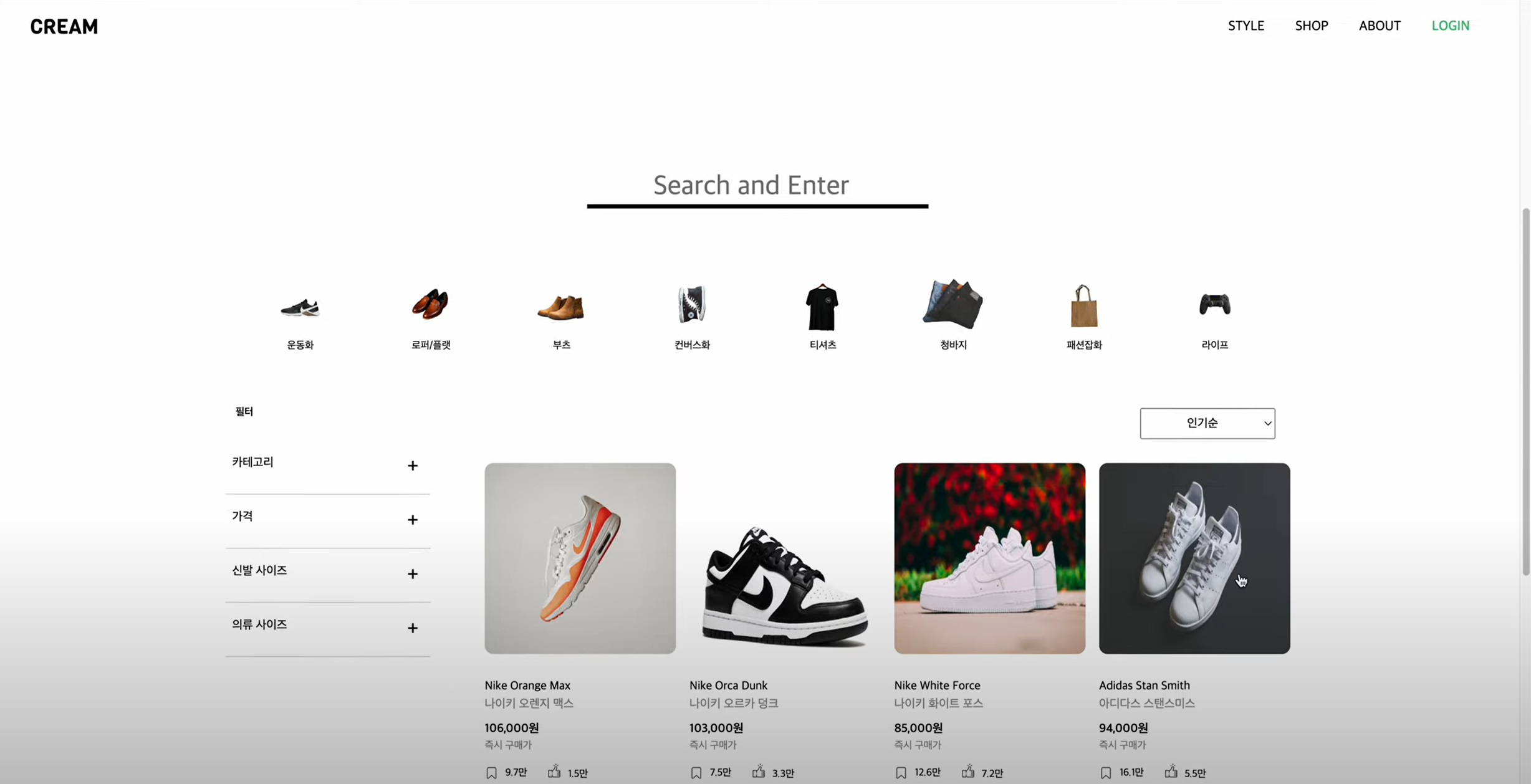
33기 2차 프로젝트 - CREAM
🚩개요
- 크림(Kream) 쇼핑몰 웹사이트 클론코딩 프로젝트 입니다.
- 클론코딩은 개발 환경 셋팅부터 시작하였으며, 하단 시연 영상은 모두 백엔드와의 데이터 연동을 통해 실제 서비스에서 이용되는 수준으로 구현하였습니다.
- 프로젝트는 11일동안 진행됨에 따라 디자인과 아래 서술한 기능들만 선택하여 구현했습니다.
- Nav Bar & Footer
- 소셜 로그인 & 회원가입
- 상품 페이지
- 상품 상세 및 리뷰
- 매매입찰
팀원
Frontend
- 이윤섭(PM), 김슬비, 유지후, 장수연
Backend
- 강세영
사용한 기술
Frontend
- React, Javascript, Styled-Component
Backend
- Python, Django Web Framework, MySQL
Cloud
- AWS EC2, RDS
Cowork
- Git, Slack, Trello, Notion, Postman Documenter
🎬시연 연상
Github 저장소 링크
백엔드 구현 기능
- 카카오 소셜 로그인, 회원가입, JWT 발급
- 제품 목록 데이터 조회
- 제품 목록 필터, 검색, 정렬
- 제품 상세 정보, 최근거래 그래프 데이터 조회
- 제품 구매/판매 입찰하기
- 제품 즉시구매/판매
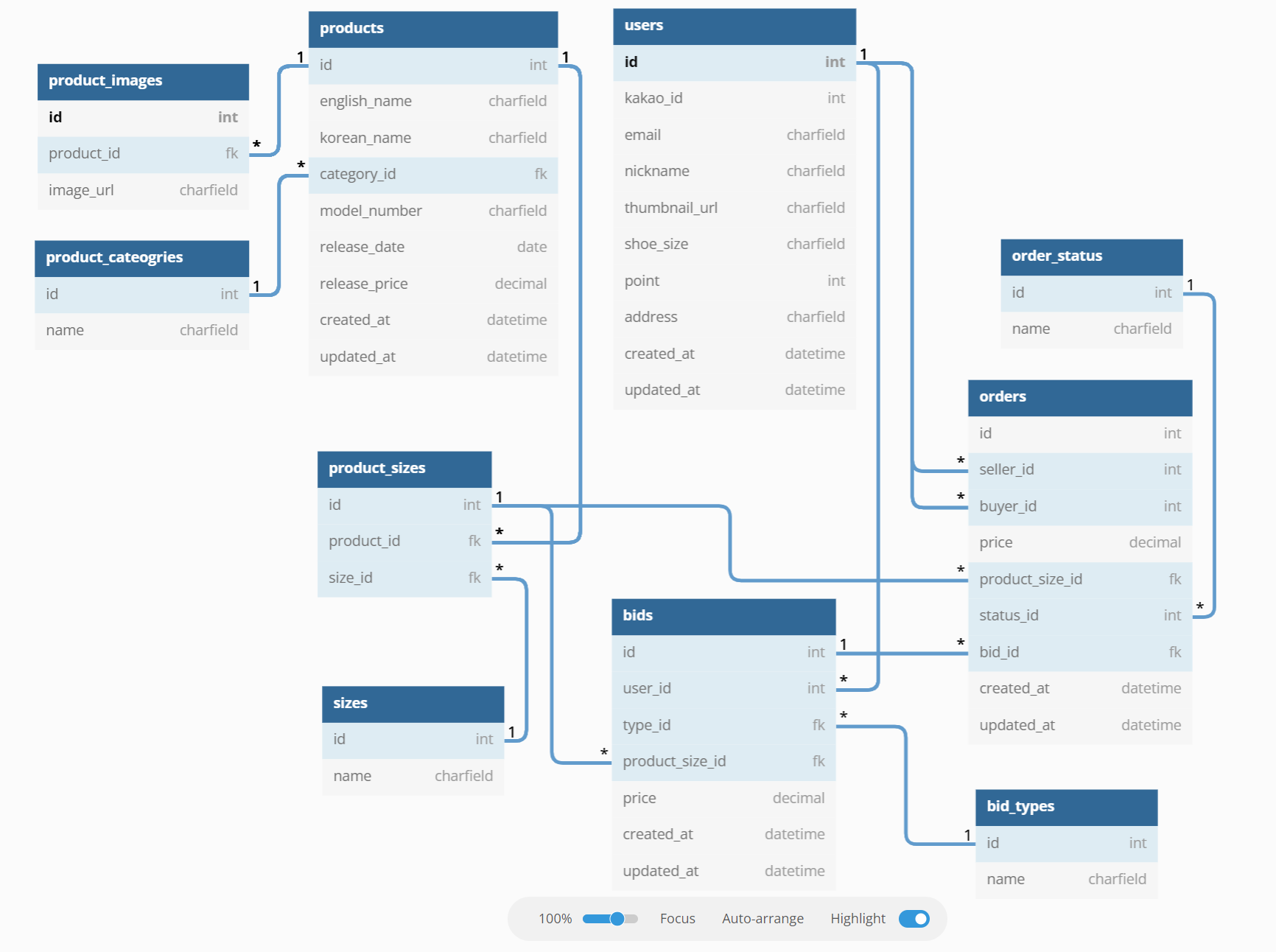
🧾데이터 ERD
KREAM 공식영상(쇼핑몰 이용방법 소개)
프로젝트 후기
초기세팅, 모델링
데이터 모델링은 1차 프로젝트 때의 경험과 다른 자료들을 참고하면서 목표 기능 구현만을 위한 단순화와 정규화를 적용했고 멘토님의 리뷰를 거쳐 초안에 약간의 수정만 하여 완료했다. 초반 기획안이 명확했고 모델링을 나름 세심하게 해놓으니 나중에 수정할 일도 없었고 따라서 Django에서 다시 마이그레이션을 할 일도 없었기 때문에 다음 단계를 빨리 진행할 수 있었다.
하지만 Django 초기 세팅했을 때 입찰기능 관련 파일들을 따로 bids 앱 폴더를 만들어서 관리하지 않고, orders 앱에 넣어 관리한게 잘못됐다는 것을 뒤늦게 깨달았다. DB 마이그레이션 오류가 날 것 같아서 프로젝트 기간 내에 수정하진 못했고 나중에 DB 덤프 파일들을 만들어 놓고 수정했다.
카카오 소셜 로그인, 회원가입
카카오 로그인 기능은 2차 프로젝트 시작하기 전 주말에 혼자 카카오에서 제공하는 공식문서를 참고하며 연습을 해봤다. 거기에 선배 분들이 만든 코드들을 참고하여 미리 완성했다. 나중에 대폭 수정되긴 했지만 프로젝트 기간 시작 전에 먼저 해봤다는게 많은 도움이 됐다.
처음에는 슬비님이 만든 페이지에서 카카오 로그인창을 띄워서 로그인 후 인가코드를 받고 액세스 토큰까지 처리하고 그걸 백엔드 쪽으로 넘기는 방식으로 구현했지만 멘토님 리뷰를 받고 액세스 토큰 받는 것부터는 백엔드가 처리하는 방식으로 바꿨다.
처음에 내가 만든 건 한 View 클래스에 모든 코드를 넣어서 구현하는 방식이었지만 코드 리뷰 때 멘토님이 모듈화가 된 코드가 좋은 코드라고 하셔서 다른 기능구현보다 모듈화를 최우선순위로 해보기로 했다.
파이썬으로 클래스를 새로 만들고 활용해본 경험이 적어서 처음엔 조금 막막했지만 로그인 과정을 단계별로 나눠 생각해보니 실마리가 보였다. 로그인을 위한 uri등의 데이터가 많이 필요했기 때문에 클래스를 만들고 def __init__(self):에 카카오에서 정해둔 데이터들을 넣어줬다. 액세스 토큰을 받는 등, 변수들을 활용해야 하는 기능들은 로그인 단계별로 나눠서 클래스 안에 메서드를 만들어 활용하는 방식으로 리팩토링 했다.
이 과정에서 객체지향 개념 등 많은 것을 배운 것 같다. 파이썬은 private 변수를 만들 수 없지만 변수명 앞에 _을 붙이면 프라이빗한 변수로 본다는 컨벤션에 대해서도 알게 됐다.
또한 카카오 로그인 처리의 마지막 부분에서 회원정보가 DB에 없으면 회원가입 시키고 JWT를 발급하거나 DB에 있으면 바로 JWT를 발급하는 분기처리를 위해 장고의 get_or_create 기능을 활용했다. 이를 통해 처음에 쓴 것보다 코드를 줄이고 race condition 이라는 개념에 대해서도 배울 수 있어서 좋았다.
지금 당장 누군가 나에게 카카오 로그인 과정을 완전히 설명해보라고 하면 솔직히 자신이 없다. 오늘부터라도 다시 카카오 공식문서를 보고 Oauth 2.0에 대해 공부해야겠다. 구글, 네이버, 페이스북 등 다른 소셜 로그인 기능에 대해서도 연습해봐야 겠다.
제품 목록 데이터 조회 (필터, 검색, 정렬)
1차 프로젝트 때도 쇼핑몰을 해봤고 2차도 마찬가지라 제품목록이나 데이터 페이지의 구성이 비슷하여 크게 어려운 점은 없었다. 다만 일반적인 제품 가격을 표출하는 쇼핑몰이 아니라 입찰데이터를 통해서 모든 제품의 사이즈별 판매입찰 최저가와 구매입찰 최고가를 조회하는 로직 구현이 약간 까다로웠다.
KREAM을 이용해본 경험도 없어서 처음에는 가격조회의 로직을 어떻게 만들어야 하나 막막했지만, 다행히도 나무위키에서 보게된 공식 유튜브 영상에 KREAM의 거래 방식이 너무 잘 설명되어 있어서 많이 참고했다.
가격 외의 데이터는 대부분 products 테이블에서 조회하기 때문에 가능하면 다른 테이블에 접근하지 않고 products 테이블 객체만으로 필요한 모든 데이터를 조회하고 싶었다. 이런 경우 products에서 product_sizes와 bids 테이블을 거쳐야만 가격 데이터를 알 수 있었기 때문에 Django shell에서 여러번 쿼리셋 코드를 쳐보면서 데이터가 제대로 출력되는지 확인하고 진행했다. 이 때가 프로젝트 기간 중 가장 힘들면서도 재밌었던 순간이었던 것 같다.
즉시구매, 판매가 조회와 정렬을 위해서 annotate와 order_by의 변수값을 맞추는 방법을 활용했는데, 1차 때도 같은 방식으로 만들었지만 깔끔한 코드를 작성하진 못했다. annotate가 유용하지만 한번에 여러 개의 컬럼을 참조하거나 Min, Max, Count 등의 서로 다른 집계함수를 사용할 경우 잘못된 데이터를 산출할 수 있다는 문제점이 있다. 그러나 많은 구글링 끝에 이 문제를 해결하는 방법을 찾아냈다. 나중에 알고보니 공식문서에 이미 나와있는 내용이었다.
Django 공식문서 filtering-on-annotations
products = Product.objects \
.annotate(
buy_price = Min("productsize__bids__price", filter=Q(productsize__bids__type_id=BidTypeEnum.SELL.value)),
sell_price = Max("productsize__bids__price", filter=Q(productsize__bids__type_id=BidTypeEnum.BUY.value)),
premium = F('buy_price') - F('release_price'),
sales_count = Count('productsize__orders', distinct=True)
) \
.filter(q).prefetch_related('images', 'productsize_set__bids') \
.order_by(sort)[offset:offset+limit]다음과 같이 Min, Max의 괄호 안에 필터옵션으로 Q객체를 넣고, Count 괄호안에는 dictinct=True 옵션을 넣는 방법으로 1차 때보다 가독성까지 좋게 만들어 만족스러웠다.
제품리스트에서 보여지는 구매가(buy_price)는 해당 제품의 판매입찰가 중 최저가를 보여줘야 하고 판매가(sell_price)는 반대로 구매입찰가 중 최고가를 보여줘야 하기 때문에 이러한 필터 옵션을 사용했다. 또한 필터값을 단순히 productsize__bids__type_id=1 같이 하드코딩하면 나만 알아볼 수 있는 코드가 되므로 가독성을 위해 미리 만들어놓은 BidTypeEnum을 활용했다.
제품리스트 필터링은 사이즈나 카테고리 체크박스의 다중선택을 고려하여 쿼리파라미터 값들을 리스트로 바꿔주는 request.GET.getlist와 리스트 안에 요소가 있는지 판단하기 위해 __in을 활용했다. 멘토님 리뷰를 받아보니 category__name__in으로 문자열 값을 이용하여 필터링하는 것보단 가능하면 category_id 같이 id값으로 필터링을 하는게 좋다는 것을 알게 됐다. 실제로 응답시간을 로깅해서 확인해보니 id값 필터링이 빨랐다.
카테고리는 종류가 적어서 프론트엔드 단에서 하드코딩하는 방식으로 수정했지만 사이즈 필터링은 개수가 많아 수정하지 못했다. id값 기준으로 필터링하기 위해서는 카테고리, 필터 관련 데이터를 조회하는 엔드포인트를 따로 만들고 프론트엔드에선 그 엔드포인트를 통해 id값 데이터를 받아서 필터바를 구성하는 방법이 가능할 듯 하다.
제품 검색 기능은 기존에 했던대로 Django의 contains, icontains를 쓰긴 했지만 이 방법은 데이터가 많아지면 검색 성능이 좋지 못하다는 단점이 있다. Django와 postgreSQL을 쓸 경우에만 활용할 수 있는 search 기능과, MySQL 등의 다른 DBMS를 사용할 경우에 DB쪽에서 full text search 기능을 활성화 하는 방법 등으로 검색성능 향상이 가능하다고 한다. 이 부분은 나중에 공부해서 꼭 적용해볼 예정이다.
아쉬웠던 점으로는 입찰가 중 최저가와 최고가 조회같이 반복적으로 활용되는 부분을 함수로 모듈화 할 수 있을 것 같았는데 나의 시간, 실력, 지식 등의 부족으로 적절한 리팩토링을 하지는 못했다. 이 부분은 나중에 공부해서 꼭 보완하고 싶다.
입찰, 즉시주문 기능
입찰과 즉시주문 기능은 프론트엔드와 연동하여 실제로 작동하는게 아니고, 프로젝트 후반에 백엔드 쪽에서만 구현한 정도로 해본 수준이라 잘 만들지는 못했다. 입찰과 주문 모두 모두 가격 조회 및 처리에 비슷한 코드가 많아 리팩토링이나 가독성 향상을 시도해볼 수 있을 것 같다. 하지만 즉시주문 기능의 비즈니스 로직에 대해 생각해보면서 구현해본 경험은 좋았다. 즉시주문시 DB에 주문기록이 저장되는 부분에서는 Django의 transaction.atomic() 메서드를 활용했다.
AWS 배포
위코드에서 제공한 AWS 배포 동영상을 그대로 따라하면서 EC2와 RDS로 배포 작업을 완료했다. 영상이 2년 전 내용이라 현재의 AWS 페이지와 약간 다른게 있었지만 큰 문제는 없었고 EC2가 아무것도 없는 상태의 리눅스 서버라서 필요한 패키지들을 초기 세팅 하듯이 설치해줘야 한다는 것 빼고는 그리 어려운 것은 없었다.
프로젝트 중반부터 배포 작업을 완료했기 때문에 프론트엔드 분들과 통신을 하기 위해 불편한 점(포트포워딩 ip주소 변경, 와이파이 네트워크 맞추기 등)이 많이 해소됐다. 앞으로 다른 프로젝트를 할때도 초반에 클라우드에 DB 세팅부터 해놓으면 무척 편리할 것 같다.
프로젝트에서 S3가 필요한 기능이 없어서 활용해보지 못했고 Docker는 시간이 부족하여 써보지 못했는데 이 부분은 나중에 따로 공부해야 겠다.
소통
위코드에서 프로젝트를 진행하면서 개발이라는 과정은 개발자들간의 소통이 정말 중요하다는 것을 깨달았다. 1차 때 나에게 가장 부족했던 것이기도 해서 초반부터 활발하게 소통하려 노력했다. 프로젝트 초반부터 프론트엔드 팀원 분들과 mock data 완성하는 시점부터 key, value를 맞추자고 합의했는데 중간에 약간 해맨 적도 있었지만 대체로 잘 됐다. 협업 관련 Tool도 1차 때의 경험을 살려서 트렐로, 슬랙, 노션, 포스트맨 등을 잘 활용했다.
팀원분들이 모두 너무 좋은 분들이고 서로 배려하고 편안하게 해주셔서 비록 혼자 백엔드를 맡았지만 큰 부담감 없이 잘 마무리했다.
🙋♀️기업협업🙋♂️
2차 프로젝트를 끝으로 우리 33기 수강생들은 앞으로 한달 동안 각자 기업으로 뿔뿔이 흩어지게 됐다. 이제부터는 함께하지 못하는게 정말 아쉽지만 기업협업 가서도 많이 배우고 수료 후에 각자 목표로 한 것을 다 이루셨으면 좋겠다.
