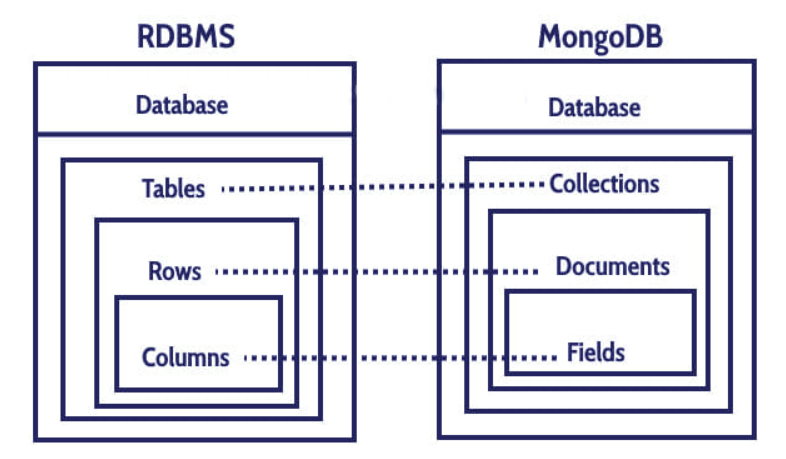
ObjectId는 클라이언트에서 생성한다는 점이다. 이는 MongoDB 클러스터에서 Sharding된 데이터를 빠르게 가져오기 위함인데 Router(mongos)는 ObjectId를 보고 데이터가 존재하는 Shard에서 데이터를 요청할 수 있다. 의아하게도 MongoDB 서버에서 알아서 ObjectId를 부여해서 저장해도 될 것 같은데 딱히 지원해주지 않는다. 참고로 ObjectId를 넣지않고 저장한다면 데이터가 그대로 저장된다.
다음으로 MongoDB 데이터 조작에 대해서 알아보자. MongoDB와 같은 NoSQL은 이름처럼 SQL을 사용하지 않고 별도로 제공하는 API를 통해 데이터를 건들 수 있다. MongoDB의 경우 자바스크립트 엔진 SpiderMonkey를 사용하여 API를 제공한다. 따라서 자바스크립트를 조금은 알아야한다.
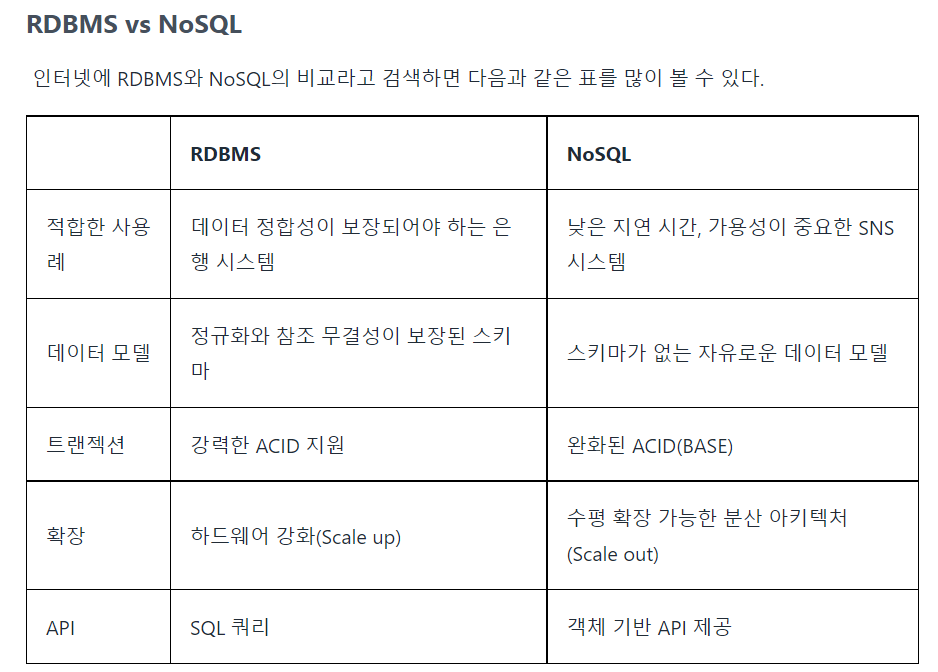
그래서 MongoDB가 뭔데?
MongoDB는 앞서 설명한 것 처럼 NoSQL 데이터베이스고 다음 세 가지 특징을 가지고있다.
Document
BASE
Open Source
데이터는 Document 기반으로 구성되어있고, ACID 대신 BASE를 택하여 성능과 가용성을 우선시한다. 그리고 오픈 소스라는 점 덕분에 무료로 이용이 가능하다.
스키마가 없다
스키마란 데이터베이스를 구성하는 개체, 속성,관계 및 데이터 조작 시에 데이터값들이 갖는 제약조건등에 관해 전반적으로 정의하는 것 스키마가 존재한다는 것은 그 구조가 미리 정의되어 있어야 한다라는 의미
MongoDB는 사전에 스키마가 정의 되지 않아도 된다. 즉 다양한 필드를 가질 수 있다.
장점
RDBMS속도보다 굉장히 빠르다.
스키마 관리가 핑요 없다.( 어떤 형태의 데이터도 저장 가능)
json 형태로 저장하기때문에 직관적이다.
데이터를 읽고 / 쓰기가 빠르다.read/write
scale-out 구조여서 쉽게 운영가능하다.
auto -sharding 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있도록 하는 기술이 있다.
단점
복잡한 쿼리를 사용할 수 없다. ( join이 없다.)
메모리 사용량이 큰 편
sql을 완전히 이전할 수 없다.
정합성이 떨어지므로 트랜잭션이 필요한 경우에는 부적합하다.(ex, 금융 ,결제,회원정보)
트랜젝션
트랜잭션은 작업의 완전성 을 보장해주는 것이다. 즉, 논리적인 작업 셋을 모두 완벽하게 처리하거나 또는 처리하지 못할 경우에는 원 상태로 복구해서 작업의 일부만 적용되는 현상이 발생하지 않게 만들어주는 기능이다. 사용자의 입장에서는 작업의 논리적 단위로 이해를 할 수 있고 시스템의 입장에서는 데이터들을 접근 또는 변경하는 프로그램의 단위가 된다.
트랜잭션의 특성
트랜잭션은 어떠한 특성을 만족해야할까? Transaction 은 다음의 ACID 라는 4 가지 특성을 만족해야 한다.
원자성(Atomicity)
만약 트랜잭션 중간에 어떠한 문제가 발생한다면 트랜잭션에 해당하는 어떠한 작업 내용도 수행되어서는 안되며 아무런 문제가 발생되지 않았을 경우에만 모든 작업이 수행되어야 한다.
일관성(Consistency)
트랜잭션이 완료된 다음의 상태에서도 트랜잭션이 일어나기 전의 상황과 동일하게 데이터의 일관성을 보장해야 한다.
고립성(Isolation)
각각의 트랜잭션은 서로 간섭없이 독립적으로 수행되어야 한다.
지속성(Durability)
트랜잭션이 정상적으로 종료된 다음에는 영구적으로 데이터베이스에 작업의 결과가 저장되어야 한다.
ACID
BASE
무결성
데이터 무결성의 의미를 재확인해보자. 데이터 무결성이란 데이터의 정확성과 일관성이 보장된 상태를 의미한다. 여기서 정확성이란 중복이나 누락이 없는 상태라고 말할 수 있다. 또 일관성이란 원인과 결과의 의미가 연속적으로 보장돼 변하지 않는 상태라고 설명된다. 데이터베이스에서 데이터 무결성이 갖는 중요성은 데이터 가치와 데이터 신뢰성 측면으로 설명할 수 있다.
CAP 이론
CAP 이론은 2000년에 에릭 브류어가 최초로 소개한 이론이며 어떤 분산 시스템이더라도 Consistency (일관성), Availability (가용성), Partition tolerance (분할 내성)를 모두 만족할 수 없다는 이론이다. 이 세 가지의 머리 글자를 따서 CAP 이론이라고 부른다.
정리하면 MongoDB는 PA / EC 시스템이므로 네트워크 파티션 상황일 때 가용성을 더 우선시하고 평상시엔 일관성을 우선시한다.
마치며
MongoDB와 RDBMS는 적합한 사용처가 다르다. 내 개인적인 생각으론 MongoDB를 비롯한 NoSQL은 최대한 단순하게 사용하는 것이 옳은 방향이라고 생각한다. NoSQL은 최대한 단순하면서 많은 데이터, RDBMS는 복잡하면서 무결성이 중요한 데이터에 적합하다고 생각한다. 물론 데이터를 단순화하는 것도 쉬운 일은 아니기 때문에 만약 당신이 MongoDB를 사용할 계획이 있다면 꼭 위 모델링 패턴을 참고하여 데이터 구조를 잡는 것을 추천한다.
적절한 사례
1. 로그성 데이터나 빅데이터 처리의 중간 저장소
RDB보다는 성능이 우월하고, 파일보다는 다양한 유틸리티성 기능과 검색에 유연하다.
설정 데이터의 보관소
이는 Redis같은 Key-Value DB가 유용하다고 여겨질 수 있으나, 검색 조건의 다양화가 필요할 경우 MongoDB가 훨씬 유용하다.
null 필드가 많이 존재할 때
데이터에 null 필드가 가변으로 다양하게 존재할 경우, rdb보다 스토리지 사용량, 처리 속도등에서 효율이 좋다.
압도적인 퍼포먼스가 필요할 떄
RDB 대비 100배 이상의 차이를 내는 압도적인 퍼포먼스 차이.
memory mapped file 기반 구조에서의 장점
nosql 계열에서 압도적인 index 활용도
Single Field Indexes : 기본적인 인덱스 타입
Compound Indexes : RDBMS의 복합인덱스 같은 거
Multikey Indexes : Array에 미챙되는 값이 하나라도 있으면 인덱스에 추가하는 멀티키 인덱스
Geospatial Indexes and Queries : 위치기반 인덱스와 쿼리
Text Indexes : String에도 인덱싱이 가능
Hashed Index : Btree 인덱스가 아닌 Hash 타입의 인덱스도 사용 가능
집계 연산, paging, 복잡한 쿼리 (단일 document 한정)가 필요할 때
key-value db (redis, aerospike 등)와 달리 집계 연산, paging이 가능함.
RDB와 동일한 접근의 데이터 스토어로서 사용 가능함.
실제로 쿼리 변환기가 존재함.
스키마 관리가 불필요함.
json 기반 저장 구조로, 유연한 동적 데이터 저장이 가능.
정규화할 데이터보다는, 단일 스키마 기반의 참조 데이터 저장에 장점이 많음.
로그성 데이터도 매우 적합 함.
부적절한 사용 사례
데이터 무결성이 가장 중요한 가치 일 때
단일 document 무결성은 유지되지만, 멀티 document 무결성은 유지 되지 않음.
애초에 join이 되지 않는지라, 일말이 오차는 존재할 수 있음.
데이터 처리량보다 일관성 있는 데이터 구조가 중요할 때
데이터 처리량이 빠른 이유는 ACID를 수행하지 않기 때문이다.
특히 샤딩+레플리카를 조합해서 사용 할 때 무결성이 깨진 상태의 데이터가 조회 될 수 있다. (document 자체가 corrupt 된다는 의미는 아니고, 조회한 시점 이전의 데이터가 조회 될 수 있거나, 이미 삭제된 데이터가 조회될 수 있다는 의미)
운용 이슈에 대한 우려 사항들이 해소가 덜 됐을 때
NoSQL 계열도 여타 DB와 마찬가지로 운용 이슈가 중요하고, 이에 대한 경험과 노하우가 부족하다면, 이 부분이 리스크가 될 수 있다.
임계치가 높을 뿐 RDB와 마찬가지로 데이터가 많아지면 성능이 저하되는 부분은 마찬가지고, 이를 해결하기 위한 방안과, 풀 스캔이나, 메모리 사용량이 커질 수 있는 작업을 production 레벨에선 사용할 수 없게 만들어야 한다.
데이터 무결성이 무엇보다 중요할 때
결제, 아이템 등을 담기엔 여전히 RDB보단 불안한 면이 존재한다.
엄격한 데이터 타입 검사나 연관 관계가 중요할 때
데이터 타입이 동적 결정되는 스키마리스 DB이고, 컬럼도 동적 컬럼이다보니 마이그레이션이 어려운 편이고, 제약 검사를 추가할 만큼 스키마가 중요하다면 선택해선 안된다.
코드 레벨에서 제어할 방법도 있지만, 접근 권한을 준 다른 서버 혹은 툴 등에서 쿼리를 날렸을 때 이를 막을 수 없다.
또한 테이블 간 연관 관계가 중요하다면, 이 또한 선택지에서 배제해야 한다.
위에서 언급한 대로 여러 document (테이블)을 동시에 조회할 수 없기에, 동일한 시점에 무결성이 깨지지 않은 데이터를 조회할 수 없다.
