Daily coding
//반복문. 가장 긴 문자열 찾기
for(int i = 0; i< arr.length; i++){
//해당 문자열이 max 보다 클 때
if (arr[i].length() >= max) {
max = arr[i].length();
maxIdx = i;
}
}💡 오늘의 학습목표
- SQL
SQL
데이터 베이스의 필요성
In-Memory: 프로그램이 실행될 때에만 존재하는 데이터File I/O: 파일을 읽는 방식으로 작동하는 형태 (데이터 필요 시 전체 파일을 읽어야함)반면에 관계형 데이터베이스는 하나의 CSV파일이나 엑셀 시트를 한 개의 테이블로 저장 가능
데이터를 불러오기 수월하다.
SQL
-
쿼리 : 질의문 ? (검색어가 일종의 쿼리) 데이터를 필터링하기 위한 질의문
-
SQL : 데이터베이스 용 프로그래밍 언어
구조화된 테이블을 사용하는 데이터베이스에서 사용할 수 있다. (NoSQL x)
📖 데이터베이스 관련 명령어
- 데이터 베이스 생성
CREATE DATABASE 데이터베이스_이름;
- 데이터 베이스 사용 (수정이나 삭제 시 사용 명령 우선 전달)
USE 데이터베이스_이름;
- 테이블 생성 (USE를 이용해 선택 후)
CREATE TABLE user ( id int PRIMARY KEY AUTO_INCREMENT, // id 필드 (자동 증가 설정) name varchar(255), // name 필드 (문자열 최대 255개) email varchar(255) //email 필드 (문자열 최대 255개) );
- 테이블 정보 확인
DESCRIBE user
📖 SQL 명령어
- SELECT
데이터 셋에 포함될 특성을 특정SELECT 'hello' // 문자열 SELECT 2 // 숫자 SELECT 5+7 // 연산
- FROM
테이블 관력 작업시 필수 입력, 결과를 도출해 낼 테이블 명시SELECT 특성1, 특정2 // (*) 모든 특성 FROM 테이블_이름
- WHERE
필터 역할, 선택적 사용SELECT 특성1, 특성2 FROM 테이블_이름 WHERE 특성1 = "특정 값" // 특정 값과 동일한 데이터 찾기 WHERE 특성1 <> "특정 값" // 특정 값을 제외한 데이터 찾기 WHERE 특성2 LIKE "%특정 문자열%" // 문자열에서 특정 값과 비슷한 값 필터 WHERE 특성2 IN ("특정값1", "특정값2") // 리스트의 값들과 일치하는 데이터 필터 WHERE 특성1 IS NULL // 값이 없는 경우 널 찾을 때 WHERE 특성1 IS NOT NULL // 값이 없는 경우를 제외할 때
- ORDER BY
데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정, 선택적 사용SELECT * FROM 테이블_이름 ORDER BY 특성1 // 기본 정렬 오름차순 ORDER BY 특성1 DESC // 내림차순 정렬
- LIMIT
결과로 출력할 데이터의 갯수 정하기, 선택적 사용, 가장 마지막에 추가SELECT * FROM 테이블_이름 LIMIT 300 // 데이터 결과를 300개만 출력
- DISTINCT
유니크한 값을 받고 싶을 때SELECT DISTINCT사용SELECT DISTINCT 특성1 // 특성1 기준으로 유니크한 값들만 선택 , 여러 특성 조합값 선택 가능 FROM 테이블_이름
- INNER JOIN
INNER JOIN이나JOIN으로 실행할 수 있다.SELECT * FROM 테이블1 JOIN 테이블2 ON 테이블1.특성A = 테이블2.특성B // 둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결
- OUTER JOIN
SELECT * FROM 테이블1 LEFT OUTER JOIN 테이블2 ON 테이블1.특성A = 테이블 2.특성B //LEFT INCLUSIVE 실행 RIGHT OUTER JOIN 테이블2 ON 테이블1.특성A = 테이블 2.특성B//RIGHT INCLUSIVE 실행 FULL OUTER JOIN // 전체 외부 포괄 조인이나 배타 조인

🔍 SQL More
집합연산 : 레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산
- GROUP BY
데이터 조회 시 그룹으로 묶어서 조회SELECT * FROM customers GROUP BY State; //주 에 따라 그룹으로 묶어 표현 각 그룹의 첫번째 데이터만 표현
- HAVING
그룹 바이로 조회된 결과를 필터링 할 수 있다.SELECT CustomerId, AVG(Total) // 조회 FROM invoices // 이 테이블을 GROUP BY CustomerId // 아이디로 그룹화 하고 HAVING AVG(Total) > 6.00 // 평균이 6 초과한 결과를그롭화 전에 데이터를 필터해야 하면 WHERE 사용
- 그룹에 대해 할 수 있는 작업
- COUNT()
레코드의 갯수 세기SELECT *, COUNT(*) FROM customers GROUP BY State; // 각 그룹의 첫번째 레코드와 각 그룹의 레코드 갯수 집계SELECT State, COUNT(*) FROM customers GROUP BY State; // 각 state에 해당하는 레코드의 갯수 확인
- SUM()
레코드의 합 리턴SELECT InvoiceId, SUM(UnitPrice) // 유닛가격 필드의 합 구하기 FROM invoice_items // 이 테이블에서 GROUP BY InvoiceId; // 아이디를 기준으로 그룹화 하고
- AVG()
평균값 계산- MAX(), MIN()
최댓값과 최소값 리턴
- SELECT 실행 순서
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
📙 트랜잭션
여러개의 작업을 하나로 묶은 실행 유닛.
ACID
데이터 베이스 내에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질
- Atomicity (원자성)
하나의 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해서 결과를 예측 - Consistency(일관성)
하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다. - Isolation(고립성)
모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다. - Durability(지속성)
하나의 트랜잭션이 성공적으로 수행되면 영구적 기록인 로그가 남아야한다.
SQL / NoSQL
- SQL : 관계형 데이터베이스에 사용 (MySQL, Oracle ...)
- NoSQL : 비관계형 데이터베이스에 사용(몽고DB, Casandra..)
- NoSQL
- Key-Value 타입
- 문서형 데이터베이스
- Wide-Columm 데이터베이스
- 그래프 데이터베이스
데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
클라우드 컴퓨팅 및 저장공간을 최대한 활용
빠른 서비스 구축과정에서 데이터 구조를 자주 업데이트 하는 경우 - NoSQL
실습
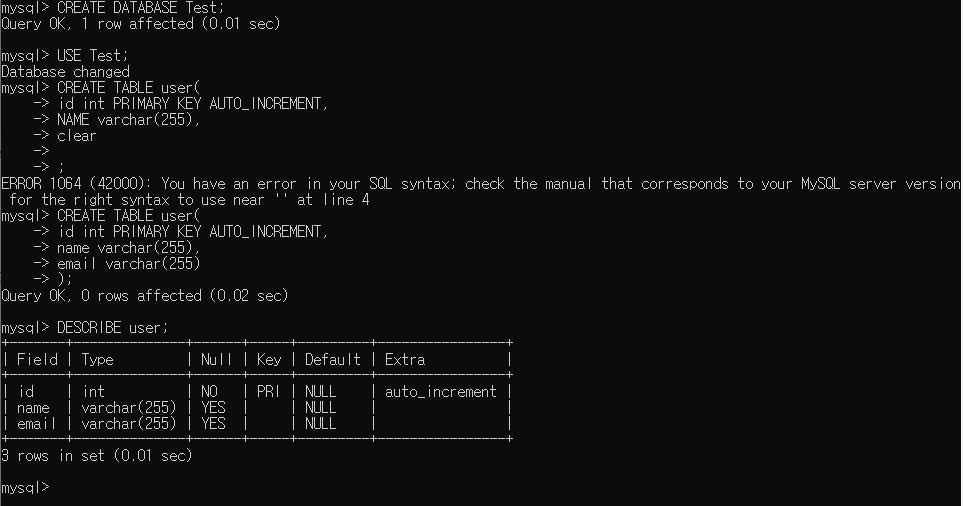
퀴즈

코린이의 공부 일지