(웹 서비스는 모자이크 처리하였습니다.)
실시간 API를 받아서 자료를 조회하고, 자료를 다운로드 받을 수 있는 웹 페이지를 제작하였다.
이 웹 페이지에서 매일의 데이터를 조회하고 자동으로 클라우드에 저장하기 위한 워크플로우를 구성하였다.
📍종합적인 워크 플로우
- EC2 인스턴스에서 Flask 애플리케이션을 실행한다.
- Flask 애플리케이션에 CSV 파일 생성 및 다운로드 기능을 구현한다.
- Lambda와 CloudWatch Events 트리거를 설정하여 특정 시간에 서버를
cronjob을 설정하여 특정 시간에 Flask 애플리케이션의 엔드포인트를 호출한다. - 해당 엔드포인트는 CSV 파일을 생성하고, S3 버킷에 업로드한다.
1. AWS EC2 설정
• EC2: Flask 애플리케이션을 배포하기 위해 AWS EC2 인스턴스를 사용한다. EC2 인스턴스에서 Flask 웹 애플리케이션을 실행한다.
• S3: 생성된 CSV 파일을 저장하는데 AWS S3를 사용한다. S3는 내구성이 높고 안정적인 파일 저장소로, 파일을 장기적으로 보관하는 데 적합하다.
2. Flask 애플리케이션 구현
• CSV 생성 기능: Flask 애플리케이션에 특정 엔드포인트에 접속하면 클라이언트에게 응답으로 csv 파일을 주도록 구현한다.
3. 자동화 작업 설정
• 람다(Lambda): 특정 시간에 EC2 인스턴스를 시작하거나 중지하도록 설정한다. Lambda는 이벤트 기반으로 작동하는 서버리스 컴퓨팅 시스템으로 특정 이벤트나 트리거가 발생하는 등 필요할 때 자동 실행되고, 실행이 끝나면 리소스를 자동으로 해제하여 비용이 발생하지 않는다.
• Amazon EventBridge: lambda를 실행하도록 이벤트 트리커를 생성한다. 근무 시간에 맞추어 9시부터 5시까지 인스턴스 실행과 중지를 실행하는 람다 함수를 실행할 수 있도록 설정한다.
• 크론잡(Cron Job): 서버에서 주기적으로 작업을 수행하기 위해 크론잡을 설정한다. 이 크론잡이 일정 시간에 Flask 엔드포인트를 호출하여 CSV 파일을 생성하고 다운로드한다.
• requests 라이브러리: 크론잡에서 Flask 애플리케이션의 특정 엔드포인트를 호출하기 위해 Python의 requests 라이브러리를 사용한다. 엔드포인트가 호출되면 Flask 애플리케이션이 CSV 파일을 생성하여 S3에 업로드하는 작업을 수행할 수 있습니다.
- AWS CloudTrail에서 lambda 함수가 잘 작동되고 있는지 이벤트 기록-> 이벤트 이름-> StartInstances(이벤트 트리거 이름)로 검색해보면 알 수 있다.
4. CSV 파일 저장
• AWS SDK (Boto3): Flask 애플리케이션 내에서 Boto3를 사용하여 생성된 CSV 파일을 S3 버킷에 업로드한다. 업로드 후, S3에서 파일을 다운로드하거나 필요한 작업을 할 수 있다.
실제 구현 과정
1. AWS EC2 설정
- ubuntu로 AWS EC2에 접속하고, python, flask 외 필요한 라이브러리를 다운받고, 가상환경을 구축한다. 이후 git clone하여 코드를 받는다.
- 참고: https://velog.io/@jaehyeong/Flask-%EC%9B%B9-%EC%84%9C%EB%B2%84-AWS-EC2%EC%97%90-%EB%B0%B0%ED%8F%AC%ED%95%98%EA%B8%B0
- Flask warning에 관하여:
https://stackoverflow.com/questions/50284753/warning-message-while-running-flask
(보안상으로 wsgi 등 서버를 연결하는 것이 좋을 수 있다. 하지만 간단한 웹의 경우 경고를 무시해도 될 정도로 문제 없다.)
2. Flask 애플리케이션 구현
<app.py 중 일부>
@app.route('/download_SK-data', methods=['GET'])
def download_skData():
try:
# 조회할 수 있는 날짜 중 가장 첫 날을 조회
current_datetime = datetime.now() # 오늘 날짜와 시간을 datetime 객체로 변환
new_datetime = current_datetime - timedelta(days=29) # 날짜를 29일 전으로 변경
date = new_datetime.strftime("%Y%m%d")
dow=custom_weekday(date) #날짜를 통해 요일을 구하여 dow에 저장
# 최종 zip 파일을 메모리에 생성
final_zip_buffer = BytesIO()
with zipfile.ZipFile(final_zip_buffer, 'w', zipfile.ZIP_DEFLATED) as final_zip_file:
for hour in range(5,24): # 05 ~ 23시까지 time으로 입력
time = f"{hour:02d}"
# show_skData와 동일
exitData = forRawDataExitHeadCount_data(date, time)
carHeadCount_1= forRawData_carHeadCount_Line1(dow,time)
carHeadCount_4= forRawData_carHeadCount_Line4(dow,time)
congestionRatio_1 =forRawData_congestionRatio_Line1(dow, time)
congestionRatio_4 =forRawData_congestionRatio_Line4(dow, time)
# 각 시간대의 데이터를 처리하여 zip 파일 생성
time_zip_buffer = sk_data_processing.process_data_and_generate_csvs(exitData, carHeadCount_1, carHeadCount_4, congestionRatio_1, congestionRatio_4, date, time)
time_zip_filename=f"skData_{date}{time}.zip" # zip 파일 이름 설정
time_zip_buffer.seek(0) # 각 시간대 zip 파일의 포인터를 맨 처음으로 이동
final_zip_file.writestr(time_zip_filename, time_zip_buffer.read()) # 최종 zip 파일에 각 시간의 zip 파일을 저장
# 최종 zip 파일의 포인터를 맨 처음으로 이동
final_zip_buffer.seek(0)
bucket_name = "odmatrix"
s3_filename= f"Day_skData_{date}.zip"
upload_csv.upload_to_s3(final_zip_buffer, bucket_name, s3_filename)
# 클라이언트에게 파일 전송
return jsonify({"message":"sucess"})
except Exception as e:
print(f"Error during processing: {e}")
return jsonify({"error": "Failed to process request"}), 500
<upload_csv.py>
import boto3
import requests
from io import BytesIO
import re
from datetime import datetime, timedelta
def upload_to_s3(file_obj, bucket_name, s3_filename):
s3 = boto3.client(
service_name ="s3",
region_name= "ap-northeast-2"
)
try:
s3.upload_fileobj(file_obj, bucket_name, s3_filename)
print(f"File has been uploaded to {bucket_name}/{s3_filename}")
except Exception as e:
print(f"Failed to upload file to S3: {e}")
- S3의 경우 IAM 역할을 추가하여 접근 가능하도록 하였다.
3. 자동화 작업 설정
<cronjob 설정>
crontab -e 명령어를 입력하고
5 9 *** 로 수정하여 9시 5분마다 script가 실행되도록 하였다.
주의할 점
ec2 서버 시간이 UTC 기준으로 설정되어 있어 cronjob이 원하는대로 동작하지 않을 수 있다.
위 두 명령어를 입력하고 date를 통해 현재 한국 시간과 일치하느지 확인한다.

<script.sh>
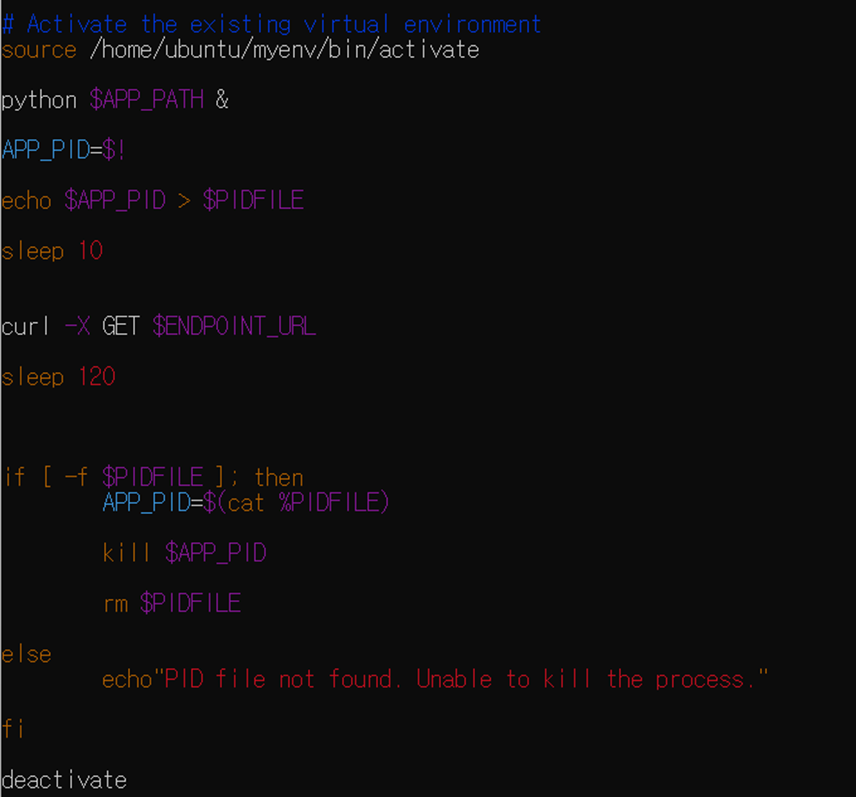
(APP_PATH, ENDPOINT_URL, PIDFILE은 따로 추가한다.
ex. APP_PATH="/home/ubuntu/krri/app.py")
설정한 시간에 가상환경 열기, 서버 열기, 엔드포인트 접속을 마치고 서버 닫고, 가상환경 닫기까지 설정하였다.
<lambda 함수 추가>

ec2 인스턴스를 시작하는 함수, 중지하는 함수를 만든다.
<StartEC2Insatance 함수>
import boto3
region = 'ap-northeast-2'
instance = 'Your-instance-ID'
ec2 = boto3.client('ec2', region_name=region)
def lambda_handler(event, context):
ec2.start_instances(InstanceIds=[instance])
print('started your instance: ' + instance)<StopEC2Insatance 함수>
import boto3
region = 'ap-northeast-2'
instance = 'Your-instance-ID'
ec2 = boto3.client('ec2', region_name=region)
def lambda_handler(event, context):
ec2.stop_instances(InstanceIds=[instance])
print('stop your instance: ' + instance)<AmazonEventBridge에서 lambda를 트리거할 수 있는 이벤트 생성>
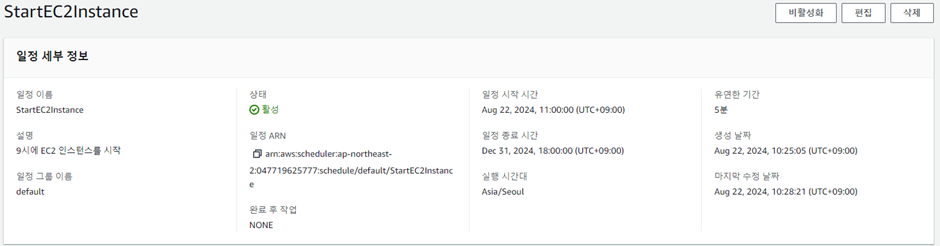
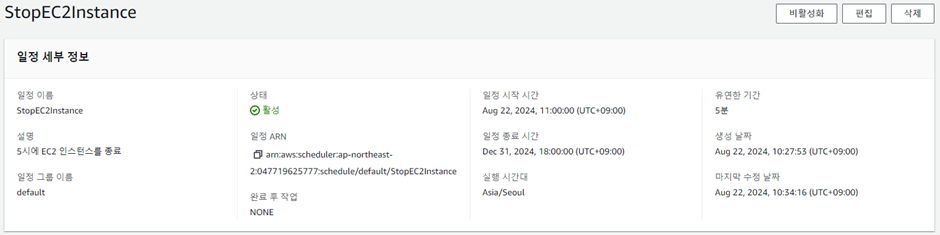
결과: S3에 파일 저장

매일 9시에 인스턴스를 시작하고 9시 5분에 서버 실행 후 엔드포인트에 접속하여 파일을 다운로드 하도록 설정하였고, 그대로 동작하여 S3에 파일이 저장된 것을 확인할 수 있다.
💭회고
- 주기적으로 자료 수집이 필요한 경우 자동화하여 시간과 노력을 줄일 수 있겠다는 생각이 들었다. 또한, 업무 시간에 맞추어 인스턴스를 시작하고 중지함으로써 만약 인스턴스를 중지하지 않았을 때 발생할 수 있는 비용도 줄일 수 있다는 점이 좋다고 생각한다.
- AWS의 서비스들을 이용하여 유기적인 연결이 쉽게 이루어졌고, 관리 또한 편하다는 점이 장점이라고 생각한다.
