
스케줄링
- OSTEP의 6/7장은 프로세스 스케줄링에 대해서 다루기는 하지만, 쓰레드 스케줄링의 알고리즘도 비슷
- 근본적으로 CPU 시간을 적절히 할당하고, 선점을 이용해 실행 순서를 제어할 수 있는 건 동일
- 선점: 현재 CPU를 사용 중인 쓰레드 강제 중단 -> 운영체제가 다른 (우선순위가 더 높은) 작업에 CPU를 할당
- 이때 중단되는 쓰레드를 선점한다라고 함
- Round Robin, Priority, Multilevel Queue 등 알고리즘도 비슷
쓰레드 전환
- 실행 중인 쓰레드를 멈추고 다른 프로세스로 전환하는 과정
운영체제의 제어권 확보
- 일단 제어권을 운영체제로 넘겨야, 쓰레드를 전환할 수 있음
- 방식 1: 사용자 프로그램의 시스템 콜 호출
- 운영체제의 코드가 실행되어 제어권이 운영체제로 넘어감
- e.g.,
yield시스템 콜: 현재 쓰레드가 CPU를 반납 -> 다른 쓰레드에 CPU를 할당 운영체제에 제어를 넘겨, CPU를 다른 쓰레드에 할당- PintOS 기준
void thread_yield(void)
- PintOS 기준
- 방식 2: 타이머 인터럽트
- 타이머는 수 밀리초(10msec)마다 인터럽트(하드웨어 신호)를 발생
- 이러한 인터럽트를 틱이라고 함. 1초엔 약 100번의 틱이 발생.
- 인터럽트 발생 시, 운영체제는 수행 중인 쓰레드를 중단하고 인터럽트 핸들러를 실행
- 인터럽트 핸들러는 운영체제의 코드이므로, 제어권이 운영체제로 넘어감
- 타이머는 수 밀리초(10msec)마다 인터럽트(하드웨어 신호)를 발생
문맥의 저장과 복원
- 운영체제게 제어권을 확보하면, 스케줄러가 현재 쓰레드를 계속 실행할지, 다른 쓰레드로 전환할지 결정
- 다른 쓰레드로 전환 시, 문맥 전환(context switch) 코드 실행
- 이전 쓰레드의 상태(state)를 저장하고, 새 쓰레드의 상태(state)를 복원하는 과정
- e.g., 쓰레드 A -> B 전환 (tmi일수도?)
- (1) 현재 쓰레드의 사용자 레지스터 값을 커널 스택에 저장 -> 커널 모드에 진입
- (2) 운영체제가 스케줄러를 통해 쓰레드를 전환 결정
- 여기서부터 본격적인 문맥 전환 과정
- (3) A가 사용하던 커널 레지스터 값을 A의 쓰레드 구조체에 저장하고, B의 쓰레드 구조체에 저장되어 있던 커널 레지스터 값 복원
- (4) 스택 포인터 레지스터의 값을 A의 커널 스택 -> B의 커널 스택으로 변경
- 여기서 문맥 전환 완료
- (5) B의 사용자 레지스터 값을 복원하고, 실행 시작
- PintOS 기준 레지스터 값 정보는
struct thread의struct intr_frame fr멤버에 있음. 이해할 필요 없음 - PintOS 기준 문맥 전환은
thread_launch()함수 내 어셈블리 코드로 진행. 이해할 필요 없음- 대신 그걸 호출하는
schedule()그리고 그걸 호출하는do_schedule()은 더 이해해야 할듯
- 대신 그걸 호출하는
인터럽트 켜기/끄기
- 시스템 콜을 처리하는 도중 타이머 인터럽트가 발생하거나
- 한 인터럽트를 처리할 때 다른 인터럽트가 발생하는 경우...
- (1) 인터럽트를 처리하는 동안 다른 인터럽트를 불능화할 수 있음
- 어떤 인터럽트도 CPU에게 전달되지 않음
- PintOS 기준
enum intr_level intr_disable (void);로 인터럽트 불능화 가능 - 단, 장기간 불능화하면 손실되는 인터럽트가 생기게 됨
- (2) 내부 자료구조의 동시 접근을 방지하기 위해 세마포어 / 락 등 사용
- 커널 내부 자료구조를 락으로 보호
스케줄링
- 본 예제에선 각 작업의 실행 시간을 미리 알 수 있지만, 실제론 안 그런 경우가 더 많음에 유의할 것.
- 작업이 바뀔 때 앞서 살펴본 문맥 교환 비용이 발생함에 유의할 것.
반환 시간
-
작업은 쓰레드 / 프로세스라고 생각하면 됨
-
반환 시간 = (작업이 완료된 시각) - (작업이 도착한 시각)
-
공정성: 각 작업에 공정한 실행 기회가 돌아가는가
-
보통 반환시간과 공정성은 상충
선입선출 (FIFO)
- 먼저 도착한 작업을 먼저 스케줄링한다.
- [예제 1] 시스템에 간발의 차이로 A -> B -> C 순으로 도착
- 본 예제에선 도착 시간이 (거의) 동시에 도착한다고 가정. 즉 으로 가정함.
- 각 작업은 10초 동안 실행됨
- 결론: 는 10, 는 20, 는 30에 종료. 평균 반환시간은 20.
- [예제 2] [예제 1]과 동일하지만, A는 100초, B/C는 10초 동안 실행됨
- 먼저 도착한 A가 먼저 100초동안 실행됨
- 이후 B, C가 10초씩 실행됨
- 결론: 는 100, 는 110, 는 120에 종료. 평균 반환시간은 110.
- convoy effect: CPU를 짧게 쓰레드가, CPU를 오래동안 사용하는 쓰레드를 기다리는 현상
- 이렇게 작업 간 실행 시간이 다르면, 더 효율적인 알고리즘이 있을 것

최단작업 우선 (SJF)
- shortest job first
- 가장 짧은 실행 시간을 가진 작업을 먼저 스케줄링한다.
- [예제 2]를 FIFO 말고 SJF로 수행한다면?
- B -> C -> A 순으로 실행
- 결론: 는 10, 는 20, 는 120에 종료. 평균 반환시간은 50.
- 모든 작업이 동시에 도착하면, SJF는 최적의 스케줄링 알고리즘
- [예제 3] 하지만 는 , 는 에 도착한다면
- 엔 밖에 없으니 실행
- 는 가 끝날 때까지 기다려야 함 -> convoy 문제 다시 발생
최소 잔여시간 우선 (STCF)
- shortest time-to-completion first
- FIFO, SJF는 비선점 스케줄러: 각 작업이 종료될 때까지 계속 수행
- B, C가 도착했을 때 스케줄러가 A를 중지하고 B, C를 먼저 실행하면(선점) 더 효율적이지 않을까?
- 선점으로 종료된 A를 나중에 다시 실행하면 되지 않을까?
- SJF에 선점 기능을 추가한 스케줄러: STCF
- 새로운 작업이 도착하면, 현재 실행 중 작업의 잔여 실행 시간과, 새로운 작업의 잔여 실행 시간 비교
- 잔여 실행 시간이 가장 작은 작업 스케줄링
- [예제 3] ( 는 , 는 에 도착한다면)
- -> A밖에 없으니 A 스케줄링
- -> B->C 도착. A(잔여시간 90)의 실행 중지 후 B(잔여시간 10) 스케줄링
- -> B 종료, C 스케줄링
- -> C 종료, 중단된 A 스케줄링
- -> A까지 종료
- 평균 반환시간 ((120 - 0) + (20 - 10) + (30 - 10)) / 3 = 50.
응답 시간
- 응답 시간(): 이전 반환시간과 다름.
- 사실 반환시간은 실제론 우리가 작업이 걸릴 시간을 모르기도 하니, 그걸 계산하는 건 비현실적이기도 하고...
- (응답 시간) = (작업이 처음으로 스케줄되는 시간) - (작업이 도착하는 시간)
- [예제 3]을 STCF 기준으로 스케줄링할 때 응답 시간은?
- A: 오자마자 스케줄링됨 ()
- B: 오자마자 스케줄링됨 ()
- C: B의 완료 후 스케줄링됨 ()
- 평균
Round Robin / 타임 슬라이싱
- 작업이 끝날 때까지, 혹은 새로운 작업이 도착할 때까지 기다리지 않음
- 일정 시간 동안 실행 후, 실행 큐의 다음 작업으로 전환
- 특별히 다음 작업을 뽑는 기준이 있는 건 아니고, 단순히
ready_list다음에 있는 작업이 실행됨. - PintOS에선
static struct list ready_list; - 타임 슬라이스: 작업이 실행되는 일정 시간 (핀토스 기준 40ms, 4 ticks)
- 타이머가 10ms마다 인터럽트를 발생하면, 타임 슬라이스는 10ms의 배수로 설정할 수 있음
- 특별히 다음 작업을 뽑는 기준이 있는 건 아니고, 단순히
- [예제 4] 3개의 작업 A, B, C가 동시에 도착하고, 각각 5초 간 실행됨
- SJF: 0-5초 A, 5-10초 B, 10-15초 C 실행
- 반환 시간: A (), B (), C ()이므로 평균
- 응답 시간: A (), B (), C ()이므로 평균
- 타임슬라이스가 1초인 RR: 0-1초 A, 1-2초 B, 2-3초 C, and so on...
- 반환 시간: A (), B(), C()이므로 평균
- 응답 시간: A (), B(), C()이므로 평균
- SJF: 0-5초 A, 5-10초 B, 10-15초 C 실행
- 타임슬라이스가 짧을수록 RR의 응답시간 성능은 좋아짐
- 하지만 너무 짧게 지정하면 문제가 생김. 문맥교환 비용 때문
- 반면 반환시간 성능은 안 좋아짐. 공정한 정책 특성상 어쩔 수 없음
- SJF/STCF는 반환시간 측면에선 좋고, 응답시간 측면에선 나쁨.
- RR은 응답시간 측면에선 좋고, 반환시간 측면에선 나쁨.
핀토스에선
- 당연히 작업이 언제 끝날 지는 알 수 없으니, STCF 같은 애는 쓸 수 없음.

do_schedule(): 현재 쓰레드의 상태를 지정된 상태로 바꾸고,schedule()함수 실행.schedule(): Ready list 맨 앞에 있는 쓰레드로 context switch.- 이 두개를 바꿔야 할까요? 뭔가 아닐 것 같은데 어차피 ready list 맨 앞에 있는 걸 꺼내야 하니까
- 대신 노드를 삽입할 때 뭔갈 해 줘야 되는 듯?
Ready List?
- priority가 높은 순 -> 낮은 순으로
- 적절한 삽입 위치는 사전 정의된
list_insert_ordered으로 찾을 수 있음 - 그러면 매번 다음 수준으로, priority가 제일 높은 노드를 얻을 수 있음
Busy Waiting
스케줄링
- OSTEP의 6/7장은 프로세스 스케줄링에 대해서 다루기는 하지만, 쓰레드 스케줄링의 알고리즘도 비슷
- 근본적으로 CPU 시간을 적절히 할당하고, 선점을 이용해 실행 순서를 제어할 수 있는 건 동일
- 선점: 현재 CPU를 사용 중인 쓰레드 강제 중단 -> 운영체제가 다른 (우선순위가 더 높은) 작업에 CPU를 할당
- 이때 중단되는 쓰레드를 선점한다라고 함
- Round Robin, Priority, Multilevel Queue 등 알고리즘도 비슷
쓰레드 전환
- 실행 중인 쓰레드를 멈추고 다른 프로세스로 전환하는 과정
운영체제의 제어권 확보
- 일단 제어권을 운영체제로 넘겨야, 쓰레드를 전환할 수 있음
- 방식 1: 사용자 프로그램의 시스템 콜 호출
- 운영체제의 코드가 실행되어 제어권이 운영체제로 넘어감
- e.g.,
yield시스템 콜: 현재 쓰레드가 CPU를 반납 -> 다른 쓰레드에 CPU를 할당 운영체제에 제어를 넘겨, CPU를 다른 쓰레드에 할당- PintOS 기준
void thread_yield(void)
- PintOS 기준
- 방식 2: 타이머 인터럽트
- 타이머는 수 밀리초(10msec)마다 인터럽트(하드웨어 신호)를 발생
- 이러한 인터럽트를 틱이라고 함. 1초엔 약 100번의 틱이 발생.
- 인터럽트 발생 시, 운영체제는 수행 중인 쓰레드를 중단하고 인터럽트 핸들러를 실행
- 인터럽트 핸들러는 운영체제의 코드이므로, 제어권이 운영체제로 넘어감
- 타이머는 수 밀리초(10msec)마다 인터럽트(하드웨어 신호)를 발생
문맥의 저장과 복원
- 운영체제게 제어권을 확보하면, 스케줄러가 현재 쓰레드를 계속 실행할지, 다른 쓰레드로 전환할지 결정
- 다른 쓰레드로 전환 시, 문맥 전환(context switch) 코드 실행
- 이전 쓰레드의 상태(state)를 저장하고, 새 쓰레드의 상태(state)를 복원하는 과정
- e.g., 쓰레드 A -> B 전환 (tmi일수도?)
- (1) 현재 쓰레드의 사용자 레지스터 값을 커널 스택에 저장 -> 커널 모드에 진입
- (2) 운영체제가 스케줄러를 통해 쓰레드를 전환 결정
- 여기서부터 본격적인 문맥 전환 과정
- (3) A가 사용하던 커널 레지스터 값을 A의 쓰레드 구조체에 저장하고, B의 쓰레드 구조체에 저장되어 있던 커널 레지스터 값 복원
- (4) 스택 포인터 레지스터의 값을 A의 커널 스택 -> B의 커널 스택으로 변경
- 여기서 문맥 전환 완료
- (5) B의 사용자 레지스터 값을 복원하고, 실행 시작
- PintOS 기준 레지스터 값 정보는
struct thread의struct intr_frame fr멤버에 있음. 이해할 필요 없음 - PintOS 기준 문맥 전환은
thread_launch()함수 내 어셈블리 코드로 진행. 이해할 필요 없음- 대신 그걸 호출하는
schedule()그리고 그걸 호출하는do_schedule()은 더 이해해야 할듯
- 대신 그걸 호출하는
인터럽트 켜기/끄기
- 시스템 콜을 처리하는 도중 타이머 인터럽트가 발생하거나
- 한 인터럽트를 처리할 때 다른 인터럽트가 발생하는 경우...
- (1) 인터럽트를 처리하는 동안 다른 인터럽트를 불능화할 수 있음
- 어떤 인터럽트도 CPU에게 전달되지 않음
- PintOS 기준
enum intr_level intr_disable (void);로 인터럽트 불능화 가능 - 단, 장기간 불능화하면 손실되는 인터럽트가 생기게 됨
- (2) 내부 자료구조의 동시 접근을 방지하기 위해 세마포어 / 락 등 사용
- 커널 내부 자료구조를 락으로 보호
스케줄링
- 본 예제에선 각 작업의 실행 시간을 미리 알 수 있지만, 실제론 안 그런 경우가 더 많음에 유의할 것.
- 작업이 바뀔 때 앞서 살펴본 문맥 교환 비용이 발생함에 유의할 것.
반환 시간
-
작업은 쓰레드 / 프로세스라고 생각하면 됨
-
반환 시간 = (작업이 완료된 시각) - (작업이 도착한 시각)
-
공정성: 각 작업에 공정한 실행 기회가 돌아가는가
-
보통 반환시간과 공정성은 상충
선입선출 (FIFO)
- 먼저 도착한 작업을 먼저 스케줄링한다.
- [예제 1] 시스템에 간발의 차이로 A -> B -> C 순으로 도착
- 본 예제에선 도착 시간이 (거의) 동시에 도착한다고 가정. 즉 으로 가정함.
- 각 작업은 10초 동안 실행됨
- 결론: 는 10, 는 20, 는 30에 종료. 평균 반환시간은 20.
- [예제 2] [예제 1]과 동일하지만, A는 100초, B/C는 10초 동안 실행됨
- 먼저 도착한 A가 먼저 100초동안 실행됨
- 이후 B, C가 10초씩 실행됨
- 결론: 는 100, 는 110, 는 120에 종료. 평균 반환시간은 110.
- convoy effect: CPU를 짧게 쓰레드가, CPU를 오래동안 사용하는 쓰레드를 기다리는 현상
- 이렇게 작업 간 실행 시간이 다르면, 더 효율적인 알고리즘이 있을 것
최단작업 우선 (SJF)
- shortest job first
- 가장 짧은 실행 시간을 가진 작업을 먼저 스케줄링한다.
- [예제 2]를 FIFO 말고 SJF로 수행한다면?
- B -> C -> A 순으로 실행
- 결론: 는 10, 는 20, 는 120에 종료. 평균 반환시간은 50.
- 모든 작업이 동시에 도착하면, SJF는 최적의 스케줄링 알고리즘
- [예제 3] 하지만 는 , 는 에 도착한다면
- 엔 밖에 없으니 실행
- 는 가 끝날 때까지 기다려야 함 -> convoy 문제 다시 발생
최소 잔여시간 우선 (STCF)
- shortest time-to-completion first
- FIFO, SJF는 비선점 스케줄러: 각 작업이 종료될 때까지 계속 수행
- B, C가 도착했을 때 스케줄러가 A를 중지하고 B, C를 먼저 실행하면(선점) 더 효율적이지 않을까?
- 선점으로 종료된 A를 나중에 다시 실행하면 되지 않을까?
- SJF에 선점 기능을 추가한 스케줄러: STCF
- 새로운 작업이 도착하면, 현재 실행 중 작업의 잔여 실행 시간과, 새로운 작업의 잔여 실행 시간 비교
- 잔여 실행 시간이 가장 작은 작업 스케줄링
- [예제 3] ( 는 , 는 에 도착한다면)
- -> A밖에 없으니 A 스케줄링
- -> B->C 도착. A(잔여시간 90)의 실행 중지 후 B(잔여시간 10) 스케줄링
- -> B 종료, C 스케줄링
- -> C 종료, 중단된 A 스케줄링
- -> A까지 종료
- 평균 반환시간 ((120 - 0) + (20 - 10) + (30 - 10)) / 3 = 50.
응답 시간
- 응답 시간(): 이전 반환시간과 다름.
- 사실 반환시간은 실제론 우리가 작업이 걸릴 시간을 모르기도 하니, 그걸 계산하는 건 비현실적이기도 하고...
- (응답 시간) = (작업이 처음으로 스케줄되는 시간) - (작업이 도착하는 시간)
- [예제 3]을 STCF 기준으로 스케줄링할 때 응답 시간은?
- A: 오자마자 스케줄링됨 ()
- B: 오자마자 스케줄링됨 ()
- C: B의 완료 후 스케줄링됨 ()
- 평균
Round Robin / 타임 슬라이싱
- 작업이 끝날 때까지, 혹은 새로운 작업이 도착할 때까지 기다리지 않음
- 일정 시간 동안 실행 후, 실행 큐의 다음 작업으로 전환
- 특별히 다음 작업을 뽑는 기준이 있는 건 아니고, 단순히
ready_list다음에 있는 작업이 실행됨. - PintOS에선
static struct list ready_list; - 타임 슬라이스: 작업이 실행되는 일정 시간 (핀토스 기준 40ms, 4 ticks)
- 타이머가 10ms마다 인터럽트를 발생하면, 타임 슬라이스는 10ms의 배수로 설정할 수 있음
- 특별히 다음 작업을 뽑는 기준이 있는 건 아니고, 단순히
- [예제 4] 3개의 작업 A, B, C가 동시에 도착하고, 각각 5초 간 실행됨
- SJF: 0-5초 A, 5-10초 B, 10-15초 C 실행
- 반환 시간: A (), B (), C ()이므로 평균
- 응답 시간: A (), B (), C ()이므로 평균
- 타임슬라이스가 1초인 RR: 0-1초 A, 1-2초 B, 2-3초 C, and so on...
- 반환 시간: A (), B(), C()이므로 평균
- 응답 시간: A (), B(), C()이므로 평균
- SJF: 0-5초 A, 5-10초 B, 10-15초 C 실행
- 타임슬라이스가 짧을수록 RR의 응답시간 성능은 좋아짐
- 하지만 너무 짧게 지정하면 문제가 생김. 문맥교환 비용 때문
- 반면 반환시간 성능은 안 좋아짐. 공정한 정책 특성상 어쩔 수 없음
- SJF/STCF는 반환시간 측면에선 좋고, 응답시간 측면에선 나쁨.
- RR은 응답시간 측면에선 좋고, 반환시간 측면에선 나쁨.
핀토스에선
- 당연히 작업이 언제 끝날 지는 알 수 없으니, STCF 같은 애는 쓸 수 없음.
do_schedule(): 현재 쓰레드의 상태를 지정된 상태로 바꾸고,schedule()함수 실행.schedule(): Ready list 맨 앞에 있는 쓰레드로 context switch.- 이 두개를 바꿔야 할까요? 뭔가 아닐 것 같은데 어차피 ready list 맨 앞에 있는 걸 꺼내야 하니까
- 대신 노드를 삽입할 때 뭔갈 해 줘야 되는 듯?
Ready List?
- priority가 높은 순 -> 낮은 순으로
- 적절한 삽입 위치는 사전 정의된
list_insert_ordered으로 찾을 수 있음 - 그러면 매번 다음 수준으로, priority가 제일 높은 노드를 얻을 수 있음
Busy Waiting
- 입출력 연산을 수행하는 작업의 경우
- 해당 작업은 입출력이 완료될 때까지 CPU를 쓰지 않음
- 입출력 동안 해당 작업은 상태가 BLOCKED로 변경. CPU에서 내려오고, ready list에서 제거해야 함.
- 입출력 완료를 기다리는 대기 상태로, 스케줄러는 그 시간 동안 다른 작업을 스케줄해야 함
- 입출력이 완료된 후에도 스케줄링이 필요함
- 입출력 완료 -> 인터럽트 발생
- 입출력을 요청한 프로세스를 대기상태(BLOCKED) -> 준비상태(READY)로 이동시켜야 함
- 즉 다시 ready list로 보내야 함
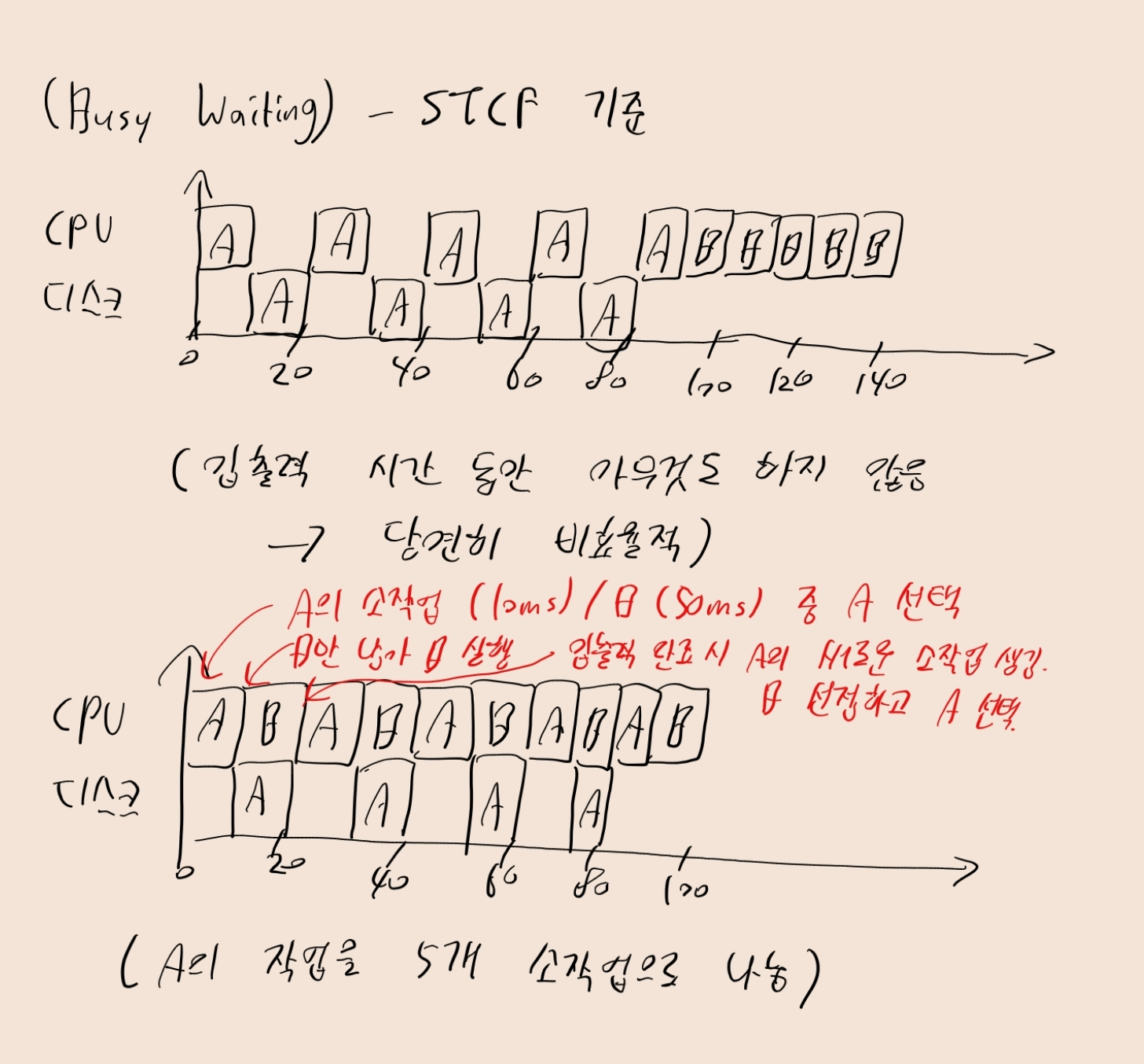
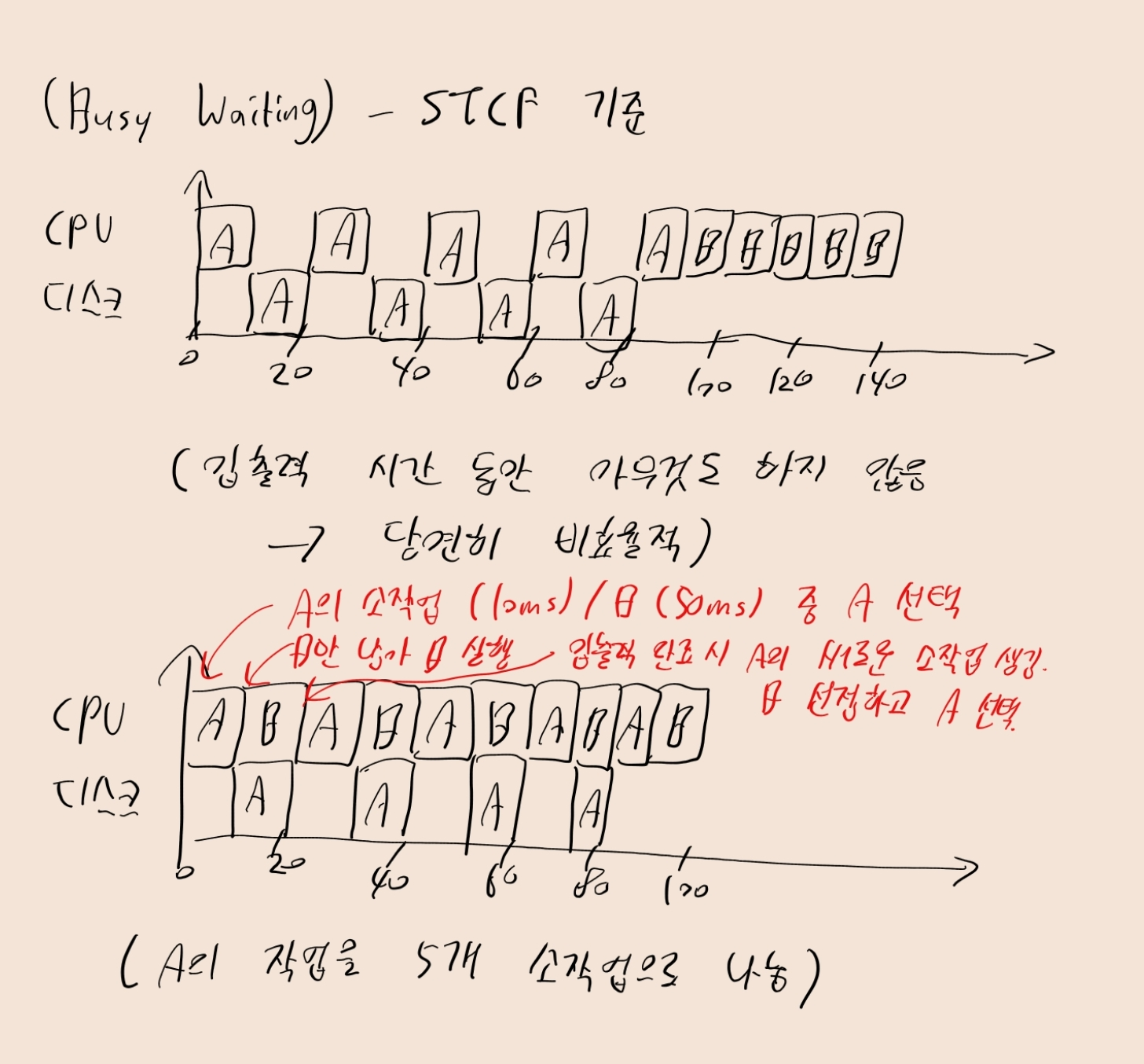
- [예제 5] 두 작업 A, B는 50ms의 CPU 시간을 필요로 함
- 단, A는 10ms 동안 실행된 후, 10ms의 입출력 요청을 거쳐야 다시 실행됨
- 반면 B는 입출력을 수행하지 않음
- 만약 입출력을 수행하는 동안 CPU가 하염없이 기다리고 있으면(busy waiting) 비효율적. 뭐라도 해야 함!!
- [예제 5]에선 A의 각 10ms 작업을 독립적 작업으로 간주해야 함
- STCF 기준, 시스템 시작시 A의 소작업(10ms) < B의 작업(50ms)이므로 A의 소작업 진행
- 이후 B의 작업(50ms) 수행하다, 10ms 지나면 입출력이 끝나 새로운 A의 소작업이 도착. 이때 B를 선점하고 A의 소작업을 수행.
sleep, 즉 우리의 예제는 어떨까?
timer_sleep (int64_t ticks) {
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
while (timer_elapsed (start) < ticks)
thread_yield ();
}- 효율적인 Sleep 방식이 아님. 매번
while조건문으로timer_elapsed(start) < ticks연산을 하고 있는데- 이 연산은 CPU를 점유하고 있음!!!!!
- 실제로는 프로세스를
ticks동안 ready list에서 제거하고, CPU를 다른 작업에 할당한 뒤,ticks이후 ready list로 복귀시켜야 함.- 일단 그러면 스케줄러를 먼저 개선해야 할 듯?
- 아니면 다른 방법이 있을려나?
즉, 이 스레드는 "자발적으로" 양보하지만, 여전히 실행 준비 상태(ready)이고,
계속 CPU를 다시 받으려고 시도합니다. 즉, CPU 스케줄링에 계속 참여 중이에요.
idle
- 준비 상태인 다른 쓰레드가 없을 때 실행됨
- ready list가 비어 있을 때??
- 입출력 연산을 수행하는 작업의 경우
- 해당 작업은 입출력이 완료될 때까지 CPU를 쓰지 않음
- 입출력 동안 해당 작업은 상태가 BLOCKED로 변경. CPU에서 내려오고, ready list에서 제거해야 함.
- 입출력 완료를 기다리는 대기 상태로, 스케줄러는 그 시간 동안 다른 작업을 스케줄해야 함
- 입출력이 완료된 후에도 스케줄링이 필요함
- 입출력 완료 -> 인터럽트 발생
- 입출력을 요청한 프로세스를 대기상태(BLOCKED) -> 준비상태(READY)로 이동시켜야 함
- 즉 다시 ready list로 보내야 함
- [예제 5] 두 작업 A, B는 50ms의 CPU 시간을 필요로 함
- 단, A는 10ms 동안 실행된 후, 10ms의 입출력 요청을 거쳐야 다시 실행됨
- 반면 B는 입출력을 수행하지 않음
- 만약 입출력을 수행하는 동안 CPU가 하염없이 기다리고 있으면(busy waiting) 비효율적. 뭐라도 해야 함!!
- [예제 5]에선 A의 각 10ms 작업을 독립적 작업으로 간주해야 함
- STCF 기준, 시스템 시작시 A의 소작업(10ms) < B의 작업(50ms)이므로 A의 소작업 진행
- 이후 B의 작업(50ms) 수행하다, 10ms 지나면 입출력이 끝나 새로운 A의 소작업이 도착. 이때 B를 선점하고 A의 소작업을 수행.
sleep, 즉 우리의 예제는 어떨까?
timer_sleep (int64_t ticks) {
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
while (timer_elapsed (start) < ticks)
thread_yield ();
}- 효율적인 Sleep 방식이 아님. 매번
while조건문으로timer_elapsed(start) < ticks연산을 하고 있는데- 이 연산은 CPU를 점유하고 있음!!!!!
- 실제로는 프로세스를
ticks동안 ready list에서 제거하고, CPU를 다른 작업에 할당한 뒤,ticks이후 ready list로 복귀시켜야 함.- 일단 그러면 스케줄러를 먼저 개선해야 할 듯?
- 아니면 다른 방법이 있을려나?
즉, 이 스레드는 "자발적으로" 양보하지만, 여전히 실행 준비 상태(ready)이고,
계속 CPU를 다시 받으려고 시도합니다. 즉, CPU 스케줄링에 계속 참여 중이에요.
idle
- 준비 상태인 다른 쓰레드가 없을 때 실행됨
- ready list가 비어 있을 때??

뭔가 만드는 걸 좋아하는 개발자 지망생입니다. 프로야구단 LG 트윈스를 응원하고 있습니다.