.png)
인터넷, 네트워크 그리고 서버
내 컴퓨터의 ip address 알아내기
- 쉘에서
ip addr입력, inent 뒤의 부분이 주소 -> 10.0.2.15 - ipinfo.io/ip라는 사이트로 접속 또는 쉘 환경에서
curl ipinfo.io/ip-> 211.36.24.37
두 개의 결과가 다르다.
- 1번 방식은 컴퓨터가 실질적으로 가지고 있는 ip가 무엇인지 알아내는 것, 컴퓨터에 부여되는 실제 ip
- 2번 방식은 온라인 서비스 입장에서 접속한 ip가 무엇인지 알려주는 것, 외부에 접속할 때 사용하는 ip
왜 다른가?
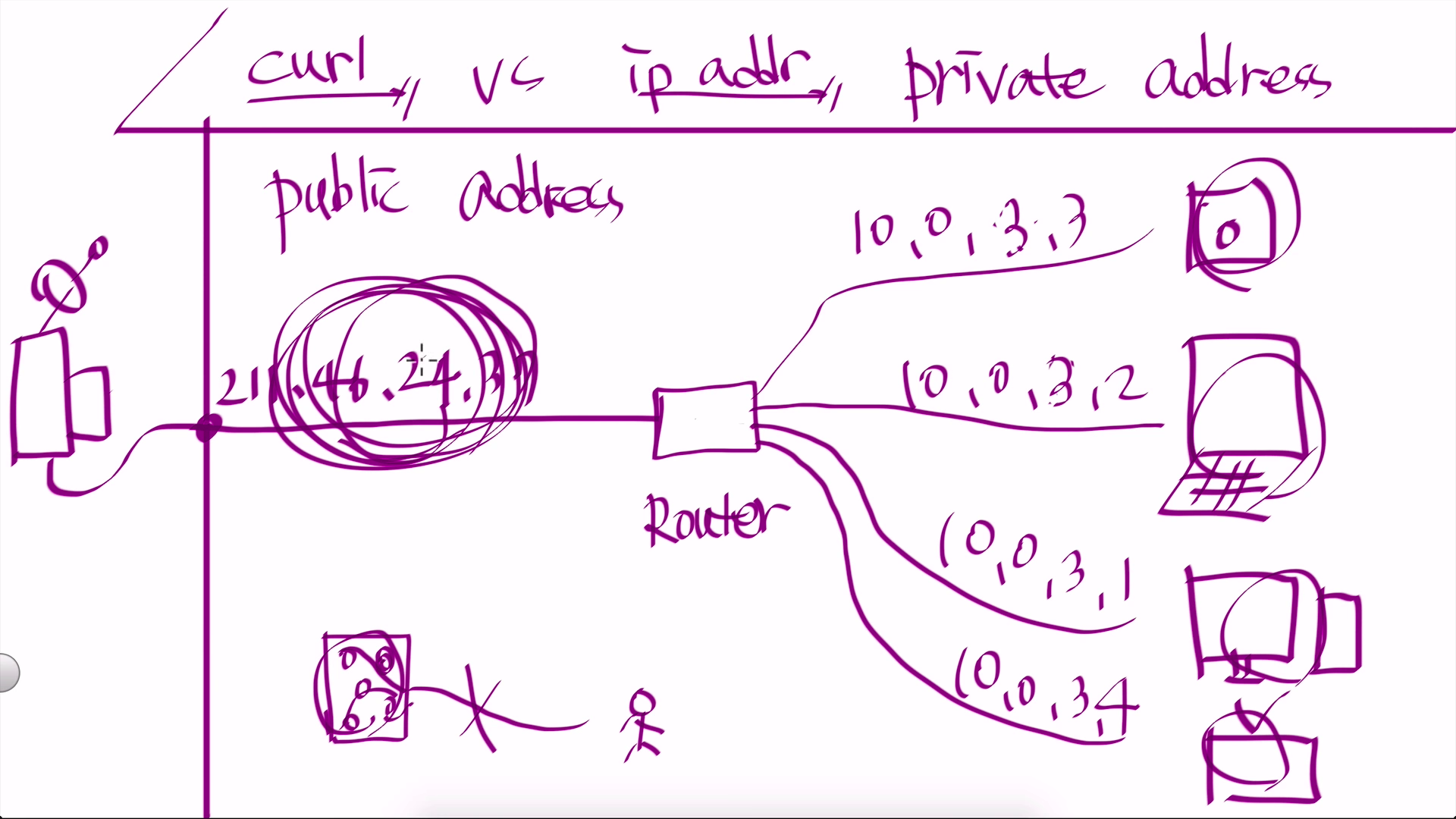
- 내 컴퓨터는 통신사가 설치한 회선에 연결, 통신사는 그 회선에 대해 ip를 부여 함.(ex. 211.36.24.37) 이 ip로 다른 사람도 연결 가능
- 만약 집에 인터넷을 쓰는 여러 개의 장치가 있다면? 각각의 장치에 각각의 ip를 부여하지 않는다. 비용이 비싸기 때문이다.
- 대신 router(공유기)를 통해 모든 장치들이 연결된다. 그리고 통신사가 부여한 ip(211.36.24.37)는 라우터의 ip가 된다. 여기서 사설 ip(private ip)라는 개념이 등장한다!
- 각각의 컴퓨터도 개별적인 주소를 갖는다. (ex. 10.0.3.1 / 10.0.3.2 / 10.0.3.3 / 10.0.3.4 등)
- 라우터의 ip를 public address, 각 컴퓨터의 ip를 private address라고 한다.
(public address는 회사의 대표번호, private address는 내선번호로 비유할 수 있다.)
public ip와 private ip가 같으면 컴퓨터를 그대로 서버로 사용하면 된다. 하지만 다를 경우에도 할 수 있는 방법이 여러 가지가 있다. 예를 들어 라우터로 묶여있는 컴퓨터 간에는 접속할 수 있다.
웹서버 (아파치)
이번 수업에서는 서버의 구체적인 사례로서 웹서버 그 중에서 아파치 웹서버를 설치하고 운영하는 방법에 대해서 알아본다.
apache install
-
설치
sudo apt-get update
sudo apt-get install apache2 -
켜고 끄기
sudo service apache2 start
sudo service apache2 stop
sudo service apache2 restart껐다 켜야할 때는 restart -
켜졌는지 확인
sudo htopf4로apache검색
apache는 많은 접속이 들어왔을 때 분산해서 처리하기 위해 여러 개의 아파치 웹서버가 자동으로 실행됨 -
서버에 접속하기
ip를 통해 웹서버에 접속하는 것은 복잡하니, 쉘에서 직접 웹서버에 접속해보자
쉘에서 웹브라우징을 할 수 있는 프로그램 elinks 설치
sudo apt-get install elinks
(elinksURL 입력, google.com(마우스 혹은tab 키를 통해 이동,Q로 빠져나감))
elinks http://내 컴퓨터의 ip 주소(ip addr로 알아낸 ip) -
한 대의 컴퓨터에서 웹브라우저와 웹서버를 동시에 사용하고 있을 경우, localhost 또는 127.0.0.1로 자신의 컴퓨터에 설치된 웹서버에 접속할 수 있다. (자기 자신을 의미)
elinks 127.0.0.1ip 주소
elinks http://localhost도메인 네임
configuration 환경 설정
-
WB가 요청(request) 보내면 WS가 받아서 storage(HDD/SDD) 어딘가에 저장되어 있는 요청한 파일을 읽어온다. 그것을 WB에게 응답(response)하고, WB는 그 파일을 해석해서 출력한다.
-
그렇다면 WS는 사용자가 요청한 파일을 어디에서 읽어오는 것일까?
프로그램의 동작방법에 대한 설정은cd /etc에 저장되어 있다.
cd apache2ls -alapache에 대한 설정파일 중apache2.conf라는 파일이 가장 중요 -
정리하면, WB의 요청이 들어올 때 WS는 /etc/apache2 밑에 있는 여러 가지 설정파일을 참고해서 사용자가 요청한 파일을 찾는다. 그리고 WS가 사용자가 요청한 파일을 찾는 최상위 디렉토리(ex.
/var/www/html)를 document root라고 부른다. -
var/www/html를 사용하는 이유는?
/etc/apache2/sites-enabled/000-default.conf파일 안에var/www/html라고 적혀있었기 때문이다. 이 값을 바꾸면 다른 곳에 설치된다. -
대부분의 서버는 etc라는 디렉토리 밑에 자신의 이름으로 설정파일이 있고 그 파일을 수정하면 동작하는 방식이 달라진다!
log
-
/etc/apache2/sites-enabled/000-default.conf설정 파일에 보면
${APACHE_LOG_DIR}/error.log
${APACHE_LOG_DIR}/access.log이런 내용이 있다.
아파치 웹서버가 동작할 때 잘 동작하는지 오류가 있는지 확인하고 싶을 때 아파치 로그 디렉토리로 지정되어 있는 특정한 디렉토리 아래에 있는 error.log, access.log에 기록하겠다라는 뜻이다. -
그렇다면
APACHE_LOG_DIR은 어디인가?cd /var/log/apache2/ -
access.log란?
cat access.logacess.log에는 누군가가 웹서버에 접속할 때마다 접속한 사람의 정보가 추가됨
tail -f var/log/apache2/access.log여기서-f는 실시간으로 끝에 추가되는 정보만을 출력하는 아주 중요한 옵션 -
error.log란?
아파치 웹서버에 특정한 에러가 있을 때(실행시켰는데 동작을 안 하거나)error.log에서 확인
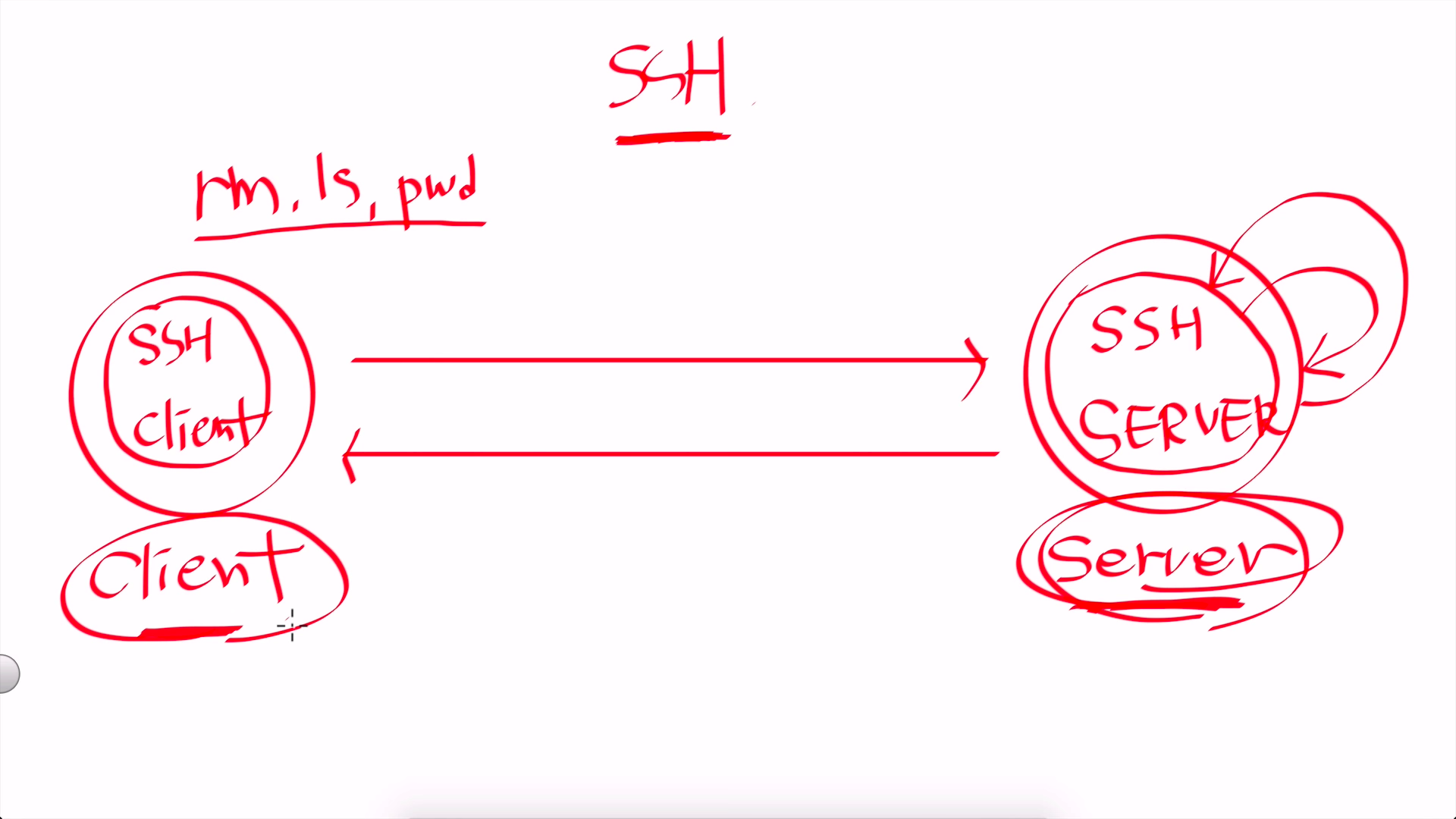
원격제어 (ssh)
원격으로 쉘을 제어할 수 있는 방법인 ssh에 대해서 알아본다.
- 서버 컴퓨터(제어하고자 하는 컴퓨터)에는 SSH Server가, 클라이언트 컴퓨터(내 컴퓨터)에는 SSH Client가 깔려 있어야 한다. (웹서버와 웹클라이언트의 관계와 유사하다.)
-
대부분의 유닉스 계열의 시스템에는 SSH가 기본적으로 깔려 있다.
-
sudo apt-get purge openssh-server openssh-clinentremove대신 purge를 하면 환경설정도 같이 사라지므로 삭제하는 것은 따라하지 말자.
sudo apt-get install openssh-server openssh-clientopenssh는 ssh와 관련된 여러 프로그램을 제공하는 구체적인 프로그램
sudo service ssh start실행 시작
sudo ps aux | grep ssh잘 실행되는지 확인 -
원격제어 연결
<Server 컴퓨터>ip addr로 ip 알아냄 -> 192.168.0.65
<Client 컴퓨터>ssh egoing@192.168.0.65openssh를 실행시키는 명령어
이제 Client에서 내리는 명령은 모두 Server에서 실행된다.
포트 (port)
포트는 네트워크를 통해 적절한 애플리케이션을 실행 시키기 위해서 꼭 필요한 개념이다.
포트란 무엇인가?
예시 1)
www.naver.com == www.naver.com:80 != www.naver.com:8888
여기서 80이라는 숫자가 포트이다.
예시 2)
ssh -p 22 egoing@192.168.0.65 p는 포트라는 의미, 접속이 된다. (exit)
ssh -p 2222 egoing@192.168.0.65 Connection refused
-> ssh는 22번이라는 포트를 쓴다는 추론이 가능
- 모든 컴퓨터에는 포트(port)가 있다. 포트는 구멍이라고 생각하면 된다.(0 ~ 약 6만 5천개의 포트가 있다.)
- SSH 서버를 설치하면 22번 포트에 연결되도록, 웹 서버를 설치하면 80번 포트에 연결되도록 약속이 되어 있다.
- 클라이언트 컴퓨터의 웹브라우저는 서버 컴퓨터의 80번 포트를 찾아간다. 80번 포트에서 대기(Listen)하고 있었던 웹서버가 받아서 처리한다.
- 0~1024번 포트는 well-known port 잘 알려진 포트라고 해서 값이 고정되어 접속할 때 포트의 값을 적지 않아도 연결된다. 그 이외의 포트는 프로그램을 만들어서 그냥 사용하면 된다.
- 포트 번호 변경
sudo nano /etc/ssh/sshd_config로 파일을 열어보면Port 22라고 적혀있다. 이것을2222로 변경할 수 있다.sudo service ssh restart해야 반영된다.
클라이언트 컴퓨터에서ssh -p 2222 egoing@192.168.0.65라고 해야 접속된다. - 변경하는 이유는 22번 포트 번호는 유명하고 원격제어는 위험하기 때문에 사람들이 잘 모르는 포트 번호로 변경하는 것이다.
포트 포워딩이란?
- 라우터를 통해 private ip를 부여받은 컴퓨터도 서버 컴퓨터로 사용할 수 있는 방법이 있다. 바로 포트 포워딩을 통해!
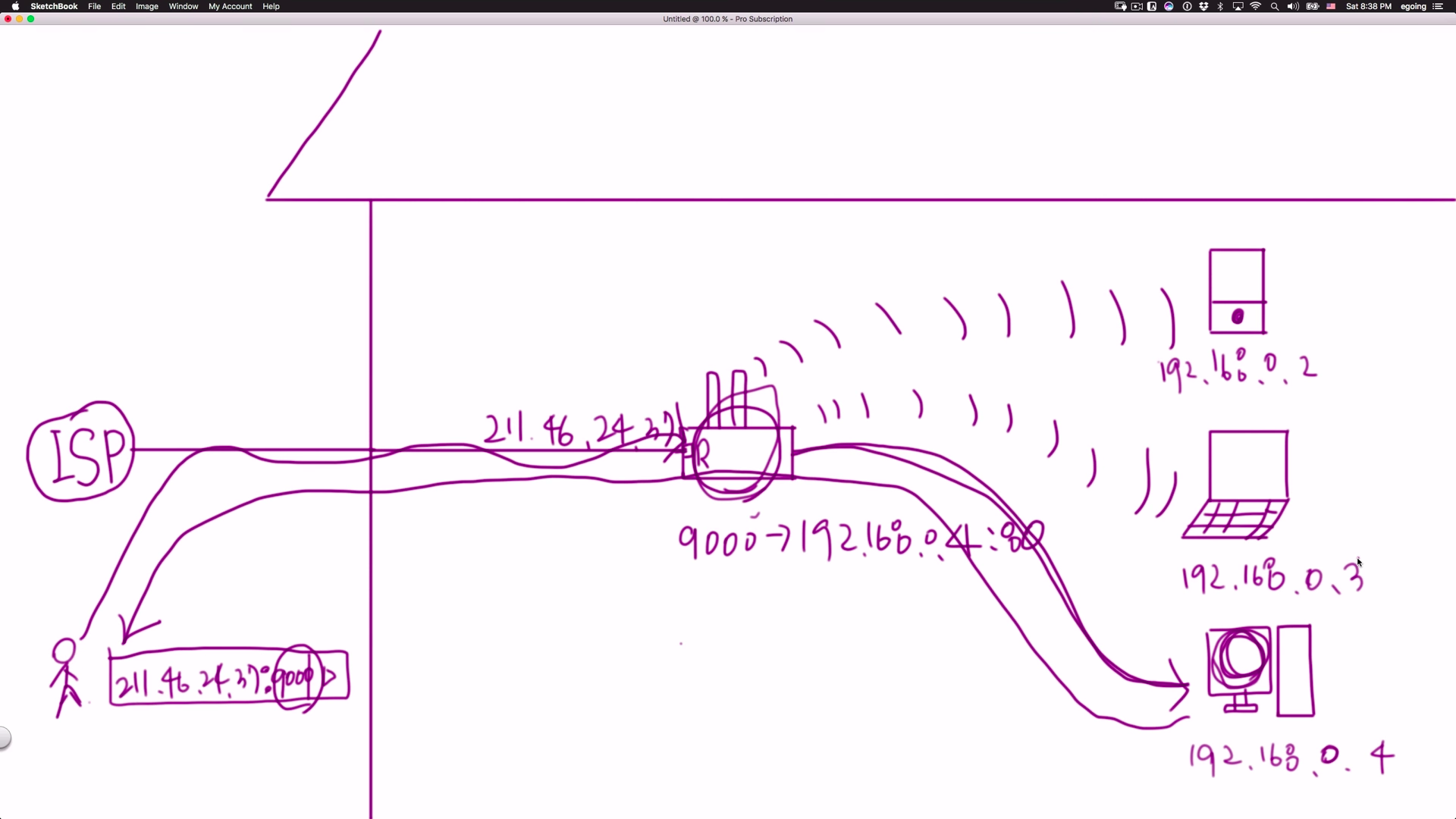
- ISP(Internet Service Provider)는 인터넷 서비스 제공 회사
- 포트 포워딩이란 사용자가 특정 포트로 접속을 하면, 그 접속을 특정 컴퓨터로 전달하는 것이다.
(라우터도 포트가 있고, 컴퓨터에도 포트가 있다.) - 예를 들어, 사용자가 9000번 포트로 접속한다.(211.46.24.37:9000), 라우터에서 9000번 포트는 192.168.0.4:80(특정 컴퓨터의 포트)로 가라고 설정한다. 그 80번 포트에 설치된 웹서버가 동작된다.
포트 포워딩 실습
-
공유기의 환경설정을 통해 포트 포워딩을 할 수 있다. 공유기의 환경설정에 접속하기 위해서는 공유기의 내장되어 있는 서버에 접속해야 한다. 그러려면 공유기의 내부에서만 통용되는 ip를 알아야 한다.(default gateway)
-
ip route로 default gateway를 알아낼 수 있다. -> 192.169.0.1
(맥은 환경설정-네트워크에서 현재 연결된 와이파이-Advanced-TCP/IP-Router의 값)
- 공유기 환경설정 사이트에서 로그인 후 포트포워드 설정으로 들어간다.
- 내부 IP주소 :
192.168.0.65내 컴퓨터의 ip주소 작성 - 규칙이름 :
linuxlove - 외부 포트 :
9000사용자가 사용할 포트의 번호(라우터의 포트) - 내부 포트 :
80 - 추가 버튼 누른다.
- 내부 IP주소 :
- 위 설정을 정리하면,
linuxlove라는 규칙에 의해서9000번 포트로 누군가 들어왔을 때192.168.0.65ip 해당되는 컴퓨터의80번 포트로 신호를 보낸다는 뜻이다.
- 사용자는
211.46.24.37:9000(public ip:route port)로 접속을 시도할 수 있다.
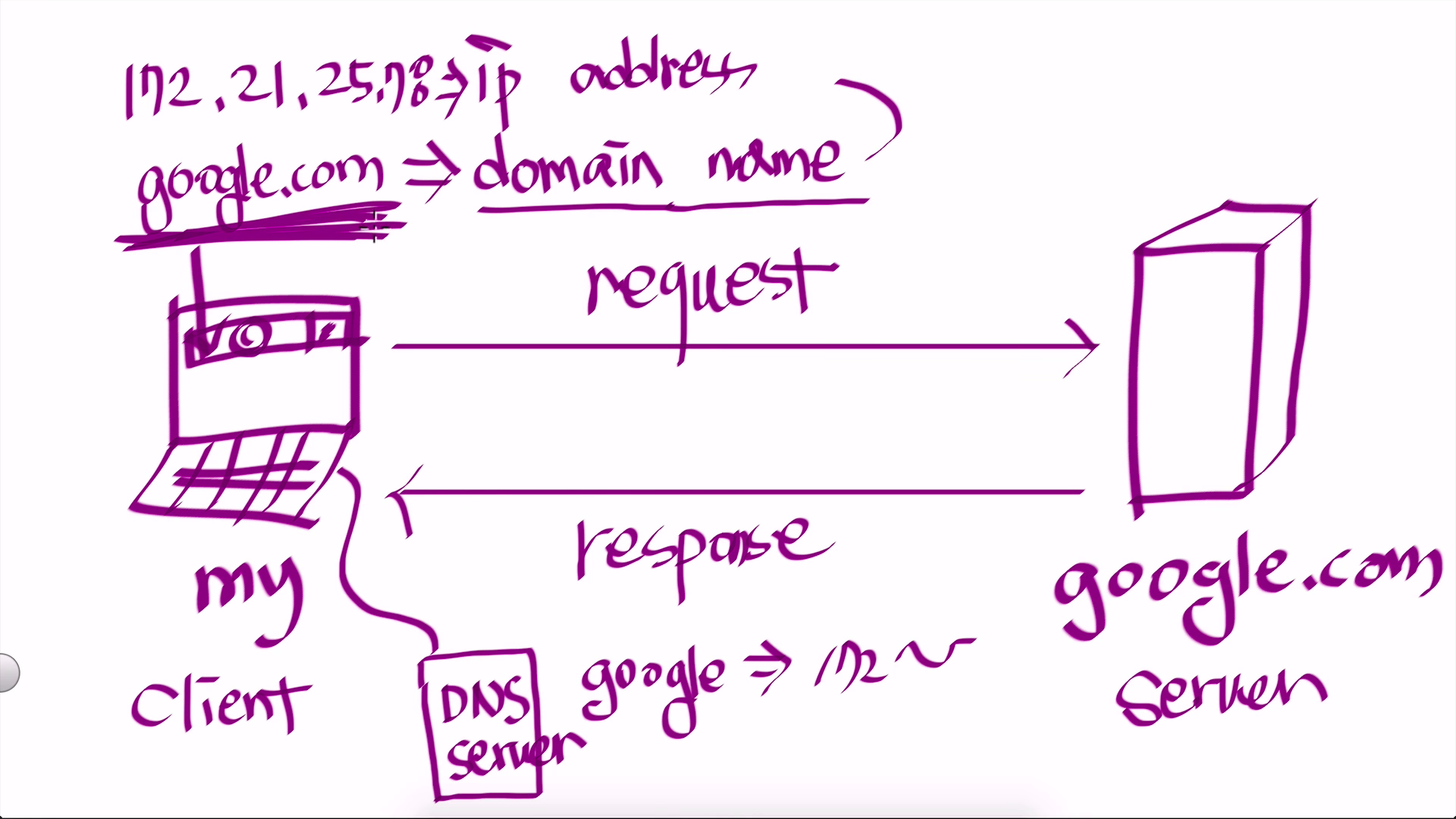
도메인 (domain)
기본
- Domain은 Domain Name System의 약자
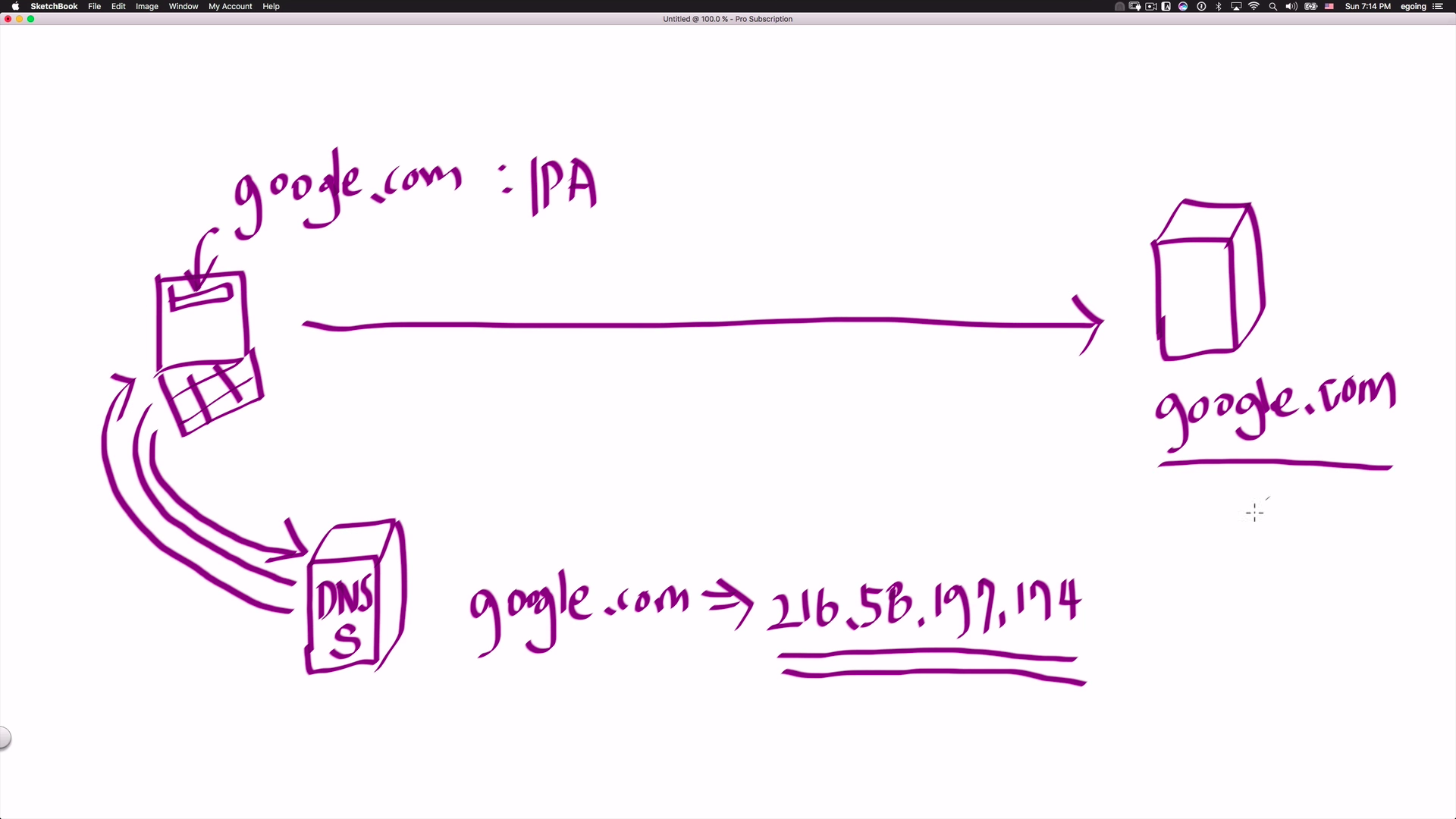
- 사용자는 웹브라우저에 google.com(도메인 네임)을 친다. 그러면 컴퓨터는 DNS Server로 접속해서 도메인 네임에 맞는 IP Address를 받는다. 내 컴퓨터는 그 ip로 구글 서버에 접속할 수 있다.
- 사용자가 ip 주소(216.58.197.174)를 기억하기는 어렵기 때문에 도메인 네임을 사용
hosts 파일
- Domain Name System이 있기 전에는 hosts 파일이 있었다.
- hosts 파일이란 어떤 도메인이 어떤 아이피라는 정보를 갖고 있는 파일이다. 각각의 컴퓨터들마다 hosts 파일이 있었다.
- hosts파일을 내마음대로 바꿀 수 있다.
sudo nano /etc/hosts로 nano에 들어간 다음
127.0.0.1 google.com작성하면elinks google.com라고 했을 때
구글 홈페이지가 뜨는 게 아니라 내 웹서버(127.0.0.1)가 뜬다.
- (인터넷에 참여하고 있는 각각의 컴퓨터를 host라 한다. host가 모여 있는 것을 network, network가 모여있는 전체적인 집단을 internet이라 한다.)
다시 말해,/etc/hosts파일은 호스트들의 이름이 어떤 아이피를 갖는지 적어놓은 것이라고 할 수 있다. - 호스트들이 많아지고 hosts 파일로 관리하기가 어려워지면서 DNS 서버를 만들어 문제를 해결
/etc/hosts파일을 어디에 활용할 수 있는가?
egoing.ga라는 운영하고 있는 서버가 있고, 도메인에도 등록되어 있다고 가정하자. 근데 도메인과 관련된 결함이 있어 서버의 내용을 바꿨음. 서버 쪽에 수정한 내용을 바로 반영했다가는 실수가 있을 수 있음. 이럴 때 자신의 개발환경에서만 hosts 파일의 도메인을 자신의 컴퓨터로 수정한다.- hosts파일은 악의적인 해킹, 공격의 대상으로도 많이 사용되므로 잘 관리해야 한다.
도메인 구입
- 우리의 컴퓨터는 DNS 서버를 어떻게 알 수 있는가?
cat /etc/resolv.conf라고 치면 어떤 IP가 나옴.(컴퓨터마다 다름)
어떤 통신사가 제공하는 케이블, 와이파이에 접속하는 순간/etc/resolv.conf의 내용이 그 회사에서 서비스로 제공하는 DNS 서버의 IP로 바뀐다. - 컴퓨터가 모르는 도메인으로 접속하려고 하면 먼저 이 IP로 접속한다.
- 도메인 구입
- 누군가 도메인 네임으로 접속했을 때 아이피를 알려주려면 도메인을 구입해야 한다.
- 도메인의 끝부분에 따라 관리하는 주체가 달라진다.
- free domain라는 사이트에서 도메인을 사용하고 있는지 조회하고 구입할 수 있다.
- 도메인에 연결할 때는
curl ipinfo.io/ip로 검색한 공용 아이피를 사용해야 한다. host egoing.ga로 아이피 확인 가능하다.
서브 도메인
-
하나의 서버는 하나의 도메인과 매칭이 된다. 만약 서버가 여러 개가 있다면 각각의 도메인을 구입해야 해야 하는데 돈이 많이 든다.
-
도메인을 재사용하는 방법이 있다! 바로 서브도메인을 이용하면 하나의 도메인을 구입해서 여러 개의 사이트를 운용하는 효과를 낼 수 있다.
egoing.ga,admin.egoing.ga,blog.egoing.ga,news.egoing.ga
DNS의 동작 원리
dig +trace egoing.ga로 egoing.ga(도메인 네임)이 DNS 서버를 통해 IP 주소 확인하는 경로를 알 수 있다.
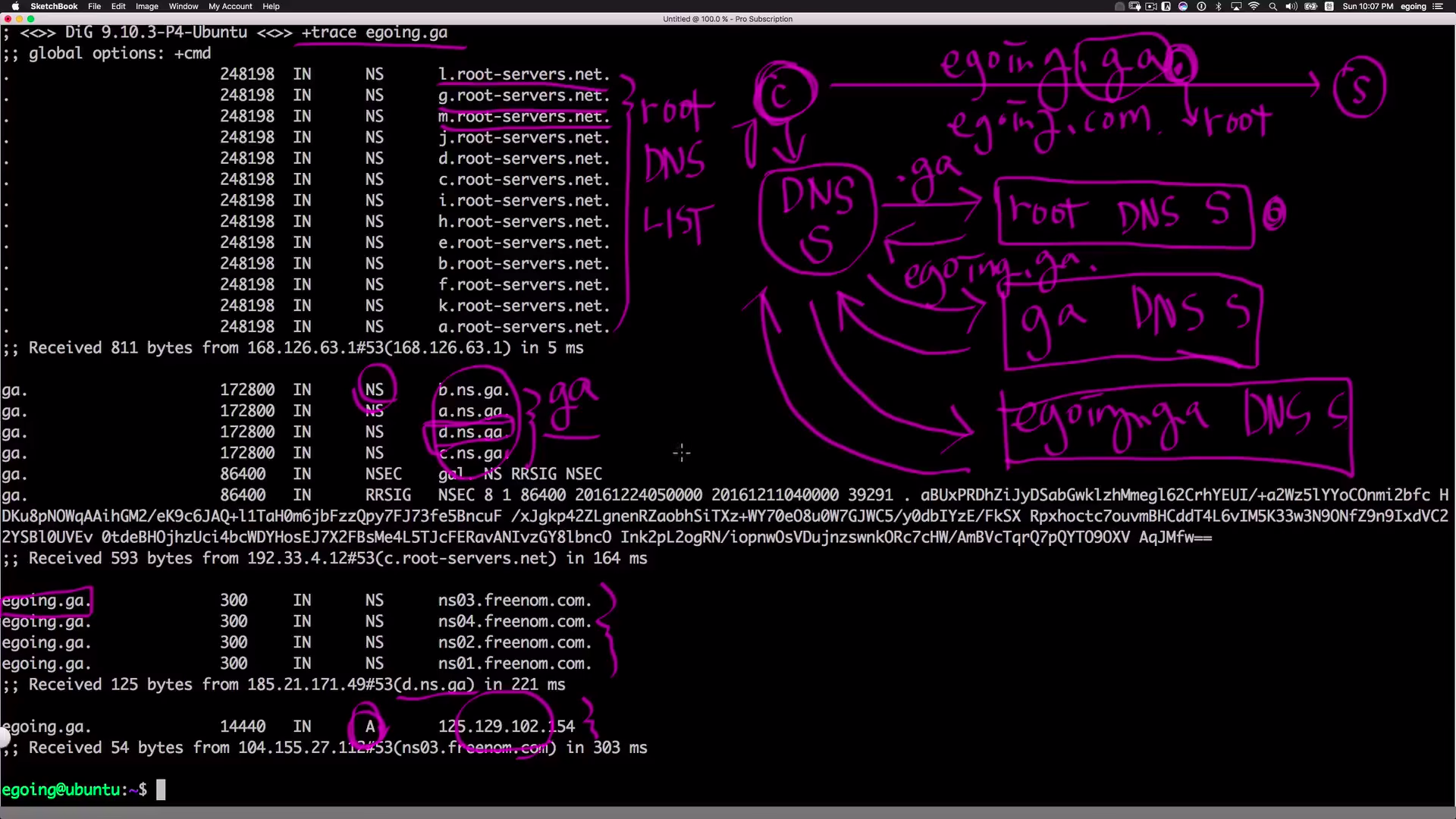
egoing.ga뒤에는.이 숨겨져 있다.(egoing.ga.).을 root라고 한다.
-
'우리의 DNS 서버'는 root DNS 리스트를 알고 있다. (
dig +trace egoing.ga치면 나오는 첫번째 문단)- root DNS 서버는 10대가 넘는 서버가 전세계가 흩어져 있다. root DNS 서버가 죽으면 엄청난 혼란이 오기 때문이다.
-
사용자가
egoing.ga접속을 시도할 때, 클라이언트는 그 ip를 DNS 서버에 물어볼 것이다. '우리의 DNS 서버'는 'root DNS 서버'에게.ga를 담당하는 DNS 서버가 누구인지를 물어본다. 그러면 root DNS 서버는.ga라는 도메인을 담당하는 네임 서버들의 목록을 돌려준다.
(dig +trace egoing.ga치면 나오는 두번째 문단)- 이 서버들도 마찬가지로 여러 개의 서버로 흩어져 있다.
-
2번의 결과로 나온 'ga의 DNS 서버'에게
egoing.ga를 관리하는 DNS 서버를 또 물어본다.
(dig +trace egoing.ga치면 나오는 세번째 문단) -
'우리의 DNS 서버'는 'egoing.ga의 DNS 서버'에게 egoing.ga의 아이피가 무엇인지 물어보고 반환한다.
(dig +trace egoing.ga치면 나오는 네번째 문단) -
이것을 클라이언트에게 보내주면 그 ip에 따라 접속한다.
-
즉, 도메인을 구입한다는 것을 ga라는 도메인을 관장하는 기관에게 관리비용을 내는 것이다. 그 기관을 그 서버를 관리하면서 요청이 들어왔을 때 그 ip 정보를 담고 있는 도메인 서버로 안내하는 것이다.
-
도메인을 구입할 때 ip 정보를 저장할 DNS 서버가 자동으로 세팅되었지만, 다른 DNS 서버를 지정할 수 있다.
인터넷을 통한 서버간 동기화 (rsync)
기본
- rsync(알싱크)
- 싱크란 특정 컴퓨터의 있는 내용을 다른 컴퓨터로 보내서 한 쪽에서의 변경사항이 다른 쪽이 반영해서 두 개가 같은 상태를 유지하는 것이다. 방향성 있음.
- r은 remote의 약자로 독립된 공간에 있는 컴퓨터들이 인터넷(네트워크)을 통해 원격으로 싱크를 할 수 있게 하는 프로그램을 의미한다.
- 네트워크를 통해 파일을 copy하거나 back-up할 때 사용할 수 있는 유용한 기능
- 실습을 해보자.
mkdir rsynccd rsync/mkdir srcmkdir dest src에 파일을 만들고 그 파일을dest에 동기화를 시켜보려고 한다.cd srctouch test{1..10}test1부터 test10까지 파일 생성cd ..rsync -a src/ dest
(만약rsync -a src dest라고 하면 dest안에 src라는 디렉토리가 생성)ls -al dest로 확인
rsync의 큰 매력은 증분 백업, 증분 카피를 한다.- 예를 들어 dest 디렉토리의 test 10파일을 지워보자
cd destrm test10 cd ..rsync -av src/ desttest10만이 복사가 된다. (v가 들어가면 자세하게 내용을 출력한다.)cd ..rsync -av src/ dest다시 실행하면 아무것도 안 나온다. 원본과 사본이 같은 상태이므로 복사를 하지 않는 것이다.
- 예를 들어 dest 디렉토리의 test 10파일을 지워보자
- 즉, 전송할 대상이 있을 때만 전송하기 때문에 굉장히 효율적으로 동작한다.
-a란? archive mode로 동작한다는 의미. 즉, 특정 디렉토리 안에 디렉토리가 있으면 그 전체를 전송하는 모드로 동작하고, 변경사항들만 전송하는 모드로 동작하고, 그 파일의 속성까지도 같이 전송하는 강력한 기능
remote sync
-
rsync를 네트워크를 통해 동기화시키는 방법
rsync -azP ~/rsync/src/ k8805@192.168.0.65:~/rsync/dest
(rsync -azP [전송하는 디렉토리] [전송받은 user명@전송받는 ip]:[전송받는 디렉토리])
z는 압축한다는 의미, P는 전송상황을 프로그래스 바로 보여준다 -
백업을 할 때 유용하게 사용된다.
로그인 없이 로그인 하기 (ssh key)
ssh public private key
- 아이디, 패스워드 입력 없이도 자동으로 로그인되면서 훨씬 안전한 방법이 있다. ssh 공개키를 통한 로그인 방식이다.
- <컴퓨터1의 ip :
192.168.0.65/ 컴퓨터2의 ip:192.168.0.67> - 먼저
ssh-keygen로 ssh 공개키, 비공개키를 만든다.
~/ .ssh디렉토리 아래에 생성된id_rsa파일은 ssh private keyid_rsa.pub파일은 ssh public key라고 한다. - 컴퓨터2(접속하고 싶은 컴퓨터)에 컴퓨터1의 공개키를 저장시켜두면 로그인 없이 접속가능하다.
ssh-copy-id egoing@192.168.0.67로 컴퓨터1의id_rsa.pub의 내용을 컴퓨터2authorized_keys파일의 맨 끝에 붙여넣는다. - 이제
ssh egoing@192.168.0.67치면 로그인 없이 컴퓨터2에 접속가능하다.
rsync
- ssh 공개키와 비공개키로 자동으로 로그인하게 하면 로그인 없이 동기화할 수 있다.
- <컴퓨터1>
mkdir rsync3
touch test{1..100}100개의 빈 파일 생성
<컴퓨터2>
mkdir rsync_welcomehttps://www.youtube.com/watch?list=PLuHgQVnccGMBT57a9dvEtd6OuWpugF9SH&v=Y16VCnP382I
<컴퓨터1>
rsync -avz . egoing@192.168.0.67:~/rsync_welcome엔터를 치면 전송이 휙 된다! 만약 퍼블릭키를 추가하지 않으면 되지 않는다.
(알싱크가 동작할 때ssh디렉토리로 들어가서 private key와 pulbic key가 있는지 확인하고, 있다면 이것들을 이용해서 전송을 하기 때문에 둘 사이의 관계를 확립해놨다면 로그인 없이 가능한 것이다.) cron(정기적으로 명령을 실행)과 같은 기능을 이용할 때 로그인을 해야 한다면 자동화를 시킬 수 없다.
RSA
- 컴퓨터1에서 컴퓨터2로 자동 로그인(
ssh egoing@192.168.0.67)할 때 RSA라는 암호화 기법이 사용된다. - 암호화란 어떤 정보를 알아야 하는 사람만 알 수 있도록 이해할 수 없는 정보로 바꾸는 것이다. (암호화 encrypt <-> 복호화 decrypt)
- key를 이용해서 암호화, 복호화할 수 있다. 즉 키를 가진 사람만이 암호를 읽을 수 있다.
- 암호화, 복호화를 할 때 똑같은 키를 쓰는 것을 대칭적 방식이라고 한다. 반대로, private key를 통해 암호화하고, public key를 통해 복호화하는 것을 비대칭적 방식이라고 한다. 비대칭적 방식의 대표 주자가 RSA다.
- ssh을 통해 인증을 하면 어떤 과정을 거치는가?
- ssh clinet(컴퓨터1)가 ssh server(컴퓨터2)에 접속하면 ssh server는 ssh client에게 random key를 준다.
- ssh client는
ssh디렉토리에서id_rsa파일이 있으면 그것을 이용해서 random key를 암호화한다. 그리고 그 결과를 ssh server에게 전달한다. - ssh server는
authorized_keys에 저장되어 있는 공개키를 이용해서 복호화한다. 복호화한 결과가 random key가 같다면 로그인을 해준다.
연속적으로 명령 실행시키기 (;과 &와 &&의 차이)
- 구분자 정리
;앞의 명령어가 실패해도 다음 명령어가 실행&&앞의 명령어가 성공했을 때 다음 명령어가 실행&앞의 명령어를 백그라운드로 돌리고 동시에 뒤의 명령어를 실행
; 성공여부와 상관없이 다음 명령어 실행
mkdir test;cd test
&& 성공한 경우에 다음 명령어 실행
- test 디렉토리가 이미 있는 상황일 때
&&를 사용하면
mkdir test(실패) && cd test && touch abccd test와 touch abc가 실행되지 않는다.- 반면,
;를 사용하면
mkdir test(실패); cd test; touch abccd test가 실행되고, touch abc도 실행된다.
- 대체로 &&를 쓰는게 좋을 때가 많다
명령어의 반환값
-
리눅스의 모든 명령어는 종료할 때 성공 여부를 알려준다.
echo $?를 통해 이전 명령어가 반환한 값을 알아낸다. -
test 디렉토리가 없는 곳에서
mkdir test명령을 실행하고echo $?을 실행하면0을 출력한다. -
test 디렉토리가 이미 있는데
mkdir test명령을 실행하고echo $?을 실행하면1을 출력한다. -
존재하지 않는 명령을 입력하고
echo $?을 실행하면127을 출력한다. -
즉, 리눅스에서 0이 아닌 값은 실패(false)를 의미한다.
&와 &&는 다르다.
&는 명령어를 백그라운드로 동작시킬 때 사용한다.
명령의 그룹핑 {}
mkdir test3 && { cd test3; touch abc; echo 'success!!' } || echo 'There is no dir';
- mkdir test가
- 성공했을 때 cd test2; touch abc를 실행하고 success!!를 출력한다.
- 실패했을 때 echo 'There is no dir'를 실행한다.
참고
본 포스팅은 생활코딩 리눅스 강의(https://opentutorials.org/course/2598)를 참고하여 작성하였습니다.
