
회고 리스트
1. 아래의 메모리 그림을 그려서 설명 부탁드리겟습니다.
def add_tuple(t1,t2):
t1 += t2
return t1
tp = (1,3)
tp = add_tuple(tp, (5,7))
print(tp)(그림을 못 그리겠어서 말로 설명합니다...)
함수를 호출 후 t1은 tp와 같이 (1, 3)을 가리킨다.
튜플은 immutable하기 때문에 += 연산을 하면서 기존 튜플을 변경하는 것이 불가능하다.
따라서 새로운 튜플 (1, 3, 5, 7)을 생성한다.
함수 반환 후엔 새로운 튜플 (1, 3, 5, 7)을 tp가 가리킨다.
2. 아래의 원본이 바뀌지 않도록 코드를 수정하시오.
def min_max(d):
d.sort()
print(d[0], d[-1], sep = ",")
l = [3,1,5,4]
min_max(l)def min_max(d):
d = list(d)
d.sort()
print(d[0], d[-1], sep = ",")
l = [3,1,5,4]
min_max(l) # 출력 : 1,5
print(l) # 출력 : [3, 1, 5, 4]d.sort()는 리스트 자체를 정렬하기 때문에 원본이 바뀐다.
입력된 값을 list(d)를 사용해서 새로운 리스트로 바꾼 후 정렬하면 원본이 바뀌지 않는다.
3. iterable 객체 와 interator 객체에 대하여 설명하시오.
-
iterable
: __iter__( ) 메서드를 가지고 있는 객체
: for문이나 in 연산자 등을 사용해서 반복할 수 있는 객체
: __iter__( ) 메서드를 호출하면 이터레이터(Iterator) 객체를 반환한다. -
iterator
: __iter__( )와 __next__( ) 메서드를 모두 가지고 있는 객체
: __next__( ) 메서드를 호출하면 다음 값을 반환하며 더 이상 반환할 값이 없으면 StopIteration 예외를 발생시킨다.
: 이터레이터는 반복 가능한 이터러블이면서 스스로 값을 하나씩 꺼내는 역할을 한다.
이터레이터에도 __iter__( )가 있길래 이터러블인가? 했는데 이터레이터도 이터러블에 포함된다고 한다.
4. 아래를 코딩하시오.
counter = Counter(3)
for i in counter:
print(i, end=' ') # 출력: 0,1,2class Counter :
def __init__(self, stop) :
self.current = 0
self.stop = stop
def __iter__(self) :
return self
def __next__(self) :
if self.current < self.stop :
r = self.current
self.current += 1
return r
else :
raise StopIteration
counter = Counter(3)
for i in counter:
print(i, end=' ') # 출력: 0,1,25. 함수도 객체인 증거를 대시오?
1) type( )으로 확인 가능하다 -> <class 'function'>
: 함수도 다른 데이터처럼 메모리에 저장된 객체이다.
2) 변수에 할당할 수 있다.
+
3) 다른 함수의 인자로 전달하거나 반환할 수 있다.
: 마치 데이터처럼 다른 함수 안에서 다뤄질 수 있다.
4) 속성을 추가할 수도 있다.
: 함수에 사용자 정의 속성ㅇ르 추가하면 데이터 저장이 가능하다.
일반적인 객체처럼 속성을 가질 수 있다.
객체란 속성(Attributes)과 행동(Method)을 가지는 데이터의 단위이다.
메모리 공간을 차지하는 하나의 실체로 변수나 함수처럼 사용할 수 있는 구조이다.
클래스라는 설계도로 만들어지고 클래스에 정의된 형태에 따라 다양한 속성과 기능을 가진다.
-> 함수도 속성과 행동을 가지며 메모리에 저장되는 독립적인 데이터 단위이다.
6 . 아래의 결과를 예측하고 설명하시오.
def say1():
print('hello')
def say2():
print('hi')
def caller(fct):
fct()
==================
caller(say1())
caller(say2)-
caller(say1())은 오류가 날 것이다.
say1()은 함수 호출이기 때문에 함수의 반환값을 넘기를 것이지 함수를 참조하는 게 아니기 때문이다.
say1()은 반환값이 없기 때문에 None이 넘어가서 함수로 호출하려고 하기 때문에 오류가 발생한다. -
만약 caller(say1)으로 수정한다면
caller(say2)까지 모두 실행될 것이고 'hello'와 'hi'가 차례대로 출력될 것이다.
7. 일반함수를 람다함수로 바꾸는 방법에 대하여 설명하시오.
def say_hi(string) :
print(string)
say_hi = lambda string : print(string)1) def 키워드를 lambda로 대체
2) 함수 이름과 매개변수 제거 및 표현식으로 변경
3) 람다 함수에 변수 할당
(예시는 함수 이름과 똑같은 이름으로 변수 할당했다.)
8. 아래를 람다 함수로 바꾸어 보시오.
def fct_fac(n):
def exp(x): # 함수 내에서 정의된, x의 n제곱을 반환하는 함수
return x ** n
return exp # 위에서 정의한 함수 exp를 반환한다.
f2 = fct_fac(2) # f2는 제곱을 계산해서 반환하는 함수를 참조한다.
f3 = fct_fac(3) # f3는 세제곱을 계산해서 반환하는 함수를 참조한다.
f2(4) # 4의 제곱은? 16
f3(4) # 4의 세제곱은? 64def fct_fac(n):
return lambda x : x ** n
print(f2(4)) # 출력 : 16
print(f3(4))f2(4) # 출력 : 64 9. 이름(name), 전화번호(tel) 필드와 생성자 등을 가진 Phone 클래스를 작성하고, 실행 예시와 같이 작동하는 PhoneBook클래스를 작성하라.
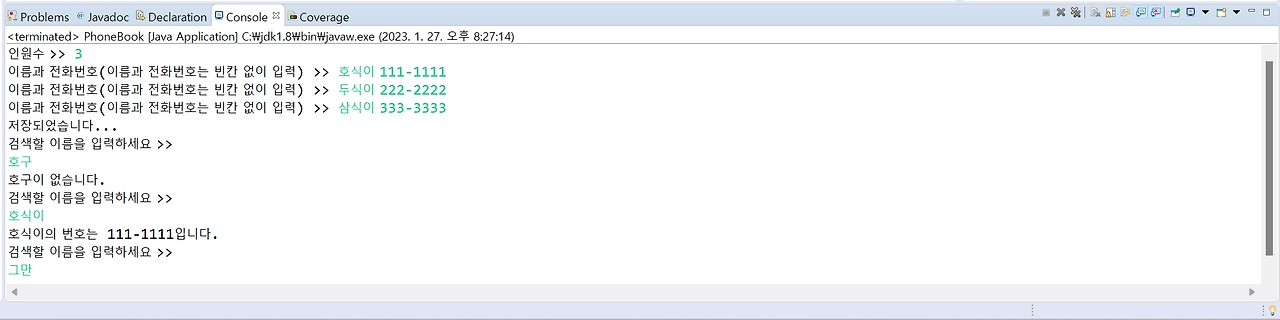
class Phone :
def __init__(self, name, tel) :
self.name = name
self.tel = tel
class PhoneBook :
def __init__(self) :
self.people_num = 0
self.tel_list = []
self.find_name = ""
self.stop = False
def save_tel(self) :
for i in range(self.people_num) :
# 입력받은 인원수만큼
self.name_input, self.tel_input = input("이름과 전화번호(이름과 전화번호는 빈칸 없이 입력) >> ").split()
self.phone = Phone(self.name_input, self.tel_input)
self.tel_list.append(self.phone)
# 이름과 전화번호를 입력받아 Phone 인스턴스를 만들어 tel_list에 추가
print("저장되었습니다...")
def search_name(self) :
self.find_name = input("검색할 이름을 입력하세요 >> ")
for phone in self.tel_list :
if self.find_name == "그만" : # 멈춤
self.stop = True
return
elif self.find_name == phone.name : # 찾으려는 이름 발견
return f"{phone.name}의 번호는 {phone.tel} 입니다."
return f"{self.find_name}님이 없습니다."
def open(self) :
while True : # 인원수 입력
try :
self.people_num = int(input("인원수 >> "))
break
except ValueError:
print("잘못 입력하셨습니다. 다시 입력하세요.")
self.save_tel()
while True :
result = self.search_name() # 출력할 문자열을 반환함
if result is not None : # 그만하고 싶을 땐 리턴값 None
print(result)
if self.stop : # 멈춤
break
phonebook = PhoneBook()
phonebook.open()10. 문자열을 입력받아 한 글자씩 회전시켜 모두 출력하는 프로그램을 작성하라.
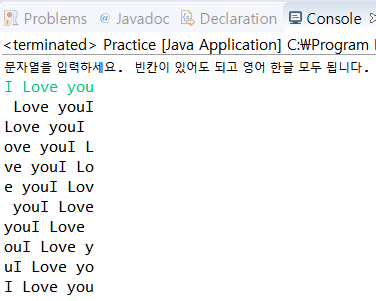
string = input("문자열을 입력하세요. 빈칸이 있어도 되고 영어 한글 모두 됩니다. \n")
string_list = list(string)
for i in range(len(string_list)+1) : # 입력한 문자열 길이만큼 반복
print( ''.join(string_list))
string_list = string_list[1:] + list(string_list[0])예전에 과제로 이런 비슷한 문제를 풀어봤던 것 같다.
덕분에 고민없이 바로 풀었던 것 같다.
근데 뜬금없이 슬라이싱을 써서 강사님의 의도와 다르게 푼 것 같기도 하다.
세줄요약:
함수도 객체이다.
튜플을 함수로 넘길때, 원본이 변화 되지 않는 특성을 잘 이해 하자.
람다를 이용하면 효율적인(?) 함수 작성이 가능하다.

