💡 오늘의 학습목표
- 애너테이션
- 람다
- 스트림
- 파일 입출력
📔 애너테이션 (Annotation)
- 다른 프로그램에게 유용한 정보를 제공하기 위해
- 컴파일러에게 문법 에러를 체크하도록 정보 제공
- 프로그램 빌드 시 코드 자동 생성할 수 있도록 정보 제공
- 런타임에 특정 기능을 실행하도록 정보 제공
@Test // 아래 메서드가 테스트 대상임을 테스트 프로그램에게 알림.
public void run(){..} //테스트 대상
public void stop(){..} // 테스트 대상이 아님
- 표준 애너테이션 : 자바에서 기본 제공하는 애너테이션
@Override: 컴파일러에게 메서드를 오버라이딩하는 것이라고 알림
@Deprecated: 앞으로 사용하지 않을 대상을 알릴 때 사용
@FunctionalInterface: 함수형 인터페이스라는 것을 알림
@SuppressWarning: 컴파일러가 경고메세지를 나타내지 않음
- 메타 애너테이션 : 애너테이션에 붙이는 애너테이션, 애너테이션 정의에 사용
@Target: 애너테이션을 정의할 때 적용 대상을 지정하는데 사용
@Documented: 애너테이션 정보를 javadoc으로 작성된 문서에 포함시킨다.
@Inherited: 애너테이션이 하위 클래스에 상속되도록 한다.
@Retention: 애너테이션이 유지되는 기간을 정하는데 사용한다.
@Repeatable: 애너테이션을 반복해서 적용할 수 있게 한다.
- 사용자 정의 애너테이션 : 사용자가 직접 정의하는 애너테이션
📖 표준 애너테이션
- @Override
메서드 앞에만 붙일 수 있으며, 선언한 메서드가 상위 클래스의 메서드를 오버라이딩 하는 메서드라는 것을 컴파일러에게 알림.
(메서드 이름 오타 시 에러 발생 알림)class Super { void run() {} } class Test extends Super { @Override // 사용 안하면 다른 메서드로 인식하여 에러 발생 x void ran() {} // 컴파일 에러 발생, 오타 발견 }
- @Deprecated
붙은 대상이 새로운 것으로 대체되었으니 기존의 것을 사용하지 않을 것을 권장
(기존 메서드를 하위 버전 호환성 문제로 삭제x 남겨둘 때)
대상을 사용하는 코드를 쓰면 컴파일 할 때 메세지가 나타남.
- @SuppressWarnings
컴파일 경고 메세지가 나타나지 않도록 한다. (경고 묵인 시 사용)
all: 모든 경고
cast: 캐스트 연산자 관련 경고
dep-ann: 사용하지 말아야 할 주석 관련 경고
deprecation: Deprecated 메서드 사용한 경우 나오는 경고
fallthrough: switch문에서 break 누락 관련 경고
finally: 반환하지 않는 finally 블럭 관련 경고
null: null 분석 관련 경고
rawtypes: 제너릭을 사용하는 클래스 매개 변수가 불특정일 때의 경고
unchecked: 검증되지 않은 연산자 관련 경고
unused: 사용하지 않는 코드 관련 경고@SuppressWarnings("all") //모든 경고 억제
- @FunctionalInterface
함수형 인터페이스 선언 시, 컴파일러가 바르게 선언되었는지 확인하도록 함
(함수형 인터페이스는 단 하나의 추상 메서드만을 가져야함)
📖 메타 애너테이션
애너테이션의 적용대상 또는 유지기간을 정하는 등 애너테이션 정의에 사용
- @Target
애너테이션을 적용할 대상을 지정하는데 사용import static java.lang.annotation.ElementType.*; //import문으로 ElementType.TYPE 대신 TYPE으로 간단히 작성 @Target({FIELD, TYPE, TYPE_USE}) //적용대상이 필드, 타입 public @interface CustomAnnotation {} //커스텀애너테이션 정의 @CustomAnnotation //적용대상이 타입인 경우 class Main { @CustomAnnotation //적용대상이 필드인 경우 int i; }
- @Documented
애너테이션에 대한 정보가 javadoc으로 작성한 문서에 포함되도록 하는 설정- @Retention
애너테이션의 지속 시간 결정RetentionPolicy.SOURCE - 소스파일에 존재, 클래스파일에는 존재x
RetentionPolicy.CLASS - 클래스 파일에 존재, 실행시 사용불가, 기본값
RetentionPolicy.RUNTIME - 클래스 파일에 존재, 실행시 사용가능- @Repeatable
애너테이션을 여러 번 붙일 수 있도록 허용
같은 이름의 애너테이션이 여러번 적용될 수 있기 때문에 하나로 묶어주는 애너테이션 별도 작성 필요@interface Works { //여러개의 애너테이션을 담을 컨데이터 애너테이션 work[] value(); } @Repeatable(Works.class) // 컨테이너 애너테이션 지정 @interface Work { String value(); }
📖 사용자 정의 애너테이션
@interface 애너테이션이름 { //인터페이스 앞에 @ 기호 붙여서 정의
타입 요소명(); // 애너테이션 요소를 선언
}📙 람다식
- 함수형 프로그래밍 기법을 지원하는 자바의 문법 요소
- 메서드를 하나의 식으로 간단하게 표현
//기존 메서드
void say() {
System.out.println("Hi")
}
//같은 메서드 람다식으로 표현
() -> System.out.println("Hi")- 반환타입과 이름 생략 가능 ( 익명함수 )
(int num1, int num2) -> { //반환타입과 메서드명 제거, 화살표 추가
num1+num2 //return 문, ; 제거
}- 메서드 바디에 실행문이 하나만 존재할 때 중괄호 생략 가능
- 매개변수 타입을 쉽게 유추할 수 있는 경우 매개변수 타입 생략 가능
(num1, num2) -> num1+num2 // 타입생략, 중괄호 생략📖 함수형 인터페이스
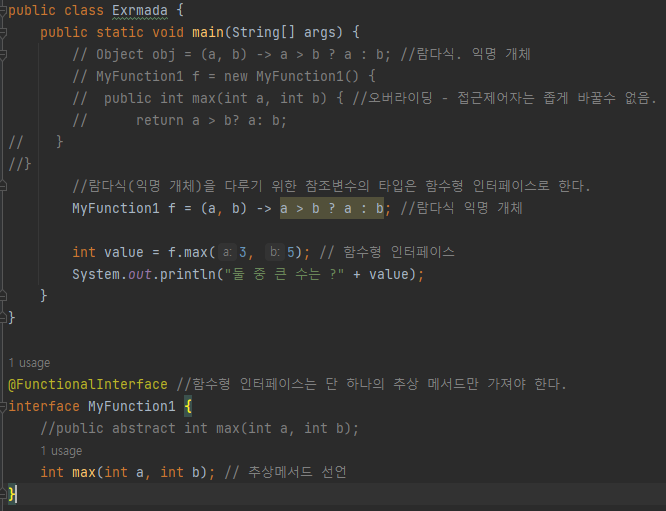
- 람다식은 익명 개체
- 객체에 접근하고 사용하기 위한 참조변수 필요 = 함수형 인터페이스
- 함수형 인터페이스는 람다식과 인터페이스의 메서드가 1:1로 매칭
(단 하나의 추상 메서드만 사용 가능)
메서드 레퍼런스
- 람다식에서 불필요한 매개변수를 제거
(left, right) -> Math.max(left, right);
//클래스이름::메서드이름
Math::max; // 메서드 참조- 인터페이스의 익명 구현 객체로 생성 (인터페이스의 매개변수, 리턴타입 달라짐)
- 정적 메서드, 인스턴스 메서드 참조
클래스 :: 메서드 //정적 메서드 참조 참조 변수 :: 메서드 // 인스턴스 메서드 참조 (먼저 객체 생성)- 생성자 참조
객체를 생성하고 리턴하도록 구성된 람다식은 생성자 참조로 대치 가능
(a,b) -> {return new 클래스(a,b);}; //생성자 참조 문법 클래스 :: new
📔 스트림(Stream)
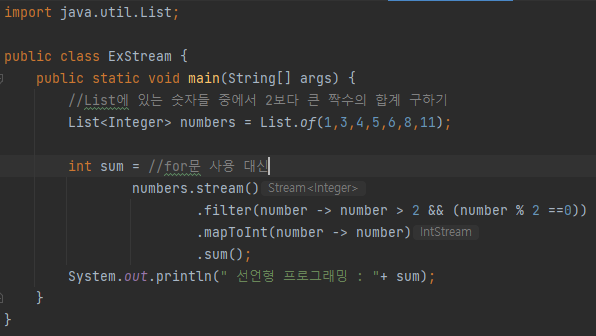
- 배열, 컬렉션의 저장 요소를 하나씩 참조해서 람다식으로 처리할 수 있도록 해주는 반복자
- 선언형 (어떻게보단 무엇을) 으로 데이터 소스 처리
- 람다식으로 요소 처리 코드 제공
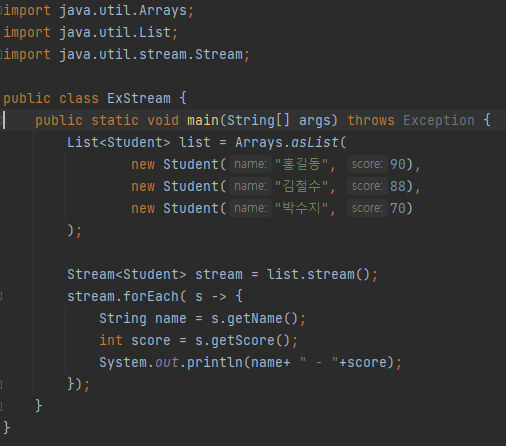
- 내부 반복자를 사용하여 병렬 처리가 쉬움.
외부반복자- 개발자가 코드로 직접 컬렉션의 요소를 반복해서 가져오는 코드 패턴 (for문 / Iterator이용하는 while문)
내부반복자- 컬렉션 내부에서 요소를 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 코드 패턴
(병렬 스트림parallel()메서드) - 중간 연산과 최종 연산 가능
중간연산 - 매핑, 필터링, 정렬 등 수행
최종연산 - 반복, 카운팅, 평균, 총합 등의 집계 수행
- 선언형 (어떻게보단 무엇을) 으로 데이터 소스 처리
📖 파이프라인 구성(.)
- 리덕션 - 대량의 데이터를 가공해서 축소하는 것
- 여러개의 스트림이 연결되어 있는 구조. 최종 연산을 제외하고 모두 중간 연산
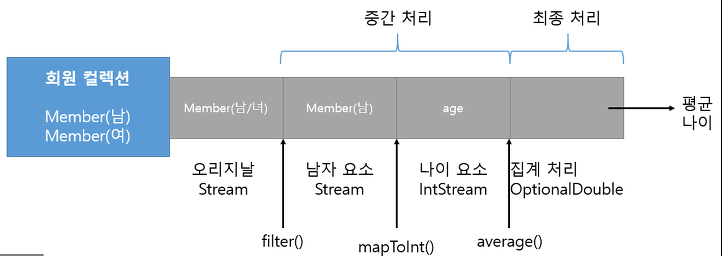
Stream<Member> maleFemaleStream = list.stream();
Stream<Member> maleStream = maleFemaleStream.filter(m -> m.getGender() == Member.MALE);
IntStream ageStream = maleStream.mapToInt(Member::getAge);
OptionalDouble opd = ageStream.average();
double ageAve = opd.getAsDouble();📖 스트림 생성, 중간 연산, 최종 연산
- 컬렉션 인터페이스를 구현한 객체들(List,Set 등) 은 모두
stream()으로 생성 - 스트림은 데이터 소스로부터 데이터를 읽기만 할 뿐 변경x
- 스트림은 일회용, 한번 사용하면 닫힌다.
- 스트림 생성
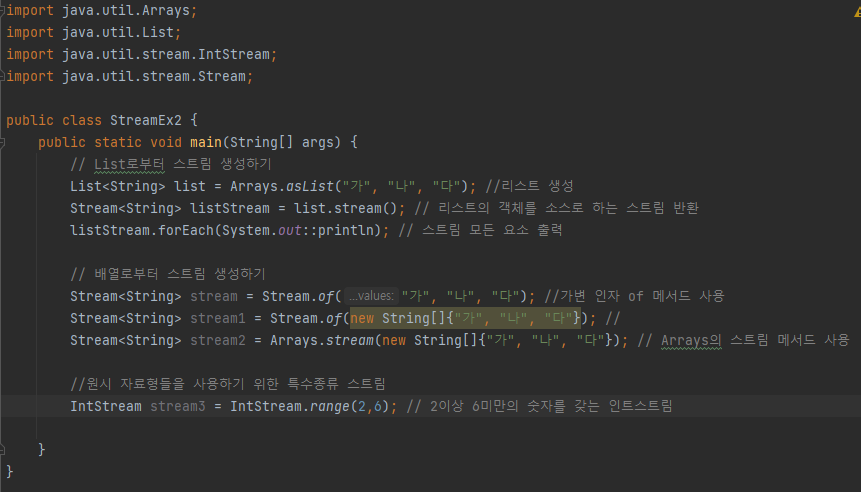
- 스트림 생성
- 중간 연산
연산 결과를 스트림으로 반환, 연속해서 여러 번 수행 가능
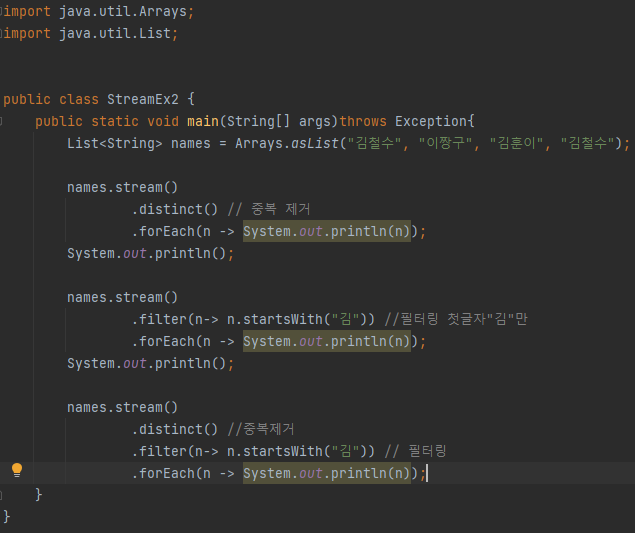
- 필터링(
filter(),distinct())
distinct(): 스트림의 요소들에 중복된 데이터가 존재하는경우 중복 제거
filter(): 조건에 맞는 데이터만을 정제하여 작은 컬렉션 만들기, 매개값으로 조건()이 주어지고 참이 되는 요소만 필터링
- 매핑(
map())
map()기존의 스트림 요소들을 대체하는 요소로 구성된 새로운 스트림 형성
저장된 값을 특정 형태로 변환하는데 사용(인자로 함수형 인터페이스function)
ex) 대문자 String의 요소들로 변환 하고자 할 때 사용 가능List<String> names = Arrays.asList("apple","banana"); names.stream() .map(s-> s.toUpperCase()) .forEach(n->System.out.println(n)); //출력 APPLE BANANA맵 메서드는 일반 스트림 -> 원시 스트림 / 그 반대 작업에 쓰인다.
원시 객체는 mapToObject 를 통해 일반 스트림 객체로 변환 가능
flatMap(): 요소를 대체하는 복수 개의 요소들로 구성된 새로운 스트림 리턴

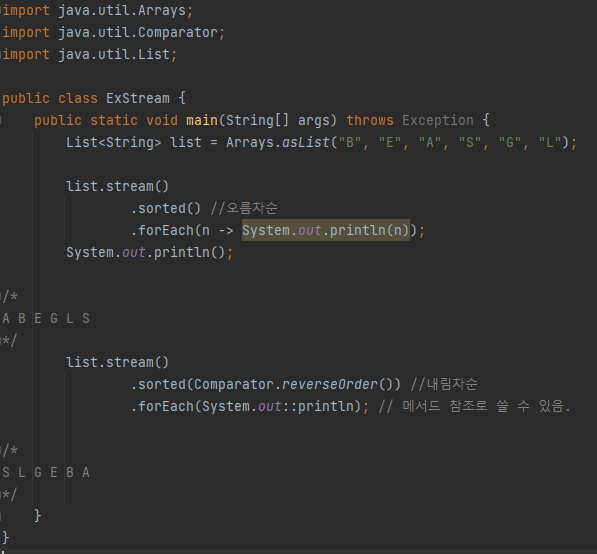
- 정렬(
sorted())
Comparator 인자 없이 호출하면 오름차순, Comparator.reverseOrder 사용하면 내림차순
- 연산 결과 확인 (
peek())
요소를 하나씩 돌면서 출력, 중간 연산 메서드 중간에 결과를 확인할 때 사용intStream .filter(a -> a%2 == 0) .peek(el -> System.out.println(el)) .sum();
- 최종 연산
단 한번만 연산이 가능
- 연산 결과 확인(
forEach())
파이프라인 마지막에서 요소를 하나씩 연산. 값 출력, 이메일 발송, 스케줄링 등.filter(a -> a%2==0) .forEach(n -> System.out.println(n)); //메서드 참조로 System.out::println 으로 쓸 수 있음.- 매칭(
match())
특정한 조건을 충족하는지 검사
1.allMatch(): 모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
2.anyMatch(): 최소한 한 개의 요소가 매개값으로 주어진 Predicate의 조건 만족 조사
3.noneMatch(): 모든 요소들이 매개값으로 주어진 Predicate 조건을 만족하지 않는지int[] arr = {2, 4, 6}; boolean result = Arrays.stream(arr).allMatch(a -> a%2==0); //배열을 스트림으로 System.out.println("모두 2의 배수인가? " + result); // true- 기본 집계(
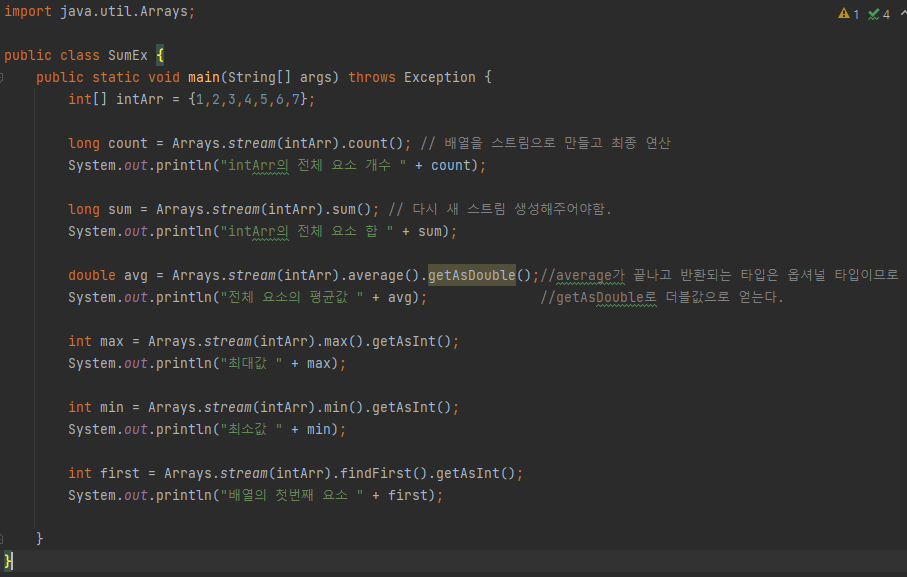
sum(),count(),average(),max(),min())
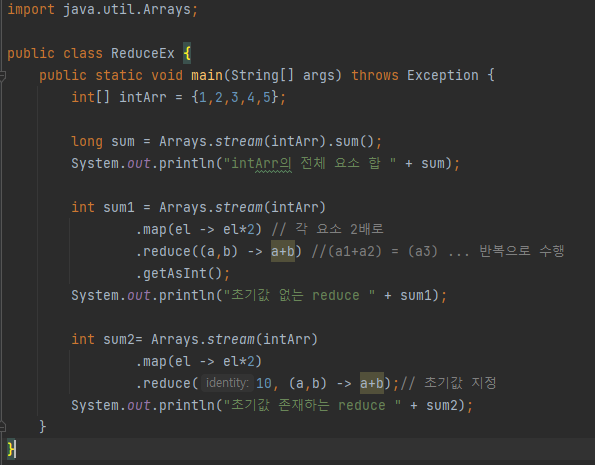
- reduce()
다양한 집계 결과물을 만들 수 있는 메서드.
누적하여 하나로 응축하는 방식 앞의 두 요소의 연산결과를 가지고 다음 요소와 연산
최대 3개의 매개변수
1.Accumulator: 각 요소를 계산한 중간 결과를 생성하기 위해 사용
2.Identity: 계산을 수행하기 위한 초기값
3.Combiner: 병렬 스트림에서 나누어 계산된 결과를 하나로 합치기 위한 로직
- collect()
스트림의 요소들을 List나 Set,Map 등 다른 종류의 결과로 수집하고 싶은 경우
Collecter(어떻게 요소들을 수집할 것인가)타입을 인자로 받는다.//사용 예 List<Student> maleList = totalList.stream() .filter(s -> s.getGender() == Student.Gender.Male) .collect(Collectors.toList()); //리스트로 수집 //.collect(Collectors.toCollection(HashSe::new));
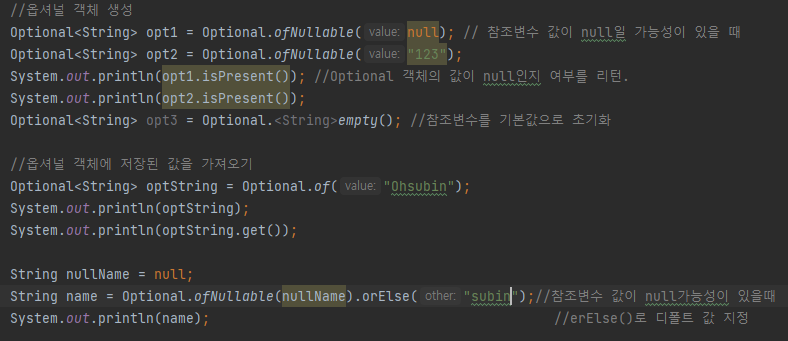
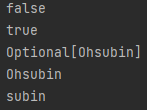
📙 Optional<T>
null값으로 인해 에러가 발생하는 현상을 객체 차원에서 방지하고자 도입
- Optional 클래스는 모든 타입의 객체를 담을 수 있는 래퍼클래스
📔 파일 입출력(I/O)
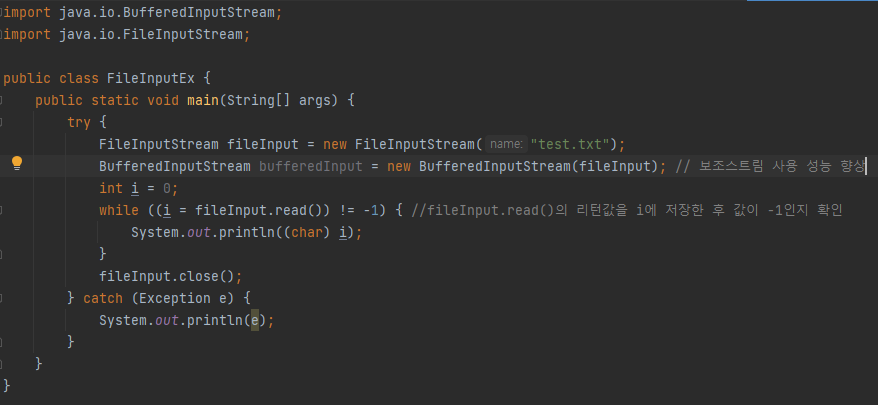
자바에서는 입출력을 다루기 위해 InputStream과 OutputStream 제공 (단방향)
- FileInputStream
터미널에서 파일 생성echo code >> test.txt- FileOutputStream
- FileReader
- FileWriter
회고
오늘은 람다와 스트림을 학습했다. 개념 자체는 어렵지 않았는데 응용부분이 걱정된다. 양이 갈수록 많아지는 느낌이다ㅠㅠ
