문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
생각해보기
그리디?
어떤식으로 실행하던 모든 작업을 끝내는 데 걸리는 시간을 똑같다.
다음과 같이 룰을 정하면 목적을 달성할 수 있을 것이다.
- 현재 처리 중인 작업이 없으면, 먼저 요청받은 작업을 처리한다.
- 현재 처리 중인 작업이 끝나기 전에 들어온 요청들에 대해 소요 시간이 짧은 요청을 먼저 처리한다.
구현은,
- 일단 구현
- 성능 올기기
순서로 진행한다.
구현
import java.util.*;
import java.util.stream.*;
class Solution {
public int solution(int[][] jobs) {
List<int[]> list = Arrays.stream(jobs)
.sorted((o1, o2) -> o1[0] == o2[0] ? o1[1] - o2[1] : o1[0] - o2[0])
.collect(Collectors.toCollection(LinkedList::new));
int sum = 0;
int offset = 0;
while(!list.isEmpty()) {
int[] next = next(list, offset);
int s = Math.max(next[0], offset);
int e = offset = s + next[1];
sum += e - next[0];
}
return sum / jobs.length;
}
private int[] next(List<int[]> jobs, int offset) {
int[] result = jobs.stream()
.filter(j -> j[0] <= offset)
.sorted((o1, o2) -> o1[1] - o2[1])
.findFirst()
.orElse(jobs.get(0));
jobs.remove(result);
return result;
}
}먼저, 요청 시간이 빠르며 요청 시간이 같으면 종료 시간이 빠른 순으로 정렬한 리스트를 만든다. (LinkedList와 PriorityQueue로 해봤는데 시간 차이는 비슷했다.)
그 다음, 규칙에 따라 리스트에서 하나씩 꺼내어 sum에 대기+실행 시간을 더한다.
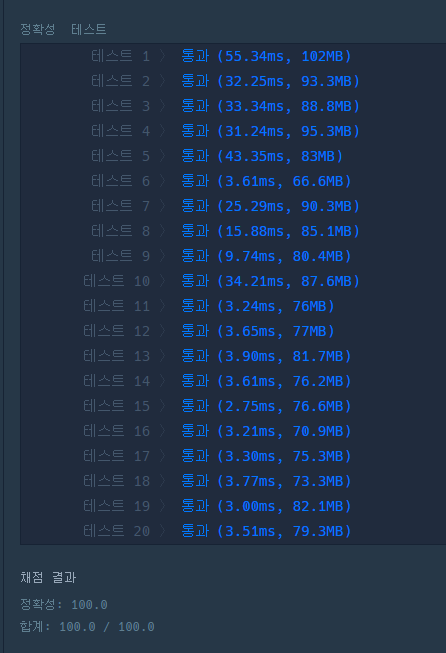
테스트 케이스 별 실행 속도 차이가 크다.
예상컨대, 데이터가 클수록 next 함수에서 Stream 비용이 커짐에 따라 발생하는 비용일 것이다.
성능 올리기
next 함수에서 Stream 제거
import java.util.*;
import java.util.stream.*;
class Solution {
public int solution(int[][] jobs) {
List<int[]> list = Arrays.stream(jobs)
.sorted((o1, o2) -> o1[0] == o2[0] ? o1[1] - o2[1] : o1[0] - o2[0])
.collect(Collectors.toCollection(LinkedList::new));
int sum = 0;
int offset = 0;
while(!list.isEmpty()) {
int[] next = next(list, offset);
int s = Math.max(next[0], offset);
int e = offset = s + next[1];
sum += e - next[0];
}
return sum / jobs.length;
}
private int[] next(List<int[]> jobs, int offset) {
int[] result = jobs.get(0);
for(int[] j : jobs) {
if(j[0] > offset) break;
else if(j[1] < result[1]) result = j;
}
jobs.remove(result);
return result;
}
}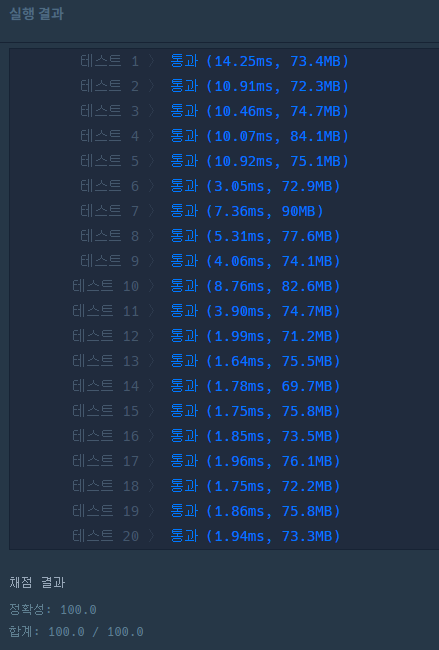 확실히 기존에 시간이 많이 걸렸던 테스트케이스들에 대해서 시간 비용이 크게 줄었다.
확실히 기존에 시간이 많이 걸렸던 테스트케이스들에 대해서 시간 비용이 크게 줄었다.
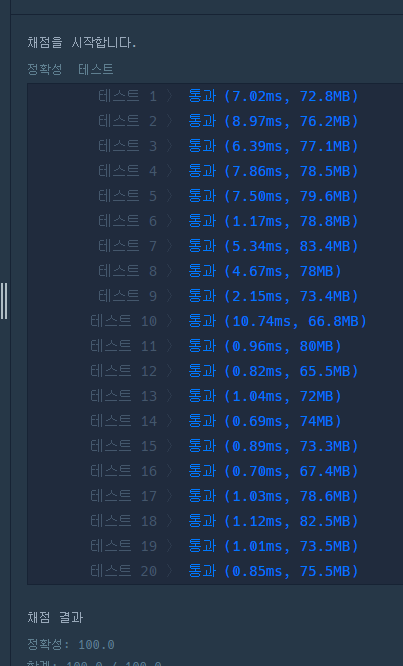
리스트 생성 부분의 Stream도 제거해보자.
import java.util.*;
import java.util.stream.*;
class Solution {
public int solution(int[][] jobs) {
List<int[]> list = new LinkedList<>();
for(int[] j : jobs) list.add(j);
Collections.sort(list, (o1, o2) -> o1[0] == o2[0] ? o1[1] - o2[1] : o1[0] - o2[0]);
int sum = 0;
int offset = 0;
while(!list.isEmpty()) {
int[] next = next(list, offset);
int s = Math.max(next[0], offset);
int e = offset = s + next[1];
sum += e - next[0];
}
return sum / jobs.length;
}
private int[] next(List<int[]> jobs, int offset) {
int[] result = jobs.get(0);
for(int[] j : jobs) {
if(j[0] > offset) break;
else if(j[1] < result[1]) result = j;
}
jobs.remove(result);
return result;
}
}
다른 답안 참고
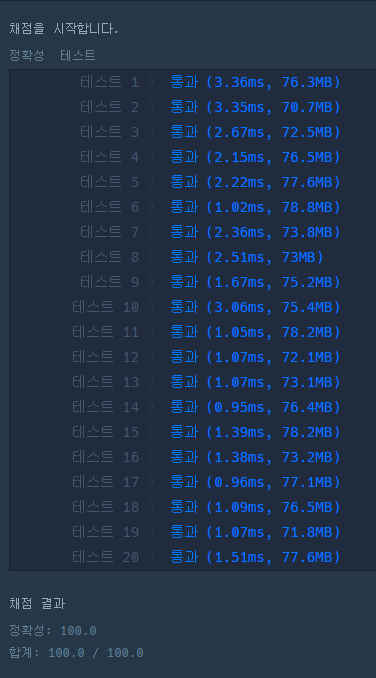
다음은 다른 분의 답안을 참고하였다.
위 답안들에 비해 next 함수에 대한 비용을 없앨 수 있다.
먼저 주어진 배열을 요청 시간에 따라 정렬한다.
그리고 종료 시간에 따라 정렬하는 PriorityQueue를 만든다.
큐는 대기 목록이다.
loop
대기 목록에 요소를 추가한다. -> 진행중인 작업의 종료 시간보다 이전의 요청시간을 가지는 요소만 추가한다. 따라서 큐는 진행중인 작업을 기다리는 대기 목록이다.
대기 목록에서 요소를 꺼내 계산한다.
endloop
import java.util.*;
class Solution {
public int solution(int[][] jobs) {
Arrays.sort(jobs, (o1, o2) -> o1[0] - o2[0]);
PriorityQueue<int[]> queue = new PriorityQueue<>(
(o1, o2) -> o1[1] - o2[1]
);
int sum = 0;
int offset = 0;
int idx = 0;
int remain = jobs.length;
while(remain > 0) {
while(idx < jobs.length &&jobs[idx][0] <= offset)
queue.add(jobs[idx++]);
if(queue.isEmpty()) {
offset = jobs[idx][0];
continue;
}
int[] next = queue.poll();
int s = Math.max(next[0], offset);
int e = offset = s + next[1];
sum += e - next[0];
remain--;
}
return sum / jobs.length;
}
}
마무리
보통 Stream의 비용은 데이터가 커질수록 그 비중이 작아지는데, 이번 경우엔 데이터의 양에 비례해 Stream의 비용도 증가하였기 때문에 비용이 크게 나왔다. 주의하자.
