
1. 문제 상황 🤔
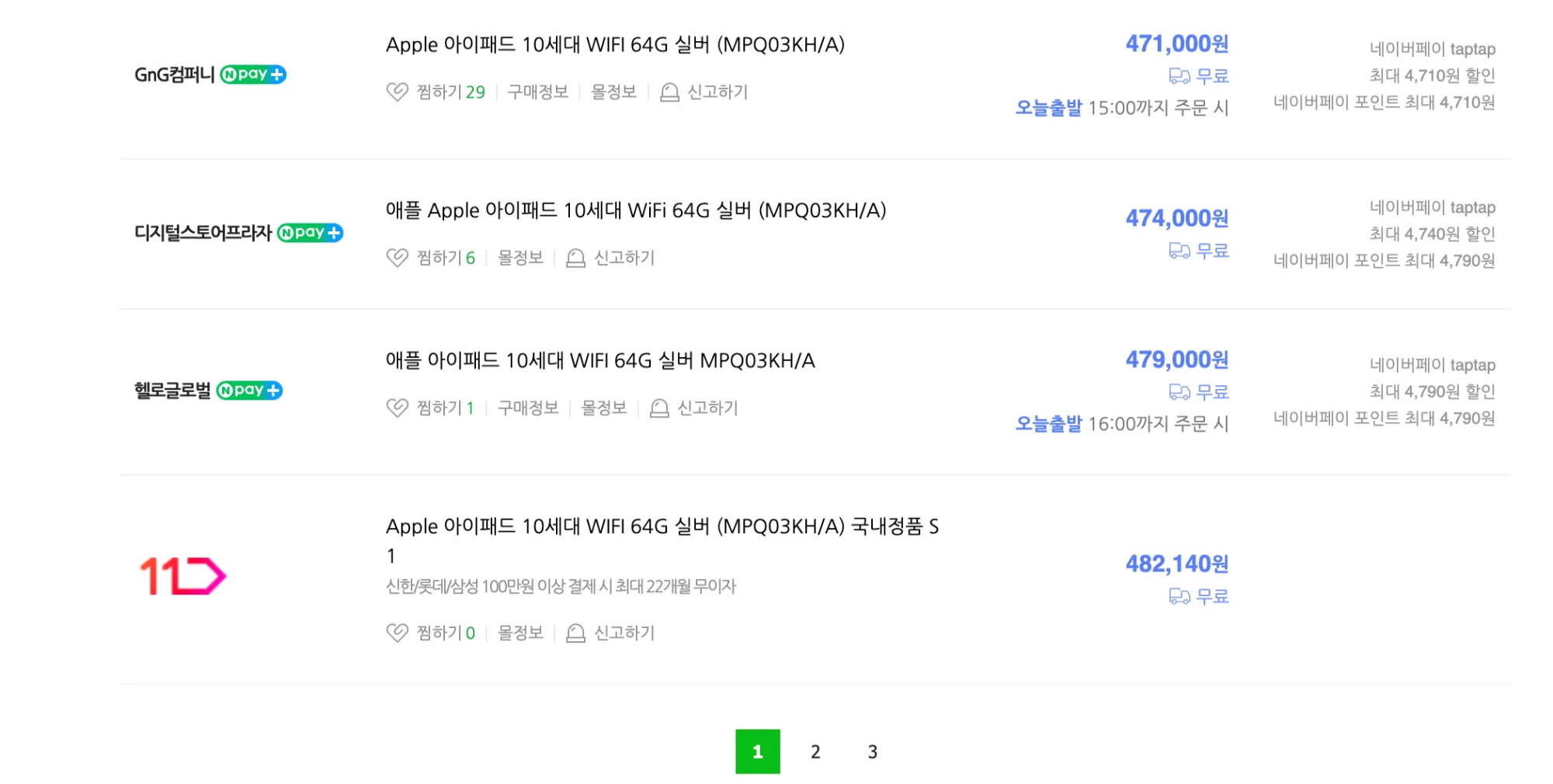
네이버 쇼핑의 상품 정보를 크롤링하는 과정에서 여러 문제점들이 발생했다. 기존 코드는 첫페이지만 크롤링이 되도록 구현되어 있었기 때문에 상품 정보가 20개밖에 저장되지 않았다. 이를 해결하기 위해 여러 페이지를 크롤링 하도록 코드를 수정했는데 이번에는 상품 정보가 너무 많다 보니 속도가 느리다는 문제점이 발생했다.
2. 멀티스레드의 도입 💡
크롤링 속도가 느린 가장 큰 이유는 순차적인 페이지 처리로 인한 긴 대기 시간 때문이다. 이를 해결하기 위해 방법을 찾아본 결과, 멀티스레드 방식을 도입하기로 결정했다.
왜 멀티스레드였나?
멀티스레드는 여러 작업을 동시에 처리할 수 있게 해주는 프로그래밍 기법이다. 마치 여러 명이 동시에 일하는 것처럼…!
멀티스레드의 장점
- 동시 처리를 통한 속도 향상
- 여러 페이지를 병렬로 처리 가능
- 전체 처리 시간 대폭 감소
- 리소스 활용 최적화
- 대기 시간을 효율적으로 활용
- CPU와 네트워크 자원의 효율적인 사용
3. 구현 방법 🛠
주요 구현 코드
@Service
@RequiredArgsConstructor
public class CrawlingService {
private final PageRepository pageRepository;
public List<Page> crawlPages(String productId) {
// 5개의 스레드로 구성된 스레드 풀 생성
ExecutorService executor = Executors.newFixedThreadPool(5);
List<Future<List<Page>>> futures = new ArrayList<>();
try {
// 5개 페이지 동시 크롤링
for (int pageNum = 1; pageNum <= 5; pageNum++) {
final int currentPage = pageNum;
futures.add(executor.submit(() -> crawlSinglePage(productId, currentPage)));
}
...
// 결과 취합
return collectResults(futures);
} finally {
executor.shutdown();
}
}
}구현 내용
- 스레드 풀 생성
Executors.newFixedThreadPool(5)→ 동시에 실행할 스레드 수를 5개로 제한하여 시스템 리소스를 효율적으로 사용한다.
- 동시 크롤링
executor.submit()→ 각 페이지 크롤링 작업(crawlSinglePage)을 비동기적으로 실행한다.- 페이지마다 각각 작업을 스레드 풀에서 처리한다.
Future객체를 활용해 비동기 작업의 결과를 나중에 확인한다.
- 결과 취합
- 비동기 작업의 결과를
Future로 받아와 모든 페이지의 데이터를 취합한다. - 취합 과정에서 크롤링 실패 또는 작업 완료 여부를 처리할 수 있다.
- 자원 관리
executor.shutdown()→ 메모리 누수가 발생하지 않도록 크롤링 작업이 끝난 뒤에는 스레드 풀을 반드시 닫아 리소스를 반환한다.
4. 성능 개선 결과 📊
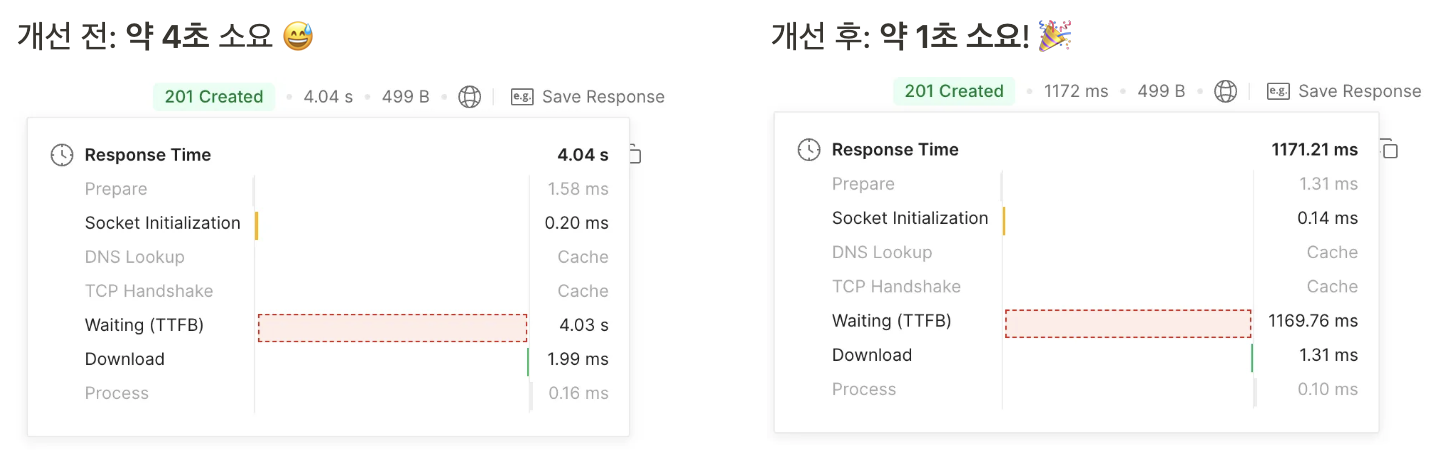
결과적으로 크롤링 작업의 처리 속도와 시스템 안정성을 크게 향상시킬 수 있었다. 기존에는 하나의 페이지를 순차적으로 처리하면서 약 4초가 소요되었지만, 이를 페이지별 병렬 처리로 전환하여 처리 시간을 1초로 줄이는 데 성공했다!

솨의 개발일기