Lexical Analyzer(어휘분석기)는 컴파일러의 Front-end(전단부) 모델로써 일반적으로 맨처음에 가장 시작되는 파트로 알려져 있다. 그렇다면, 어휘분석기가 실제로 어떤 일들을 하는지 자세하게 한번 알아보자.
Scanning(스캐닝)
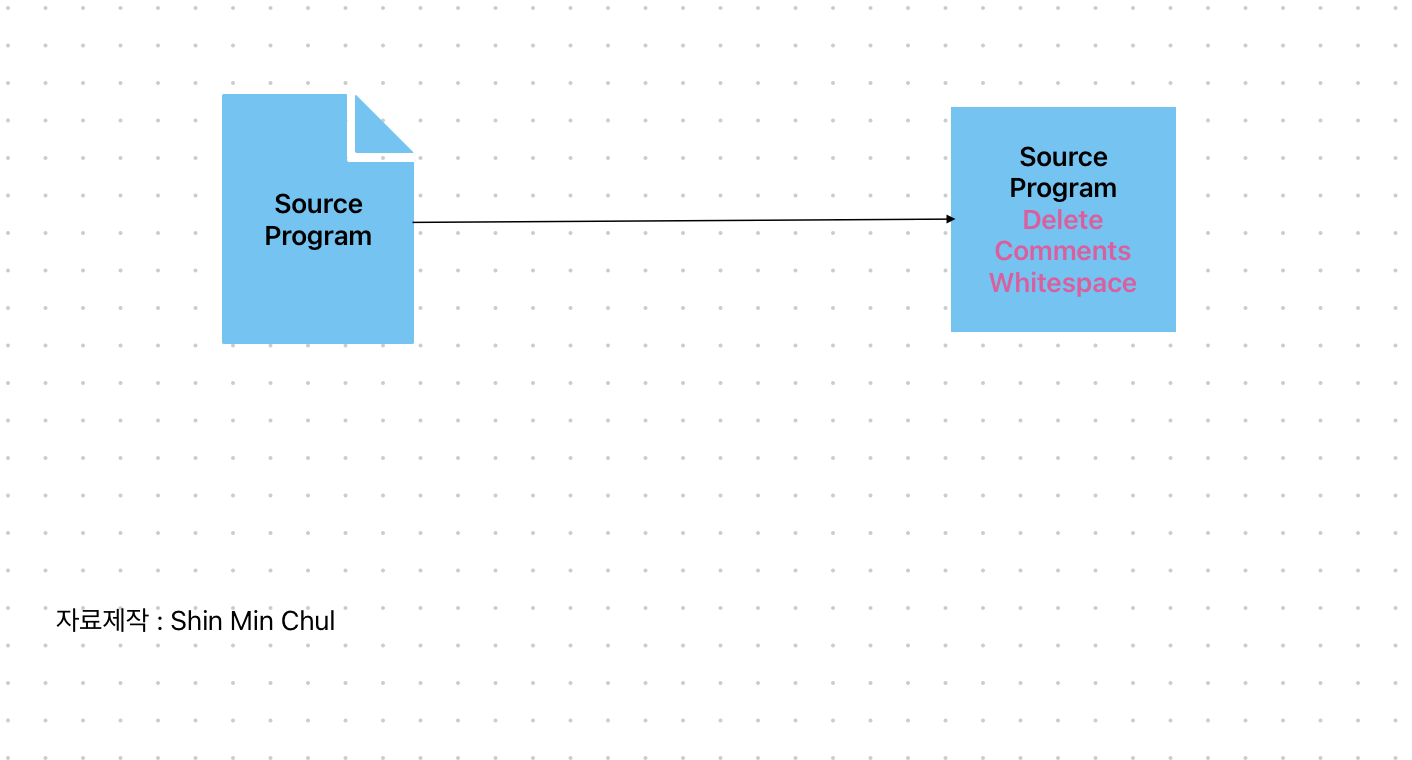
첫번째로, Scanning 작업을 실시한다. 해당 작업은 주석의 제거와 연속된 여백 문자들을 한개의 여백 문자로 대치하여 고유의 Lexical Analysis(어휘 분석) 파트에서 있을 토큰화 작업에서 추가적인 작업이 발생하지 않도록 한다.
고유의 어휘 분석은 매우 복잡한 부분으로 주로 파서에게 반환하기 위한 토큰화 작업을 뜻하고, 바로 다음 문단에 등장한다.
Lexical Analysis( 어휘 분석 )
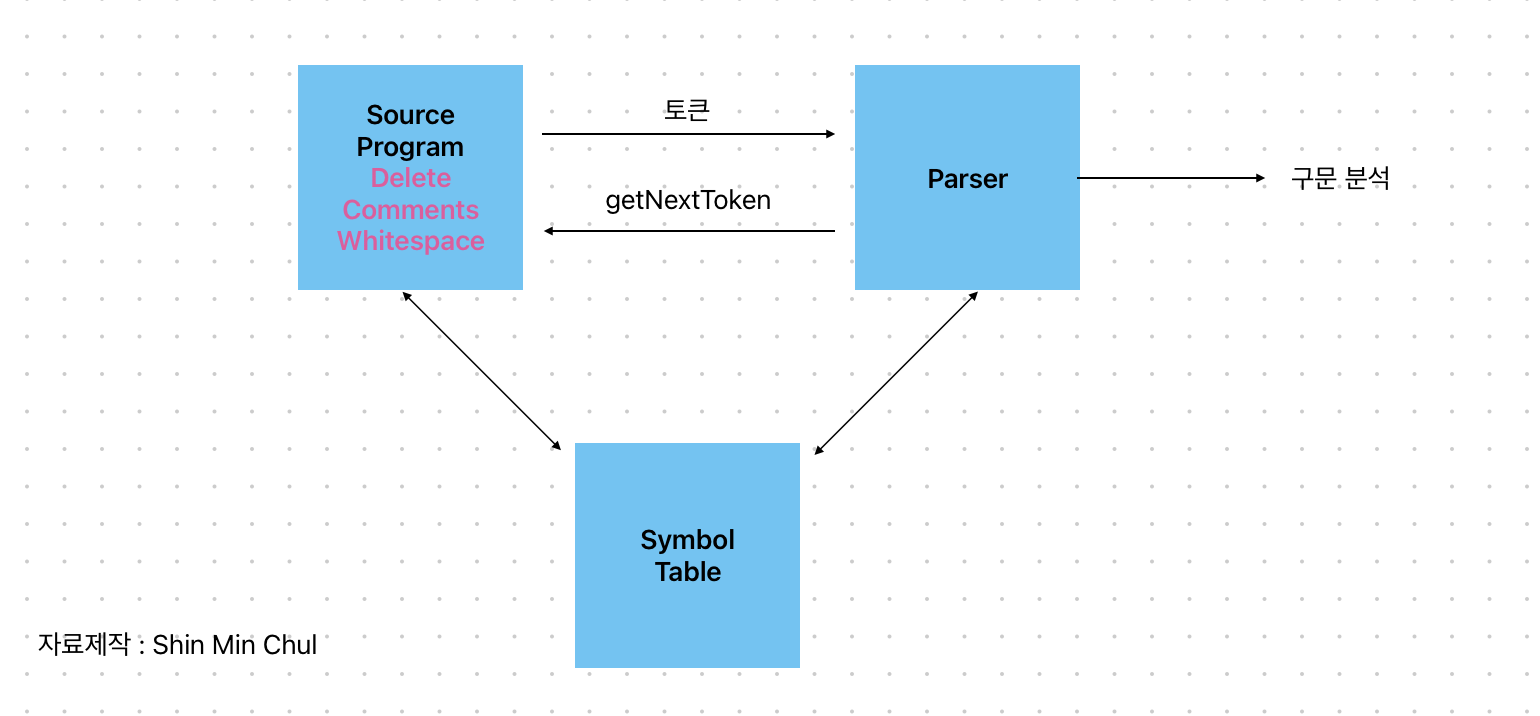
이 작업이 어휘 분석기에 있어서 핵심이며, 매우 복잡한 과정을 지니고 있다. 또한 스캐너의 출력으로 나오게 된 원시 프로그램을 가지고 작업을 진행하게 된다.
일반적인 상호작용 형태는, 파서가 getNextToken 명령으로 표현된 호출은 어휘 분석기가 다음 어휘항목을 발견할 때까지 입력으로부터 문자들을 읽어서 파서에게 반환하는 다음 토큰들을 생산하게 한다.
하지만 작업간에 어휘항목을 발견할 때 심볼 테이블에 넣는 것이 필요하다.
그 이유는 어휘 분석기만으로 토큰을 결정하는 것이 어렵기 때문에, 보조 기억장치 개념을 추가 사용하여 파서에게 전달해야 하는 적당한 토큰을 결정하는 것을 돕는다.
오류 메시지와 원시 프로그램을 서로 관련시킨다.
어휘 분석기는 원시 텍스트를 읽는 컴파일러의 부분이므로, 각 문자들이 어디 Line(라인)에서 등장했는지 추적할 수 있다.
그래서, 컴파일러 작업시에 오류가 발생했다면, 어휘분석기를 통해 오류 메시지와 원시 프로그램의 라인 번호를 연관시킴을 통해, 문제가 발생한 위치를 제공할 수 있다.
다른 방법으로는, 적당한 위치에 오류 메시지가 삽입된 원시 프로그램의 복사본을 만드는 경우도 있다.
어휘분석기의 일반적인 모델
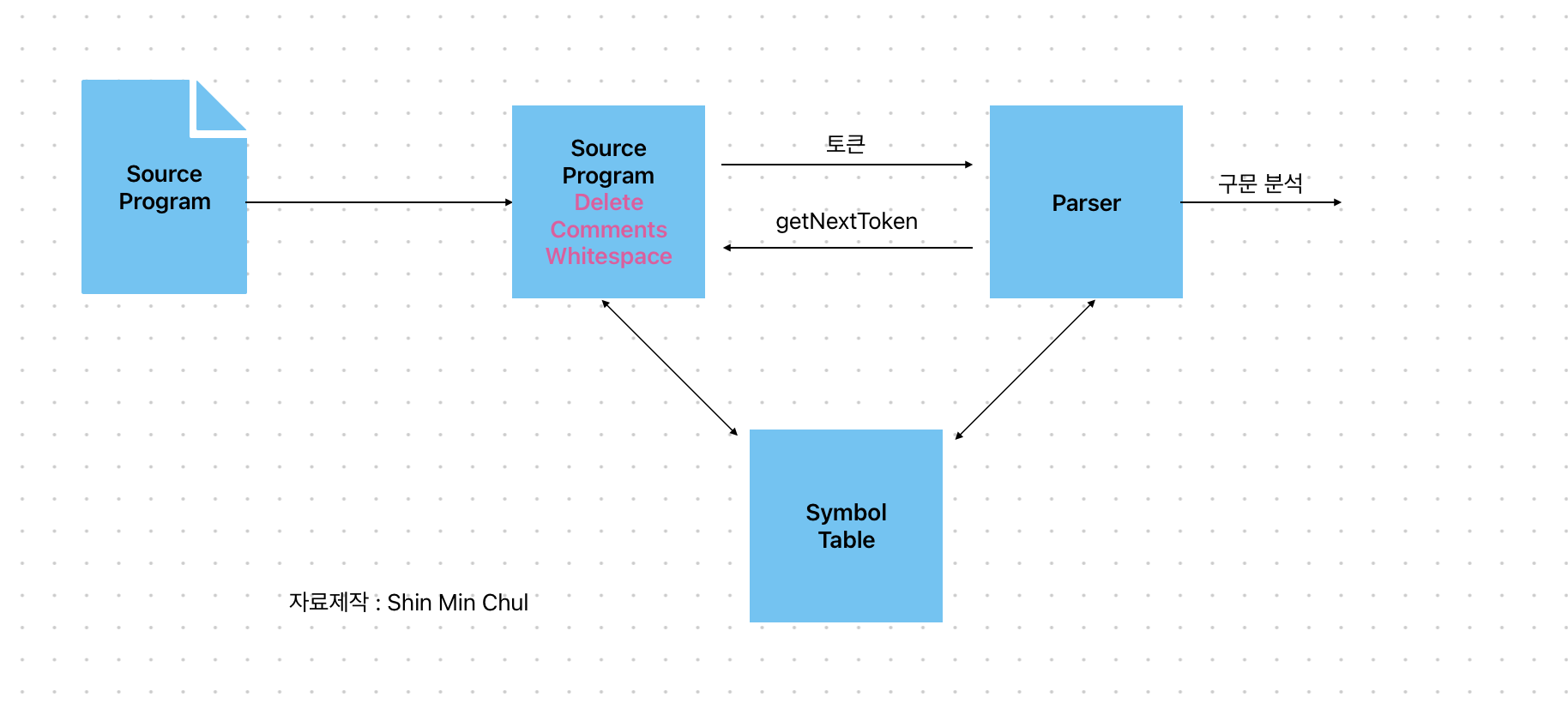
어휘분석기의 모델을 최종적으로 표현하자면 이러한 그림을 지니게 된다. 때때로 어휘 분석기는 직렬로 연결된 [ Scanner - 토큰화 작업 ] 과 같은 2개의 프로세스로 나뉘어져서 보기도 하니, 이 점도 인지하고 있다면 건강한 지식이 될 것이다.
