 확보하는 키. 기본키는 보통 인조키로 설정.
- 자연키 : 중복되는 것을 제외하고 자연스럽게 뽑아 결정하는 기본키, 언젠가 변함.
- 외래키 : 다른 테이블의 기본키를 그대로 참조하는 값.
- 후보키 : 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족하는 키.
- 대체키 : 후보키가 두 개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키들.
- 슈퍼키 : 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키.
유일성
- 유일성이란, 하나의 키값으로 튜플을 유일하게 식별할 수 있는 성질을 의미한다.
- 예를 들어 User 릴레이션에 (주민등록번호, 나이, 사는 곳, 혈액형)이라는 속성이 존재할때 주민등록번호는 중복이 발생할 수 없으므로 유일성을 만족한다.
최소성
- 최소성이란, 키를 구성하는 속성들 중 가장 최소로 필요한 속성들로만 키를 구성하는 성질을 의미한다.
- 쉽게 말해, 키를 구성하고 있는 속성들이 진짜 각 튜플을 구분하는 데 꼭 필요한 속성들로만 구성되어 있는지를 의미한다.
- 예를 들어 User 릴레이션에 (주민등록번호, 나이, 사는 곳, 혈액형) 이라는 속성이 존재할 때 (주민등록번호, 나이)가 키로 지정이 되어 있다면, 당연히 이 키는 각 튜플들을 구분할 수 있다.
하지만 더 간단하게 주민등록번호 하나만으로도 튜플들을 구별 가능하다. 따라서 이 경우에 (주민등록번호, 나이)는 최소성을 만족하지 않고 주민등록번호는 최소성을 만족한다고 말한다.

8. Array vs LinkedList
Array
- 탐색 : 인덱스를 통한 임의 접근 방식(random access), O(1)
- 삽입, 삭제 : O(n)
- 메모리 할당 영역 : stack
- 메모리 할당 시점 : 컴파일 시점에 정적 메모리 할당
LinkedList
- 탐색 : 순차 접근 방식(sequential access), O(n)
- 삽입, 삭제 : O(1)
- 메모리 영역 : heap
- 메모리 할당 시점 : 런타임 시점에 동적 메모리 할당
10. 데이터베이스 리플리케이션이란?
데이터베이스 리플리케이션(Replication) : 이름 그대로 복제본 데이터베이스를 운용하는 것이다. 원본 데이터베이스를 Master, 복제된 데이터베이스를 Slave라고 부른다. Slave 데이터베이스는 Master 데이터베이스를 복제(Replication)하여 동일한 데이터를 가지게 된다.
-
부하 분산
서비스에 사용자가 많아져 트래픽이 늘어날 경우, DB에 쿼리를 날리는 일이 빈번하게 일어난다. DB에서는 쿼리를 모두 처리하기 부담이 되고 이에 따라 부하를 줄이기 위해 DB를 이중화하여 Master에서는 insert, update, delete 연산을 처리하고 Slave에서는 read 연산만을 처리하여 병목 현상을 줄일 수 있다. -
데이터 백업
Master의 데이터가 날아가더라도 Slave에 데이터가 저장되어 Slave를 Master로 승격시켜서 데이터를 복구할 수 있다. 다만 비동기 방식이기 때문에 100% 정합성을 보장할 수 없다.
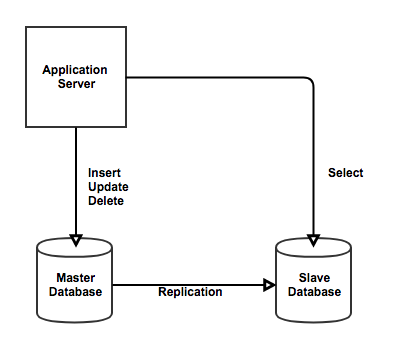
리플리케이션은 기본적으로 비동기 복제 방식을 이용한다. 따라서 Master로부터 Slave로 복제되는 시간 사이에 데이터 정합성 문제가 발생할 수 있다. 하지만 실시간성이 높은 데이터의 경우 Master DB에 요청 보내도록 하면 문제를 해결할 수 있다.
