문제

풀이 1
- 전화번호를 길이가 짧은 순으로 정렬
- 전화번호를 하나씩 순회하며 set에 있는 전화번호로 시작하는 것이 있는지 확인
- 있다면 return false
- 없다면 set에 넣기
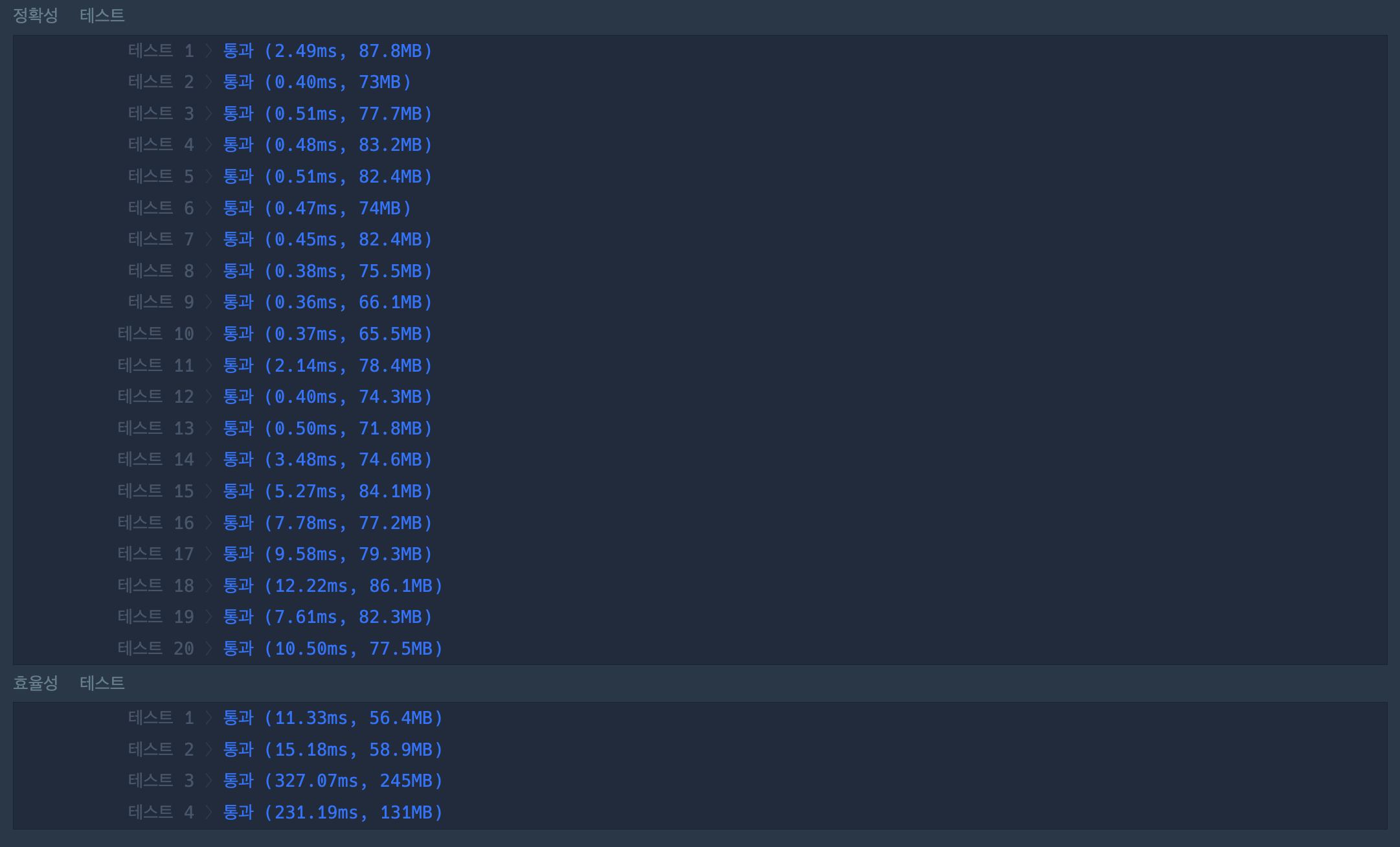
지금 다시 보며 생각해보니 정말 별로인 풀이이다.
Set을 사용하는 이점 중 큰 부분이 검색에서 O(1)를 가진다는 것인데, 이 이점을 활용하지 않는 풀이이다.
지금 이 풀이는 Set을 Array처럼 사용하고 있다.
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
HashSet<String> hs = new HashSet<>();
Arrays.sort(phone_book, new Comparator<String>() {
public int compare(String str1,String str2) {
return str1.length()-str2.length();
}
});
hs.add(phone_book[0]);
for(int i=1;answer && i<phone_book.length;i++) {
for(String phone_num : hs) {
if(phone_book[i].startsWith(phone_num)) {
answer = false;
break;
}
}
if(answer) hs.add(phone_book[i]);
}
return answer;
}
}
역시나? 효율성 테스트에서 시간 초과가 뜬다.
풀이 2
이번엔 전화번호는 모두 0~9의 10개의 문자로 시작한다는 점을 활용해보았다.
HashMap<Character,ArrayList<String>>: 각 0~9로 시작하는 전화번호를 묶는다.
즉,hm.get('0')은 0으로 시작하는 전화번호의 리스트를 리턴한다.
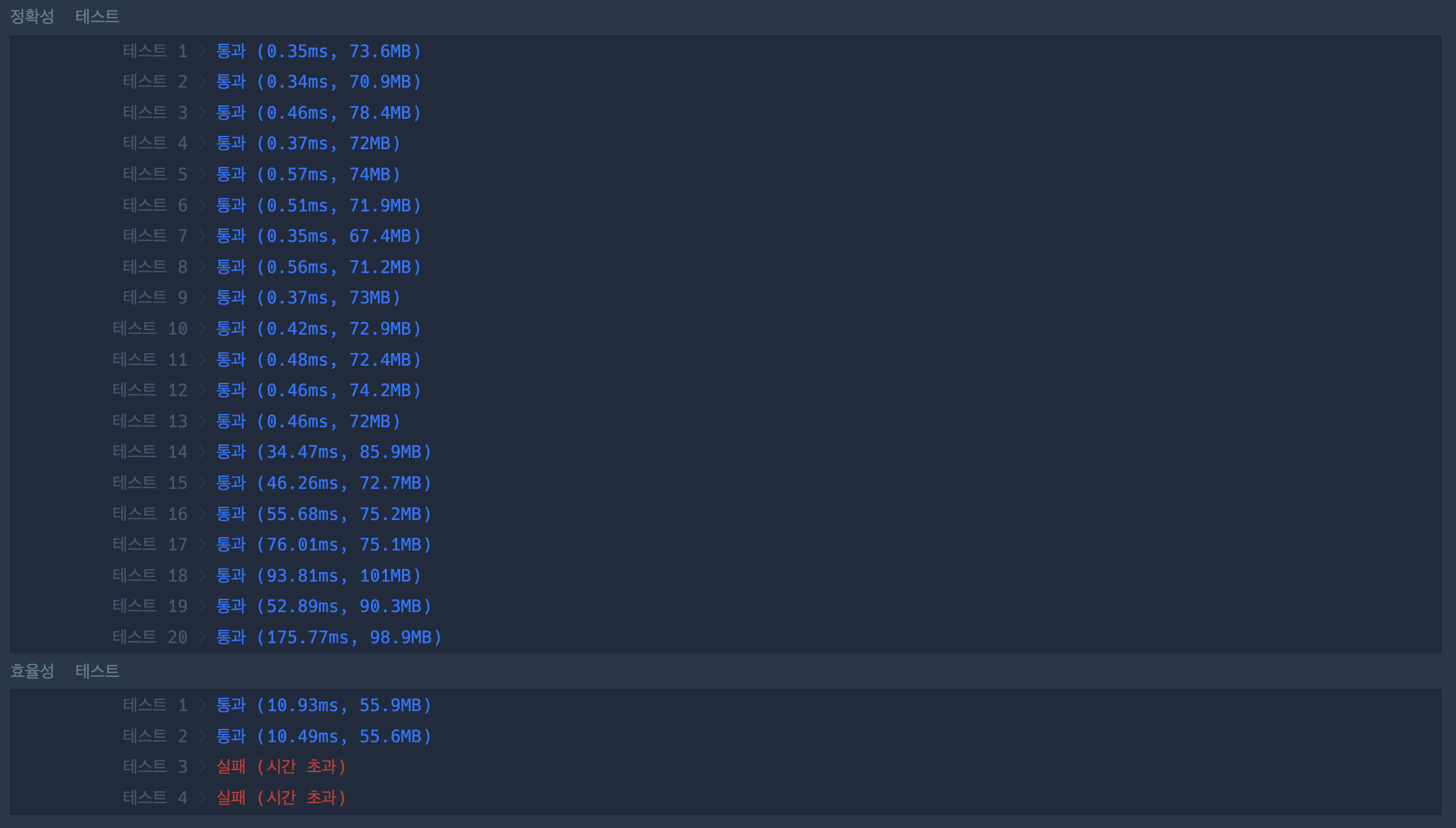
이 풀이는 첫 번째 풀이에서 성능을 살짝 향상시킨 풀이라 볼 수 있다.
- 첫 번째 풀이 : 각 전화번호 a에 대해서 a보다 길이가 짧은 모든 전화번호와 비교하여 접두어가 있는지 확인한다.
- 두 번째 풀이 : 각 전화번호 a에 대해서 a보다 길이가 짧고, a와 같은 첫번째 문자를 가진 모든 전화번호와 비교하여 접두어가 있는지 확인한다.
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
HashMap<Character,ArrayList<String>> hm = new HashMap<>();
Arrays.sort(phone_book, new Comparator<String>() {
public int compare(String str1,String str2) {
return str1.length()-str2.length();
}
});
for(int i=0;
i<phone_book.length;i++) {
if(!hm.containsKey(phone_book[i].charAt(0))) {
hm.put(phone_book[i].charAt(0), new ArrayList<String>());
} else {
ArrayList<String> sameFNList= hm.get(phone_book[i].charAt(0));
for(int j=0;j<sameFNList.size();j++) {
if(phone_book[i].startsWith(sameFNList.get(j))) {
answer = false;
break;
}
}
}
if(answer) hm.get(phone_book[i].charAt(0)).add(phone_book[i]);
else break;
}
return answer;
}
}
아직도 효율성 테스트는 통과를 하지 못 한다.
풀이 3
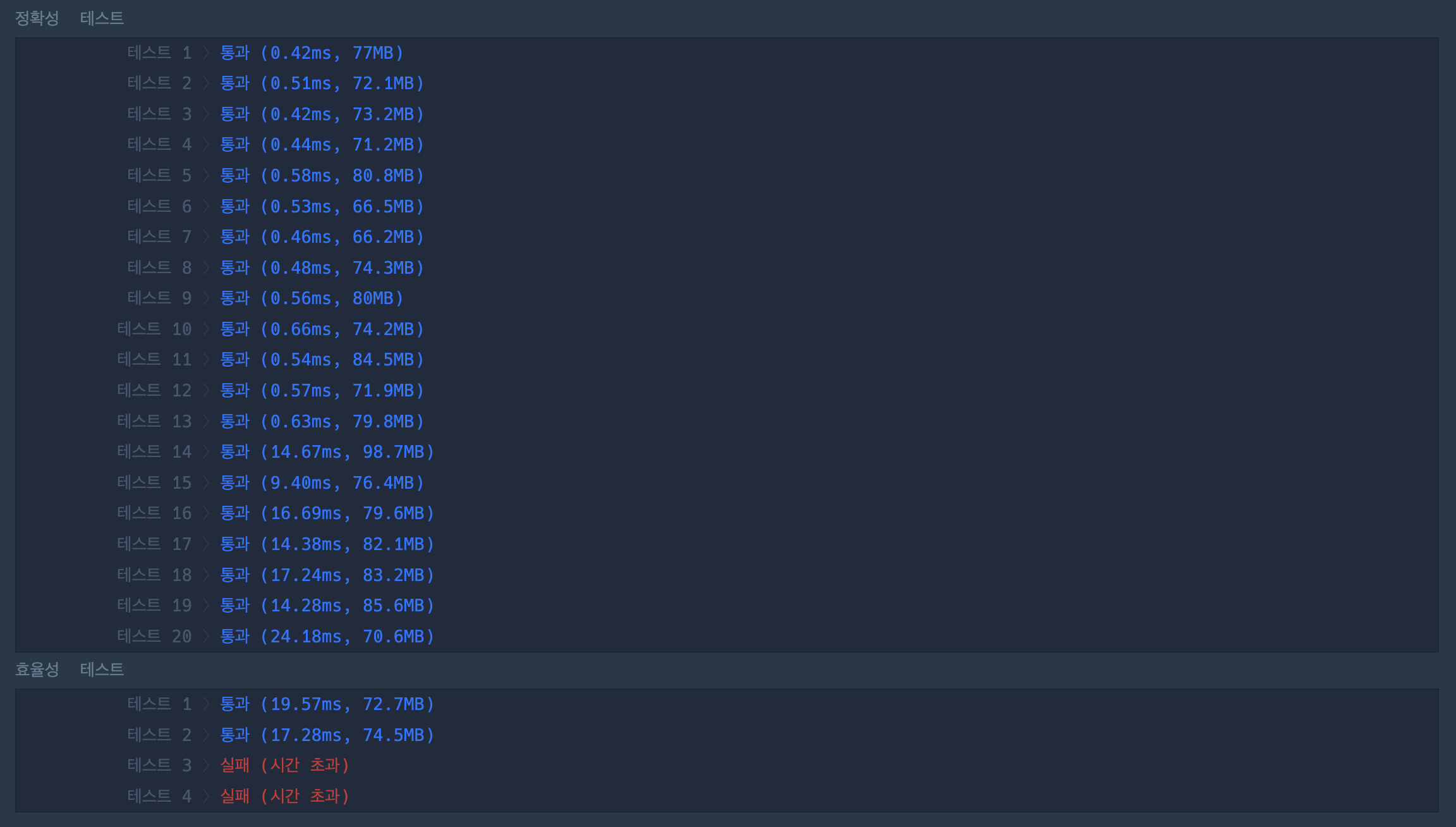
두 풀이가 효율성 테스트를 통과하지 못 하는 이유는 뭘까?
두 풀이 모두 각각의 전화번호 a에 대해서 a보다 길이가 짧은 전화번호 '모두'와 비교를 한다는 것이다.
물론 두 번째 풀이는 첫번째 문자가 같아야 한다는 조건이 붙기는 하지만, 길이가 20까지 될 수 있는 문자열에서 첫번째 문자만 동일하다는 것은 크게 메리트가 되지 못하는 듯하다. (적어도 10문자 정도는 동일해줘야지..)
전화번호의 길이는 1 이상 20 이하 이므로 한 전화번호에서 나올 수 있는 접두어의 개수는 최대 19개이다. (같은 전화번호가 중복해서 들어있지 않으므로 자기자신이 접두어인 경우는 제외)
따라서 만일 배열의 길이가 최대인 1,000,000 이고, 모든 전화번호의 길이 또한 최대 길이인 20일 때,
- 각 전화번호에서 나올 수 있는 모든 접두어가 존재하는지 확인
-> 1,000,000 * 19 => 19,000,000 - 길이가 짧은 모든 문자열을 확인
-> 1 + 2+ 3+ ... + 1,000,000-1 => 5*(10의 11승)
즉 .. 모든 접두어를 확인하는 편이 훨씬 빠르다.
그리고 이 때 가능한 접두어가 존재하는지 검색할 때 필요한 자료구조가 바로 HashSet이다.
import java.util.*;
class Solution {
public boolean solution(String[] phone_book) {
boolean answer = true;
HashMap<Character,HashSet<String>> hm = new HashMap<>();
Arrays.sort(phone_book, new Comparator<String>() {
public int compare(String str1,String str2) {
return str1.length()-str2.length();
}
});
for(int i=0;i<phone_book.length;i++) {
if(!hm.containsKey(phone_book[i].charAt(0))) {
hm.put(phone_book[i].charAt(0), new HashSet<>());
} else {
HashSet<String> hs = hm.get(phone_book[i].charAt(0));
for(int j=0;j<phone_book[i].length()-1;j++) {
if(hs.contains(phone_book[i].substring(0,j+1))) {
answer = false;
break;
}
}
}
if(answer) hm.get(phone_book[i].charAt(0)).add(phone_book[i]);
else break;
}
return answer;
}
}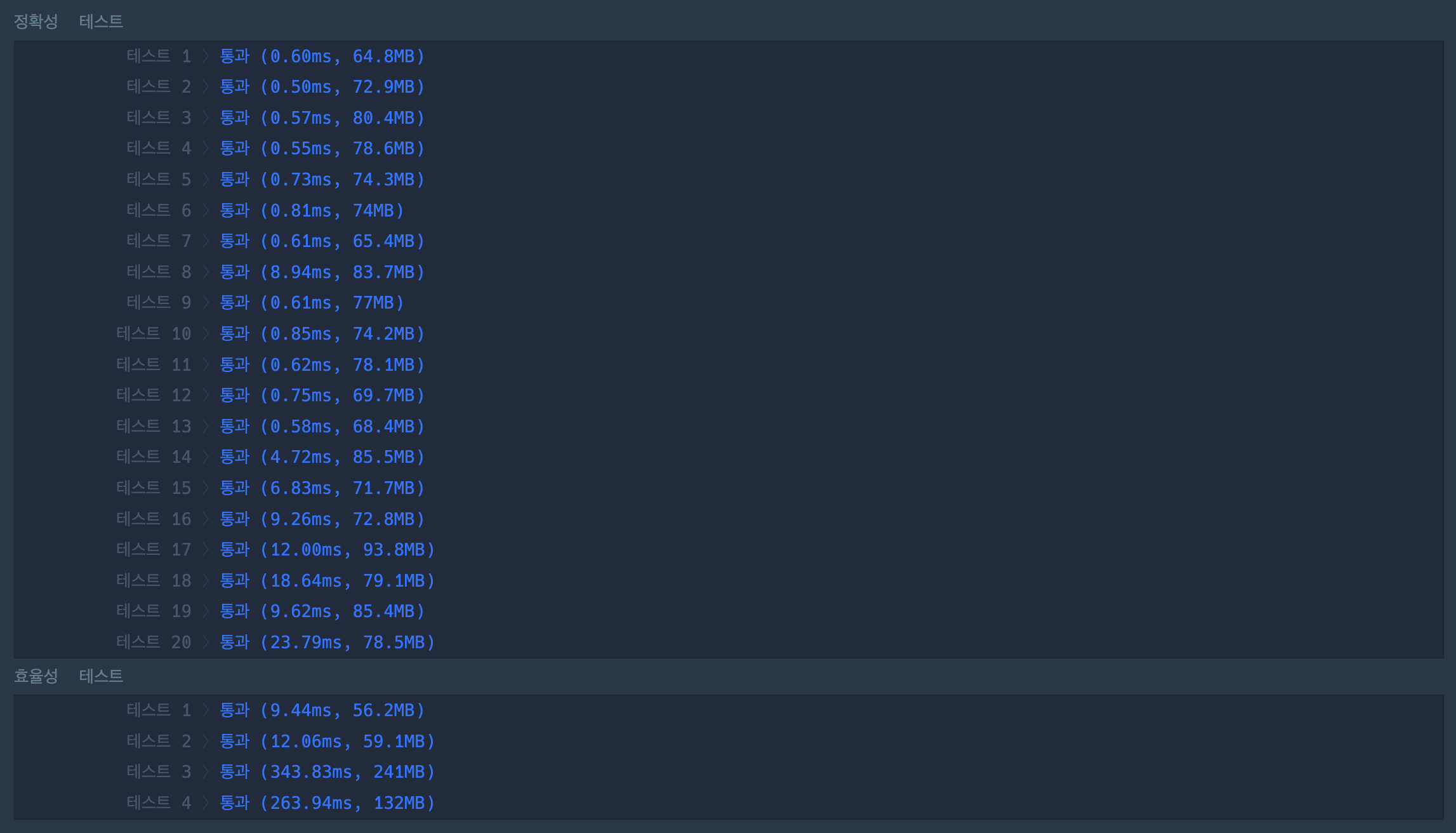
풀이 2에서 발전시키는 과정이었기에 Set을 Map으로 감싸준 풀이로 제출을 하게 되었다. 이후 불필요한 Map을 지우고 단순 Set을 사용한 풀이로 다시 제출하였다.
import java.util.*; class Solution { public boolean solution(String[] phone_book) { boolean answer = true; HashSet<String> hs = new HashSet<>(); Arrays.sort(phone_book, new Comparator<String>() { public int compare(String str1,String str2) { return str1.length()-str2.length(); } }); for(int i=0;i<phone_book.length;i++) { if(!hs.isEmpty()) { for(int j=0;j<phone_book[i].length()-1;j++) { if(hs.contains(phone_book[i].substring(0,j+1))) { answer = false; break; } } } if(answer) hs.add(phone_book[i]); else break; } return answer; } }
훨씬 깔끔하다 !