예제 참고 전 개념 정리 : https://velog.io/@studyjun/Spring-Batch
프로젝트 환경
- Java 19
- Spring Boot 3.0.6
- Batch 5.0.1
프로젝트 시작
의존성 추가(Batch 예제이므로 Batch 필수)

yml파일 설정(사실상 db설정)
logging:
level:
root: info
com.studyjun.studyBatch: debug
spring:
batch:
job:
names: ${job.name:NONE}
jpa:
hibernate:
ddl-auto: update
use-new-id-generator-mappings: true
show-sql: true
datasource:
url: jdbc:mariadb://localhost:3306/studybatch
username: studyjun
password: 1234
driver-class-name: org.mariadb.jdbc.Driverdatabase 메타데이터 설정
- 프로젝트 -> External Libraries -> ...spring-batch-core:5.0.1 -> org.springframework.batch.core 안에서 자신의 사용하는 데이터베이스의 스키마를 추가해야함
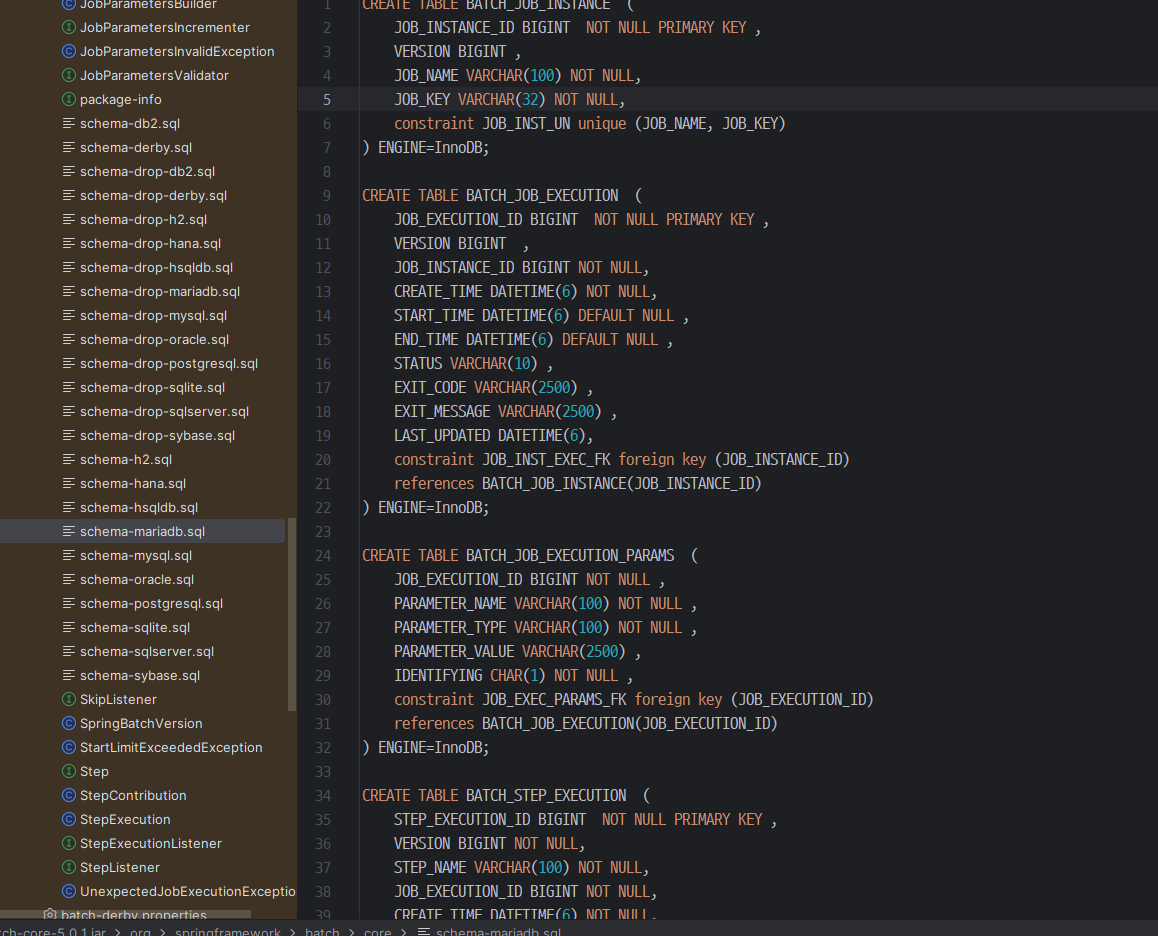
- 저걸 복사해서 붙여넣는 방식
tasklet
- 단일 메서드, 단일 task를 수행
코드
@Slf4j
@Configuration
public class TaskletJob {
@Bean
public Job taskletJobBatchBuild(JobRepository jobRepository, Step taskletJobStep1) {
return new JobBuilder("taskletJob", jobRepository)
.start(taskletJobStep1)
.build();
}
@Bean
public Step taskletJobStep1(JobRepository jobRepository, Tasklet testTasklet, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("taskletJobStep1", jobRepository)
.tasklet(testTasklet, platformTransactionManager).build();
}
@Bean
public Tasklet testTasklet(){
return ((contribution, chunkContext) -> {
log.info("-> job -> [step1]");
return RepeatStatus.FINISHED;
});
}
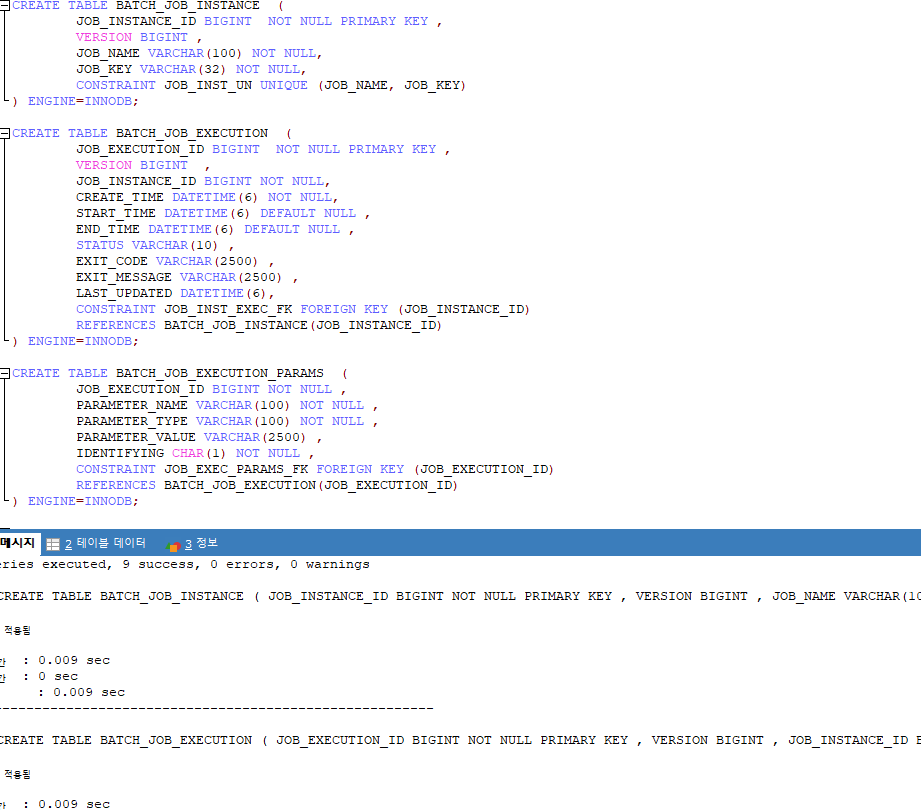
}실행 결과


- 같은 코드로 똑같이 실행했을 때 처음은 실행되지만 두 번째는 실행되지 않는 모습(한번 실행된 배치는 다시 실행되지 않음, 파라미터를 바꿔서 실행해야함)
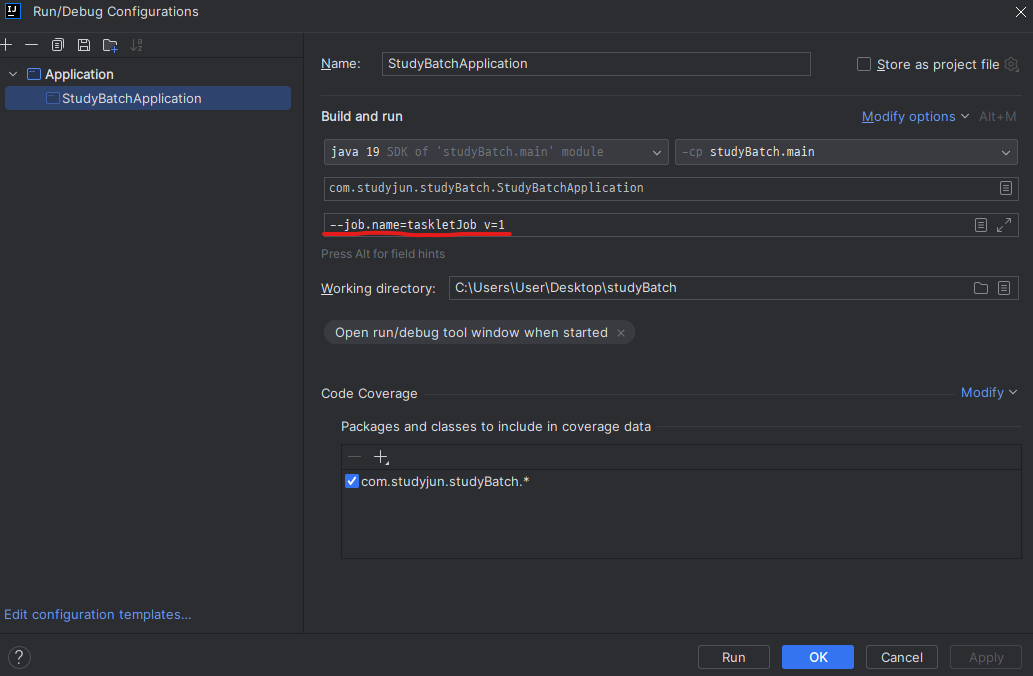
- run 환경에서 파라미터를 임의로 바꿔주면 실행 가능(실제론 date에 대한 값을 많이 넣는다고 함)

추가
- step을 추가할 수도 있음
@Slf4j
@Configuration
public class TaskletJob {
@Bean
public Job taskletJobBatchBuild(JobRepository jobRepository, Step taskletJobStep1, Step taskletJobStep2) {
return new JobBuilder("taskletJob", jobRepository)
.start(taskletJobStep1)
.next(taskletJobStep2)
.build();
}
@Bean
public Step taskletJobStep1(JobRepository jobRepository, Tasklet testTasklet1, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("taskletJobStep1", jobRepository)
.tasklet(testTasklet1, platformTransactionManager).build();
}
@Bean
public Step taskletJobStep2(JobRepository jobRepository, Tasklet testTasklet2, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("taskletJobStep2", jobRepository)
.tasklet(testTasklet2(new Date()), platformTransactionManager).build();
}
@Bean
public Tasklet testTasklet1(){
return ((contribution, chunkContext) -> {
log.info("-> job -> [step1] ");
return RepeatStatus.FINISHED;
});
}
@Bean
@JobScope
public Tasklet testTasklet2(){
return ((contribution, chunkContext) -> {
log.info("-> step1 -> [step2] ");
return RepeatStatus.FINISHED;
});
}
}DB
- 테이블의 데이터를 다른 테이블로 옮김(데이터 가공 가능)
테스트 데이터 작성
@Setter
@Getter
@ToString
@Entity
@AllArgsConstructor
@NoArgsConstructor
public class Dept {
@Id
Integer deptNo;
String dName;
String loc;
}@Setter
@Getter
@ToString
@Entity
@AllArgsConstructor
@NoArgsConstructor
public class Dept2 {
@Id
Integer deptNo;
String dName;
String loc;
}@SpringBootTest
public class TestRepository {
@Autowired
DeptRepository deptRepository;
@Test
@Commit
public void dept01() {
for (int i = 1; i <= 100; i++) {
deptRepository.save(new Dept(i, "dName_" + String.valueOf(i), "loc_" + String.valueOf(i)));
}
}
}코드
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JpaPageJob1 {
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job jpaPageJob1BatchBuild(JobRepository jobRepository, Step jpaPageJobStep1) {
return new JobBuilder("JpaPageJob1", jobRepository)
.start(jpaPageJobStep1).build();
}
@Bean
public Step jpaPageJobStep1(JobRepository jobRepository, PlatformTransactionManager platformTransactionManager) {
return new StepBuilder("JpaPageJobStep1", jobRepository)
.<Dept, Dept2>chunk(chunkSize)
.reader(jpaPageJob1DBItemReader())
.processor(jpaPageJob1Processor())
.writer(jpaPageJob1DBItemWriter())
.transactionManager(platformTransactionManager)
.build();
}
@Bean
public ItemProcessor<Dept, Dept2> jpaPageJob1Processor() {
return dept -> {
return new Dept2(dept.getDeptNo(), "NEW_" + dept.getDName(), "NEW_" + dept.getLoc());
};
}
@Bean
public JpaPagingItemReader<Dept> jpaPageJob1DBItemReader() {
return new JpaPagingItemReaderBuilder<Dept>()
.name("jpaPageJob1DBItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(chunkSize)
.queryString("SELECT d FROM Dept d order by 'dept_no' asc")
.build();
}
@Bean
public JpaItemWriter<Dept2> jpaPageJob1DBItemWriter() {
JpaItemWriter<Dept2> jpaItemWriter = new JpaItemWriter<>();
jpaItemWriter.setEntityManagerFactory(entityManagerFactory);
return jpaItemWriter;
}
}파라미터 추가
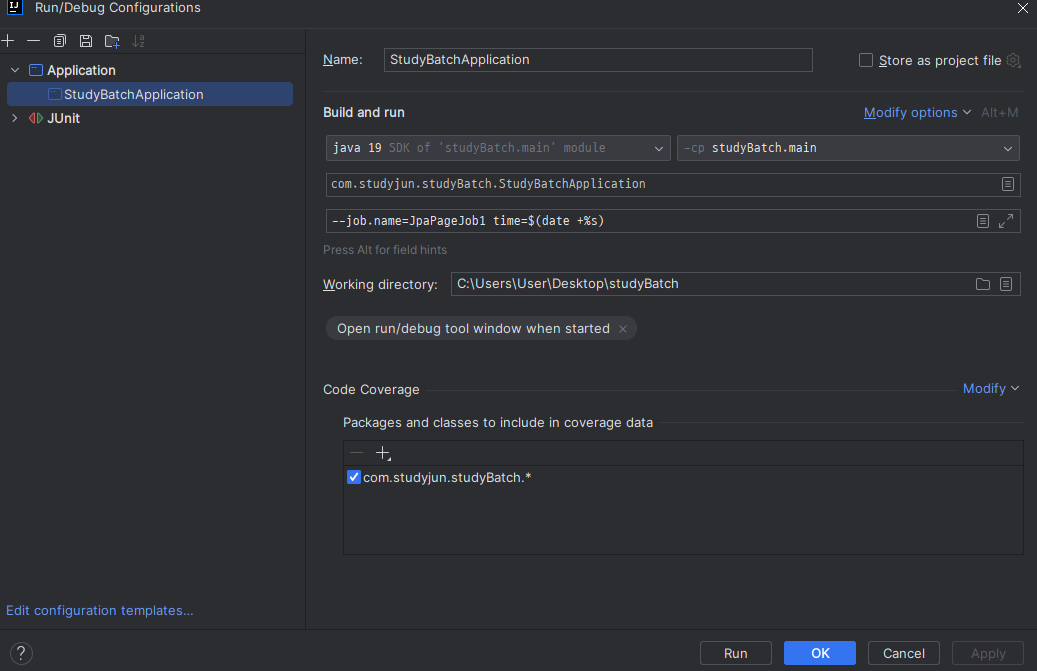
실행 결과
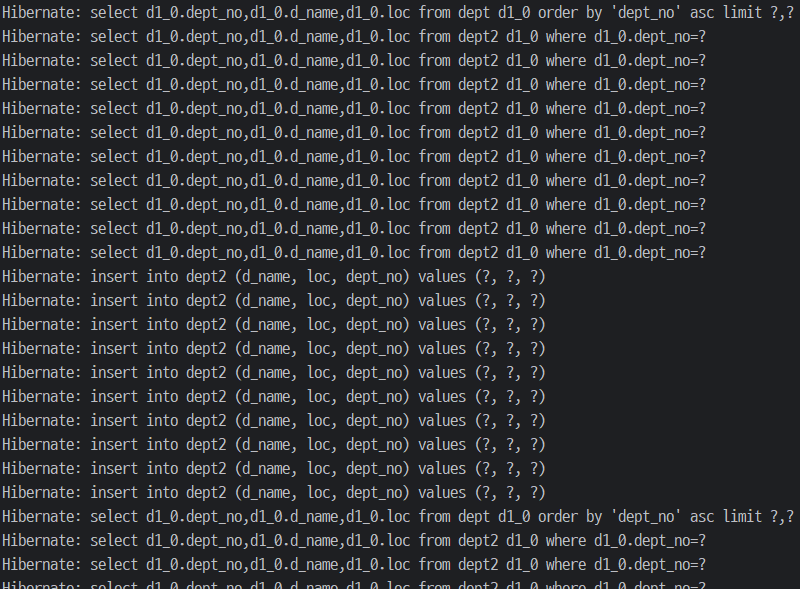
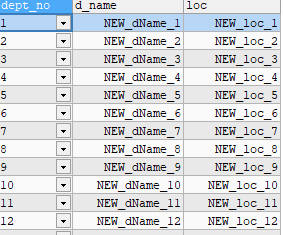
txt
- txt파일을 커스텀해서 새롭게 파일을 만들 수 있음
테스트 데이터
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
public class OneDto {
String one;
@Override
public String toString() {
return one;
}
}- txt파일을 만들어준다
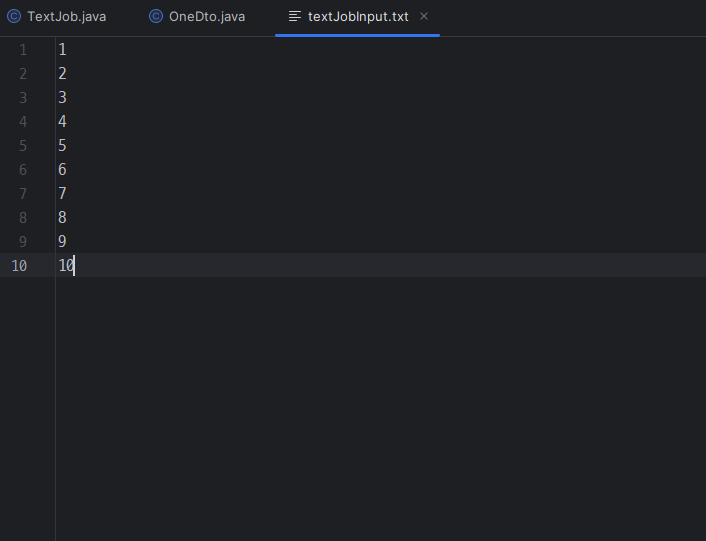
코드
@Slf4j
@Configuration
public class TextJob {
private static final int chunkSize = 5;
@Bean
public Job textJobBatchBuild(JobRepository jobRepository, Step textJobBatchStep) {
return new JobBuilder("textJob", jobRepository)
.start(textJobBatchStep).build();
}
@Bean
public Step textJobBatchStep(JobRepository jobRepository, PlatformTransactionManager platformTransactionManager) {
return new StepBuilder("textJobBatchStep", jobRepository)
.<OneDto, OneDto>chunk(chunkSize)
.reader(textJobFileReader())
.writer(textJobFileWriter())
.transactionManager(platformTransactionManager)
.build();
}
@Bean
public FlatFileItemReader<OneDto> textJobFileReader() {
FlatFileItemReader<OneDto> flatFileItemReader = new FlatFileItemReader<>();
flatFileItemReader.setResource(new ClassPathResource("textJobInput.txt"));
flatFileItemReader.setLineMapper((((line, lineNumber) -> new OneDto(lineNumber + "==" + line))));
return flatFileItemReader;
}
@Bean
public FlatFileItemWriter textJobFileWriter() {
return new FlatFileItemWriterBuilder<OneDto>()
.name("textJobFileWriter")
.resource(new FileSystemResource("textJobOutPut.txt"))
.lineAggregator(new CustomPassThroughLineAggregator<>())
.build();
}
}결과

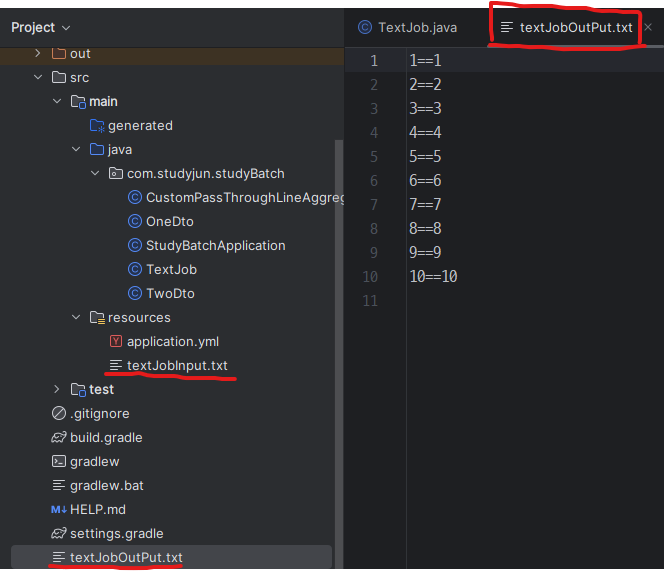
커스텀 방법
- OneDto의 toString에서 가능
- CustomPassThroughLineAggregator의 aggregate에서 가능
- TextJob의 Step에서 Processor로 가능(추천)
csv
테스트 데이터
- 보통 csv파일은 구분자가 콤마(,)이지만 쉽게 보이기 위해 커스텀했음
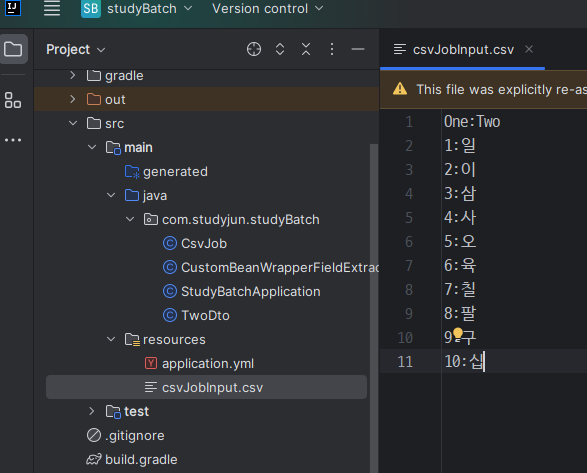
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
public class TwoDto {
String one;
String two;
}
코드
@Slf4j
@Configuration
public class CsvJob {
private static final int chunkSize = 5;
@Bean
public Job csvJobBatchBuild(JobRepository jobRepository, Step csvJobBatchStep) {
return new JobBuilder("csvJob", jobRepository)
.start(csvJobBatchStep).build();
}
@Bean
public Step csvJobBatchStep(JobRepository jobRepository, PlatformTransactionManager platformTransactionManager) {
return new StepBuilder("csvJobBatchStep", jobRepository)
.<TwoDto, TwoDto>chunk(chunkSize)
.reader(csvJobFileReader())
.transactionManager(platformTransactionManager)
.writer(csvJobFileWriter(new FileSystemResource("csvJobOutput")))
.build();
}
@Bean
public FlatFileItemReader<TwoDto> csvJobFileReader() {
FlatFileItemReader<TwoDto> flatFileItemReader = new FlatFileItemReader<>();
flatFileItemReader.setResource(new ClassPathResource("csvJobInput.csv"));
flatFileItemReader.setLinesToSkip(1);
DefaultLineMapper<TwoDto> dtoDefaultLineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer();
delimitedLineTokenizer.setNames("one", "two");
delimitedLineTokenizer.setDelimiter(":");
BeanWrapperFieldSetMapper<TwoDto> beanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
beanWrapperFieldSetMapper.setTargetType(TwoDto.class);
dtoDefaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
dtoDefaultLineMapper.setFieldSetMapper(beanWrapperFieldSetMapper);
flatFileItemReader.setLineMapper(dtoDefaultLineMapper);
return flatFileItemReader;
}
@Bean
public FlatFileItemWriter<TwoDto> csvJobFileWriter(WritableResource resource){
BeanWrapperFieldExtractor<TwoDto> beanWrapperFieldExtractor = new BeanWrapperFieldExtractor<>();
beanWrapperFieldExtractor.setNames(new String[]{"one", "two"});
beanWrapperFieldExtractor.afterPropertiesSet();
DelimitedLineAggregator<TwoDto> dtoDelimitedLineAggregator = new DelimitedLineAggregator<>();
dtoDelimitedLineAggregator.setDelimiter("@");
dtoDelimitedLineAggregator.setFieldExtractor(beanWrapperFieldExtractor);
return new FlatFileItemWriterBuilder<TwoDto>().name("csvJobFileWriter")
.resource(resource)
.lineAggregator(dtoDelimitedLineAggregator)
.build();
}
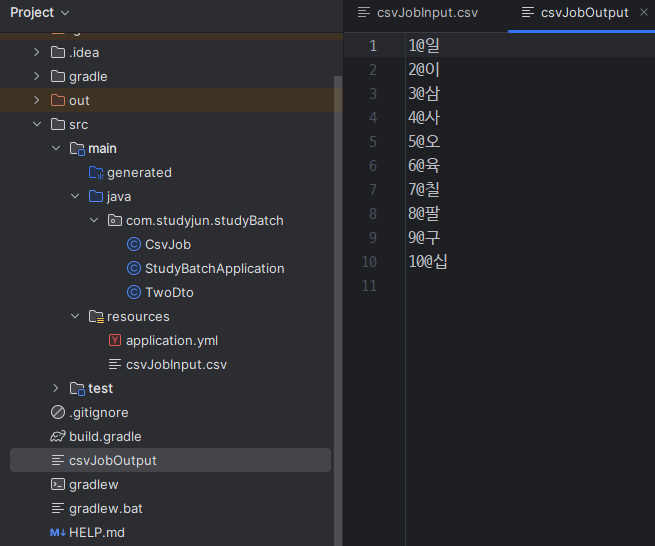
}실행 결과
- 맨 윗줄을 스킵하고, : -> @ 로 바뀜
fixed
테스트 데이터
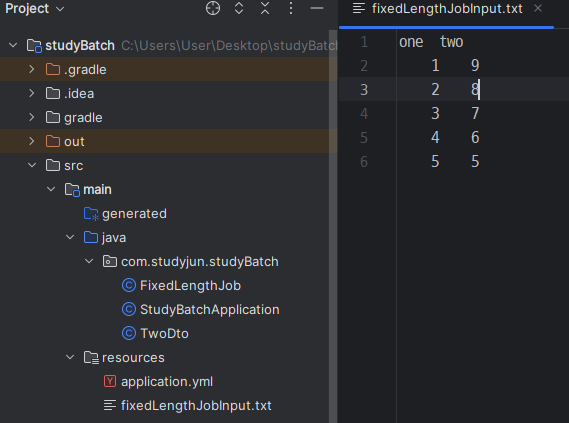
코드
@Slf4j
@Configuration
public class FixedLengthJob {
private static final int chunkSize = 5;
@Bean
public Job fixedLengthJobBatchBuild(JobRepository jobRepository, Step fixedLengthJobBatchStep) {
return new JobBuilder("FixedLengthJob", jobRepository)
.start(fixedLengthJobBatchStep)
.build();
}
@Bean
public Step fixedLengthJobBatchStep(JobRepository jobRepository, PlatformTransactionManager platformTransactionManager) {
return new StepBuilder("fixedLengthJobBatchStep", jobRepository)
.<TwoDto, TwoDto>chunk(chunkSize)
.reader(fixedLengthJobFileReader())
.transactionManager(platformTransactionManager)
.writer(fixedLengthJobFileWriter(new FileSystemResource("fixedLengthJobOutput.txt")))
.build();
}
@Bean
public FlatFileItemReader<TwoDto> fixedLengthJobFileReader() {
FlatFileItemReader<TwoDto> flatFileItemReader = new FlatFileItemReader<>();
flatFileItemReader.setResource(new ClassPathResource("fixedLengthJobInput.txt"));
flatFileItemReader.setLinesToSkip(1);
DefaultLineMapper<TwoDto> dtoDefaultLineMapper = new DefaultLineMapper<>();
FixedLengthTokenizer fixedLengthTokenizer = new FixedLengthTokenizer();
fixedLengthTokenizer.setNames("one", "two");
fixedLengthTokenizer.setColumns(new Range(1, 5), new Range(6, 10));
BeanWrapperFieldSetMapper<TwoDto> beanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
beanWrapperFieldSetMapper.setTargetType(TwoDto.class);
dtoDefaultLineMapper.setLineTokenizer(fixedLengthTokenizer);
dtoDefaultLineMapper.setFieldSetMapper(beanWrapperFieldSetMapper);
flatFileItemReader.setLineMapper(dtoDefaultLineMapper);
return flatFileItemReader;
}
@Bean
public FlatFileItemWriter<TwoDto> fixedLengthJobFileWriter(FileSystemResource resource) {
BeanWrapperFieldExtractor<TwoDto> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames((new String[] {"one", "two"}));
fieldExtractor.afterPropertiesSet();
FormatterLineAggregator<TwoDto> lineAggregator = new FormatterLineAggregator<>();
lineAggregator.setFormat("%-5s###%5s");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<TwoDto>()
.name("fixedLengthJobFileWriter")
.resource(resource)
.lineAggregator(lineAggregator).build();
}
}실행 결과
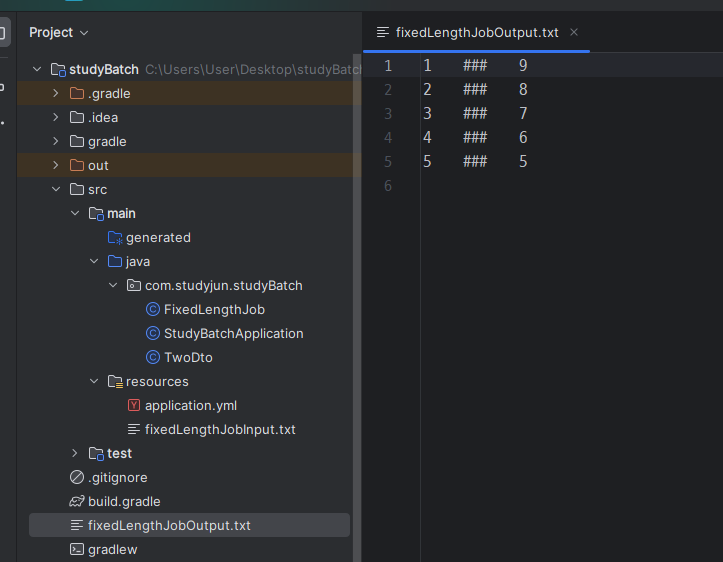
json
- 위와 상동

study