
OSTEP 8장 - MLFQ (멀티레벨 피드백큐)
- OSTEP 7장에서 응답 시간(
작업 종료 - 작업 도착)과 반환 시간(작업 첫 스케줄링 - 작업 도착)에 대해서 배웠음.- Round Robin은 응답시간 Good, 반환시간 Bad
- SJF / STCF는 반환시간 Good, 응답시간 Bad
- 둘 다 개선할 수 있는 방법은 없을까?
- 멀티레벨 피드백큐 -> 여러 개의 큐를 사용한다
- 즉 핀토스의
ready_list도 여러 개로 만들어야 할 수도 있을듯??
- 즉 핀토스의
우선순위
-
멀티레벨 피드백 큐는 우선순위를 사용
- 각 작업별로 다른 우선순위가 부여됨. 값이 클수록 우선순위가 높음
- e.g., 작업이 긴 시간 동안 CPU를 집중적으로 사용하면, MLFQ는 해당 작업의 우선순위를 낮춤
- e.g., 작업이 키보드 입력을 기다리며 반복적으로 CPU를 양보하면, MLFQ는 해당 작업의 우선순위를 높임
-
우선순위에 따른 스케줄링 규칙
- 규칙 1 A의 우선순위 > B의 우선순위이면, A가 실행되고 B는 실행되지 않음.
- 규칙 2 A의 우선순위 = B의 우선순위이면, A와 B는 RR 방식으로 실행됨.
-
cf. 큐를 1개 사용하는 기본 핀토스도 위와 같은 방식으로 스케줄링이 이루어짐.
우선순위의 변경
- MLFQ는 여러 개의 큐로 구성되며, 각 큐에는 다른 우선순위가 배정됨
- 즉 높은 우선순위 큐에 존재하는 작업이 선택됨
- CPU는 매 시점 가장 높은 큐에 있는 작업을 실행
- 규칙 3 작업이 시스템에 도착하면, 가장 높은 큐 (맨 위의 큐)에 놓여짐
- 규칙 4A 주어진 타임 슬라이스를 모두 사용하면, 우선순위는 낮아짐 (한 단계 아래 큐로 이동)
- 규칙 4B 타임 슬라이스를 모두 사용하기 전에 CPU를 양도하면, 현재 우선순위를 유지함
- 아래 예제에선 타임슬라이스가 10ms라고 가정
예제
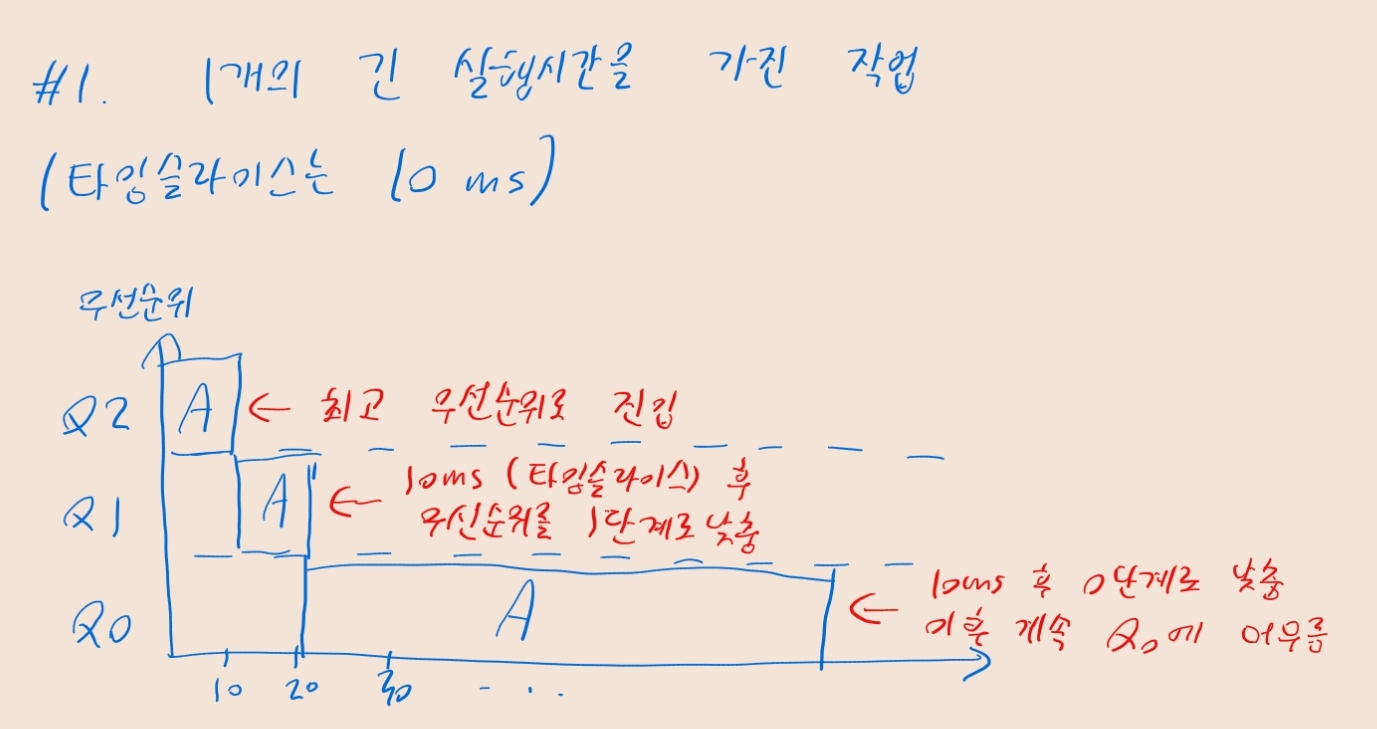
- 10ms 타임 슬라이스가 지날 때마다 우선순위가 낮아짐에 유의
- 즉 한단계 큐 아래로 내려감
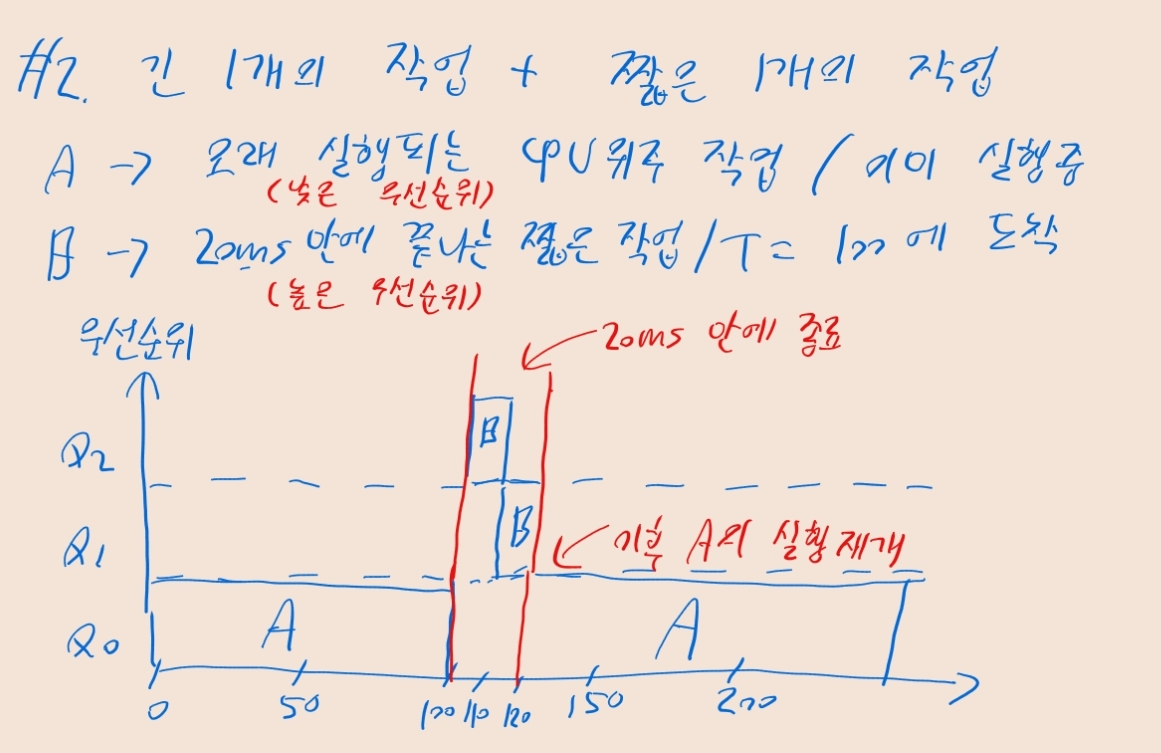
- e.g., A는 CPU를 오랫동안 점유하고, B는 짧게만 점유하는 대화형 작업일 때
- B의 실행시간은 20ms이므로, 2번의 타임 슬라이스만 소모하면 종료
- A는 하단 큐에 남아 있지만, 상단 큐에 B가 존재하므로 B가 우선 실행됨
- 스케줄러는 막 도착한 작업을 짧은 작업으로 가정 -> 높은 우선순위 부여
- 알고보니 짧은 작업이 아니라면, 천천히 아래 큐로 이동함
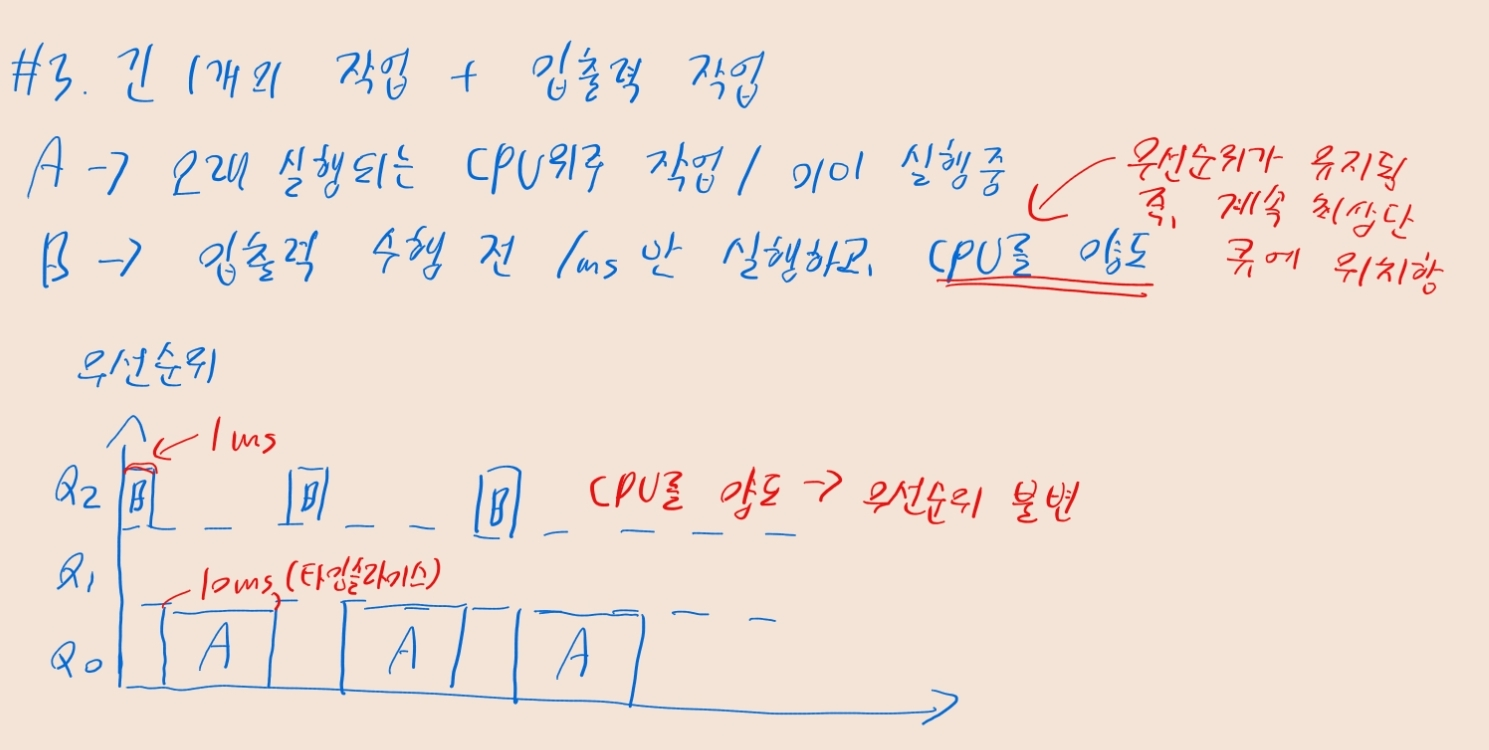
- 입출력을 하는 대화형 작업 B는, 입출력 작업 시작 전 CPU를 양도함
- 위 입출력 작업 B는 CPU를 계속해서 양도하므로, 가장 높은 우선순위 (맨 위 큐)를 유지
- 입출력을 하는 동안엔 작업 B는 Ready 상태가 아니라 Blocked 상태
- 잠시 큐에서 빠져나감 -> 입출력 끝나면 기존 우선순위를 유지한 채, Ready 상태로 전환되어 맨 위 큐에 재진입함
기아 상태
- 위 방식의 문제점: 기아 상태가 발생할 수 있음
- 시스템에 너무 많은 대화형 작업이 존재하면, 대화형 작업이 모든 CPU 시간을 소모함
- 따라서 CPU위주 작업 등, 긴 실행 시간 작업은 CPU를 할당받지 못함
- 이를 비유적으로 굶어 죽는다고 해 기아 상태라고 함
우선순위의 상향
- 기아 문제 해결을 위해, 주기적으로 모든 작업의 우선순위를 상향 조정(boost)할 수 있음
- 규칙 5: 일정 기간 가 지나면, 시스템의 모든 작업을 최상위큐로 이동시킨다
- (1) 프로세스가 굶지 않게 됨
- 최상위 큐에 존재하는 동안, 다른 높은 우선순위 작업들과 round robin 방식으로 우선순위 공유
- (2) CPU 위주 작업이 대화형 작업으로 변할 시, 우선순위를 상향하여 대처할 수 있음
- 를 부두 상수(voo-doo constant)라고도 부름
- 너무 크면, 상향이 너무 적게 이루어짐 -> 긴 실행 시간을 가진 작업이 기아 상태에 빠질 수 있음
- 너무 작으면, 상향이 너무 많이 이루어짐 -> 대화형 작업이 적절한 양의 CPU 시간을 사용할 수 없음
CPU 총 사용시간 측정
- 현재 MLFQ에선 타임 슬라이스가 끝나기 직전 CPU를 양도(e.g., 입출력)하는 경우, 지속해서 같은 우선순위에 머무를 수 있음
- 연속으로 타임 슬라이스를 모두 소비하는 경우에만, 우선순위가 내려감에 유의
- 이 경우 현재 작업이 CPU를 거의 독점하게 됨
- 해결책: 매번 작업이 사용한 CPU 사용 시간을 누적해 저장하기
- 누적 시간이 타임 슬라이스보다 길어지면, 다음 우선순위 큐로 강등
- 타임 슬라이스를 한 번에 소비하든, 짧게 여러번 소비하든 상관 없음
- 이를 반영해 규칙 4A, 4B 변경 가능
- 규칙 4A 주어진 타임 슬라이스를 모두 사용하면, 우선순위는 낮아짐 (한 단계 아래 큐로 이동)
- 규칙 4B 이때 CPU를 몇 번 양도했는지와 상관없이, 누적 시간이 타임 슬라이스보다 길어지면 강등
큐별로 다른 타임 슬라이스 할당
- 큐의 우선순위가 높을수록 타임 슬라이스를 짧게 할당할 수 있음
- 대화형 작업은 빠르게 교체하는 것이, CPU 기반의 오래 실행되는 작업은 오래 실행하는 것이 적절할 것
Priority Donation
- 다행히 lock에서의 priority donation만 구현하면 됨. semaphore, conditional variable 쪽은 구현 안해도 됨.
- lock을 기다리는 thread 중 priority가 제일 높은 thread의 priority를, 현재 실행 중인 thread의 priority에 기부하기
- 기부한다: 기부받은 thread의 priority를, 기부한 thread의 priority로 바꿔주는 것.
- 즉 기부받은 thread의 priority만 변경됨. 기부한 thread의 priority는 변경되지 않음
- e.g., thread A(pri=5)가 thread B(pri=3)에 기부하는 경우, thread B의 priority는 5 + 3 = 8이 아니라, 5가 됨.
- 당연하지만 현재 실행 중인 thread의 priority가 기다리는 thread보다 높은 경우, 기부가 이루어지지 않음
해야할 것
어떡하지?
버그 없나?
-
[구현 3-1]
struct thread구조체에 추가할 멤버들int saved_priority: priority donation이 이루어진 경우, donation 이전 priority를 저장.- 원래
priority의 경우 업데이트를 갱신하려고 함.
- 원래
struct lock *wait_on_lock: 현재 쓰레드가 대기 중인 lock.struct list *donations: 현재 쓰레드에게 priority를 기부할 수 있는 쓰레드들을 리스트로 관리.- priority 내립차순으로 관리. 기부할 수 있는 thread가 여러개면, 제일 높은 priority를 기부하게 되기 때문!
struct list_elem d_elem: list에 넣는 용도.
-
[구현 3-2]
init_thread: priority donation 관련 멤버도 초기화해야 함.- priority donation을 담당할 자료구조가 필요함
saved_priority멤버도,priority매개변수로 초기화해 줘야겠지?wait_on_lock을NULL로 해 줘야겠지?init_list로donations멤버 자리에 리스트를 만들어 두어야겠지?
-
[구현 3-3]
lock_acquire- lock을 얻을 수 없는 경우 (lock을 이미 acquire한 thread가 있는 경우.
lock -> holder != NULL) - (1) 현재 쓰레드의
wait_on_lock을, 현재 acquire하려는lock으로 갱신한다. - (2) lock을 acquire한 쓰레드의
donations리스트에 현재 쓰레드를 넣어 준다.- 이때
priority의 내림차순으로 넣어야 할 것임. 제일 높은 priority 기준이니까? (list_insert_ordered)
- 이때
- (3) lock을 acquire한 쓰레드의
priority를,donations맨 앞에 위치한 노드의priority로 갱신한다. (thread_set_priority). 단, 갱신할 priority가 높은 경우에만 갱신한다 - 빼먹은 게 있을까? 그건 나중에 하자.
- 난 이걸 위해
donate()함수 따로 만듦. 입력받은 쓰레드의 priority랑 donations 리스트 맨 앞priority 비교해서, 기부가 필요하면 기부하는 식.
// 입력받은 쓰레드의 priority와, donations 리스트 맨 앞의 priority를 비교 후, 기부가 필요하면 기부. void donate(struct thread *c_thread){ struct list *c_donations = &(c_thread -> donations); int front_priority = list_entry(list_begin(c_donations), struct thread, d_elem) -> priority; // 현재 lock을 가진 쓰레드의 priority를, donations 맨 앞 위치한 노드의 priority로 갱신 // 단, 갱신할 priority가 높은 경우만 if ((c_thread -> priority) < front_priority){ c_thread -> priority = front_priority; } // [구현 3-7] Nested Donation 구현 if (c_thread -> wait_on_lock != NULL){ donate(c_thread -> wait_on_lock -> holder); } } - lock을 얻을 수 없는 경우 (lock을 이미 acquire한 thread가 있는 경우.
-
[구현 3-4]
lock_release-
(1) lock->holder(lock을 갖고 있던 쓰레드)의
donations를 순회한다.- 순회하면서 확인한 쓰레드의
wait_on_lock멤버가lock과 일치하면, 해당 노드를 없앤다. - 없앤 노드의
wait_on_lock도NULL로 바꿔 주자. - 연결 리스트를 순회하면서 삭제할 때, 삭제된 노드의 다음 노드에 접근하면 에러가 발생할 수 있다.
- 순회하면서 확인한 쓰레드의
-
(2) thread의 priority를 남은
donations리스트의 최댓값 priority로 재설정한다.- 단 리스트가 빈 경우,
saved_priority로 재설정한다. (thread_set_priority)
- 단 리스트가 빈 경우,
-
-
[구현 3-5]
thread_set_priority- 일단
saved_priority,priority를 설정한 값으로 바꾼다.- 이후
donations리스트를 재정렬해 준다.
- 이후
- 이후 새롭게 set한 priority와, 현재 donate된 priority 중 높은 쪽을 기준으로 설정한다.
donate함수 잘 써먹음
- 일단
-
[구현 3-6]
thread_get_priority- priority를 기부받은 경우, donated priority를 반환해야 함
- 하지만 우리는
priority에 갱신된 priority를 두고saved_priority에 원래 priority를 두므로, 변경할 게 없음.
-
[구현 3-7] nested donation
- donation이 이루어진 후, donation받은 노드 역시 다른 lock에 걸려 있으면 연쇄적으로 donate
- 따로 만든
donate함수를 재귀 처리. 입력받은 쓰레드의 priority와 donations 리스트 맨 앞의 priority를 비교해서 기부 처리하는 함수인데, 매개변수를 donate당한 애로 넣어주면 될듯?
- 따로 만든
- donation이 이루어진 후, donation받은 노드 역시 다른 lock에 걸려 있으면 연쇄적으로 donate
-
이렇게 하면
priority-donate-sema빼고 다 됐는데sema_up에서 세마포어 기다리는 쓰레드들을 확인할 때, donation이 이루어져도 정렬되지 않았던 게 문제였음sema_up에서thread_unblock하기 전에&sema->waiters를 정렬시켜야 했다
void
sema_up (struct semaphore *sema) {
// [구현 2-5] 깨운 쓰레드의 priority가 더 높은 경우, CPU는 yield해줘야 함
enum intr_level old_level;
ASSERT (sema != NULL);
old_level = intr_disable ();
if (!list_empty (&sema->waiters)){
list_sort(&sema -> waiters, dsc_priority, NULL);
thread_unblock (list_entry (list_pop_front (&sema->waiters),
struct thread, elem));
}
sema->value++;
// 깨운 쓰레드의 priority가 더 높은 경우 yield
check_front_yield();
intr_set_level (old_level);
}
뭔가 만드는 걸 좋아하는 개발자 지망생입니다. 프로야구단 LG 트윈스를 응원하고 있습니다.