
회고 리스트
1. 판다스로 생성 할수 있는 두객체의 이름은?
-
Series : 1차원 데이터 구조로 '인덱스 + 값'으로 이루어져있다.
-
DataFrame : 2차원 데이터 구조(엑셀의 표 같은 구조)로 여러 개의 Series가 모여서 만들어진다.
2. 아래의 결과값을 예측하시고, 에러가 나는 부분은 왜 에러가 나는지 설명하고 수정하시오.
s = pd.Series(data = [1000,2000,"3000"],
index = ["메로나","구구콘",-1])
print(s)
print(s.iloc[0])
print(s.iloc[1])
print(s.iloc[2])
print(s.iloc[-1])
print(s.loc["메로나"])
print(s.loc["구구콘"])
print(s.loc["하겐다즈"]) 맨 마지막 줄에서 KeyError가 발생한다.
"하겐다즈"란 인덱스가 Series에 존재하지 않기 때문이다.
if "하겐다즈" in s.index:
print(s.loc["하겐다즈"])
else:
print("해당 인덱스가 존재하지 않습니다.")이런 식으로 loc 사용 전 인덱스 존재 여부를 확인하면 에러가 나지 않는다.
3. 아래의 결과를 예측하고 그 결과를 설명하시오.
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([
[1],
[2],
[3]
])
print(arr2.shape)
result = arr1 + arr2
print(result)4. 넘파이에서 브로드 캐스팅에 대한 개념과 브로드 캐스팅이 일어 나는 조건은?
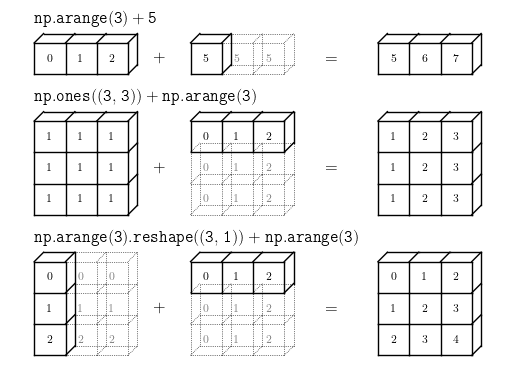
Broadcasting은 크기가 다른 배열 간의 연산을 자동으로 확장하여 수행하는 기능이다.
아래 조건을 만족하면 Broadcasting이 가능하다.
- 두 배열의 차원이 같을 때
- 둘 중 한 배열의 차원이 1일 때
import numpy as np
a = np.array([1, 2, 3])
b = 2 # 스칼라 (0차원)
result = a + b
print(result)
# 출력 : [3 4 5]a = np.array([[1, 2, 3],
[4, 5, 6]]) # (2,3)
b = np.array([10, 20, 30]) # (3,)
result = a + b
print(result)
# 출력 : [[11 22 33]
# [14 25 36]]a = np.array([[1],
[2],
[3]]) # (3,1)
b = np.array([10, 20, 30]) # (3,)
result = a + b.reshape(3,1) # b의 shape을 (3,1)로 변경
print(result)
# 출력 : [[11]
# [22]
# [33]]
database
5. emp 테이블에서 ename(사원이름)의 두번째 문자가 'A'인 사원의 이름을 출력한다면?
select ename
from emp
where ename like '_A%';6. mgr 가 null 이면 없음으로 출력하시오.
select ifnull(mgr, "없음") as mgr
from emp;7. EMP 테이블에서 사원이름이 5자 이상인 사원들의 사번과 이름을 출력해보세요
select empno, ename
from emp
where length(ename) >= 5;8.급여가 1000과 2000 사이인 사원들의 사원번호, 이름, 급여를 출력.
select empno, ename, sal
from emp
where sal between 1000 and 2000
order by sal desc;9.커미션이 NULL인 사원의 사원이름과 커미션을 출력
select ename, comm
from emp
where comm is null;10.입사년도가 81년인 사원들의 입사일과 사원번호를 출력
select hiredate, empno
from emp
where hiredate like '1981%';세줄요약:
1. 넘파이에서 브로드캐스팅이 일어나는 케이스를 잘 이해 하자.
2. 판다스란 = 시리즈 + 데이터프레임 이다.
3. 오라클 = nvl함수이고 이고 mysql은 ifnull 이다.

