자료구조(Data Structure)
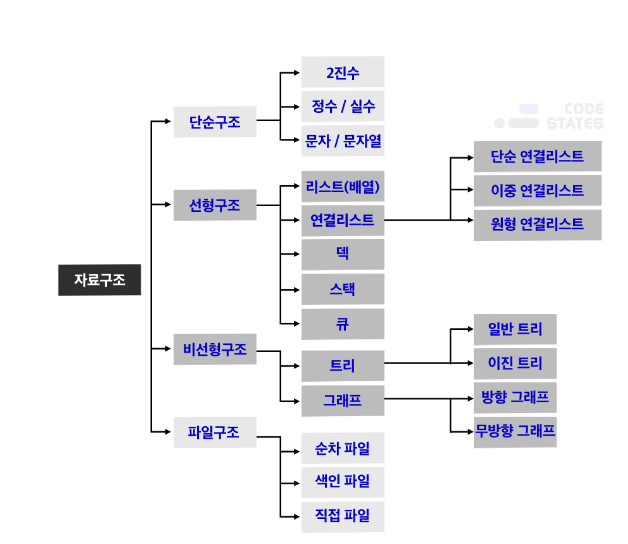
자료 구조는 여러 데이터들을 사용하기 위한 수단이며, 시간과 공간적 효율성을 위해 고안된 여러 구조들이다.
아래는 자료구조/알고리즘의 공부에 앞으로 나올 개념
-
ADT(Abstarct Data Type)
ADT는 추상화된 자료의 형태이며, 이는 어떤 자료구조의 아이디어라고 생각한다. -
Pseudocode
슈도코드는 추상화된 형태를 인간의 언어의 가깝게 묘사하는 것이며 이는 컴퓨터에게 명령을 하는 언어가 아닌, 사람들에게 설명을 하기 위해 간단하게 작성한 의사코드이다.
예시)
-
Big-O Notation
우리가 자료구조/알고리즘을 공부하면서 추구해야할 중요한 가치중 하나는 효율성이다.
그렇다면 우리가 설계한 자료구조, 알고리즘이 얼마나 효율적인지를 어떻게 확인할 수 있는가?
수학적 표기법인 빅-오 노테이션을 많이 사용한다.
이것은 입력값 N에 따라 최악의 수행시간이 얼마나 걸리는지를 표현한다.
예를 들어,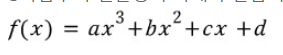
입력 값 x에 관한 3차 함수가 있다고 가정하면,
x = 1이면 x가 세제곱이던 제곱이던 함수값에 영향을 미치는 정도는 비슷하다.
하지만 x = 100000이라는 값을 가진다면, 세제곱과 제곱의 차이는 더욱 커진다.
이는 함수값의 증가율에 x가 커질 수록 최고차항의 영향이 커진다는 의미이다.
본론으로 돌아와서, 우리는 빅-오 노테이션을 사용할 때 최악의 수행시간을 분석하며 수행시간 증가율에서 가장 영향력이 높은 최고차항만을 사용하여 표현하며 최악의 수행시간을 가정한다.
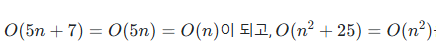
더욱 더 직관적인 예시는
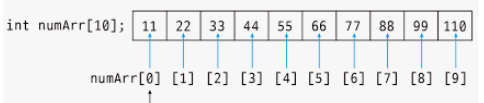
이러한 배열에서 특정값을 찾는 알고리즘을 구현하려 한다.
가장 간단한 아이디어는 앞에서 부터 하나씩 비교해보는 것이다.
최악의 경우 110을 찾는 경우이며 이는 10번 비교하게 된다.
그렇다면 배열의 크기가 10이 아닌 N이라고 가정한다면,
최악의 수행시간을 O(N)이라고 표현하는 것이다.
이러한 정사각형 모양의 2차원 배열에서는 한변의 길이가 N이라면
최악의 수행시간은 O(N^2)이 될 것이다.
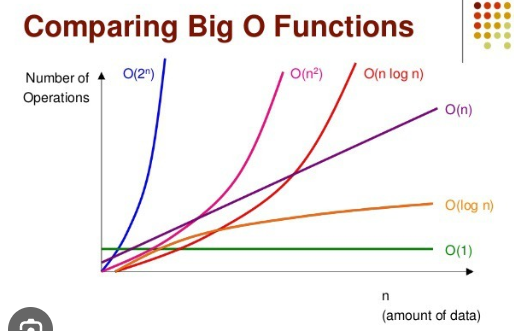
위는 시간복잡도에 따른 증가율을 나타낸 그래프이며
O(1)<O(log n)<O(n)<O(nlog n)<O(n^2)<O(2^n)
순서로 왼쪽부터 효율적이라는 의미이다.
O(1)은 상수시간안에 해결할 수 있다는 의미이며
N의 값에 관계 없이, 특정 시간 안에 해결할 수 있음을 나타낸다.
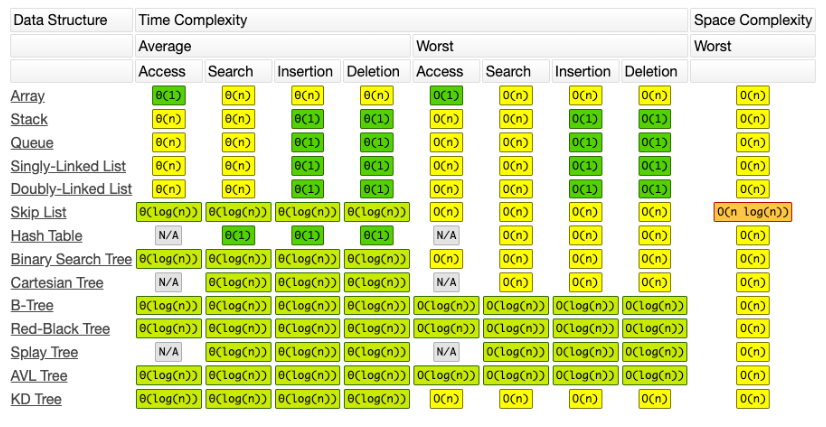
자료구조를 공부하는 것은, 아이디어를 공부하는 것이고 사람에 따라 구현 방식에 차이가 있다.
대부분 누군가가 구현한 가장 효율적인 것을 사용하기 위해 STL(Standard Template Library)를 사용한다.
