Adaptive Instance Normalization
기존에는 임의의 이미지를 한다해도 정확도가 떨어지거나, 스타일을 특정지어서 하거나, 정확도는 높으나 속도가 느려진다는 둘다 충족 시키는 것이 없었다
- 자신이 원하는 임의의(arbitrary) 스타일 이미지로부터 스타일 정보를 가져올 수 있다
- 하나의 네트워크를 학습시키고 어떤 이미지에서든 스타일 정보를 추출하고 적용할 수 있다
- 실시간으로(real-time) 빠르게 스타일 전송 가능
- feed-foward네트워크로 이미지를 준비해서 한번의 foward로 결과 이미지 만들 수 있다
- 이미지의 feature의 statistics(mean과 various)를 변경할 수 있다
-> AdaIN자체가 styletransfer이라 할 수 있다
배경지식
초창기 StyleTransfer

- style loss와 content loss 두가지를 이용하여 구성
- 노이즈 정보를 업데이트하는 방식
- 단점 : 매번 사전학습된 네트워크에 넣고 역전파를 통해서 구한 기울기 값으로 각각의 픽셀 값들을 업데이트 시킨다 -> 수백 수천개의 픽셀을 foward하고 다시 역전파를 하여 시간이 오래걸린다
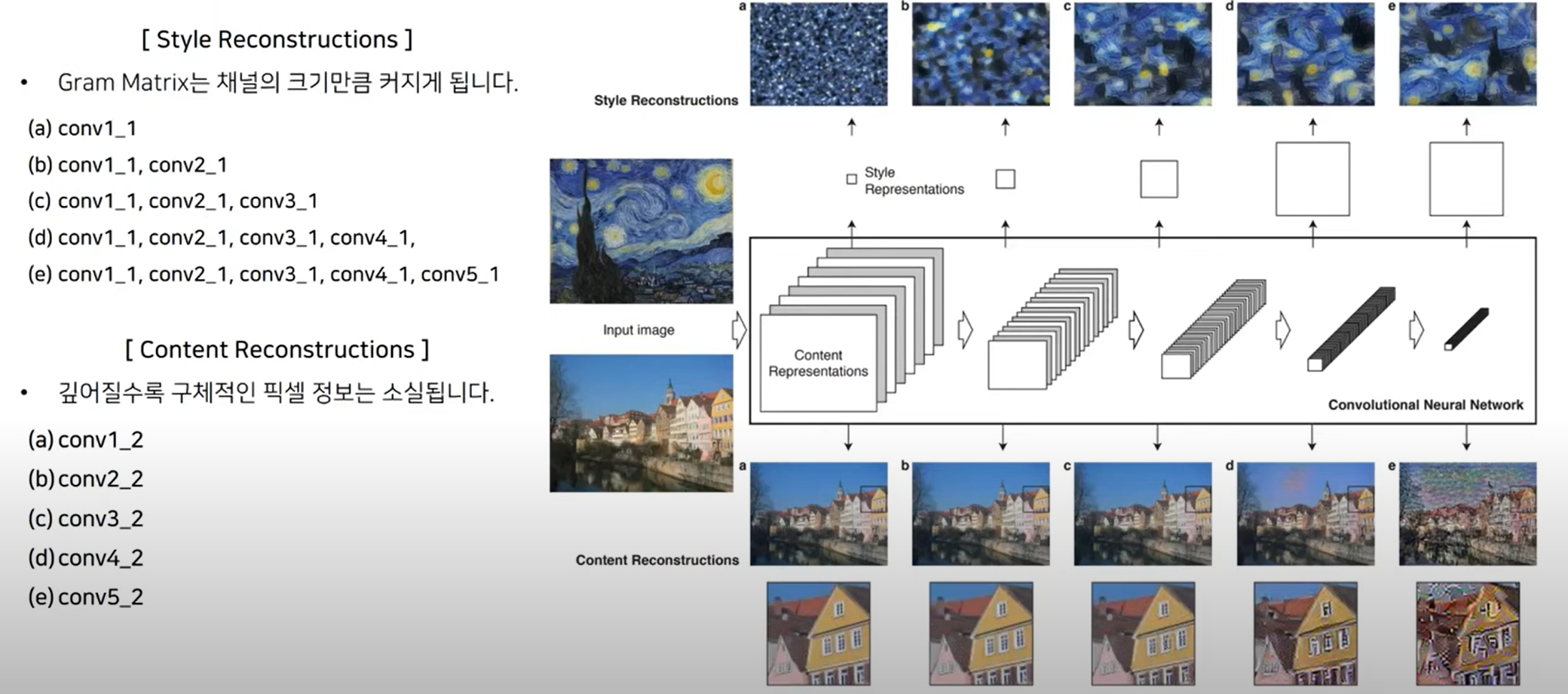
- 사전학습되 CNN에서 content는 특정레이어에서 feature같이 같아지는 방식으로 업데이트
- Style은 그램메트릭스를 구한뒤에 이러한 그램메트릭스가 유사해질 수 있도록 업데이트하는 방식
-> 사전 학습된 CNN에 feature를 추출하는 목적
Batch Normalization
- scaling: 일반적으로 데이터의 범위를 임의로 조정하는 것
- 표준정규분포: 편차가 1이고 평균이 0
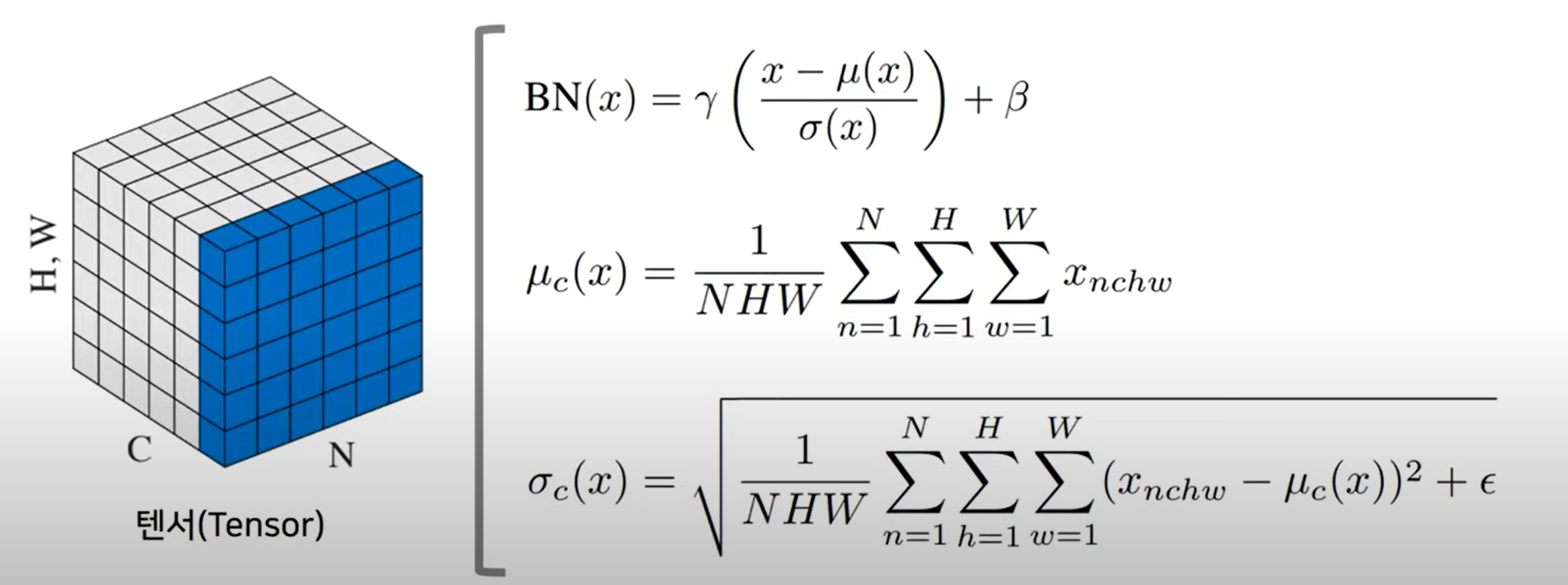
- 채널별로 배치사이즈 만큼 정규화 시키고 파라미터인 스케일 r와 tanslation b를 넣는다
-> 분류모델에서 사용시 속도르 향상 시켜준다
Instance Normalization
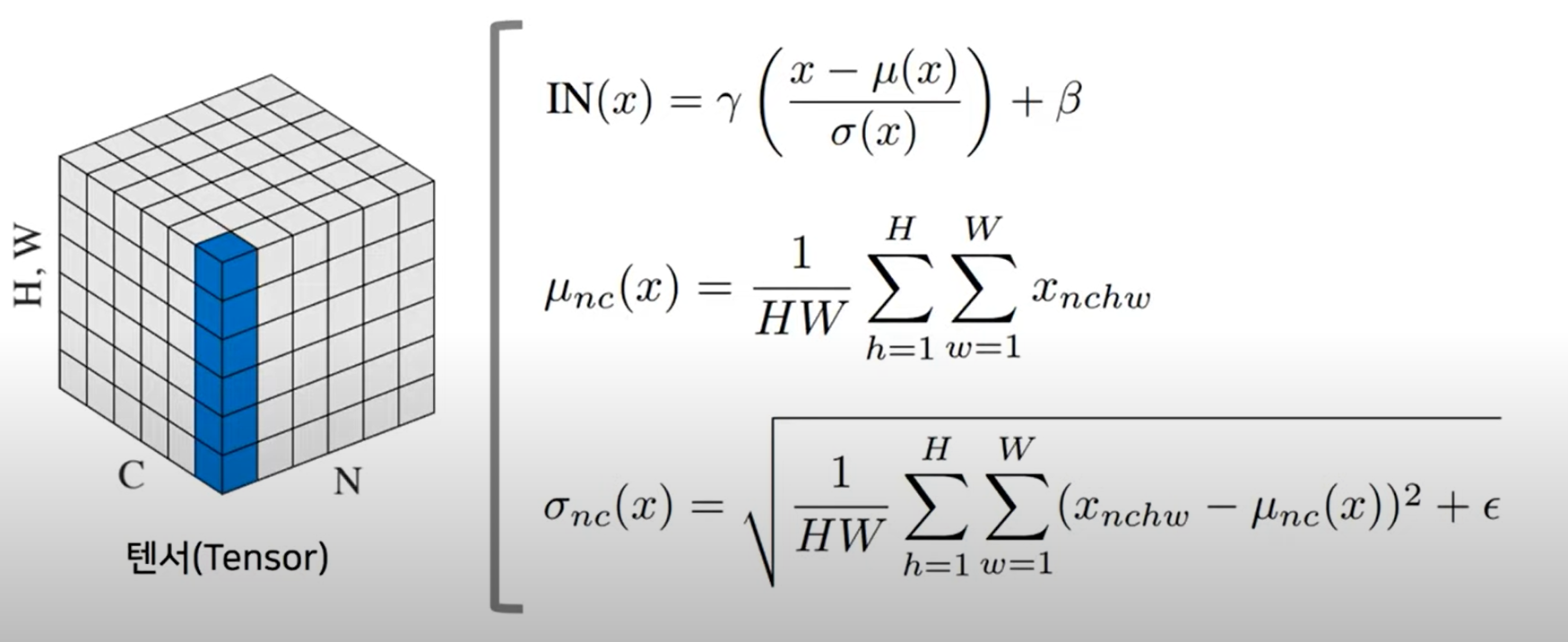
- 개별적인 이미지(인스턴스)에 대하여 각 체널별로 정규화 수행
-> 배치와 다르게 개별적으로 수행
조건부 인스턴스 정규화
-
인스턴스 정규화를 수행 시 조건에 따라 다른 feature stastics를 갖도록 한다
-
감마와 벡터가 스타일별로 다르게 들어간다
-> 다른 감마와 벡터를 사용하는 것만으로도 다른 스타일을 만들어 낼 수 있다


-
2FS 각각의 featureMap마다 2개의 감마 벡터 필요하고 또한 스타일 개수만큼 필요
AdaIN
- CIN으로 feature stastics 변경만으로 style transfer 효과를 낼 수 있다
-> 고정된 style 사용하지 않고 임의의 이미지로부터 스타일 추출 - 다른 원하는 이미지에서 스타일 정보를 가져와 적용할 수 있다
-> feed-foward 방식의 style transfer네트워크에서 사용되어 좋은 성능
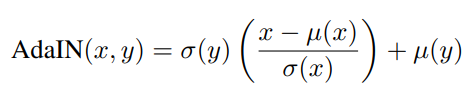
- r를 다른 이미지로부터 가져온 피쳐상의 시그마와 mean값으로 바꿔줬다
x: 콘텐츠 이미지 y: 스타일 이미지 - CIN에서의 statsics 부분을 스타일에서 가져온 정보로 대처한 것
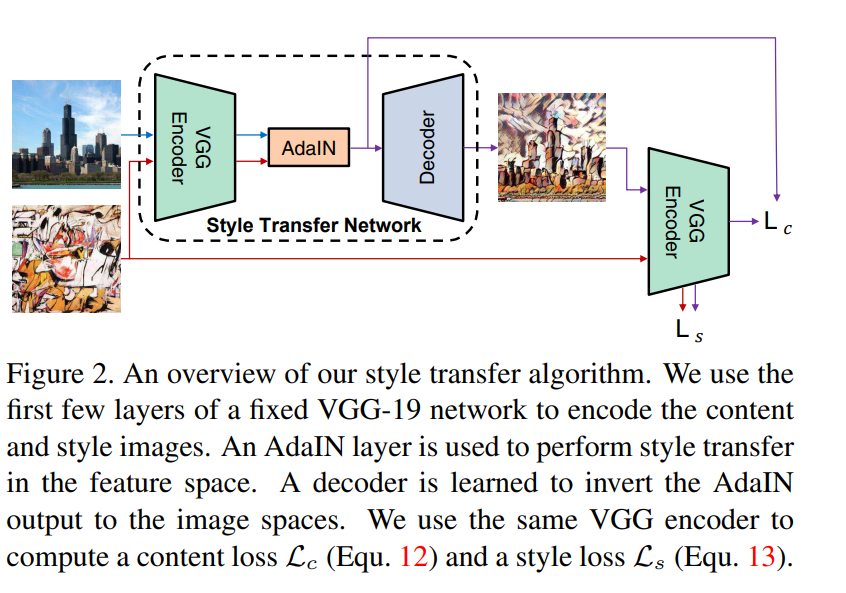
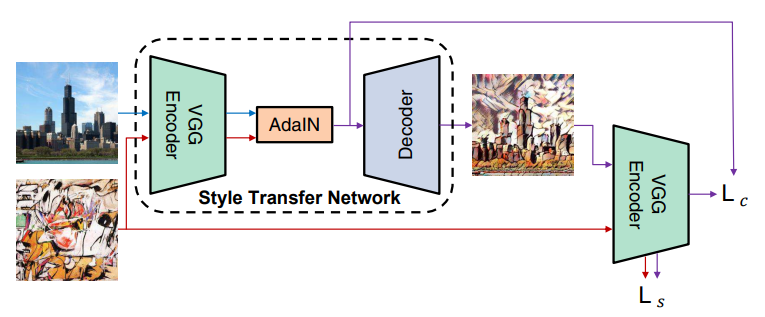
- 사전학습된 VGG Encoder를 사용하여 특징 추출 목적으로 사용되는 고정된 네트워크
- Decoder: 학습할 네트워크이며 결과 이미지를 생성하는 역할
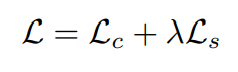
- content Loss와 style Loss 두가지로 된다

- style과 content feature를 추출한 다음에 adain레이어를 거치게 한다
- 디코더네트워크 g를 거쳐 결과 이미지를 만든다

- contentLoss
- 결과 이미지를 다시 vgg네트워크에 넣고 Adain레이어의 feature값 t와 같아 질 수 있도록 로스값을 변경
- styleLoss
- 콘텐트 이미지에 feature에 statiscs값을 바꾸는 방향
- 파이i는 i번쨰 스타일 feature
- 스타일로스는 하나의 레이어만 사용하는 것이 아닌 여러개의 레이어에 사용
- 결과 상의 feature값의 평균값이 스타일상의 평균값과 유사해질 수 있도록 업데이트 -> 평균과 표준편차 둘다 같아질 수 있도록 학습
논문리뷰
Abstract

- 픽셀 하나하나를 업데이트 하기에 몇백번의 과정을 반복
- feed foward방식으로 수행하도록 바꿈
-> 고정된 스타일로만 가능하여 새로운 모델을 학습시켜 스타일을 적용시켜야 했다 - Adain을 통해 해결 가능하다
- content와 스타일 비율 조절 가능
Introduction

- 초창기는 속도에 문제가 있었다
- feed-foward방식을 사용했고
-> 하나의 스타일로 제한돼 있었다

- instance nomarlizaion으로 style transfer과 같은 효과를 낼 수 있다고 생각
- feature statistics자체가 스타일 정보를 가지고 있다
-> 그램메트릭스를 통해 맞추는 것도 feature statistics를 다루는 것과 같다 - Adain은 사전 학습된 VGG 네트워크를 고정하고 A decoder를 학습
-> 3배 이상 빨라졌다 - 기존의 feedfoward와 다르게 임의의 이미지의 스타일을 바로 적용 가능
Related Work

- 초창기 styletransfer은 그램매트릭스를 사용하는 거였는데 이것이 결국 feature statistics를 다루는 것

- 효과적인 결과가 나왔지만 속도 측면에서 떨어지기에 디바이스 상황에서는 사용이 힘들다
-> 순전파와 역전파를 통해 업데이트를 했기 때문에 - feed foward방식이 나왔지만 스타일에 제한이 있기 때문에 더 효과적인 기술이 나와도 제한적이었다

- styleswap(논문)레이어를 통해 임의의 스타일을 만들 수 있게도 했다 -> 속도 저하
- 이전 논문의 로스값을 구하는 것을 보면 CNN에 넣고 추출한 feature값 자체의 statistics를 match시키는 방식으로 styletransfer진행
Batch normalization

-
배치사이즈 만큼 각각의 채널별로 정규화를 한다
-
r, b는 알아서 학습된다
-
추론할 때 유명한 statistics로 대체하여 사용하기 때문에 트레이닝하는 동안과 불일치가 나올 수 있다
Instance Normalization

- 각각의 이미지와 각각의 채널에 대해서 개별적으로 수행된다
- cnn에서 사용시에도 BN보다 IN을 사용할 떄 더 좋은 결과가 나왔다
Conditional Instance Normalization

- 스타일 개수만큼 IN을 사용하자 ->CIN
- 감마와 벡터를 스타일 개수만큼 사용
Interpreting Instance Normalization

- IN이 스타일 정규화에 영향을 끼친다
- IN이 대비 정규화에 영향이 끼친다고 생각했는데
- mean과 variance를 다루는 것이 스타일을 정규화 하는데 영향을 끼친다
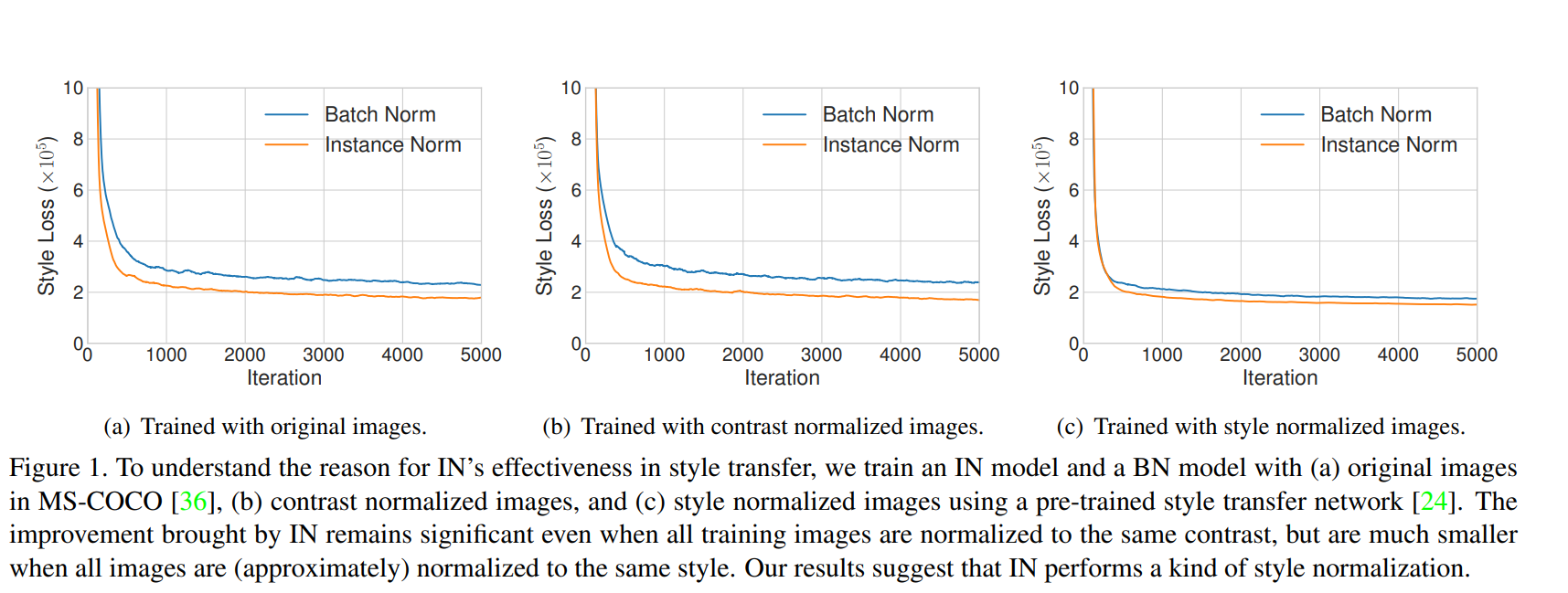

- BN은 배치에 포함되어 있는 하나의 스타일로 정규화가 된다
-> 하나의 이미지에 다른 스타일도 있을 수 있기에 IN에 비해 스타일 정규화에 안좋다
Adaptive Instance Normalization

- Adain을 통해 r를 y의 표준편차와 평균으로 정규화
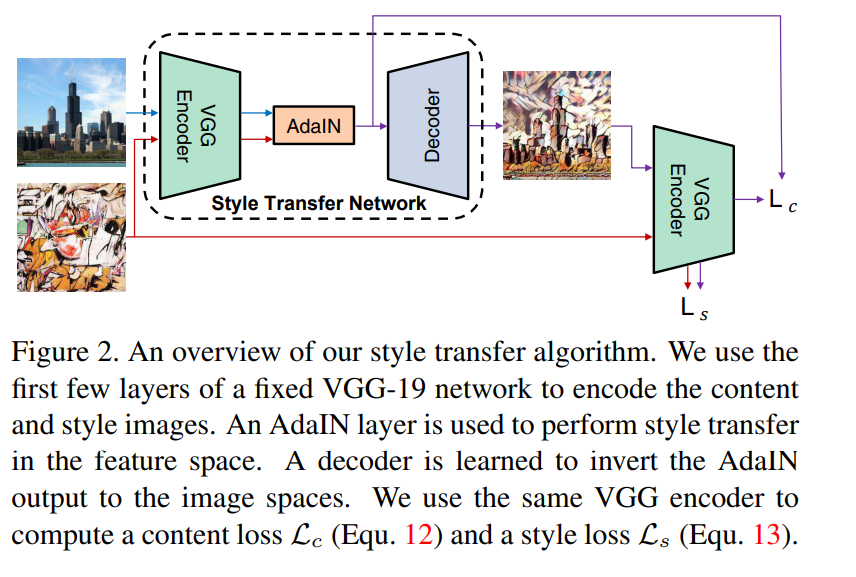
- 사전학습된 VGG를 사용하고 decorder가 학습
Architecture

- encorder f를 특정레이어까지만 사용하고 VGG인 학습된 네트워크 사용
- Adain에 학습된 CNN네트워크에 content와 style를 넣고 나온 t값을 decorder에
- encorder학습된 vgg네트워크 이므로 decorder도 동일하게
- adain레이어에서 스타일 트랜스퍼가 진행됐기에 decorder에서 정규화를 수행하지 않아도 된다
Training

- 어떤 로스에 더 가중치를 둘지를 람다로 사용
- 컨텐트 로스는 : 아다인 결과 나온 t를 다시 디코더에 넣고 다시 인코더에 넣어 feature를 뽑아내고(스타일 전이가 일어난 이미지의 feature를 뽑아낸것 ) 처음 아다인으로 뽑은 t와 비교하여 같게 한다
- 스타일 로스는 : 각각의 평균과 표준편차 즉 statistic을 의미
원본 스타일 이미지의 정보가 같아지도록 설정 - 그램메트릭스보다 개념적으로 쉽게 이해된다 결과는 비슷

Runtime controls
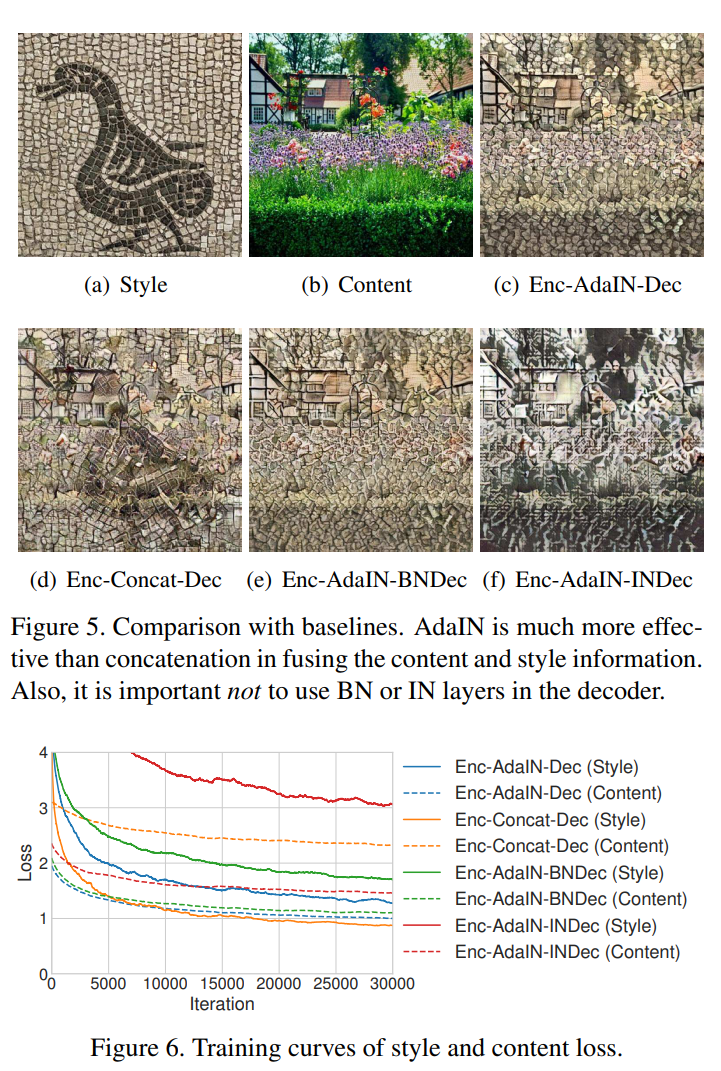
- IN/ BN레이어를 사용하지 않는 것이 더 좋았다 스타일이 정규화되기 때문에
- adain쓰고 디코더를 했을 때 가장 좋은 결과가 나온다

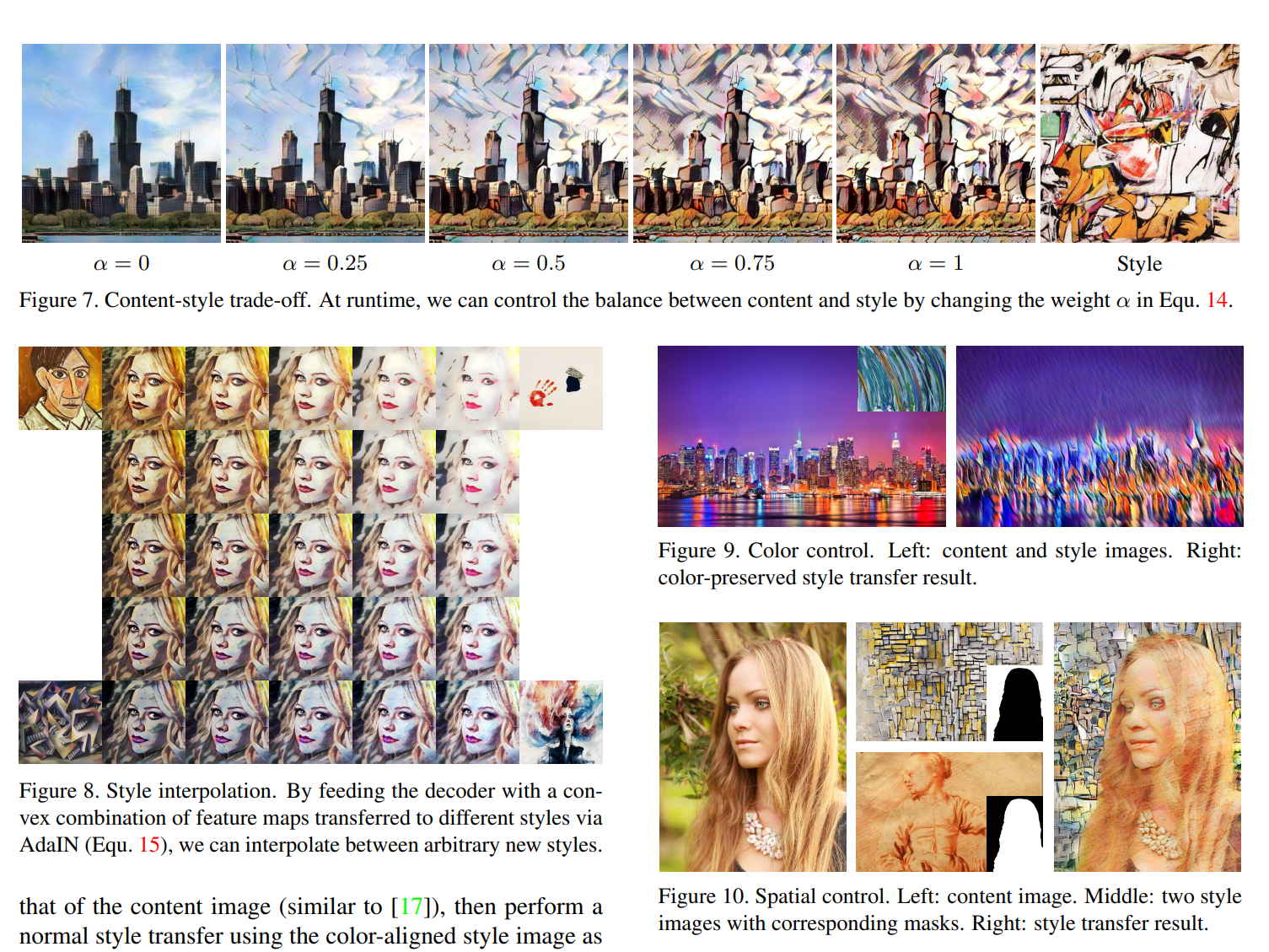
- adain을 수행한 결과와 기존 content feature값을 보간하여 어떤것에 가중치를 더 줄지 가능 0에 가까울 수록 content이미지 강해짐
- k개의 이미지를 보간 가능하다

안녕하세요