.png)
쿼리 최적화를 통한 서비스 성능 개선
2차 프로젝트를 마무리하면서 개선하고 싶었던 부분이 메모리 캐싱을 통한 성능 향상이었다.
프로젝트 전체적인 소스코드를 리팩토링하면서 장고에서 메모리 캐싱을 하기 위해 일반적으로 사용하는 prefetch_related에 더해 Prefetch 객체의 적용법을 알게 되었다. 또한, annotate와 Case, When을 활용해 특정 조건에서 집계함수를 사용할 때 쿼리문을 최적화하는 방법을 알아내기도 했다.
그래서 결과적으로 http://localhost:8000/product/1 엔드포인트 요청 시 쿼리문 갯수가 291개에서 11개로 줄었고, 소요시간은 62초에서 4초로 단축되는 결과를 확인할 수 있었다.
쿼리문 갯수, 소요시간 측정
query_debugger 데코레이터를 이용해 쿼리문 갯수와 소요시간을 측정해보았다.
query_debugger데코레이터 소스코드는 아래에 있음
테스트로 http://localhost:8000/product/1를 요청해보았다. ProductDetailView에 연결된 엔트포인트이다.
리팩토링 전
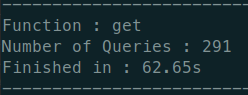
- 쿼리문 갯수 : 291
- 소요시간 : 62.65s
리팩토링 후
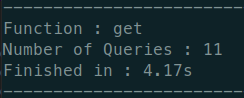
- 쿼리문 갯수 : 11
- 소요시간 : 4.17s
많은 성능차이가 나는 걸 확인할 수 있다.
어떤 방법을 적용해서 장고 프로젝트의 쿼리 최적화를 시도했는지 아래에 설명하도록 하겠다.
쿼리 최적화 방법
총 5가지 방법을 활용해 쿼리 최적화를 시도했다.
1. select_related
select_related는 1:N 정참조 또는 1:1 정참조, 역참조 관계에서 사용된다.
적용 전
Size와ProductSize는1:N관계ProductSize에서Size는 정참조(N->1)
product_sizes = ProductSize.objects.filter(product_id=product_id)
results = [{
'size_id' : product_size.size.id,
'size_name' : product_size.size.name,
} for product_size in product_sizes
]적용 후
product_sizes = ProductSize.objects.filter(product_id=product_id).select_related('size')
results = [{
'size_id' : product_size.size.id,
'size_name' : product_size.size.name,
} for product_size in product_sizes
]2. prefetch_related
prefetch_related는 1:N, N:M 역참조 관계일 때 사용된다.
적용 전
Product와Image는1:N관계Product에서Image는 역참조(1->N)
products = Product.objects.all()
results = [{
'image' : product.image_set.first().image_url,
} for product in products
]적용 후
products = Product.objects.prefetch_related('image_set')
results = [{
'image' : product.image_set.all()[0].image_url,
} for product in products
]
first()대신all()[0]을 사용한다.
3. Prefetch 객체
Prefetch 객체는 prefetch한 대상에 filter가 걸려있을 경우 사용한다.
적용 전
ProductSize와Ask는1:N관계ProductSize에서Ask는 역참조(1->N)- 역참조하는
Ask에filter 조건이 걸려있다.
- 내가 구현하려는 서비스는 경매방식으로 신발을 사고 파는 것이다. 따라서 똑같은 신발이라도 가격이 변동될 수 있다.
가장 최근 거래된 가격을 구하려고 한다.- 가격은 거래가 성사된 상품만을 대상으로 한다. 따라서 입찰된 제품(
ask) 중order_status가completed인 filter 조건을 지정해주었다.가장 최근을 구하기 위해order_by('-matched_at')[0]을 지정해주었다.
product_sizes = ProductSize.objects.filter(product_id=product_id)
results = [{
'last_sale_price' : int(product_size.ask_set.filter(order_status__name='completed').order_by('-matched_at')[0].price)
} for product_size in product_sizes
]적용 후
product_sizes = ProductSize.objects.filter(product_id=product_id)\
.prefetch_related(
Prefetch('ask_set', queryset=Ask.objects.filter(order_status__name='completed').order_by('-matched_at'), to_attr='ask_completed'),
)
results = [{
'last_sale_price' : int(product_size.ask_completed[0].price)
} for product_size in product_sizes
]
to_attr를 사용해서 반환되는 Prefetch 객체를 새로운 이름으로 사용할 수 있다.
4. Annotate
aggregate는 annotate를 사용해서 쿼리문을 최적화할 수 있다.
적용 전
Product와ProductReview는1:N관계Product에서ProductReview는 역참조(1->N)- 제품별
리뷰 평균을 구하고 싶다.
products = Product.objects.all()
results = [{
'rate_average' : round(product.productreview_set.aggregate(rate_average=Avg('rate'))['rate_average'], 1)
} for product in products
] 그냥 prefetch_related를 적용하면 안 된다.
products = Product.objects.prefetch_related('productreview_set') # 이렇게 하면 안 됨!적용 후
products = Product.objects.annotate(rate_average=Avg('productreview__rate'))
results = [{
'rate_average' : round(product.rate_average, 1)
} for product in products
]for문 안에서 aggregate를 쓰지 않고, for문 밖에서 annotate를 사용한다.
결과는 똑같으나 쿼리문은 한 번만 날아간다.
5. Annotate + Case, When
4번 방법과 비슷하나 집계함수를 적용하는 테이블에 filter 조건이 있을 경우 Case와 When을 적용하면 된다.
적용 전
ProductSize와Ask는1:N관계ProductSize에서Ask는 역참조(1->N)- 역참조하는
Ask에filter 조건이 걸려있다. - 상품별 평균 판매 가격을 구하려고 한다. 단, 거래가 성사된 내역이어야 한다.
product_sizes = ProductSize.objects.filter(product_id=product_id)
results = [{
'average_sale_price' : int(product_size.ask_set.filter(order_status__name='completed').aggregate(total_avg=Avg('price'))['total_avg'])
} for product_size in product_sizes
]적용 후
product_sizes = ProductSize.objects.annotate(total_avg=Avg(
Case(
When(
ask__order_status__name='completed',
then='ask__price'
)
)
))
results = [{
'average_sale_price' : int(product_size.total_avg)
} for product_size in product_sizes
][참고] query_debugger 데코레이터
import functools, time
from django.db import connection, reset_queries
from django.conf import settings
def query_debugger(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
reset_queries()
number_of_start_queries = len(connection.queries)
start = time.perf_counter()
result = func(*args, **kwargs)
end = time.perf_counter()
number_of_end_queries = len(connection.queries)
print(f"-------------------------------------------------------------------")
print(f"Function : {func.__name__}")
print(f"Number of Queries : {number_of_end_queries-number_of_start_queries}")
print(f"Finished in : {(end - start):.2f}s")
print(f"-------------------------------------------------------------------")
return result
return wrapper
[참고] 쿼리문 로깅
settings.py에 입력
# settings.py
LOGGING = {
'disable_existing_loggers': False,
'version': 1,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
'level': 'DEBUG',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'level': 'DEBUG',
'propagate': False,
},
},
}참고사이트
https://stackoverflow.com/questions/39354746/django-annotate-on-prefetched-filtered-related-model
http://raccoonyy.github.io/conditional-annotate-with-django-query/
https://velog.io/@wltjs10645/Django-query-logging-prefecthrelated
