어휘분석기에 원시 프로그램을 입력받을때, 어디부터 어디까지 하나의 어휘항목인지 구별을 해야 하고, 또한 하나의 어휘항목이 구별 되었을때 그 어휘항목이 올바른 어휘항목을 가졌다는 것을 확신해야 한다.이 작업들에 대한 프로세스는 생각보다 심플하니 가볍게 어떤 구조인지 한번 살펴보자.
어디까지가 하나의 어휘항목인가?
어휘분석기는 하나의 어휘항목을 구별해야 할때, 적어도 한 개 이상의 문자를 미리 볼 필요가 있는 많은 상황들이 있다. 예를 들어, 어떠한 식별자를 입력받았을때, 그 id의 어휘항목의 일부가 아닌 문자를 볼때까지는 그 식별자의 끝을 보았다고 확신할 수가 없다.
식별자 뿐만 아니다, C에서 -,= 또는 < 와 같은 단일 문자 연산자는 한개만 가지고서도 의미를 가질 수 있지만, -> , == , <= 와 같은 두개의 문자 연산자의 앞부분이 될 수 있다.
그리하여 어휘분석기는 모든 원시 프로그램의 문자들을 읽을 때, 어휘분석의 끝을 확신할 수 있는 근거로써 반드시 한개 이상의 문자를 더 추가적으로 미리 봐야 한다.
2개의 포인터를 사용해 어휘항목의 시작과 끝을 찾아낸다.
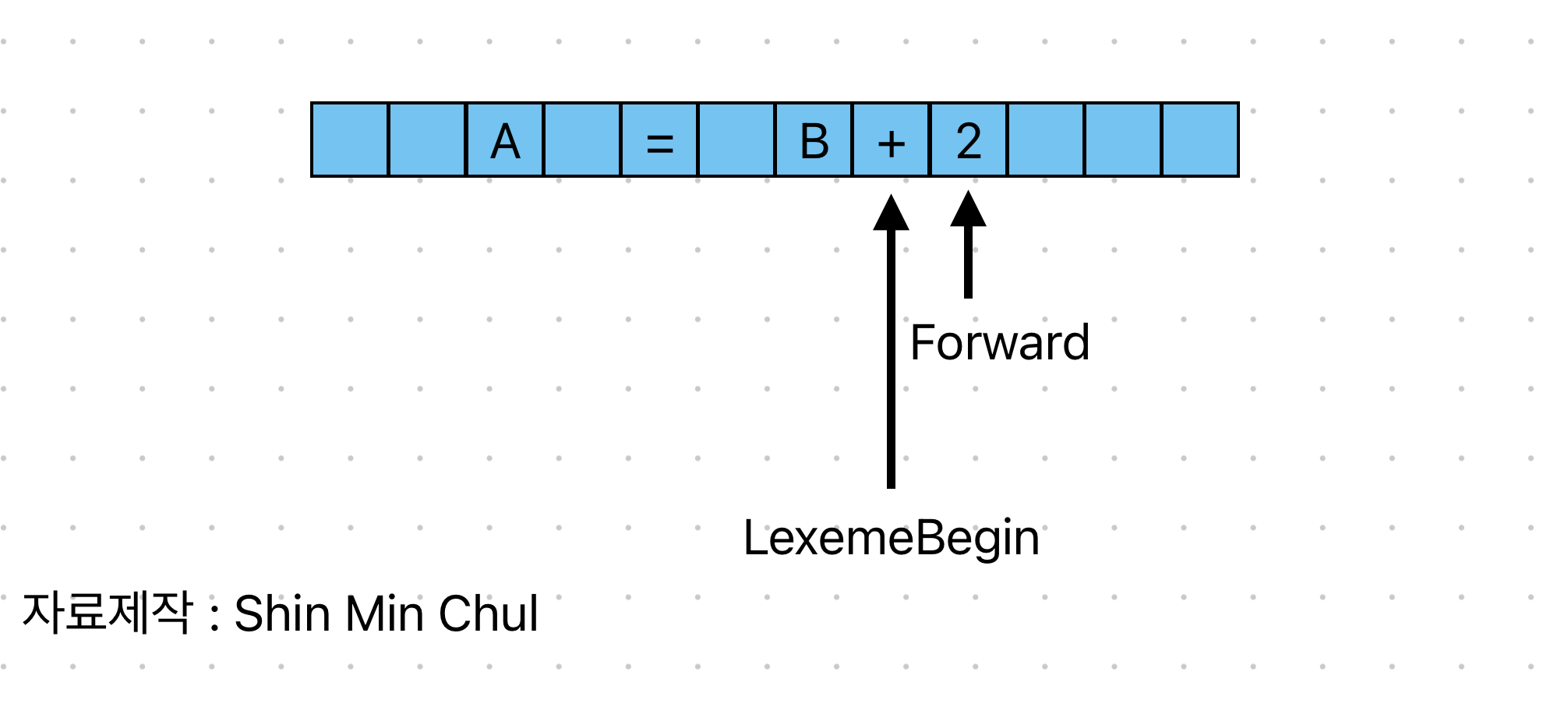
- lexemeBegin 포인터는 현재의 어휘항목(내용을 결정하려고 하는 어휘항목)의 시작을 표시한다.
- forward 포인터는 패턴 부합이 발견될 때까지 전방으로 스캔한다. 이런 결정이 행해지는 정확한 전략은 찾아보길 바란다.
키워드를 reserved(예약어)로 구별하지 않는다면?
우리가 현대의 프로그래밍 언어인 C,Java,Python 을 사용할때, while,if,for 과 같은 코드는 하나의 예악어로 정해두어, 해당 키워드들을 식별자로 사용할 수 없게 만들어 두는 경향이 있다. 왜냐하면 단순히 어휘 분석기에서 해당 키워드들을 식별자로 사용하게 되었을때, 매개변수를 갖는 프로시저 이름인지, 어떠한 실행 명령을 가진 키워드인지 확신할 수가 없는 문제에서 심플하고 단순하게 해결할 수 있기 때문이다.
그렇지 않게 된다면, 해당 키워드들을 모호한 식별자로 처리하고 파서에게 이런 문제를 해결할 수 있도록 설계를 해야만 한다.
