프로메테우스(Prometheus)란?
- 2016년 5월에 CNCF에 2번째 인큐베이팅된 프로젝트
- 이벤트 모니터링 & 알람을 담당
- 메트릭을 수집하고 시계열DB(TSDB)
메트릭이란?
- 시스템 상태를 알 수 있는 측정값
- CPU 메모리 사용량 표시
- 웹서비스 관련 HTTP 상태 코드 표시 - Pull방식으로 데이터를 수집
프로메테우스(Prometheus)의 구조
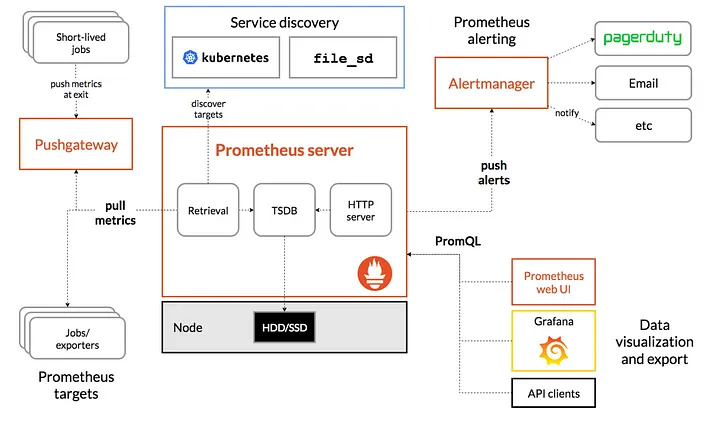
주요 구성 요소
Prometheus Server
- 수집된 Metric을 Pull 방식
- TSDB에 저장
- 외부에 노출을 위한 HTTP 서버 존재
Node-Exporter
- 각 노드에 Linux 레벨의 Metric을 수집
Kube-state-metrics
- 클러스터의 여러 Metric data를 수집
- 수집된 data를 Prometheus가 수집할 수 있는 Metric 형태로 변환 후 공개
AlertManager (중요)
- Alert Rule을 설정하고, Event 발생 시 설정된 Alert 메시지를 전달
- Email, Slack, Webhook 등의 방법으로 전달
AlertManager의 주요 기능 요소
- Grouping : 유사한 성격의 경고를 하나의 알림으로 분류
- Inhibition : 특정 경고가 활성화 되어 있을 경우, 타 경고 알림을 억제
- Silences : 주어진 시간동안 발생하는 경고를 음소거 하는 역할, 경고에 대한 알림이 발생하지 않음
알림 상태 종류
- Inactive : 정상 상태
- Pending : 알람 전송 보류 상태
- Firing : 알람 발생, 조건에 따라 외부 전달
데이터를 수집하는 방식
- Node-exporter : exporter는 수집한 매트릭을 HTTP를 통해 가져갈 수 있도록 /metrics라는 HTTP endpoint를 노출, cpu, memory, disk, network등 노드에 대한 메트릭 수집
- Retrieval : 수집 대상에서 메트릭을 가져오는 역할
- TSDB : 시간을 기준으로 저장(Key:Value 형태로 저장), 전반적으로 뛰어난 성능 보유
- HTTP Server : Prometheus에 저장된 데이터를 조회하는 역할, HTTP REST API를 제공, 대시보드 구성 지원
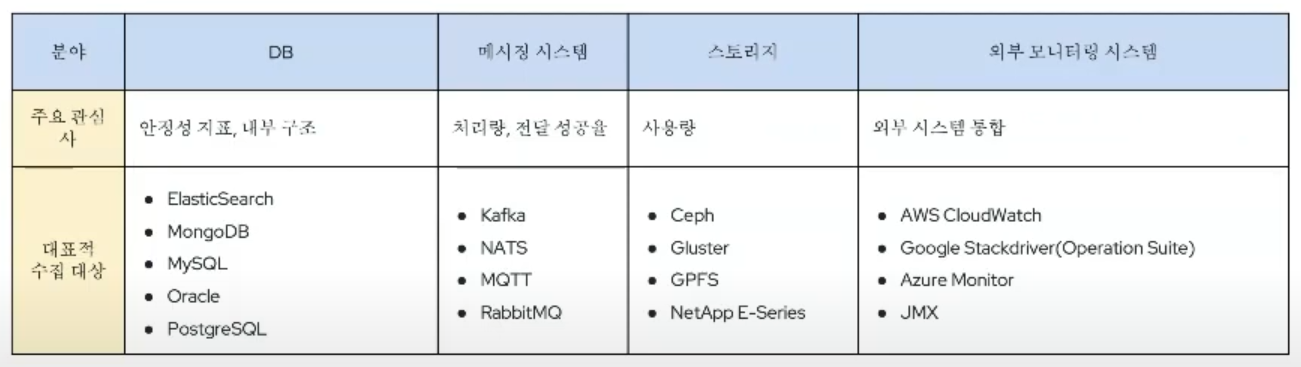
대표적인 Exporter 종류
DIY 구축 시 고려 사항
- 확장성 : 여러 프로메테우스를 중앙 프로메테우스에서 메트릭 수집 -> 데이터의 수집 강도를 늘려 해결
- 가용성 : 패치 혹은 서버 재시작등으로 인한 메트릭 수집 불가 -> 다수의 프로메테우스로 메트릭 수집 시 해결 가능
데이터 중복이나 스토리지 용량 관리 부분에서 이슈가 생길 수 있음(최적화된 방법은 아님)
Thanos란? (Highly available & long term storage capabilities)
- 클라우드 환경에서 프로메테우스의 확장성과 내구성을 향상시키기 위한 오픈 소스 프로젝트이다.
- 프로메테우스의 메트릭 데이터를 분산된 원격 스토리지에 저장하고 조회할 수 있게 해주는 기능을 제공
- 여러 개의 프로메테우스로부터 매트릭을 조합해서 타노스에서 전체 프로메테우스의 메트릭을 볼 수 있도록 해주고, 수집된 메트릭을 스케일이 가능한 스토리지에 저장해서 특정 프로메테우스 인스턴스가 다운이 되더라도 그 인스턴스가 담당하는 메트릭을 조회할 수 있도록 해준다.
Thanos의 주요 기능
- Global Query View : 다수의 Prometheus 서버들과 클러스터들에 걸친 Query를 지원
- Unlimited Retention : 다양한 저장소에 메트릭을 저장할 수 있으며, 데이터 보관주기의 제약이 없다.
- Prometheus Compatible : Prometheus의 인터페이스와 거의 완벽하게 호환되는 API를 제공
- DownSampling & Compaction : 데이터의 시간주기별 데이터를 생성, 통합데이터 조회의 성능을 높임, 상세 저장주기 설정을 통한 효율성 확보

study