
-
depth의 깊이가 모델의 성능에 큰 영향을 준다는 것을 알 수 있는데
depth가 올라감에 따라 발생하는 문제가 오버피팅, gradient소멸, 연산량 증가 있습니다. -
간략하게 보자면 오버피팅은 학습한게 특정 데이터에 너무 정확하게 일치하여 추가 데이터나
미래 관찰에 대해서 잘 예측하지 못하는 것이고 -
gradient소멸은 활성함수 역전파 과정에서 출렧에서 입력으로 갈 수록 기울기가 작아져서 0에 수렴하는 것인데
은닉층을 지날 수록 오차가 크게 줄어 학습이 안되는데 이를 기울기 소멸 -
해결방법으로 resnet을 제안했습니다
-
depth 깊이가 중요해지면서 레이어를 쌓는 만큼 더 쉽게 네트워크 학습시킬 수 있는지 의문을 갖게 됐고
vanishing/exploding gradinet현상이 방해요소 -
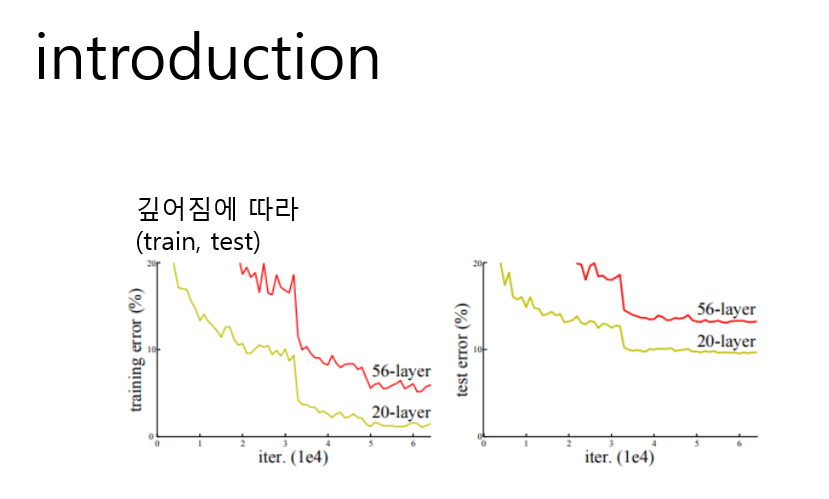
심층 신경망의 성능이 최고수준 도달시 degradation문제 발생
디르레데이션이란 깊어짐에 따라 정확도 급속하게 감소 하는것인데 -
train과 test가 에러가 같이 높어자셔 오버피팅문제가 아니라 그저 layer수가 추가 되면서
underfitting문제가 발생한것이고 이는 최적화 방식의 문제를 뜻합니다
-
심층모델에서 제한된 상황에서 최적화 가능한데 이 방법은 추가된 레이어가 identity mapping이고, 추가되지
않은 다른 레이어들은 더 얕은 모델에서 학습된 layer를 사용하는 것 -
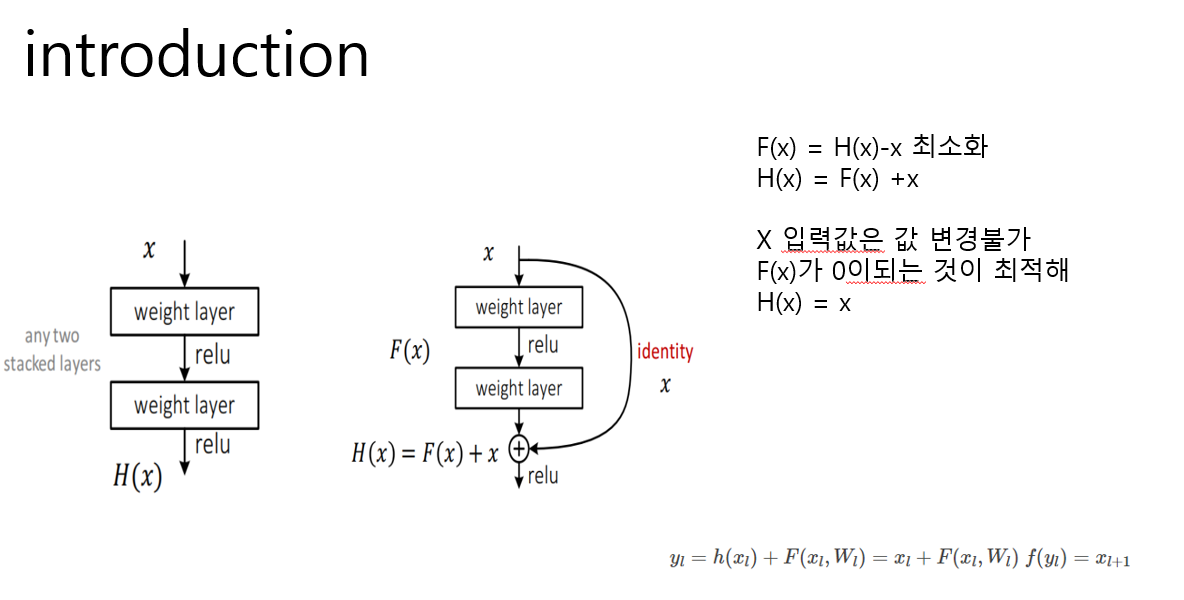
기존 신경망 cnn같은 것은 입력 들어온x가 weight layer(conv layer와 동치) 지나가고 활성화 함수 통과해
최정적인 형태 H(x)를 최적화를 목표로 한다 -
레지넷은 출력과 입력차인 H(x)-x 얻로록 수정
입력인 x는 현시점에서 변할 수 없는 값이므로
f(x)를 0에 가깝게 만드는 것이 목적이다
f(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 된다
즉, h(x)=x로 메핑하는것이 목표로 하는 방법입니다 -
입력에서 출력으로 바로 연결되는 shortcut만 추가 하면 된다 입력과 같은
x가 그대로 출력에 연결되기에 파라미터 수에 영향 없고, 덧셈이 늘어나는것 제외하면
shortcut연결을 통한 연산량 증가없다 역전파 단순해져 기울기소멸 문제 해결 가능

-
이전은 알지 못하는 최적값으로 H(x)를 매핑 해야했는데 위와 같은 결과로
H(x)=x라는 최적의 목표값이 사전에 알 수 있으므로 f(x)학습이 쉬워졌다 -
실제로는 아이덴티 메핑이 최적일 가능성이 낮지만 레지넷에서 재구성하는 방식을 통해 H(x)=x라는 최적의 목표값이
사전에 알게하고 최적화 하는 방법이 기존에 알지 못하는 최적값으로 H(x)를 매핑하는 것보다 학습하는데
더 효율적이라고 합니다
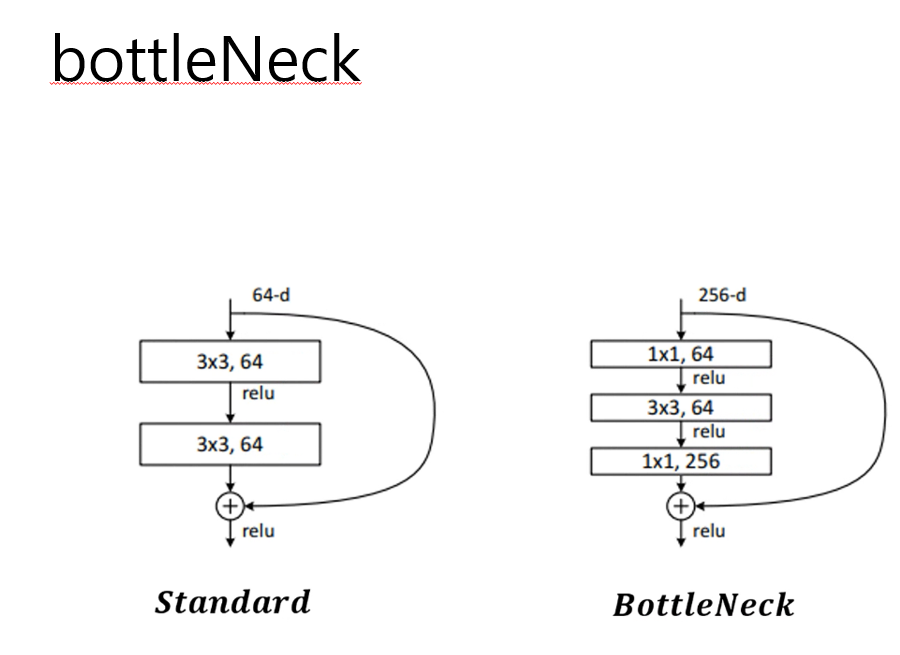
- 레즈넷은 bottleneck shortcut방식으로 깊게 쌓을 수 있습니다.
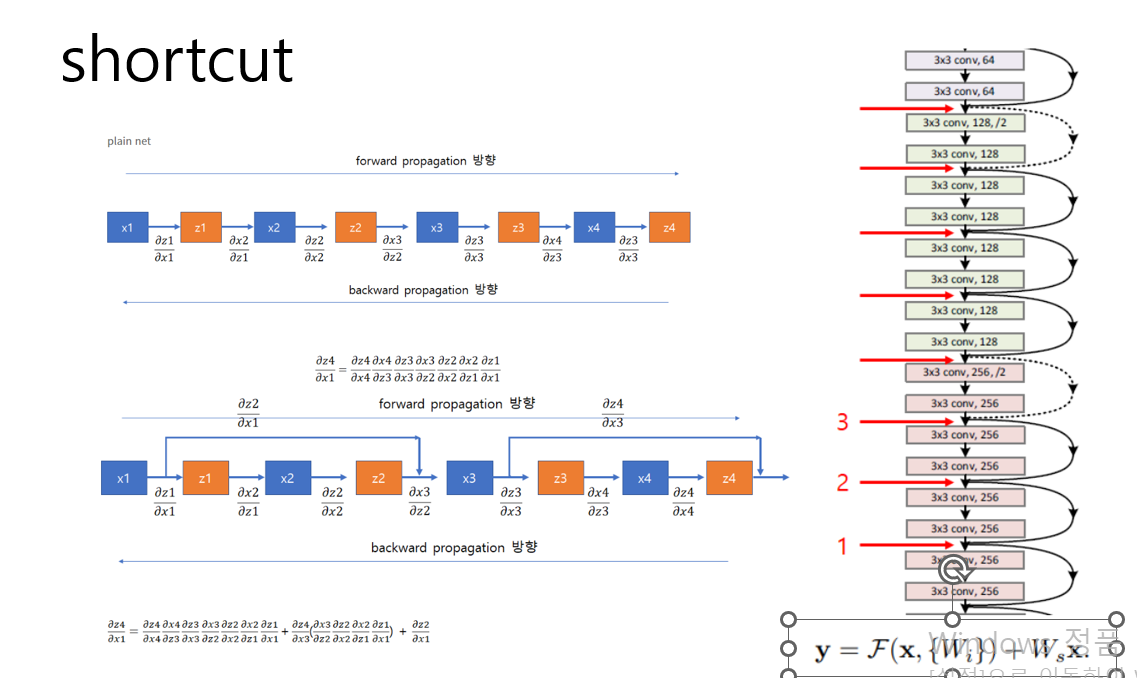
먼저 shortcut을 보면
일반적 plain net은 기울기는 앞 레이어에 의존적이다 0에 가깝다면 전체는 0에 수렴
레즈넷은 덧셈관계이기 때문에 반드시 0에 수렴하는 것이 아니다
사진을 보면 shortcuts(block을 학습하지 않고 다음 block으로 보내는 방식을 )을
편미분하기에(상수값) 최소 1이상이 넘어오기에 vanishing문제 해결
shortcut 파라미터나 연산 복잡성 추가 안함 ws는 차원을 매핑 시켜줄 때만 사용
즉,덧셈연산량이 증가할 뿐 파라미터 수에는 영향없으며 많은 수의 레이어 갖는 깊은 모델도 빠르고 잘 학습가능
-
bottleneck block은 레이어수가 많아졌지만 복잡성은 줄어들게 됐습니다
레이어가 많아짐에 따라 활성화 함수가 기존보다 많이 들어가게 되고
이는 입력값을 다양하게 가공할 수 있다는 것을 의미하게 됩니다 -
위와 같은 방법으로 레즈넷은 기존보다 깊게 레이어를 쌓을 수 있게 됐습니다

