GAN
- 기존의 지도학습의 경우 데이터셋이 필수적으로 수반된다. 이러한 데이터셋을 만드는 과정에 드는 시간 등의 비용의 한계가 있다
- Gan은 지도학습에 사용되는 라벨 없이도 학습 가능한 비지도학습, 데이터를 직접 생성하는 큰 장점
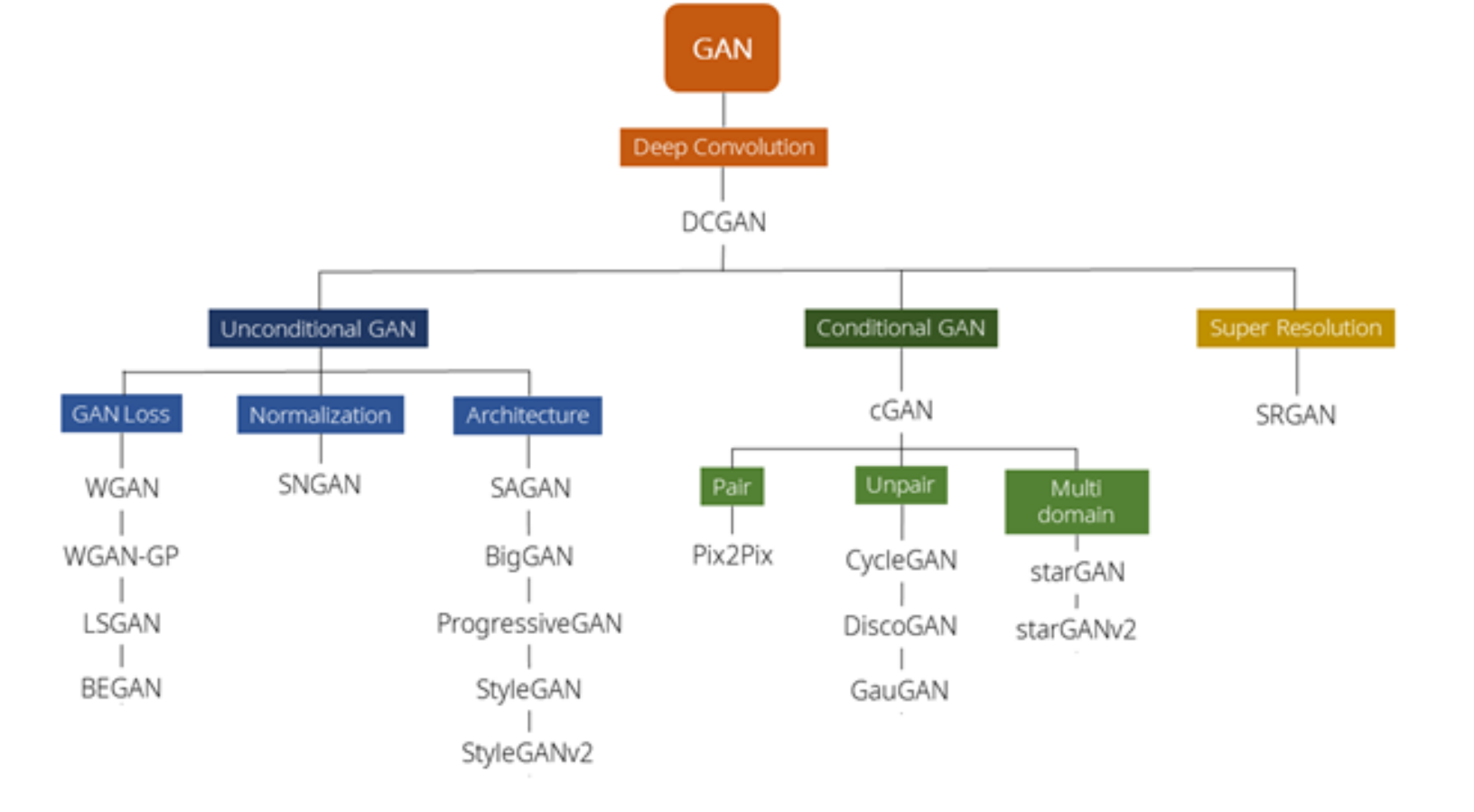
GAN의 분류체계
-
블로그
-
DCGAN : Facebook은 DCGAN을 통해 모든 후속연구가 이어질 수 있도록 키운 모델
-
LSGAN : 기존 GAN에 적용된 Loss의 수시을 LeastSquareloss로 바꾸어 성능 향상을 도모한 모델
-
PGGAN : 기존 모델과 달리 점진적으로 학습하여 1024x1024의 고화질 이미지 생성을 가능하게한 모델
-
SRGAN : GAN모델의 인지적 해상도를 높여 고화질 이미지 생성을 가능하게 한 모델
-
CycleGan: 역함수 개념과 순환일관성 손실함수를 이용해 특정 이미지의 화풍을 다른 이미지에 적용할 수 있게 한 모델
-
StarGan: 단일 생성자/판별자로 Domain Transfer가 가능하도록 만든 모델
기본적인 GAN
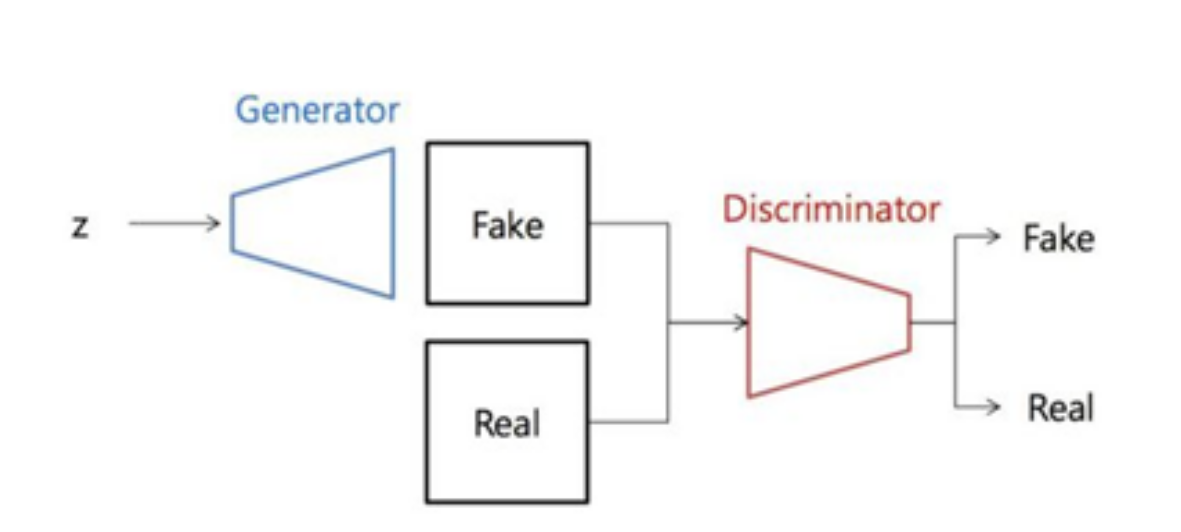
- 두개의 모델 Genreator과 Discriminator이 있고 두개의 모델이 동시에 훈련하는 것
- Z는 렌덤 백터를 의미
- Generator의 입력으로 렌덤벡터 z를 넣어 fake를 생성
이후 Real의 경우 실제 데이터셋을 의미하는 것으로 생성된 Fake와 실제 Real이미지를 Discriminator의 입력으로 넣게 되면 Fake또는 Real출력 - 최종 출력인 Fake와 Real의 확률이 1/2에 수렴하여 진짜 가짜 구분 못하게 한다
확률분포
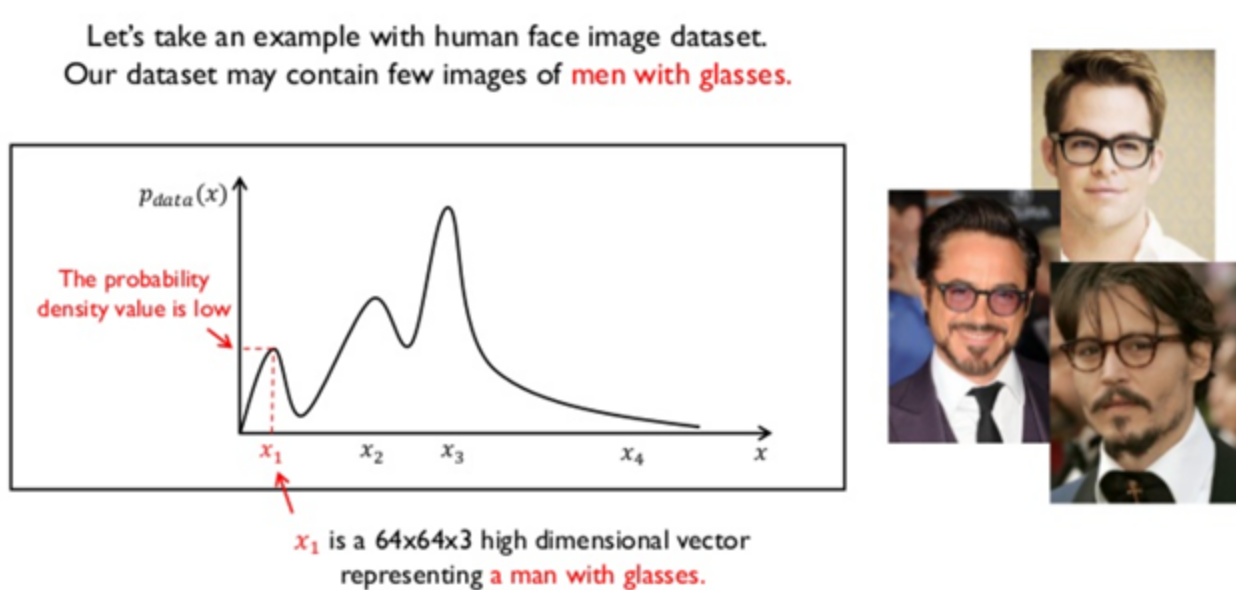
- GAN모델에 안경을 낀 남성의 데이터를 학습시킨 경우 남성의 특징을 x1이라고 하는 벡터가 가지게 된다
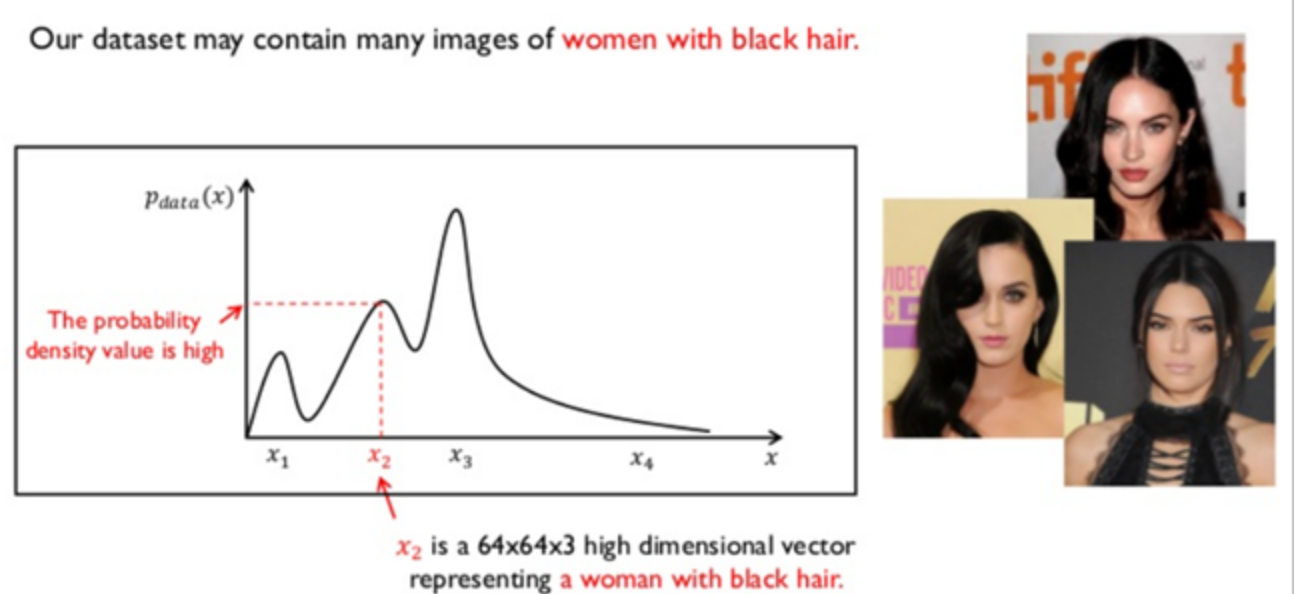
- 흑발 여성에 대한 특징을 x2라고 하는 벡터가 가지게 된다
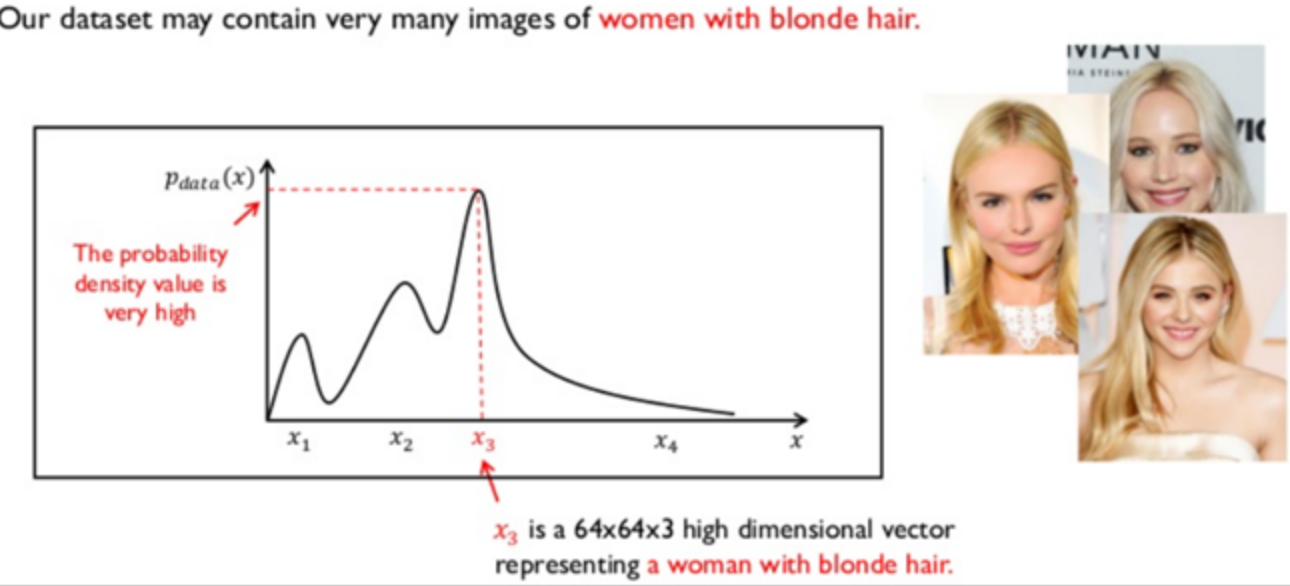
- 금발 여성에 대한 특징을 x3라고 하는 벡터에 학습시키게 된다
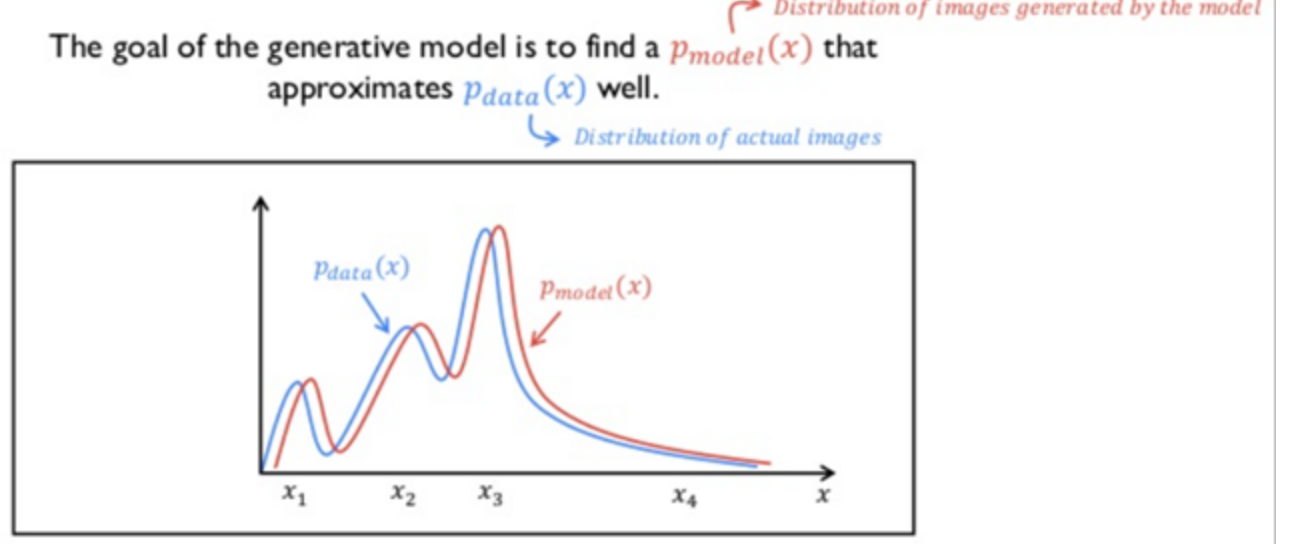
- 이렇게 학습된 확률밀도 함수가 있을 때, 아래와 같이 GAN모델이 생성한 이미지가 가지는 확률밀도함수와 둘 사이의 차이가 줄어들 수록 원래의 실제 이미지와 같아지는 원리
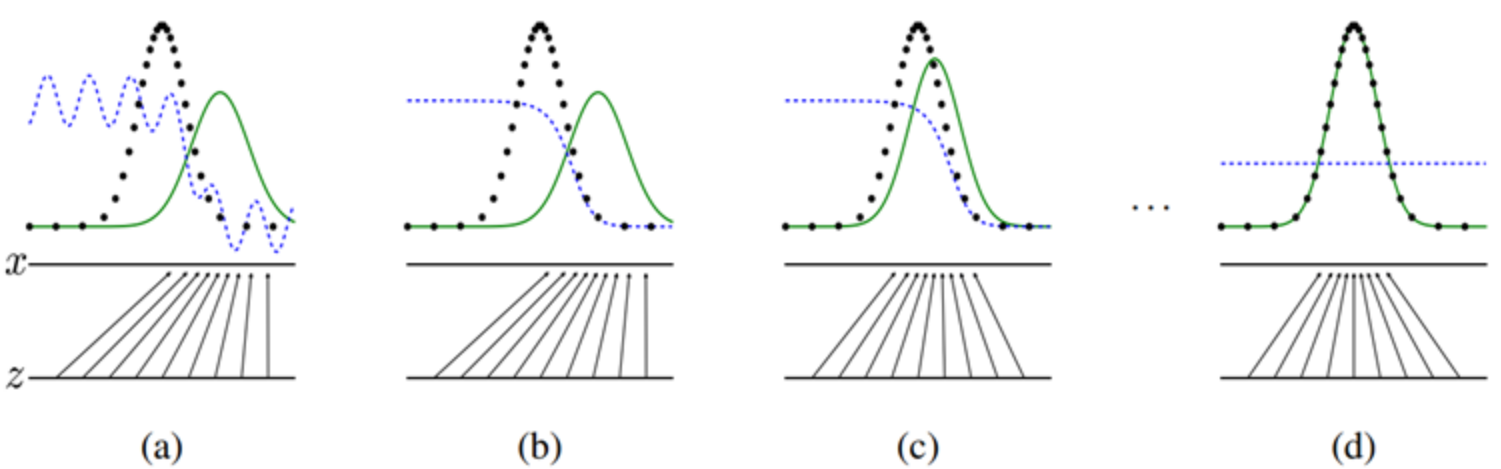
-
검은 점선: 원데이터의 확률분포
-
녹색: 생성자가 만들어 내는 확률분포
-
파란: 판별자의 확률분포
-
d단계에서는 real/fake를 분류하게 되어도 확률이 같기 때문에 분류를 해도 소용 없게 되며 생성자는 실제 데이터와 매우 흡사하게 이미지를 생성할 수 있게 된다
-
확률변수가 특정한 값을 가질 확률을 나타내는 함수
-
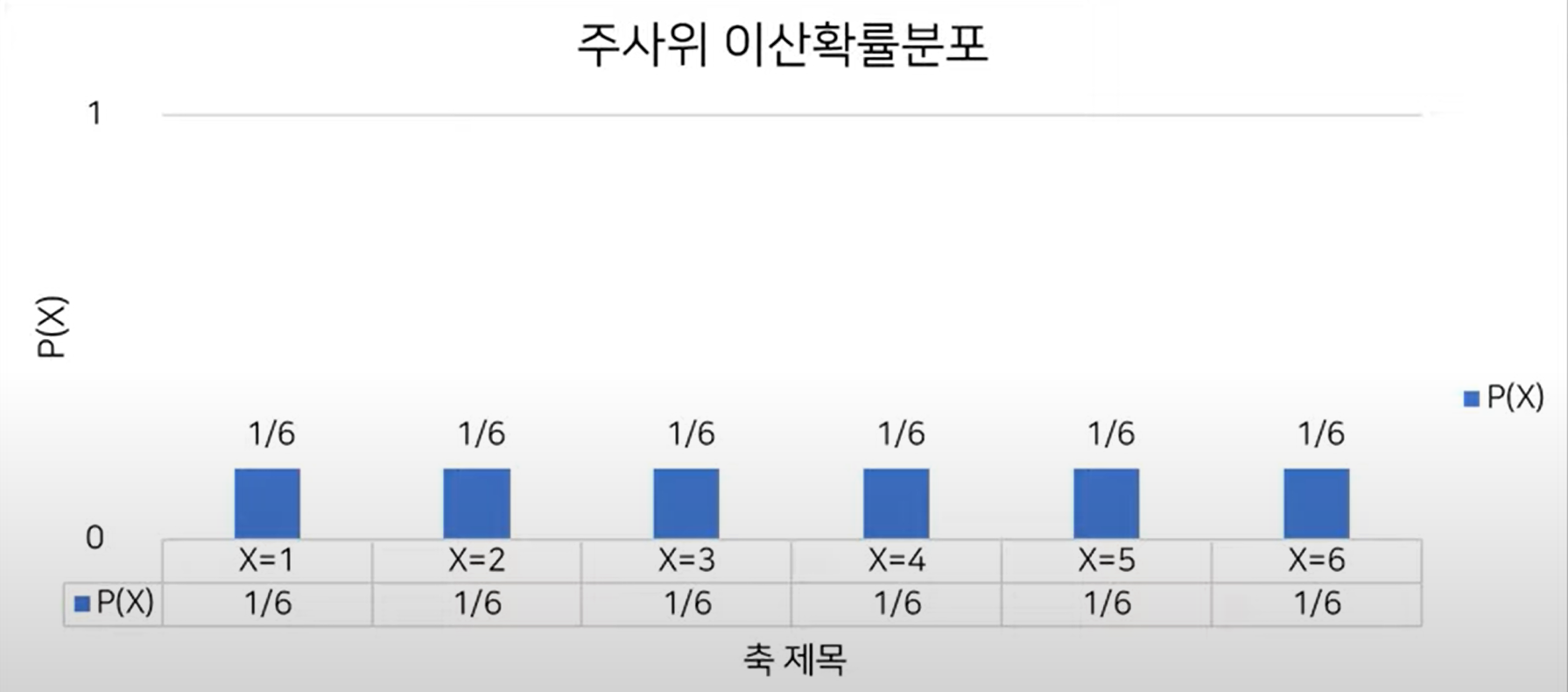
주사위 경우 6개의 눈이 있으므로 1/6의 확률을 같는다.
이산확률분포
- 확률변수 x의 개수를 정확히 셀 수 있을 때 이산확률분포라고 한다.
- 주사위 눈금 x의 확률 분포는 다음과 같다
연속확률분포
- 확률변수 x의 개수를 정확히 셀 수 없을 때 연속확률분포라 한다.
- 연속적인 값 예시: 키, 달리기 성적
이미지 데이터에 대한 확률분포
- 이미지 데이터는 다차원 특징 공간의 한 점으로 표현된다
- 사람의 얼굴에는 통계적인 평균치가 존재할 수 있다(목의 길이, 얼굴 크기 등)
- 모델은 이를 수치적으로 표현할 수 있게 된다
다변수 확률분포
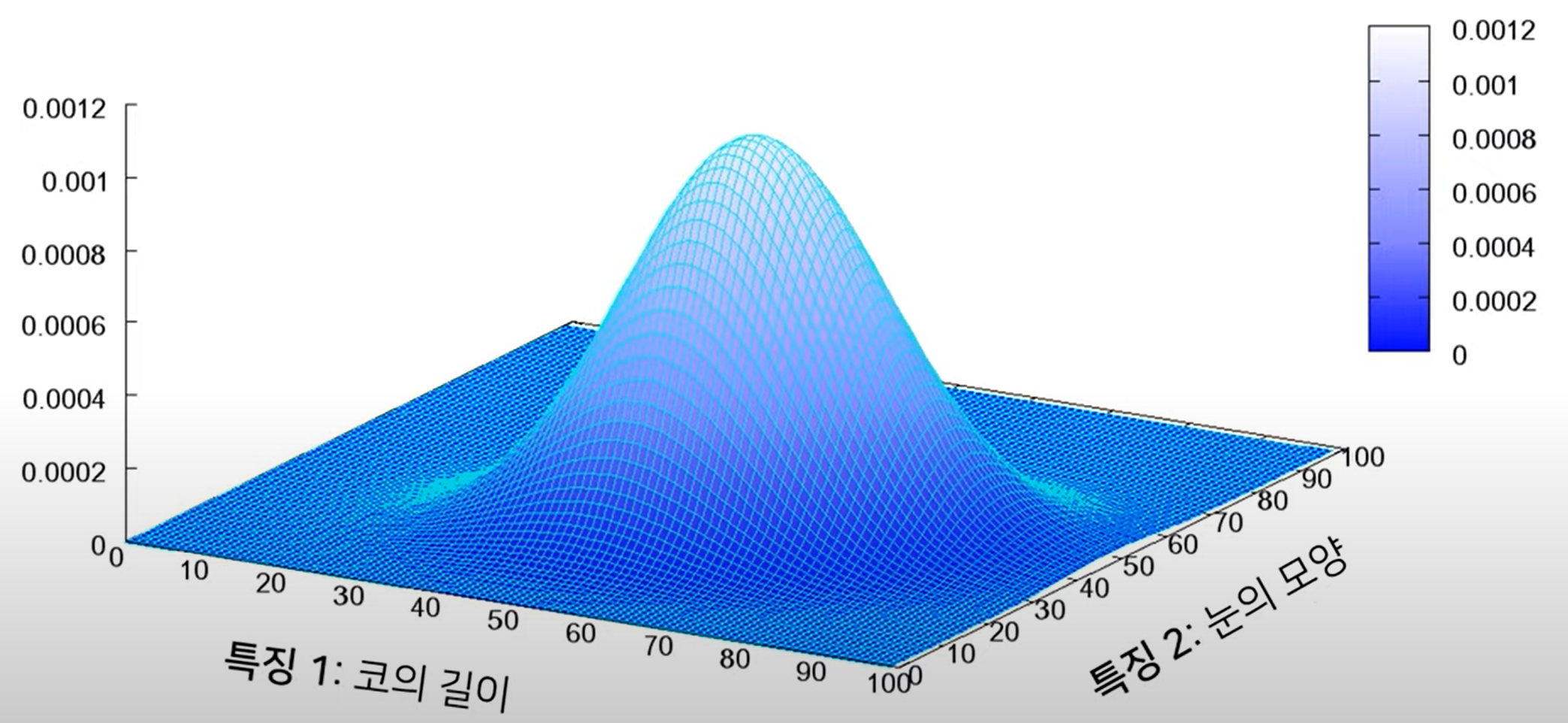
생성모델
실존하지 않지만 있을 법한 이미지를 생성할 수 있는 모델
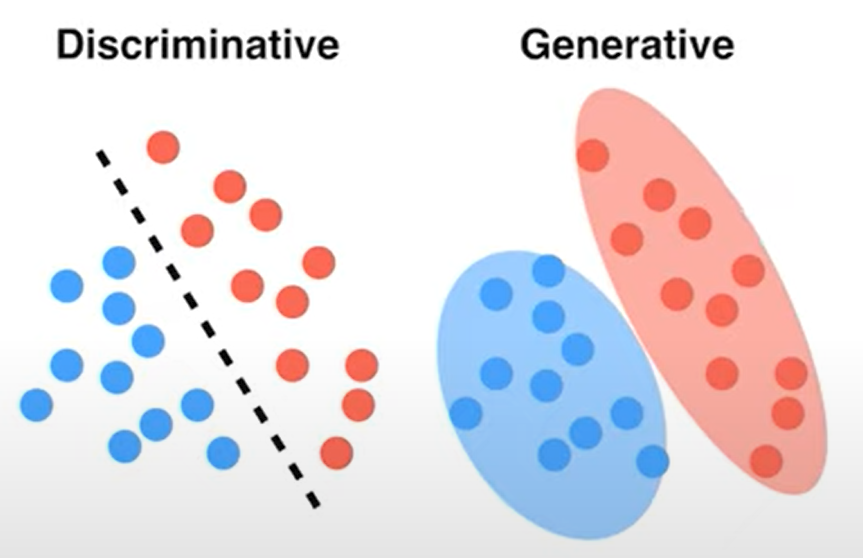
- Discriminative 분류 모델: decision 바운더리를 통해 나눈다.
- Generative: 각각의 클래스에 대해서 분포를 학습
확률분포를 잘 학습시킬 수 있다면 통계적인 수치를 내제가능
목표
- 이미지 데이터의 분포를 근사하는 모델 G를 만드는 것이 생성 모델의 목표
- 원래 이미지들의 분포를 잘 모델링 할 수 있다는 것을 의미한다
- 학습이 잘 되었다면 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성가능
Generative Adversarial Networks(GAN)
- 생성자와 판별자 두 개의 네트워크를 활용한 생성모델
- 다음의 목적함수를 통한 생성자는 이미지 분포를 학습 가능
목적함수
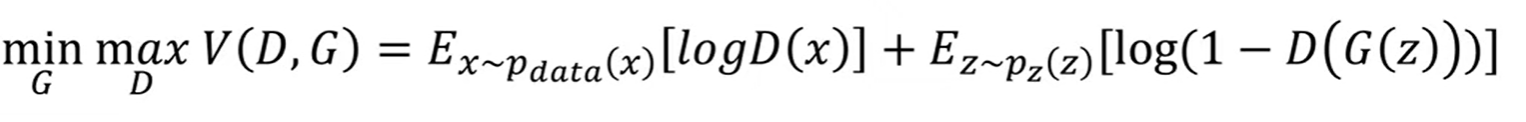
- V라는 함수의 D는 높이려하고 G는 낮추려고한다
- P data는 원본데이터를 뜻하고 한개의 데이터 x를 꺼내어 logD(x)기댓값 평균값을 구하겠다(판별자)
- 오른쪽은 생성자와 관련이 있고 노이즈 벡터로 부터 하나를 뽑아내고 G(z)에 넣어 가짜 이미지를 만들고 D()에 넣고 1에서 뺸 평균값
기댓값 공식
- 모든 사건에 대해 확률을 곱하면서 더하여 계산

출처:
https://www.youtube.com/watch?v=AVvlDmhHgC4
https://www.youtube.com/watch?v=odpjk7_tGY0
https://roytravel.tistory.com/109

안녕하세요