본 포스팅은 Redis를 활용한 캐싱의 핵심 개념과 주요 전략을 정리한 학습 노트다. 단순히 용어만 외우는 것이 아니라, "왜 이 전략이 필요한가"라는 맥락을 함께 짚어보는 방식으로 정리했다.
0. 들어가며
Redis를 처음 배울 때는 그냥 "빠른 저장소"라고만 생각했다. 그런데 실제로 활용하다 보면 단순히 빠른 게 아니라, 어떻게 데이터를 넣고, 얼마나 오래 두고, 언제 버릴 것인가까지 전략적으로 설계해야 한다는 걸 깨닫게 된다.
캐싱은 아무 데이터나 저장한다고 성능이 좋아지는 게 아니다. 잘못 설계하면 오히려 메모리만 낭비하거나, 오래된 데이터를 사용자에게 보여주는 역효과가 생긴다.
이번 글에서는 캐싱의 개념부터 시작해 실제로 자주 쓰이는 3가지 전략을 정리한다.
1. 캐시(Cache)란 무엇인가
캐시는 원래 CPU 내부에서 자주 쓰는 데이터를 빠르게 꺼내 쓰기 위한 작은 임시 저장소에서 비롯된 개념이다. 웹 개발에서의 캐싱은 이 아이디어를 애플리케이션 레벨로 확장한 것이다.
디스크 (영속성, 느림)
↓
RAM / 메모리 (빠름)
↓
캐시 (가장 빠름, 휘발성)웹 개발에서의 캐싱이란, DB에서 조회하는 데 시간이 오래 걸리는 데이터를 Redis 같은 인메모리 DB에 미리 저장해두고, 다음에 같은 요청이 들어왔을 때 DB를 거치지 않고 빠르게 응답하는 기술이다.
캐싱이 왜 필요한가
쿼리 한 번에 10~100ms가 걸리는 PostgreSQL과 달리, Redis는 같은 데이터를 1ms 이하로 응답한다. 조회가 빈번한 API일수록 이 차이는 더욱 크게 느껴진다.
실제 개발 환경에서 Redis를 적용했을 때 API 응답 시간이 30~50% 이상 단축되는 사례는 흔히 볼 수 있다.
캐싱의 장점을 정리하면 다음과 같다.
| 항목 | 설명 |
|---|---|
| 응답 속도 향상 | DB 대신 메모리에서 데이터를 읽어 응답 속도 대폭 개선 |
| DB 부하 감소 | 읽기 요청의 80~90%를 캐시에서 처리 가능 |
| 확장성 | 같은 DB 인프라로 더 많은 요청 처리 가능 |
브라우저 캐시도 같은 맥락이다. 자주 바뀌지 않는 이미지나 정적 자원을 로컬에 저장해 페이지 로드를 줄이는 것, 그리고 RESTful 설계 원칙에서 "응답이 캐시 가능한지 명시해야 한다"는 제약도 모두 이 캐싱 개념에서 출발한다.
2. 캐싱의 핵심 용어
전략을 이해하기 전에 반드시 알아야 할 용어들이 있다.
Cache Hit vs Cache Miss
클라이언트 요청
↓
[캐시 확인]
/ \
있음 없음
(Cache Hit) (Cache Miss)
↓ ↓
캐시에서 응답 DB 조회 후 응답
+ 캐시에 저장- Cache Hit : 캐시에 데이터가 있어 바로 반환하는 경우
- Cache Miss : 캐시에 데이터가 없어 원본 DB까지 조회하는 경우
- Cache Hit Ratio (적중률) : 전체 요청 중 Cache Hit이 차지하는 비율. 높을수록 좋다.
Eviction Policy (삭제 정책)
캐시는 메모리 공간이 한정적이다. 공간이 부족해지면 어떤 데이터를 먼저 제거할지 결정하는 규칙이 바로 삭제 정책(Eviction Policy)이다.
Redis가 지원하는 주요 정책은 아래와 같다.
| 정책 | 설명 |
|---|---|
allkeys-lru | 전체 키 중 가장 오래 사용되지 않은 것부터 제거 (LRU: Least Recently Used) |
allkeys-lfu | 전체 키 중 가장 적게 사용된 것부터 제거 (LFU: Least Frequently Used) |
volatile-lru | TTL이 설정된 키 중에서만 LRU 적용 |
volatile-ttl | TTL이 가장 짧게 남은 키부터 제거 |
noeviction | 메모리 한계 도달 시 새 쓰기 거부 (에러 반환) |
LRU vs LFU 어떤 걸 써야 할까?
LRU는 "최근에 안 쓴 데이터"를 버리고,
LFU는 "전체적으로 자주 안 쓴 데이터"를 버린다.
접근 패턴이 빠르게 변하는 경우엔 LRU가, 일정한 핫(hot) 데이터가 있는 경우엔 LFU가 캐시 적중률이 더 좋다.
Redis 공식 문서도 범용 캐싱에는 allkeys-lru를 기본 권장하고 있다.
TTL (Time To Live)
캐시 데이터에 만료 시간을 설정하는 것이다. TTL이 지나면 자동으로 해당 키가 삭제된다.
# TTL 300초(5분) 설정
SET product:123 '{"name":"노트북"}' EX 300TTL은 단순히 메모리 관리뿐 아니라, stale data(오래된 데이터) 문제를 방지하는 핵심 수단이기도 하다.
3. 캐싱 전략 3가지
이제 본론이다. 캐싱 전략은 크게 읽기 전략과 쓰기 전략으로 나뉜다. 커리큘럼에서 다루는 3가지를 하나씩 살펴보자.
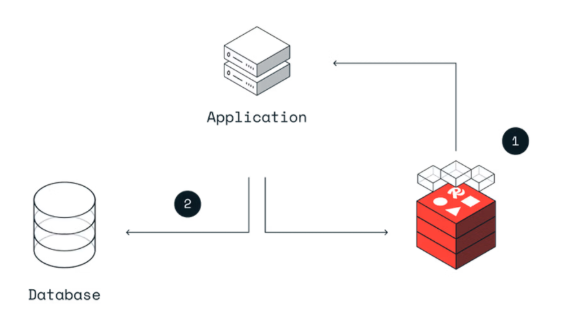
3-1. Cache-Aside (= Lazy Loading)
가장 널리 쓰이는 전략이다. "게으른 로딩"이라는 별명처럼, 필요할 때만 캐시에 데이터를 올린다.
동작 흐름
① 클라이언트가 데이터 요청
↓
② 애플리케이션이 캐시(Redis) 먼저 확인
↓
[Cache Hit] [Cache Miss]
캐시에서 바로 반환 → DB에서 데이터 조회
↓
결과를 캐시에 저장
↓
클라이언트에 반환코드 예시 (Spring / Java 의사코드)
public Product getProduct(Long productId) {
String cacheKey = "product:" + productId; // Redis 키 설계 (namespace:id 패턴 권장)
// ① 캐시에서 먼저 조회
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
// ② Cache Hit: 캐시에서 바로 반환
return objectMapper.readValue(cached, Product.class);
}
// ③ Cache Miss: DB에서 조회
Product product = productRepository.findById(productId)
.orElseThrow();
// ④ 조회한 결과를 캐시에 저장 (TTL 10분 설정)
redisTemplate.opsForValue().set(
cacheKey,
objectMapper.writeValueAsString(product),
Duration.ofMinutes(10) // TTL: 10분 후 자동 만료
);
return product;
}장단점 요약
| 장점 | 단점 |
|---|---|
| 실제로 요청된 데이터만 캐시에 저장됨 (메모리 효율적) | 최초 요청은 DB까지 가기 때문에 상대적으로 느림 |
| 캐시 장애 시 DB로 폴백(fallback) 가능 | 캐시와 DB 간 데이터 불일치(stale data) 가능성 있음 |
읽기가 많고 쓰기가 적은 서비스(예: 상품 목록, 공지사항 등)에 특히 잘 맞는 전략이다.
3-2. Write-Through
데이터를 쓸 때 캐시와 DB를 동시에 업데이트하는 전략이다.
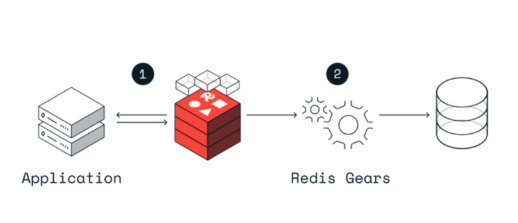
동작 흐름
클라이언트가 데이터 수정 요청
↓
① 캐시(Redis)에 먼저 저장
↓
② DB에도 저장 (동기 처리)
↓
완료 응답코드 예시
public Product updateProduct(Long productId, ProductUpdateRequest request) {
// ① DB 업데이트
Product product = productRepository.findById(productId).orElseThrow();
product.update(request);
productRepository.save(product); // DB에 저장
// ② 캐시도 즉시 업데이트 (데이터 일관성 보장)
String cacheKey = "product:" + productId;
redisTemplate.opsForValue().set(
cacheKey,
objectMapper.writeValueAsString(product),
Duration.ofMinutes(10) // TTL도 함께 갱신
);
return product;
}장단점 요약
| 장점 | 단점 |
|---|---|
| 캐시 데이터가 항상 최신 상태 유지 (강한 일관성) | 쓰기 요청마다 캐시 + DB 두 곳에 저장하므로 지연 발생 |
| Cache Miss가 거의 발생하지 않음 | 자주 읽히지 않는 데이터도 캐시에 쌓임 (메모리 낭비) |
실무에서는 Cache-Aside와 Write-Through를 함께 사용하는 경우가 많다. 읽기는 Cache-Aside로, 쓰기는 Write-Through로 처리하는 방식이다.
3-3. Write-Behind (= Write-Back)
데이터를 쓸 때 캐시에만 먼저 저장하고, 일정 주기로 DB를 비동기(async)로 업데이트하는 전략이다.
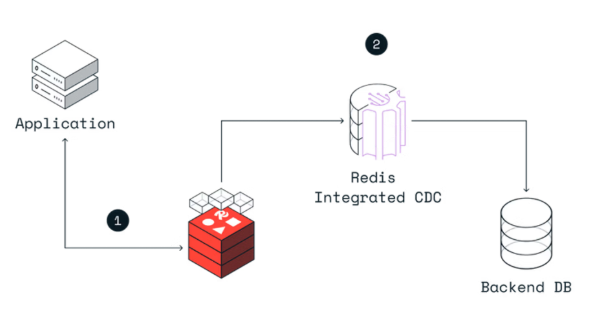
동작 흐름
클라이언트가 데이터 수정 요청
↓
① 캐시(Redis)에 저장 → 즉시 응답
↓
② 백그라운드에서 일정 주기로 DB에 반영 (비동기)장단점 요약
| 장점 | 단점 |
|---|---|
| 쓰기 응답이 매우 빠름 (DB 대기 없음) | 캐시 장애 시 DB에 반영 안 된 데이터 소실 위험 |
| 쓰기가 폭발적으로 많은 상황에서 DB 부하 대폭 감소 | 구현 복잡도가 높음 |
Write-Behind는 좋아요 수 집계, 조회수 증가 같이 쓰기가 매우 빈번하지만 순간적인 데이터 손실이 크게 치명적이지 않은 경우에 적합하다. 금융 거래 등 정합성이 중요한 도메인에는 부적합하다.
4. 전략 비교 한눈에 보기
어떤 전략을 선택해야 할까?
읽기 위주 서비스? → Cache-Aside (가장 보편적)
데이터 정합성 중요? → Write-Through
쓰기 폭증, 부하 분산? → Write-Behind| 전략 | 읽기 성능 | 쓰기 성능 | 데이터 일관성 | 메모리 효율 |
|---|---|---|---|---|
| Cache-Aside | 높음 (Hit 시) | 보통 | 보통 (stale 가능) | 높음 |
| Write-Through | 높음 | 낮음 (동기 이중 쓰기) | 높음 | 낮음 |
| Write-Behind | 높음 | 매우 높음 | 낮음 (비동기) | 보통 |
5. 추가 내용
Read-Through 패턴
Cache-Aside와 비슷하지만, 캐시 미스 시 캐시 레이어 자체가 DB를 조회해서 채워주는 방식이다. 애플리케이션 코드에서 DB 조회 로직을 분리할 수 있다는 장점이 있다.
Redis 자체는 이 패턴을 네이티브로 지원하지 않는다. 별도의 미들웨어나 라이브러리 레벨에서 구현해야 한다.
Cache Prefetching (캐시 워밍, Cache Warming)
Cache-Aside는 최초 요청이 항상 느리다는 단점이 있다. 이를 보완하기 위해 서비스 시작 전 자주 쓰이는 데이터를 미리 캐시에 적재해두는 기법이다. "온보딩(onboarding, 서비스 준비 단계)"에서 미리 캐시를 채워두는 셈이다.
Cache Stampede 문제
인기 있는 캐시 키의 TTL이 만료되는 순간, 수많은 요청이 동시에 DB로 몰리는 현상이다. 이를 방지하기 위해 분산 락(distributed lock) 또는 Probabilistic Early Refresh 기법을 사용한다.
// 단순한 방어 예시: 락을 이용한 재진입 방지 (개념)
// 실제 구현은 Redisson 등의 라이브러리 활용 권장
if (redisLock.tryLock()) {
try {
// DB에서 데이터 가져와 캐시 갱신
} finally {
redisLock.unlock();
}
}레거시 환경과의 현실
기존에 구축된 시스템에서는 캐싱 로직이 서비스 코드 곳곳에 흩어져 있는 경우가 많다. Spring의 @Cacheable, @CachePut, @CacheEvict 어노테이션을 활용하면 코드 레벨에서 캐싱 로직을 분리할 수 있고, 이는 다음 챕터에서 다룬다.
6. 정리
| 개념 | 요약 |
|---|---|
| 캐싱 | 자주 쓰는 데이터를 빠른 저장소에 올려두는 기법 |
| Cache Hit / Miss | 캐시에 데이터 있음 / 없음 |
| Eviction Policy | 캐시 공간 부족 시 삭제 기준 (LRU, LFU 등) |
| Cache-Aside | 읽을 때 캐시 먼저 확인, Miss 시 DB 조회 후 저장 |
| Write-Through | 쓸 때 캐시 + DB 동시 업데이트, 일관성 보장 |
| Write-Behind | 캐시에만 먼저 쓰고 DB는 나중에 비동기 반영 |
캐싱은 성능 최적화의 강력한 도구이지만, 잘못 설계하면 데이터 불일치나 메모리 낭비로 이어진다. 어떤 데이터가 자주 읽히고, 얼마나 자주 바뀌는지를 먼저 분석한 다음 전략을 선택하는 것이 올바른 순서다.
참고 자료
