
탐색 알고리즘(Search Algorithm)이란?
- 탐색 또는 검색이란 주어진 데이터 집합에서 원하는 데이터를 찾는 과정이다. 탐색 알고리즘은 탐색 작업을 효율적으로 수행할 수 있도록 설계된 알고리즘이다.
- 탐색 알고리즘은 메커니즘에 따라 선형(Linear), 이진(Binary), 해싱(Hashing)으로 구분된다.
- 탐색 알고리즘은 그 구현에 따라 여러 종류의 자료구조에서 작동할 수도 있지만 특정 자료구조에서만 작동할 수도 있다.
- 탐색 알고리즘이 활용되는 분야는 다음과 같다.
- 조합 최적화 문제(Combinatorial Optimization Problem)
- 제약 만족 문제(Constraint Satisfaction Problem)
- 게임 이론(Game Theory)
- 적대적 탐색(Adversarial Search)
- 지역 탐색(Local Search)
- 데이터베이스(Database)
- 트리 탐색 문제(Tree Search Problem)
순차 탐색(Sequential Search)
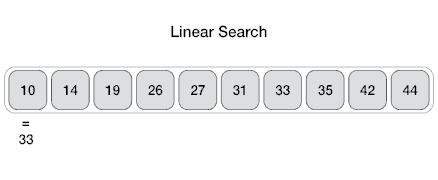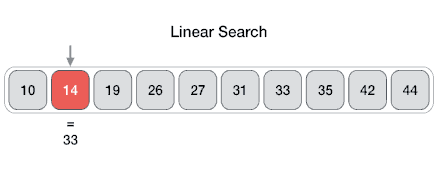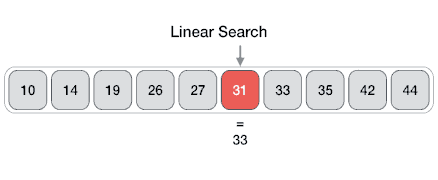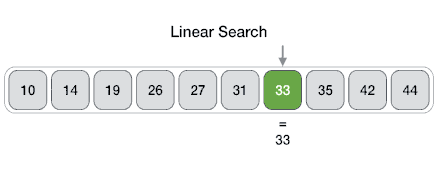
- 순차 탐색은 데이터의 처음부터 끝까지 모든 요소를 차례대로 비교하여 원하는 데이터를 찾는 탐색 알고리즘이다. 한쪽 방향으로만 탐색하므로 선형 탐색(Linear Search)과 같다.
- 가장 간단한 탐색 알고리즘이므로 구현이 쉽고, 정렬되지 않은 데이터에서 탐색할 수 있는 유일한 방법이지만 이진 탐색 같은 알고리즘 보다 비효율적이다.
- 순차 탐색의 최악의 시간 복잡도는 이며 공간 복잡도는 이다.
- 순차 탐색의 단점을 보완하기 위한 방법으로 자기 구성 순차 탐색(Self-Organizing Sequential Search)이 있다.
- 이는 자주 사용되는 항목을 데이터의 앞쪽에 배치함으로써 순차 탐색의 효율성을 개선하는 방법으로, 구현 방법에 따라 세 가지로 나뉜다.
- 전진 이동법(Move to Front Method): 탐색 된 요소를 데이터의 가장 앞으로 옮기는 방법이다.
- 전위법(Transpose Method): 탐색 된 요소를 바로 이전 항목과 교환하는 방법이다.
- 계수법(Frequency Count Method): 데이터의 각 요소가 탐색 된 횟수를 별도의 공간에 저장해두고, 탐색 된 횟수가 높은 순으로 데이터를 재구성하는 방법이다.
이진 탐색(Binary Search)
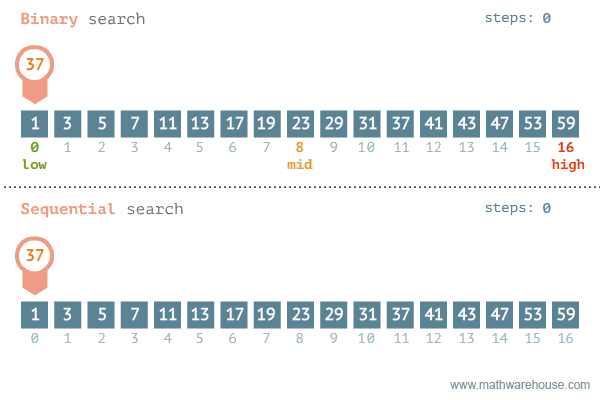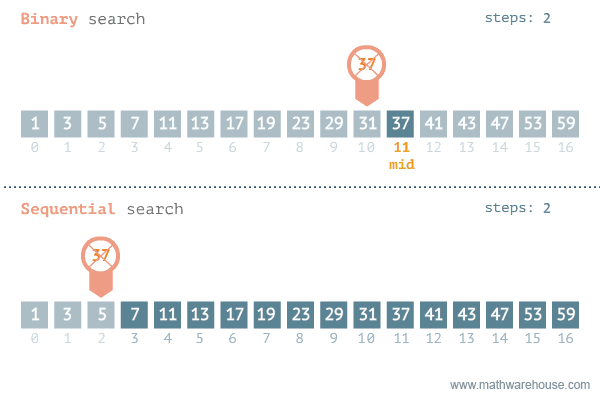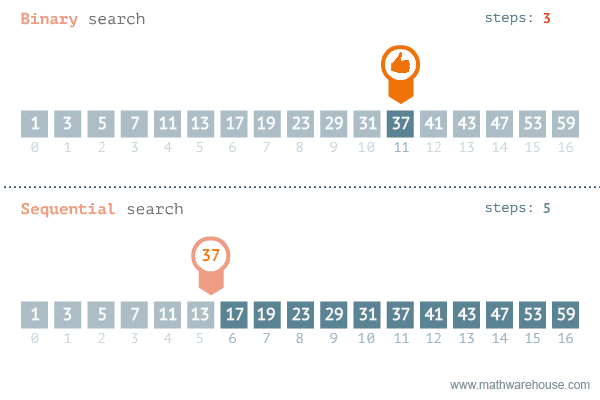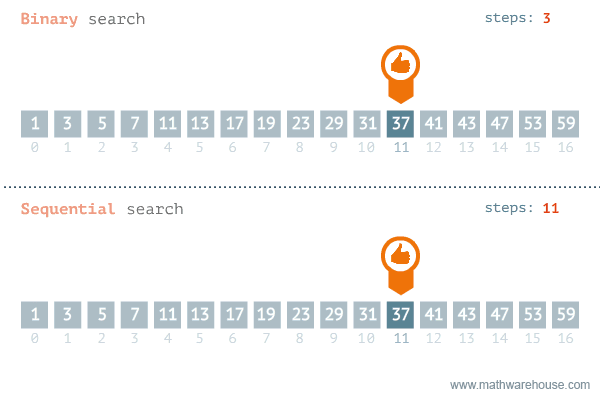
- 이진 탐색은 이미 정렬된 데이터에서 사용할 수 있는 탐색 알고리즘이다. 탐색 범위를 1/2씩 줄여나가는 방식이라 이진 탐색 또는 이분 탐색이라 부른다.
- 이진 탐색의 수행 과정은 다음과 같다.
- 데이터의 가운데 위치에 있는 요소(중앙 요소)를 찾는다.
- 목표 값이 중앙 요소보다 작다면 중앙을 기준으로 데이터의 왼쪽 부분으로, 크다면 오른쪽 부분으로 탐색 범위를 좁혀서 1번부터 반복한다. 목표 값과 같다면 그 위치를 반환한다.
- 데이터의 크기를 n, 이진 탐색의 반복 횟수를 x로 놓으면 다음과 같은 식이 나온다.
여기에 로그 함수를 적용하면 다음과 같다. - 따라서 이진 탐색의 최악의 시간 복잡도는 이 된다. 로그함수의 기울기가 매우 완만하기 때문에 데이터의 크기가 아무리 커져도 탐색에 필요한 시간은 매우 완만하게 증가한다. 100만 개의 데이터에서 이진 탐색을 실시하면 20회 이하, 1000만 개의 데이터에선 23회 이하의 탐색 횟수로 목표값을 찾을 수 있다.
- 이잔 탐색의 공간 복잡도는 이다.
- 기본적으로 이진 탐색은 정렬이 완료된 데이터에 대해 사용하지만 코딩 문제 풀이 시엔 시간 제한 때문에 데이터를 정렬하지 않은 상태에서 이진 탐색을 수행해야 풀 수 있는 경우도 있다.
- 단순한 이진 탐색 구현으로는 정렬된 배열 만을 탐색할 수 있다. 정적 배열 외에 연결 리스트 같은 동적으로 크기가 바뀌는 자료구조를 이진 탐색하려면 이진 탐색 트리 같은 변형된 이진 탐색 알고리즘이 필요하다.
- 또한 이진 탐색 트리를 사용하면 요소의 삽입과 삭제를 더 효율적으로 수행할 수 있다.
이진 탐색 트리(Binary Search Tree)
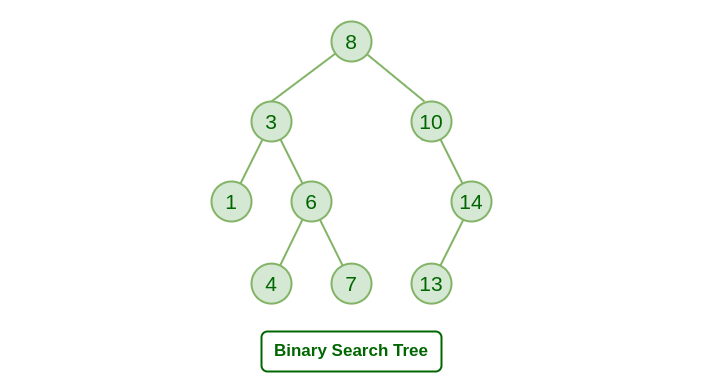
- 이진 탐색 트리란 이진 탐색을 위해서 구성하는 이진 트리로, 왼쪽 자식 노드는 부모 노드보다 작고 오른쪽 자식 노드는 부모 노드보다 크다는 규칙을 따른다.
- 이진 탐색 트리의 뿌리 노드는 트리 전체의 중앙 요소(중앙 값)가 된다.
- 이진 탐색 트리를 활용한 재귀적인 이진 탐색 과정은 다음과 같다.
- 뿌리 노드에서 시작하여, 목표 값을 현재 노드와 비교한다.
- 목표 값이 현재 노드보다 작으면 왼쪽 자식 노드로 이동하여 1번부터 반복한다.
목표 값이 현재 노드보다 크면 오른쪽 자식 노드로 이동하여 1번부터 반복한다. - 목표 값과 현재 노드의 값이 일치하면 노드를 반환한다. 트리에 목표 값이 존재하지 않으면 탐색을 종료한다.
- 이진 탐색 트리를 중위 순회(inorder traversal)하면, 모든 노드를 정렬된 순서로 탐색한다.
- 이진 탐색 트리는 이진 탐색이 가능한 상태로 정렬되어 있어야 한다. 이러한 상태를 유지하려면 노드의 삽입과 삭제가 이루어질 때마다 별도의 작업을 수행해야 한다.
- 이진 탐색 트리에서 노드의 삽입 연산은 이진 탐색으로 새 노드를 연결할 부모 노드를 찾아낸 후 그곳에 연결하는 방식으로 이루어진다. 삽입할 노드는 항상 트리의 잎 노드로 삽입된다.
- 이진 탐색 트리에서 노드의 삭제 연산은 일단 이진 탐색으로 삭제할 노드의 위치를 찾고, 그 노드를 트리에서 떼어내는 작업이 필요하다. 이때 삭제할 노드의 위치에 따라 수행 과정이 달라진다.
- 삭제할 노드가 잎 노드라면 삭제할 노드의 부모 노드의 포인터를 NULL로 초기화 하고 삭제할 노드의 메모리를 해제하면 된다.
- 삭제할 노드가 잎 노드가 아닌 경우 두 가지로 나뉜다.
- 삭제할 노드가 왼쪽과 오른쪽 중에 어느 한쪽 자식 노드만 갖고 있는 경우: 삭제할 노드의 자식 노드를 삭제할 노드의 부모 노드로 연결 시켜주면 된다.
- 삭제할 노드가 양쪽 자식 노드를 모두 갖고 있는 경우: 삭제할 노드의 오른쪽 하위 트리에서 가장 작은 값을 가진 노드(최소값 노드) 또는 왼쪽 하위 트리에서 가장 큰 값을 가진 노드(최대값 노드)를 삭제할 노드의 위치로 옮긴다.
- 옮겨온 노드가 자식이 없으면 연산을 종료한다.
- 옮겨온 노드가 자식이 있으면 그 자식 노드를 옮겨온 노드의 원래 부모 노드(삭제할 노드의 위치로 옮기기 전의 부모 노드)에 연결하면 된다.
-
이진 탐색 트리의 공간 복잡도는 이며 탐색, 삽입, 삭제 연산에 대한 최악의 경우 시간 복잡도는 이다. 평균적인 경우의 시간 복잡도는 모든 연산에 대해 이다.
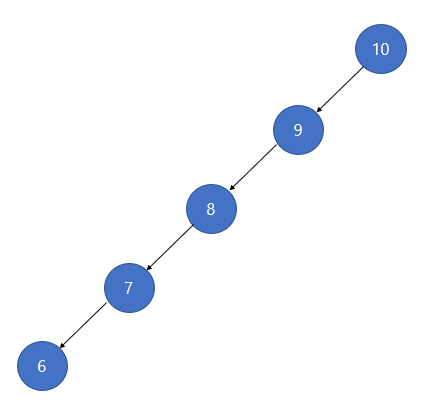
-
이진 탐색 트리는 훌륭한 탐색 알고리즘이지만, 노드를 삽입하고 삭제하다보면 트리가 한쪽으로 쏠린 모양이 되기 쉽다는 단점이 있다. 예를 들어 10, 9, 8, 7, 6의 순서로 삽입하여 이진 탐색 트리를 만들면 위와 같은 모양의 이진 트리가 되는데 이렇게 한 쪽으로 치우친 이진 트리를 경사 이진 트리라고 한다.
-
이진 탐색 트리가 이렇게 경사 이진 트리같은 모양이 될수록 탐색의 시간 복잡도가 이진 탐색이 아닌 순차 탐색에 가까워지기 때문에 탐색의 효율성이 저하된다.
-
이러한 문제를 해결하려면 트리에 노드를 삽입하거나 삭제할 때 마다 높이를 낮게 유지하여 균형을 잡는 자가 균형(self-balancing) 이진 탐색 트리가 필요하다. 이러한 트리로는 AVL 트리, 레드-블랙 트리 등이 있다.
-
자가 균형 트리 외에 다른 방법으로는 자주 탐색되는 노드를 트리의 뿌리 노드에 가깝게 재배치하는 방법이 있다. 이러한 트리로 스플레이(Splay) 트리가 있다.
스플레이 트리(Splay Tree)
- Splay의 사전적인 의미는 손가락·다리 등을 벌리다 이다.
- 스플레이 트리는 자주 탐색되는 노드를 뿌리 노드에 가깝게 위치하도록 만드는 이진 탐색 트리이다.
- 스플레이 트리에서 탐색, 삽입, 삭제 연산이 일어날 때마다 특정 노드를 뿌리로 옮기는 연산이 필요한데, 이를 스플레잉(Splaying)이라 부른다.
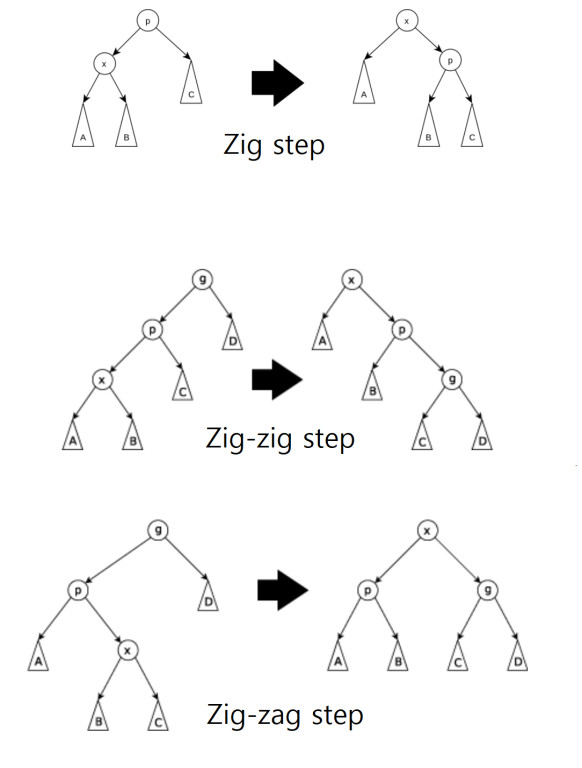
- 스플레잉은 Zig, Zig-Zig, Zig-Zag의 세 가지 유형으로 나뉜다.
- x: 최근에 접근한 노드, p: x의 부모 노드, g: x의 조부모 노드
- Zig step: p가 트리의 뿌리 노드인 경우에 수행된다. p와 x의 간선 연결을 회전시킨다.
- Zig-Zig step: p가 루트가 아니고 x와 p가 동일하게 왼쪽 자식 또는 오른쪽 자식인 경우에 수행된다. p와 g와의 간선 연결을 회전시키고, 그다음에 x와 p의 간선 연결을 회전시킨다.
- Zig-Zag step: p가 루트가 아니고 x가 왼쪽 자식, p가 오른쪽 자식이거나 그 반대인 경우(x가 오른쪽 자식, p가 왼쪽 자식)에 수행된다. x와 p의 간선 연결을 회전시키고, 그다음에 x와 x의 새로운 부모 p와의 간선 연결을 회전시킨다.
- 스플레이 트리의 공간 복잡도는 이며 탐색, 삽입, 삭제 연산에 대한 최악의 시간 복잡도는 모두 이지만 분할 상환(Amortized) 분석을 하면 이 된다.
- 스플레이 트리는 평균적인 상황에서 다른 이진 탐색 트리 알고리즘과 성능이 비슷하며 참조 지역성이 중요한 경우 유용한 알고리즘이다. 하지만 트리의 균형이 깨지기 쉽다는 단점도 있다.
AVL 트리(AVL Tree)
- AVL 트리는 자가 균형 이진 탐색 트리의 일종으로, 알고리즘을 발명한 Georgy Adelson-Velsky와 Evgenii Landis의 이름을 따서 AVL 트리라고 부른다.
- AVL 트리는 높이 균형(height balanced) 트리이며, 모든 노드의 왼쪽 서브트리의 높이와 오른쪽 서브트리의 높이 간의 차이는 1이하 여야 한다.
- AVL 트리의 탐색 과정은 이진 탐색 트리의 탐색 방법과 동일하다.

- AVL 트리에서 노드를 삽입하거나 삭제하면 균형이 깨질 수 있기 때문에 노드의 위치를 재구성하는 과정이 필요하다. 이 과정은 보통 노드를 회전(rotation)시키는 방법으로 구현된다. 회전은 부모와 자식 노드의 위치를 서로 바꾸는 연산이다.
- 불균형은 모두 4가지 유형(Left-Left, Right-Right, Left-Right, Right-Left)으로 나뉘는데, 이에 대응하는 회전 작업을 수행하는 식으로 균형을 맞춘다.
- AVL 트리의 공간 복잡도는 이며, 모든 상황에서 탐색, 삽입, 삭제의 시간 복잡도가 으로 동일하다. 이는 레드-블랙 트리의 시간 복잡도와 같다.
- AVL 트리는 레드-블랙 트리보다 더 엄격하게 균형을 유지하기 때문에 일반적으로 레드-블랙 트리보다 탐색은 빠르지만 삽입과 제거는 느리다.
레드-블랙 트리(Red-Black Tree)
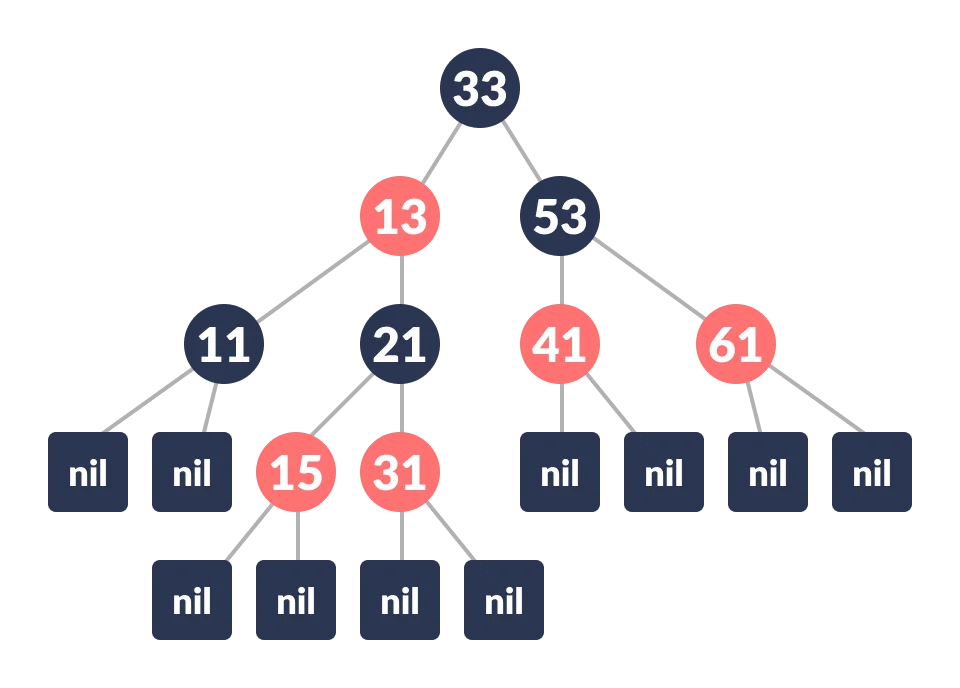
-
레드-블랙 트리는 자가 균형 이진 탐색 트리의 일종으로, 모든 노드를 레드 또는 블랙으로 표시하여 트리의 균형을 유지하기 때문에 레드-블랙 트리라고 부른다.
-
레드-블랙 트리의 공간 복잡도는 이며, 모든 상황에서 탐색, 삽입, 삭제의 시간 복잡도가 으로 동일하다.
-
레드-블랙 트리는 구현이 복잡하지만 매우 효율적인 알고리즘이기 때문에 다양하게 활용된다.
-
각종 프로그래밍 언어의 연관 배열 자료형(파이썬의 딕셔너리, C++의 map이나 set 등)들은 대부분 레드-블랙 트리 기반으로 구현되어 있다.
-
레드-블랙 트리는 2-3-4 트리와 매우 유사하며 등거리 변환(isometry)이 가능하다. 즉, 모든 2-3-4 트리에는 구성 원소와 그 순서가 같은 레드-블랙 트리가 최소한 하나 이상 존재한다는 뜻이다.
-
레드-블랙 트리는 다음과 같은 규칙을 이용하여 균형을 유지한다.
- 모든 노드는 레드 또는 블랙이다.
- 뿌리 노드와 잎 노드는 블랙이다.
- 레드 노드의 자식 노드는 레드일 수 없고, 모두 블랙이어야 한다. 블랙 노드는 레드와 블랙 모두 자식 노드로 가질 수 있다.
- 뿌리 노드와 모든 잎 노드 사이에 있는 블랙 노드의 수는 모두 동일하다.
-
레드-블랙 트리의 규칙을 지키기 위해서, 모든 잎 노드는 아무 데이터도 갖지 않으면서 블랙인 NIL 노드가 된다. 이러한 노드를 센티넬(sentinel) 노드라고 부른다.
-
NIL 노드는 구현의 편의를 위해 이용되는 노드이므로 보통 메모리를 할당하지 않는다.
-
레드-블랙 트리의 탐색 과정은 이진 탐색 트리의 탐색 방법과 동일하다.
-
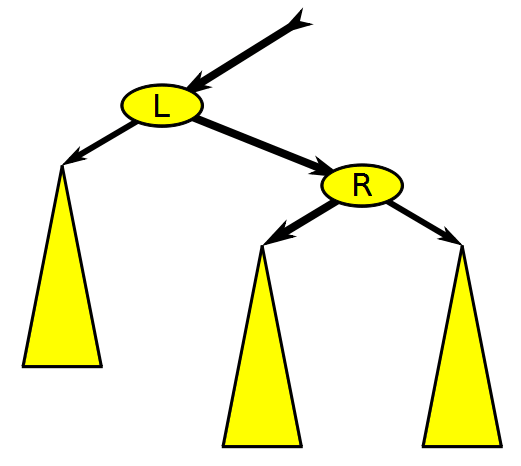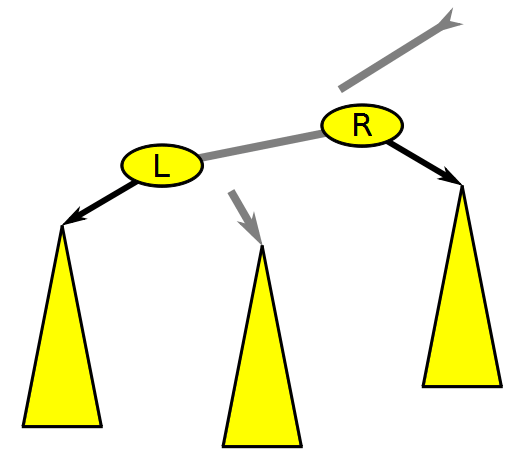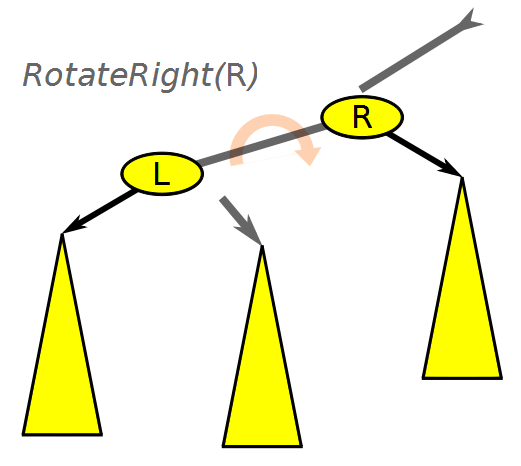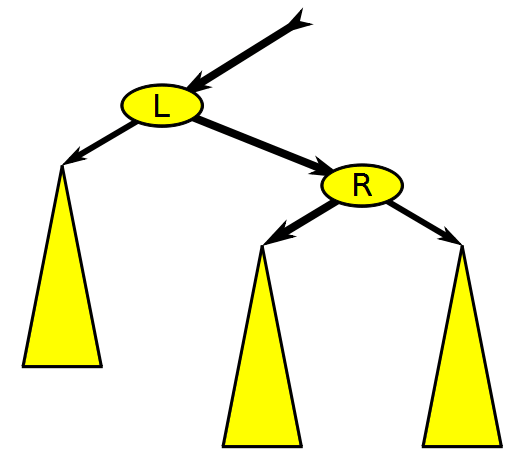
레드-블랙 트리에서 노드를 삽입하거나 삭제하면 균형이 깨질 수 있기 때문에 노드의 색을 바꾸거나 노드를 회전하는 과정이 필요하다. 회전은 방향에 따라 좌회전과 우회전으로 구분된다.
-
좌회전은 오른쪽 자식 노드의 왼쪽 자식 노드를 부모 노드의 오른쪽 자식으로 연결한다. 우회전은 그 반대로 왼쪽 자식 노드의 오른쪽 자식 노드를 부모 노드의 왼쪽 자식으로 연결한다.
-
레드-블랙 트리에 노드를 삽입하는 과정은 다음과 같다.
-
삽입할 노드를 초기화 한다. 노드의 색은 레드로 하고 양쪽 자식으로 NIL을 연결하면 된다.
-
레드-블랙 트리를 이진 탐색하여 삽입할 노드가 연결될 위치를 찾는다. 트리가 빈 상태라면 삽입할 노드는 루트 노드가 된다. 삽입할 노드의 부모 노드가 있다면 그 부모 노드의 NIL 노드를 떼어내고 그 자리에 연결한다.
-
삽입할 노드의 부모 노드가 블랙이면 규칙을 위반할 일이 없으므로 그대로 둔다.
-
삽입할 노드의 부모 노드가 레드이면, 삼촌 노드(부모 노드의 형제 노드)의 색에 따라 다른 과정을 거쳐야 한다.
a. 삼촌이 레드인 경우: 삽입할 노드의 부모 노드와 삼촌 노드를 모두 블랙으로 만들고 할아버지 노드를 레드로 만든다. 할아버지 노드가 3번 규칙을 위반하는 상태가 되면 할아버지 노드를 새로 삽입한 노드로 간주하고 다시 처음부터 세 가지 경우를 따져봐야 한다.b. 삼촌이 블랙이며 삽입할 노드가 부모 노드의 오른쪽 자식인 경우: 삽입할 노드의 부모 노드를 기준으로 좌회전 시킨다. 이렇게 하면 밑에서 설명한 c의 상황이 되므로 같은 방법으로 처리하면 된다.
c. 삼촌이 블랙이며 삽입할 노드가 부모 노드의 왼쪽 자식인 경우: 삽입할 노드의 부모 노드를 블랙으로 만들고 할아버지 노드를 레드로 만든 다음 할아버지 노드를 우회전 시킨다. 이렇게 하면 3번 규칙을 위반할 일이 없어진다.
-
위 과정의 결과로 뿌리 노드가 레드가 되면 연산의 마지막 단계에서 블랙으로 바꿔준다.
-
-
레드-블랙 트리에 노드를 삭제하려면, 삭제할 노드의 색에 따라 다른 과정을 거쳐야 한다.
-
삭제할 노드가 레드인 경우 규칙을 위반할 위험이 없으므로 기본적으로 이진 탐색 트리의 삭제 연산과 동일하며, 이 과정에서 노드의 색깔만 적절히 바꿔주면 된다.
-
삭제할 노드가 블랙인 경우 3, 4번 규칙을 위반할 위험이 생긴다. 규칙을 지키려면 삭제된 노드를 대체하는 노드(successor)를 블랙으로 바꿔야 한다. 대체할 노드가 레드였다면 더 이상의 문제가 없지만, 블랙이었다면 이 노드는 이중 흑색 노드가 되어 1번 규칙을 위반하게 되므로 이를 해결해야 한다.
-
이중 흑색 노드를 처리하는 방법은 이중 흑색 노드의 형제와 조카 노드들의 색에 따라 다음 네 가지 경우로 나뉜다.
-
형제가 레드인 경우: 형제는 블랙, 부모는 레드로 만들고, 부모를 기준으로 자식 노드를 좌회전시킨다. 그 후에는 2번의 a, b, c 중에서 일치하는 경우에 따라 처리하면 된다.
-
형제가 블랙인 경우는 다음의 세 가지로 나뉜다.
a. 형제의 양쪽 자식이 모두 블랙인 경우: 형제만 레드로 만들고 이중 흑색 노드가 갖고 있던 2개의 블랙 중 하나를 부모 노드에게 넘겨준다. 그 후에는 부모 노드를 기준으로 네 가지 경우 중 어떤 경우에 해당 되는 지를 따져서 그에 맞게 처리한다.b. 형제의 왼쪽 자식은 레드, 오른쪽 자식은 블랙인 경우: 형제는 레드로, 형제의 왼쪽 자식은 블랙으로 만든다. 그 후에 형제 노드를 기준으로 우회전한다. 이렇게 하면 c의 상황과 같아지므로 c의 처리 방법을 따르면 된다.
c. 형제의 오른쪽 자식이 레드인 경우: 이중 흑색 노드의 부모 노드가 갖고 있는 색을 형제 노드에 칠한다. 그 다음에 부모 노드와 형제 노드의 오른쪽 자식 노드를 블랙으로 만들고, 부모 노드를 기준으로 좌회전 한다. 마지막으로 이중 흑색 노드를 블랙으로 만든다.
- 레드-블랙 트리보다 구현이 더 쉽고 동일한 시간 복잡도를 가지는 좌편향(Left-leaning) 레드-블랙 트리라는 변형이 있다.
2-3-4 트리 (2-4 트리)
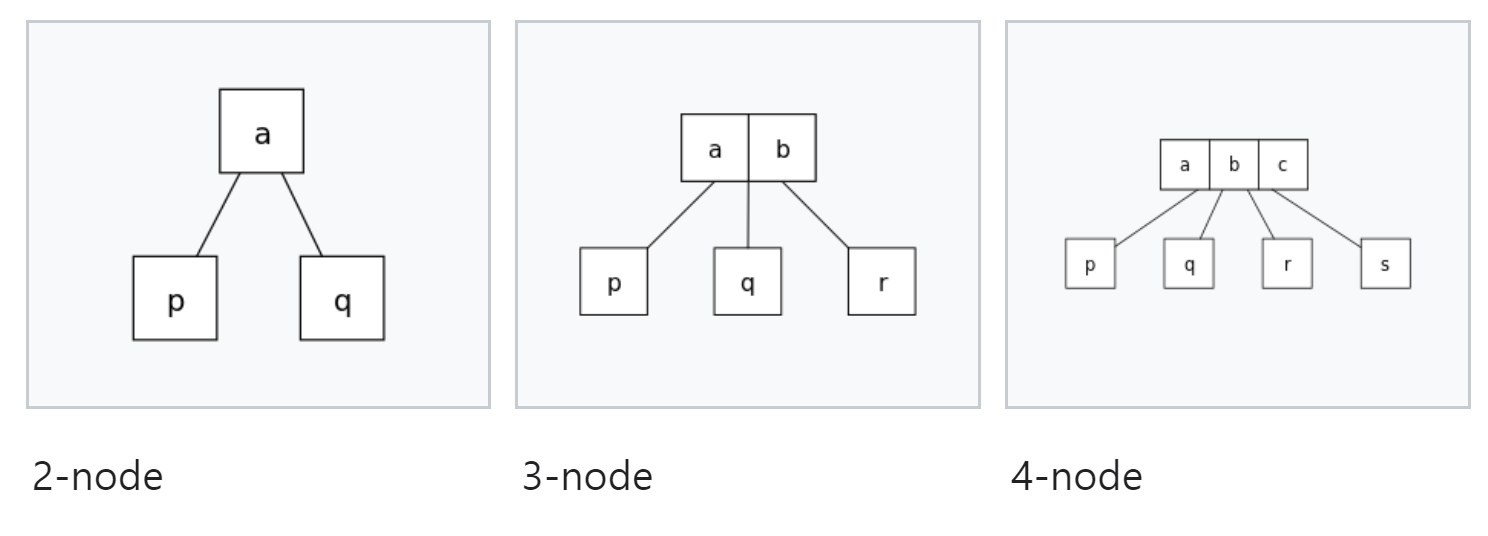
- 2-3-4 트리는 자가 균형 탐색 트리의 일종으로 2-4트리라고도 한다. 모든 노드가 2 또는 3 또는 4개의 자식 노드를 가지기 때문에 2-3-4 트리라고 부른다.
- 이 자료구조는 연관 배열(associative array, map, symbol table, dictionary)을 구현하기 위해 사용된다.
연관 배열은 (key, value) 쌍의 데이터를 나타내는 추상적 자료형이다. - 2-3-4 트리는 레드-블랙 트리와 동형(isomorphic)이지만, 보통 2-3-4 트리의 구현이 더 어렵기 때문에 레드-블랙 트리가 더 사용되고 있다.
- 2-3-4 트리의 시간 복잡도는 모든 연산에 대해 이며, 공간 복잡도는 이다.
- 2-3-4 트리의 특징은 다음과 같다.
- 2-3-4 트리의 모든 노드는 2-노드, 3-노드, 4-노드 중 하나가 된다.
2-노드는 1개의 키와 2개의 자식을 갖는다.
3-노드는 2개의 키와 3개의 자식을 갖는다.
4-노드는 3개의 키와 4개의 자식을 갖는다. - 각 노드의 한 키의 왼쪽 서브트리에 있는 모든 키값은 그 키값보다 작다.
각 노드의 한 키의 오른쪽 서브트리에 있는 모든 키값은 그 키값보다 크다. - 모든 잎 노드의 레벨은 동일하다.
- 2-3-4 트리의 모든 노드는 2-노드, 3-노드, 4-노드 중 하나가 된다.
- 2-3-4 트리에서의 탐색 연산은 이진 탐색 트리의 탐색 연산과 비슷하다.
- 2-3-4 트리에서의 삽입 연산은 이진 탐색 트리와 비슷하지만, 삽입할 노드를 찾는 탐색 과정에서 4-노드를 만나면 노드를 분할해야한다.
- 2-3-4 트리에서의 삭제 연산 역시 이진 탐색 트리와 비슷하지만, 삭제 후 2-3-4 트리의 성질을 만족하도록 노드의 구조를 조정해야한다.
- 2-3-4 트리는 자가 균형 트리이기 때문에 경사 트리가 되지 않는다는 장점이 있지만 노드의 구조가 복잡해질 수 있다는 단점이 있다.
- 2-3-4 트리를 이진 탐색 트리 같은 형태로 바꾸어 표현한 것이 바로 레드-블랙 트리이다.
- 레드-블랙 트리에서 레드 노드를 부모 노드와 묶어서 하나의 노드로 표현하면 2-3-4 트리가 된다.
B-트리(B-tree)
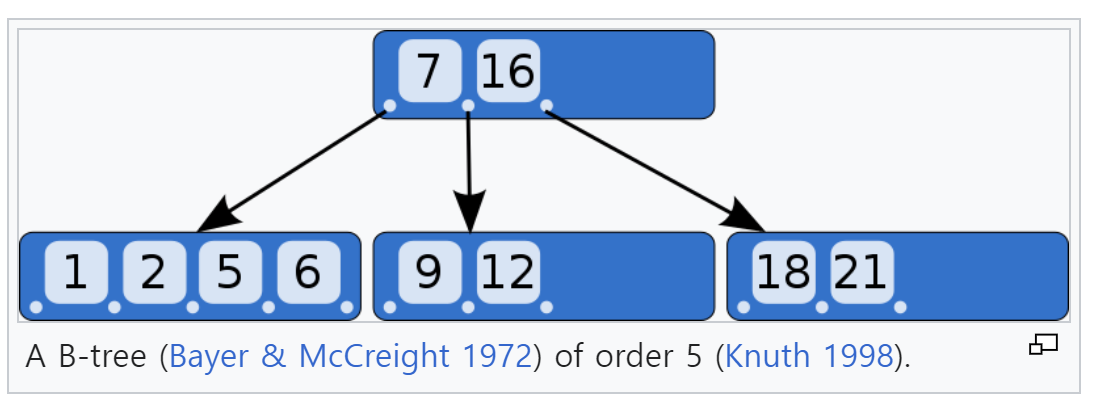
- B-트리는 정렬된 데이터를 유지하면서 검색, 조회, 삽입, 삭제 연산을 로그 시간 내에 할 수 있는 자가 균형 트리이다. B-트리는 데이터베이스, 파일 시스템 등의 다양한 분야에 활용된다.
- B-트리는 루돌프 바이어와 에드워드 멕크레이트에 의해 개발되었는데 두 사람 모두 B의 의미를 설명하지 않았다.
B는 Boeing, balanced, between, broad, bushy, Bayer 정도로 추측된다. - B-트리의 시간 복잡도는 모든 연산에 대해 이며, 공간 복잡도는 이다.
- B-트리의 특징은 다음과 같다. 여기서 는 자연수 상수이다.
- 루트 노드는 1개 이상 개 미만의 오름차순으로 정렬된 키를 갖는다.
- 루트 노드가 아닌 모든 노드는 개 이상 개 미만의 오름차순으로 정렬된 키를 갖는다.
- 내부 노드는 자신이 가진 키의 개수보다 하나 더 많은 자식을 갖는다.
- 각 노드의 한 키의 왼쪽 서브트리에 있는 모든 키값은 그 키값보다 작다.
각 노드의 한 키의 오른쪽 서브트리에 있는 모든 키값은 그 키값보다 크다. - 모든 잎 노드의 레벨은 동일하다.
- B-트리에서의 탐색 연산은 2-3-4 트리와 비슷하다.
- B-트리에서의 삽입 연산은 2-3-4 트리와 비슷하지만, 탐색 과정에서 키의 개수가 인 노드를 만나면 노드를 분할해야한다.
- B-트리에서의 삭제 연산은 2-3-4 트리와 비슷하지만 2-3-4 트리와 마찬가지로 삭제 후 B-트리의 성질을 만족하도록 조정하는 작업이 필요하다.
- 인 B-트리는 2-3-4 트리 또는 레드-블랙 트리와 거의 같다.
- B-트리의 변형으로는 B+트리, B*트리 등이 있다.
- B+트리는 비단말 노드는 데이터를 저장하지 않고 자식 노드에 대한 포인터만 가지며 잎 노드에만 데이터를 담는 B-트리이다. 또한 잎 노드는 다음 순서의 형제 노드에 대한 포인터를 가지도록 하여 일반적인 B-트리보다 탐색 성능이 좋다.
- B*트리는 노드의 약 2/3 이상이 차야 하는 B-트리이다. 또한 노드가 꽉 차면 분리하지 않고, 키와 포인터를 재배치하여 다른 형제 노드로 옮긴다. 일반적인 B-트리보다 삽입 연산 시 노드 분할이 더 적게 발생하며 탐색 성능이 더 빠르다.
- B*+트리는 B*트리와 B+트리의 특성을 절충한 트리이다.
- Bx 트리는 움직이는 객체(moving object)에 대한 효율적인 B+ 트리 기반 인덱스 구조를 갱신하는 데 사용되는 쿼리이다.
참고자료
- 이것이 자료구조+알고리즘이다
- 방송대 컴퓨터과학과 알고리즘 교재
- https://en.wikipedia.org/wiki/Search_algorithm
- https://en.wikipedia.org/wiki/Binary_search_algorithm
- https://en.wikipedia.org/wiki/Binary_search_tree
- https://en.wikipedia.org/wiki/AVL_tree
- https://en.wikipedia.org/wiki/Red-black_tree
- https://en.wikipedia.org/wiki/2%E2%80%933%E2%80%934_tree
- https://en.wikipedia.org/wiki/B-tree
