프로젝트 코드베이스를 AI가 잘 이해하도록 도와줌
- 지식 A랑 B랑 모순되는 게 있는지
- A의 근거가 된 다른 지식을 찾기
- A에서 B로 가는 추론 경로가 뭔지
1. 지식 그래프란?
노드(점) + 엣지(선) 로 이루어진 자료 구조다.
[PlayerComponent] --calls--> [EbSkillService]
[SemiBossRoom] --inherits--> [StageEntity]
[보스 봉인 디자인 문서] --references--> [DebuffAriellaBlessingSeal.cs]목적: 코드/문서/이미지 사이의 연결 관계를 한눈에 보고 검색하기 위해.
2. graphify 파이프라인 7단계
https://github.com/safishamsi/graphify
https://youtu.be/Ma8e25AOtao?si=-e3y8Dd1SAzibYAV
[1] Detect (감지)
↓
[2] AST 추출 (코드 → 구조 그래프, 공짜)
↓
[3] Semantic 추출 (코드/문서/이미지 → 의미 그래프, LLM 비용)
↓
[4] Merge (AST + Semantic 합치기)
↓
[5] Build & Cluster (그래프 빌드 + 커뮤니티 묶기)
↓
[6] Label (커뮤니티 이름 붙이기)
↓
[7] Export (HTML/JSON/리포트 출력)3. 각 단계 상세
Step 1. Detect (감지)
폴더 훑어서 파일 종류별로 분류한다.
EB 프로젝트의 경우:
- code: 1,638개 (.cs C# 파일)
- document: 11개 (.md 문서)
- paper: 1개 (.pdf)
- image: 0개
- video: 0개목적: 어느 파일에 어느 추출기를 돌릴지 결정.
Step 2. AST 추출 (Abstract Syntax Tree)
핵심 개념: 코드를 컴파일러처럼 파싱해서 구조를 뽑는다.
AST가 뭐냐?
C# 컴파일러는 너의 코드를 텍스트로 안 본다. 트리(Tree) 자료구조로 본다.
예시 코드:
public class SemiBossRoom : StageEntity
{
public void Init() {
SpawnSemiBoss();
}
}AST로 보면:
ClassDecl: SemiBossRoom
├── BaseType: StageEntity ← inherits 엣지
├── MethodDecl: Init
│ └── MethodCall: SpawnSemiBoss ← calls 엣지왜 공짜냐?
- LLM 안 씀. Tree-sitter 라는 파서 라이브러리가 코드를 규칙 기반으로 분석.
- 결정론적 (같은 입력 → 같은 출력)
- 빠름 (1,638개 C# 파일 → 몇 초)
프로젝트 결과
AST: 17,010 노드, 45,309 엣지이게 잡아내는 것:
- 노드: 클래스, 메서드, 필드 (예:
SemiBossRoom.cs,.Init(),.SpawnSemiBoss()) - 엣지:
inherits(상속):SemiBossRoom → StageEntitycalls(호출):Init() → SpawnSemiBoss()references(참조):SemiBossRoom → EbMonsterSheet.Referenceimports(using):SemiBossRoom → UnityEngine
AST가 못 잡는 것
- 의미적 연관 (이 두 함수는 사실 같은 문제를 푼다)
- 디자인 의도 (왜 이렇게 짰는지)
- 문서·이미지에 있는 정보
→ 이건 다음 단계가 처리.
Step 3. Semantic 추출 (의미 추출)
핵심 개념: LLM(나 같은 모델)이 파일을 읽고 의미적인 연결을 뽑는다.
왜 LLM이 필요하냐?
AST가 못 잡는 거 예시:
// File A
public void ValidateUserInput(string s) { ... }
// File B (다른 클래스)
public bool CheckInputSafety(string input) { ... }AST 입장: 두 함수는 호출 관계도 없고, 같은 클래스도 아니고, 상속도 없다. → 엣지 없음.
LLM 입장: 둘 다 "사용자 입력 검증" 한다. → semantically_similar_to 엣지를 INFERRED로 추가.
추출 카테고리
1. EXTRACTED — 명시적 (소스에 직접 적혀있음)
예: import 문, 인용 ([1] 참조)
confidence_score: 1.0
2. INFERRED — 추론 (모델이 판단)
예: 같은 데이터 구조를 공유하는 함수들
confidence_score: 0.6~0.9
3. AMBIGUOUS — 모호 (확신 없지만 표시)
예: 손글씨 메모 해독
confidence_score: 0.1~0.3이게 "honest audit trail"이라는 graphify의 자랑. 환각이 아니라 확실성을 표시해서 검증 가능하게 함.
프로젝트는 어떻게 처리됐나?
비코드 12개 파일만 LLM에 넘겼다:
gemini.md,README.mddocs/superpowers/plans/*.md(4개 작업 계획)docs/superpowers/specs/*.md(3개 디자인 스펙)reiconed.pdf,steam_appid.txt,lib_burst_generated.txt
왜 코드는 LLM에 안 넘겼나?
- 1,638개 × LLM 호출 = 비용 폭발 (~75 에이전트, 수 분, 수백만 토큰)
- AST가 이미 17k 노드 잡아냄 → 80% 가치는 이미 확보
- 첫 패스는 비코드만, 나중에
--mode deep로 코드도 돌리면 됨
하이퍼엣지 (Hyperedge)란?
일반 엣지는 노드 2개 연결. 하이퍼엣지는 3개 이상 노드를 한 그룹으로 묶는다.
예시:
"인증 플로우"라는 하이퍼엣지:
- LoginButton.cs
- AuthService.cs
- SessionStore.cs
- TokenValidator.cs이 4개는 서로 다 호출 안 해도, 같은 인증 플로우의 일부. 하이퍼엣지가 그걸 표현.
Step 4. Merge
AST 결과 + Semantic 결과 합치기. 같은 노드 ID면 중복 제거.
AST: 17,010 노드 + 45,309 엣지
Semantic: 52 노드 + 56 엣지
─────────────────────────────────
Merge: 17,062 노드 + 45,365 엣지Step 5. Build & Cluster
Build
merge된 데이터를 networkx (파이썬 그래프 라이브러리) 그래프 객체로 만든다. 이때 잘못된 엣지(존재 안 하는 노드 가리키는 거)는 자동 정리되어 노드 수 약간 줄어듦 (17,062 → 15,505).
Cluster (커뮤니티 검출)
Louvain 알고리즘으로 노드를 그룹으로 묶는다.
원리: 연결이 빽빽한 노드끼리 같은 커뮤니티로.
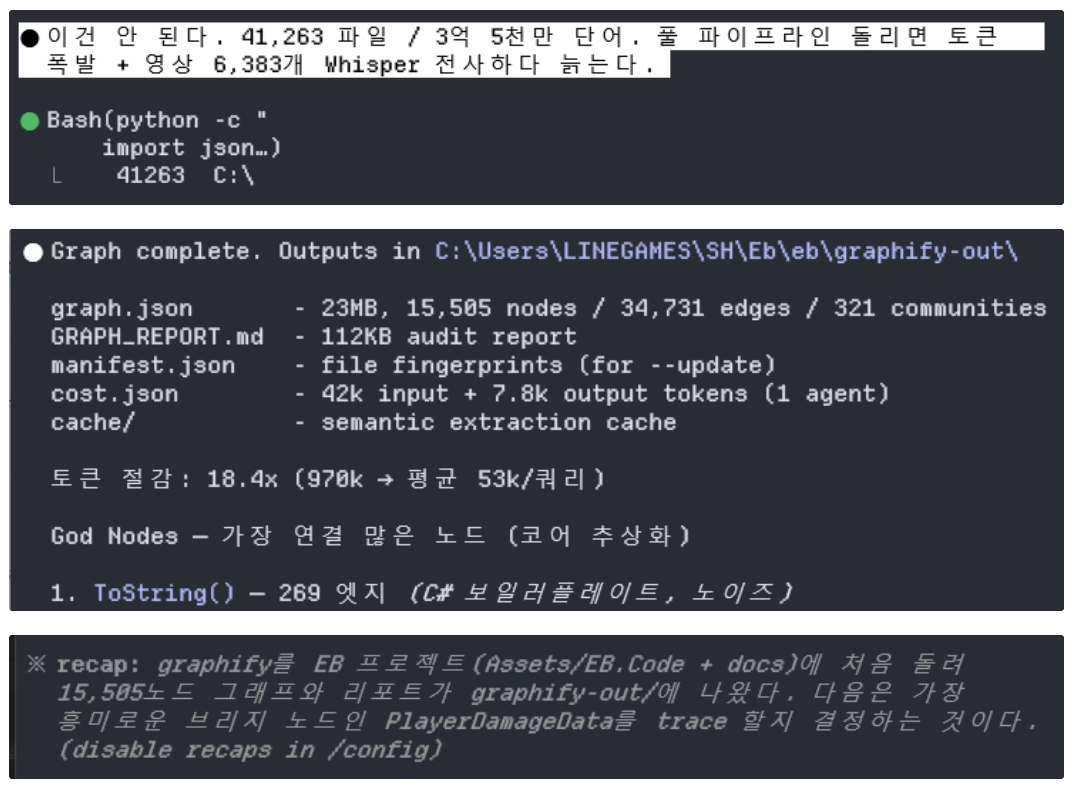
결과: 321개 커뮤니티 (대부분 작은 거)
- C0: 1,722 노드 (Skill Controller Core)
- C1: 1,698 노드 (Combat Damage System)
- C2: 1,284 노드 (Arcana Skill Variants)
...
- C320: 1 노드 (외톨이 노드)왜 클러스터링하냐? 1만 5천 노드 한꺼번에 보면 머리 깨진다. 커뮤니티 단위로 보면 시스템 구조가 드러난다.
Cohesion Score (응집도)
각 커뮤니티가 얼마나 빽빽하게 연결됐는지 점수. 0.0이면 "사실 한 묶음이 아닌데 강제로 묶임" → 분리 권장.
Skill Controller Core는 cohesion=0.0 → 너무 많은 걸 한 클래스로 모았다는 신호. 리포트가 "분리해라" 제안.
God Nodes (신 노드)
연결이 비정상적으로 많은 노드. 너의 코어 추상화 또는 스파게티 신호.
1. ToString() — 269 엣지 ← C# 보일러플레이트, 노이즈
2. Create() — 176 ← 팩토리 패턴
3. LuaBlessingApi — 71 ← 진짜 허브 (Lua API 코어)
4. ConsoleCommandRegistry — 51 ← 치트 콘솔 진입점Surprising Connections (의외의 연결)
다른 커뮤니티 사이의 INFERRED 엣지. 디자이너 의도 못 한 결합 또는 발견.
예: Ember and Blade Project --references--> Steam AppID 480 ← 이게 발견 가치.
Step 6. Label (커뮤니티 이름 붙이기)
Step 5 결과 그대로면 Community 0, Community 1 … 이라 무의미. 나(LLM)가 노드 라벨 보고 사람 말로 이름 짓는다.
C0의 노드들: (예) ActorFlag.cs, ...
→ 라벨: "Skill Controller Core"
C19의 노드들: (예) MobAI.cs ...
→ 라벨: "Monster AI"상위 40개만 라벨링하고 나머지 281개는 일반 이름. (큰 게 의미 있어서.)
Step 7. Export
세 가지 산출물:
-
graph.html— 인터랙티브 그래프 (브라우저에서 노드 클릭/드래그)- EB는 15k 노드라 너무 커서 자동 스킵.
--svg나--obsidian으로 대체 가능.
- EB는 15k 노드라 너무 커서 자동 스킵.
-
graph.json— 구조화된 raw 데이터 (다른 도구로 불러오기 위해)- 23MB
-
GRAPH_REPORT.md— 사람이 읽는 리포트- God nodes, surprises, 추천 질문, cohesion 점수 등
추가로 cost.json (토큰 비용 누적), manifest.json (--update용 파일 지문).
4. 토큰 절감 벤치마크
원본 코퍼스: 727,599 단어 → ~970,132 토큰
질문 1개당 평균: ~52,816 토큰
절감율: 18.4x무슨 뜻이냐?
- 옛날 방식: 너가 "PlayerDamageData가 어디서 쓰여?" 물으면 → 전체 코퍼스(97만 토큰) LLM에 다 넣어야 답함
- graphify 방식: 그래프에서 BFS/DFS로 관련 5만 토큰만 추려서 LLM에 넣음 → 정답은 같은데 비용 1/18
이게 "GraphRAG" 패턴. RAG (Retrieval-Augmented Generation)인데 retrieval을 그래프로 함.
5. 너가 쓸 수 있는 명령
/graphify . # 풀 빌드
/graphify . --update # 변경된 파일만 재추출 (싸다)
/graphify . --mode deep # 코드도 LLM 세만틱 돌림 (비싸다)
/graphify query "PlayerDamageData가 어디 쓰여?" # BFS 검색
/graphify query "..." --dfs # DFS (특정 경로 추적)
/graphify path "AuthModule" "Database" # 두 노드 사이 최단 경로
/graphify explain "SemiBossRoom" # 노드 1개 상세 설명6. 왜 굳이 이런 짓을 하나?
문제: AI 코딩 어시스턴트(나)는 매번 코드를 새로 읽음. 1,638개 .cs 파일 매번 grep · read · trace = 시간/토큰 낭비.
해결: 그래프를 한 번 만들어놓고, 다음부터는 그래프 쿼리해서 필요한 부분만 파악. 같은 질문 100번 해도 매번 다시 읽을 필요 없음.
부수 효과:
- 새로 합류한 팀원이 코드베이스 구조 한눈에 파악
- 의외의 결합(Spacewar AppID 같은 거) 자동 감지
- 죽은 코드, 외톨이 모듈 식별
7. 한 줄 요약
AST = 빠르고 공짜로 코드 구조 추출. Semantic = LLM이 의미 연결 추출. 그 다음 클러스터링해서 사람이 읽을 수 있는 지도로 바꾼다. 그래프는 영구 저장되어 다음 질문은 빠르고 싸게 답할 수 있다.
