트리
트리란?
- 노드와 에지로 연결된 그래프의 특수한 형태
- 순환 구조를 지니고 있지 않고, 1개의 루트 노드가 존재
- 루트 노드를 제외한 노드는 단 1개의 부모노드를 가짐
- 트리의 부분 트리 역시 트리의 모든 특징을 따름
- 트리에서 임의의 두 노드를 이어주는 경로는 유일함
트리의 핵심 이론
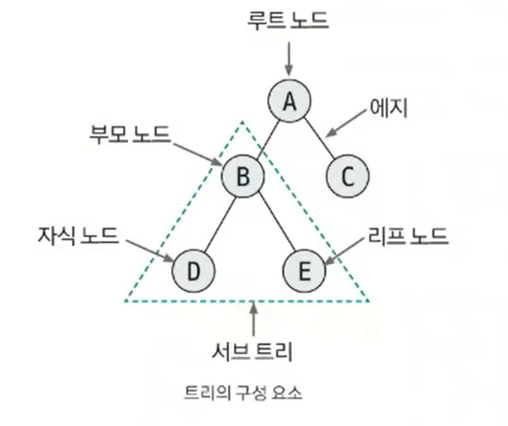
- 노드 : 데이터의 index와 value를 표현하는 요소
- 에지 : 노드와 노드의 연결 관계를 나타내는 선
- 루트 노드 : 트리에서 가장 상위에 존재하는 노드
- 부모 노드 : 두 노드 사이의 관계에서 상위 노드에 해당하는 노드
- 자식 노드 : 두 노드 사이의 관계에서 하위 노드에 해당하는 노드
- 리프 노드 : 트리에서 가장 하위에 존재하는 노드(자식 노드가 없는 노드)
- 서브 트리 : 전체 트리에 속한 작은 트리
이진 트리
이진 트리란?
- 각 노드의 자식 노드(차수)의 개수가 2 이하로 구성된 트리
- 트리 영역에서 가장 많이 사용되는 형태
이진 트리의 핵심 이론
이진트리의 종류
- 편향 이진 트리 : 노드들이 한쪽으로 편향돼 생성된 이진 트리
- 포화 이진 트리 : 트리의 높이가 모두 일정하며 리프 노드가 꽉 찬 이진 트리
- 완전 이진 트리 : 마지막 레벨을 제외하고 완전하게 노드들이 채워져있고, 마지막 ㅔ벨은 왼쪽부터 채워진 트리
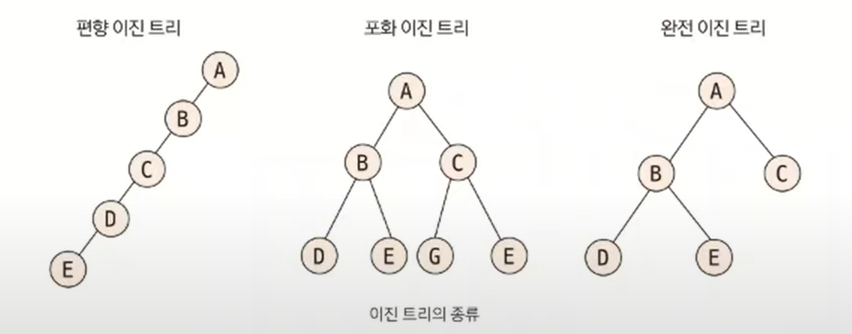
데이터를 트리 자료구조에 저장할 때 편향 이진 트리의 형태로 저장하면 탐색 속도가 저하되고 공간이 많이 낭비되는 단점이 있음
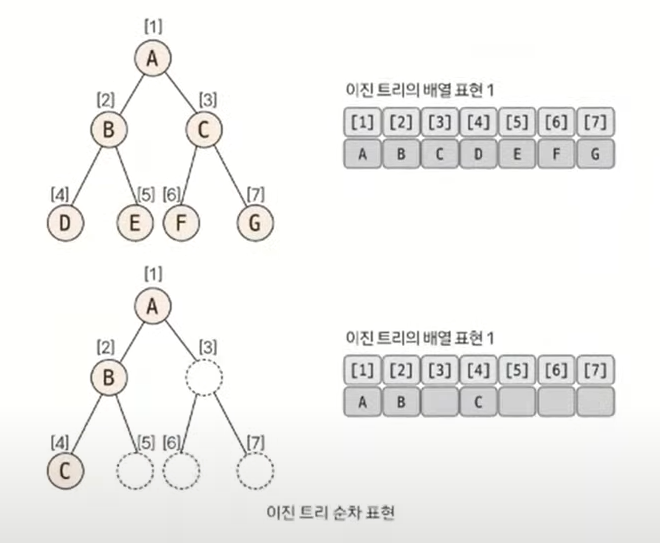
이진 트리의 순차 표현
- 가장 직관적이면서 편리한 트리 자료구조 형태는 배열

세그먼트 트리(인덱스 트리)
세그먼트 트리란?
- 주어진 데이터의 구간 합과 데이터 업데이트를 빠르게 수행하기 위해 고안해낸 자료구조의 형태
- 더 큰 범위는 '인데스 트리'라고 불리는데, 코딩 테스트 영역에서는 큰 차이가 없음
세그먼트 트리의 핵심 이론
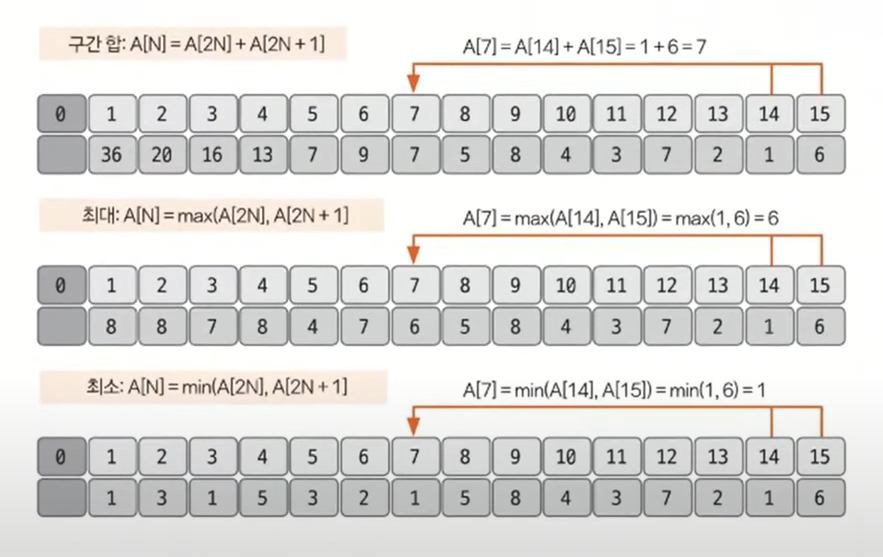
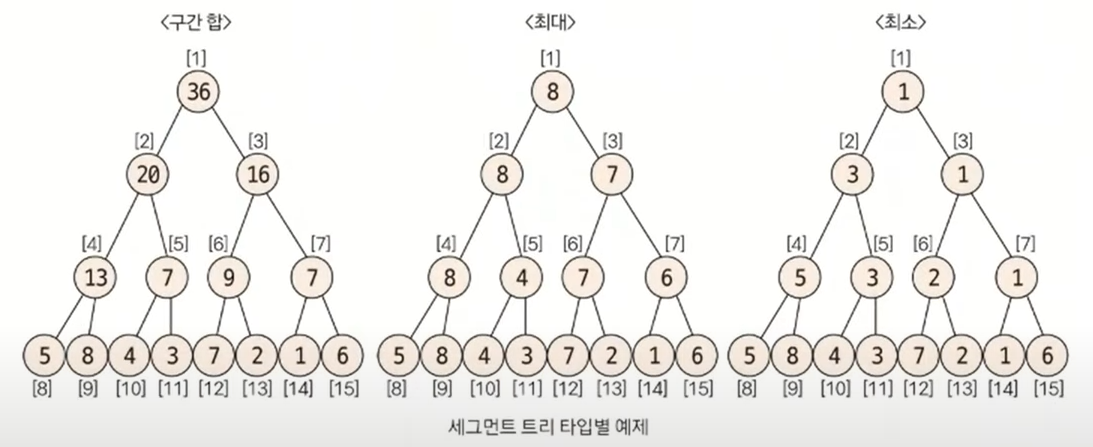
- 종류는 구간 합, 최대·최소 구하기로 나눌 수 있고, 구현 단계는 트리 초기화하기, 질의값 구하기(구간 합 또는 최대·최소), 데이터 업데이트하기로 나눌 수 있음
1. 트리 초기화
- 리프 노드의 개수가 데이터의 개수(N) 이상이 되도록 트리 배열을 만듬
- 트리 배열의 크기를 구하는 방법은 2^k ≥ N을 만족하는 k의 최솟값을 구한 후 2^k * 2를 트리 배열의 크기로 정의
- 리프 노드를 제외한 나머지 노드의 값을 2^k - 1부터 1번 쪽으로 채움
- 채워햐 하는 인덱스가 N이라고 가정하면 자신의 자식 노드를 이용해 해당 값을 채울 수 있음(자식 노드의 인덱스는 이진 트리 형식이기 때문에 2N, 2N + 1이 됨)
2. 질의값 구하기
- 주어진 질의 인덱스를 세그먼트 트리의 리프 노드에 해당하는 인덱스로 변경
- 기존 샘플을 기준으로 한 인덱스 값과 세그먼트 트리 배열에서의 인덱스 값이 다르기 때문에 인덱스를 변경해야 함
질의 인덱스를 세그먼트 트리 인덱스로 변경하는 방법 : 세그먼트 트리 index = 주어진 질의 index + 2^k - 1
질의값 구하는 과정
1. startIndex % 2 == 1일 때 해당 노드를 선택
2. endIndex % 2 == 0일 때 해당 노드를 선택
└> 1 ~ 2에서 해당 노드를 선택했다는 것은 해당 노드의 부모가 나타내는 범위가 질의 범위를 넘어가기 때문에 해당 노드를 질의값에 영향을 미치는 독립 노드로 선택하고, 해당 노드의 부모 노드는 대상 범위에서 제외한다는 뜻
3. startIndex depth 변경 : satrtIndex = (startIndex + 1) / 2 연산을 실행
4. endIndex depth 변경 : endIndex = (endIndex - 1) / 2 연산을 실행
5. 1 ~ 4를 반복하다가 endIndex < startIndex가 되면 종료
질의에 해당하는 노드를 선택하는 방법은 구간 합, 최댓값 구하기, 최솟값 구하기 모두 동일하며 선택된 노드들에 관해 마지막에 연산하는 방법만 다름
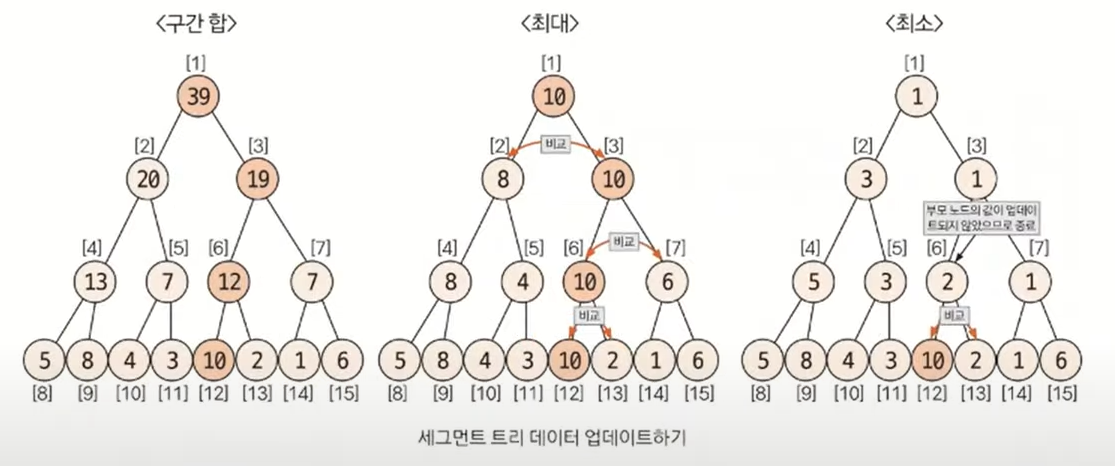
3. 데이터 업데이트
- 업데이트 방식은 자신의 부모 노드로 이동하면서 업데이트한다는 것은 동일하지만, 어떤 값으로 업데이트할 것인지에 관해서는 트리 타입별로 조금 다름
- 구간 합에서는 원래 데이터와 변경 데이터의 차이만큼 부모 노드로 올라가면서 변경
- 최댓값 찾기에서는 변경 데이터와 자신과 같은 부모를 지니고 있는 다른 자식 노드와 비교해 더 큰 값으로 업데이트(업데이트가 일어나지 않으면 종료)
- 최솟값 찾기에서는 변경 데이터와 자신과 같은 부모를 지니고 있는 다른 자식 노드와 비교해 더 작은 값으로 업데이트(업데이트가 일어나지 않으면 종료)
LCA(최소 공통 조상)
LCA란?
- 트리 그래프에서 임의의 두 노드를 선택했을 때 두 노드가 각각 자신을 포함해 거슬러 올라가면서 부모 노드를 탐색할 때 처음 공통으로 만나게 되는 부모 노드
LCA의 핵심 이론
1. 일반적인 최소 공통 조상 구하기(트리의 높이가 크지 않을 때)
- 루트 노드에서 탐색을 시작해 각 노드의 부모 노드와 깊이를 저장
- 이때 탐색은 DFS 또는 BFS을 이용해 수행
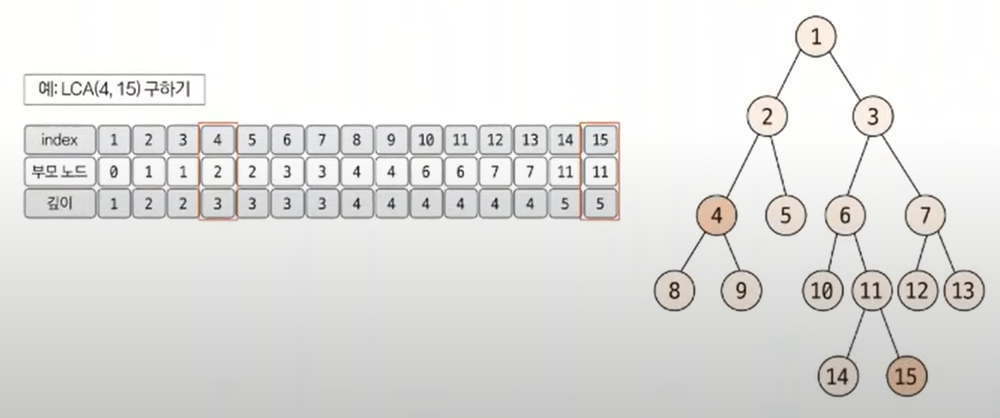
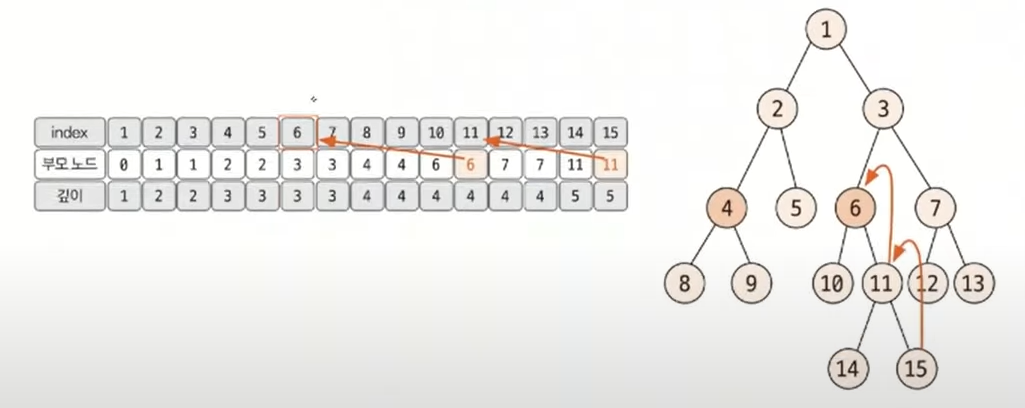
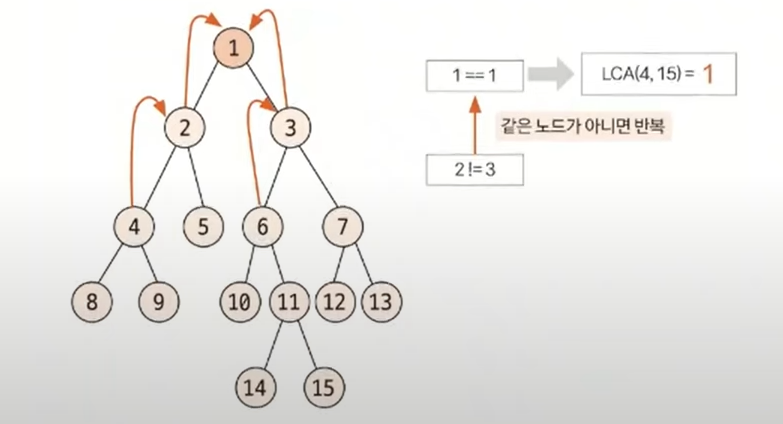
- 선택된 두 노드의 깊이가 다른 경우, 더 깊은 노드의 노드를 부모 노드로 1개씩 올려주면서 같은 깊이로 맞춤
- 이때 두 노드가 같으면 해당 노드가 최소 공통 조상이므로 탐색을 종료
- 위의 방법으로 최소 공통 조상을 구할 수 있지만, 트리의 높이가 커질 경우, 시간 제약 문제에 직면
- 이러한 문제를 해결하기 위해 새롭게 제안된 방식이 '최소 공통 조상 빠르게 구하기'
- '최소 공통 조상 빠르게 구하기'는 일반적인 최소 공통 조상 구하기 알고리즘을 약간 변형한 형태
2. 최소 공통 조상 빠르게 구하기
- 핵심은 서로의 깊이를 맞춰 주거나 같아지는 노드를 찾을 때 기존에 한 단계씩 올려 주는 방식에서 2^K씩 올라가 비교하는 방식
- 기존에 자신의 부모 노드만 저장해 놓던 방식에서 2^K번째 위치의 부모 노드까지 저장해 둬야 함
2 - 1. 부모 노드 저장 배열 만들기
- 부모 노드 배열의 정의 : P[K][N] = N번 노드의 2^K번째 부모의 노드 번호
- 부모 노드 배열의 점화식 : P[K][N] = p[K - 1]P[K - 1][N]]
- K는 트리의 깊이 > 2^K를 만족하는 최댓값
2 - 2. 선택된 노드 깊이 맞추기
- P 배열을 이용해 기존에 한 단계씩 맞췄던 깊이를 2^K 단위로 넘어가면서 맞춤
2 - 3. 최소 공통 조상 찾기
- 공통 조상을 찾는 작업도 한 단계씩이 아닌 2^K 단위로 점프하면서 맞춤
- K값을 1씩 감소하면서 P 배열을 이용해 최초로 두 노드의 부모가 달라지는 값을 찾을 때까지 반복(반복문이 종료된 후 이동한 2개의 노드가 같은 노드라면 해당 노드가, 다른 노드라면 바로 위의 부모 노드가 최소 공통 조상)

study