진법
: 한 자릿수에 표현할 수 있는 숫자의 개수.
~진법이라는건, 한 자릿수를 ~가지의 숫자나 문자로 나타낼 수 있다는 것. ~진법으로 나타낸 수를 n진수.
해당 수가 어떤 진수인지 표기하기 위해서 숫자의 맨 오른쪽에 아래 첨자를 사용하여 진수 표기. 라 쓰면 2진수. 이런느낌. AF1216 이거는 16진수.
2진법: 0,1로 수 표현.
전기 신호를 기준으로 on일때 1, off일때 0으로 구분.
비트: 0,1의 조합
바이트: 비트가 8개 모인것.
데이터: 바이트들이 모인것.
2진수 표현시 0b라는 접두어 붙임.
ex. 10진수 7을 2진수로 표현하면 0b111, 10진수 13을 2진수로 표현하면 0b1101
(참고로 앞에 붙은거 대문자 O 아니고 숫자 0임.)
10진법: 0~9 (10개의 수)로 표현.
16진법: (0~9, A~F)로 수 표현.
16진법이 필요해진 이유: 컴퓨터는 기본적으로 2진법을 쓰지만 2진법은 수가 조금만 커져도 표현시에 많은 글자수가 필요함. --> 비효율적.
2진수를 간편하게 표현하기 위해서 다른 진법으로 표현할 필요성.
그 중 16진법이 쓰임.
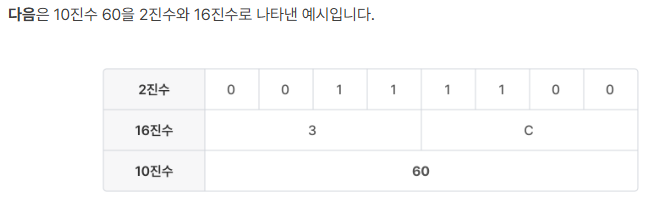
ex. 2진수 4자리를 16진수 한 자리로 축약하여 표현이 가능.
0b1100 --> 0xC
16진수의 쓰임: 디버깅 도구(프로그램 분석할 때 쓰는 툴)에서 메모리 위치를 나타내는 주소값을 16진수로 출력, RGB 색상 표현 시 16진수 형태로 표기
16진수 표현시 0x라는 접두어 붙임.
(참고로 앞에 붙은거 대문자 O 아니고 숫자 0임.)
ex. 10진수 12를 16진수로 표현하면 0xC
비트와 바이트
1비트: 컴퓨터에서 사용하는 데이터의 최소 단위(0,1을 나타냄)
1바이트: 8개의 비트로 구성된 단위.
1바이트는 2의 8승=256가지 수를 표현할 수 있다.
10진수로 0~255, 2진수로 00000000~11111111, 16진수로 00~FF까지 나타냄.
2진수 한자리는 1비트니까 1바이트는 8비트인것.
8진수 한자리는 3비트
16진수 한자리는 4비트
16진수 한 자리를 2진수 네자리로 변환하는 방식과 그 역은 진법 변환을 쉽게 함.

2진수 <--> 16진수 진법 변환
참조: https://wony-wony.tistory.com/13
2의 4승이니까 16진수 한자리가 2진수 네자리인것임.
8진수 한자리는 2진수 세자리임.
변환 원리는 소수점 기준으로.
정수 부분은 왼쪽.
소수 부분은 오른쪽으로.
8진수로의 변환은 3자리씩, 16진수로의 변환은 4자리씩 묶어 변환함.
진법 변환 배우기
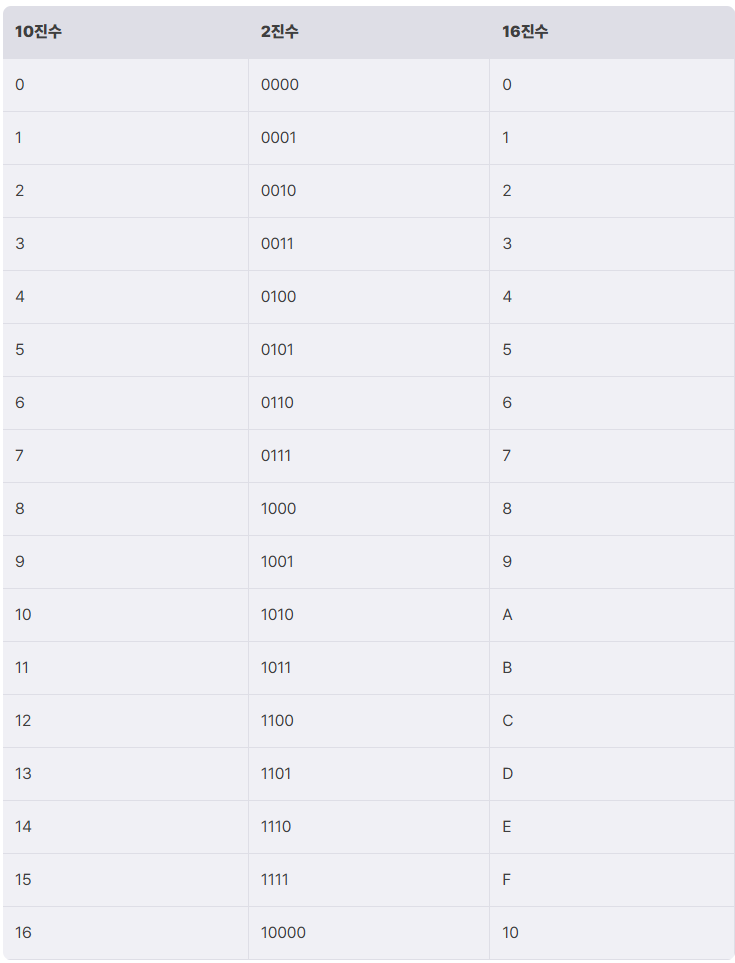
최상위비트(MSB) / 최하위비트(LSB)
최상위비트(Most Significant Bit): 여러 개의 비트로 구성된 이진 데이터에서 가장 왼쪽에 있는 비트
최하위비트(Least Significant Bit): 여러 개의 비트로 구성된 이진 데이터에서 가장 오른쪽에 있는 비트
중요하다(significant) 라는 표현을 붙이는 이유는, 가장 왼쪽에 있는 비트가 숫자의 크기에 가장 큰 영향을 미치기 때문이다.
가장 오른쪽에 있는 비트는 숫자의 크기에 가장 작은 영향을 미치기 때문에 그러한 명명이 붙었다.
ex. 2진수 Ob10010100의 MSB와 LSB를 표시하면 아래와 같다.
이때 Ob10010100의 최상위비트는 1이고, 최하위비트는 0이라고 말할 수 있다.
부호 비트
부호가 있는 데이터의 경우, MSB는 부호의 의미를 가지게 된다.
MSB가 0이면 +
1이면 -
프로그래밍 언어에서
부호(+,-)를 가지는 데이터는 signed 데이터라 또는 부호가 있는 데이터라 부르고,
부호 없이 양수(+)로만 나타내는 데이터는 unsigned 데이터 또는 부호가 없는 데이터라 부른다.
ex. Ob10010100 은 부호가 있는 데이터이고
MSB가 1이기 때문에 10진수로 표현하면 음수인 -108이 됨.
반면 부호가 없는 데이터라면,
MSB인 1은 부호를 의미하지 않고 값을 의미하므로 양수인 148이 됨.
바이트 오더링(Byte Ordering)
2바이트 이상 데이터는 메모리에 연속적으로 저장된다.
→ 왜 2바이트 이상 데이터부터 연속이지
바이트 오더링: 메모리에 각 바이트가 정렬되는 방식
바이트 오더링에는 어떤 바이트부터 낮은 주소에 저장되는지에 따라 두 가지 방식이 있다.
1. 빅 엔디안 (big endian)
2. 리틀 엔디안 (little endian)
엔디안 : 바이트들의 정렬 순서를 결정하는 방식
(왼쪽에 있는 바이트일수록 크다)
ex. 0x01234567과 같은 데이터가 있을 때
가장 왼쪽의 0x01이 가장 큰 바이트이고,
가장 오른쪽의 0x67이 가장 작은 바이트이다.
빅 엔디안은 큰(big) 바이트부터 낮은 주소에 저장된다.
반대로 리틀 엔디안은 작은(little) 바이트부터 낮은 주소에 저장된다.
어떤 자료에서 MSB, LSB를 이용하여 빅 엔디안, 리틀 엔디안을 설명할 때
이때의 MSB, LSB는 significant bit를 의미하는게 아니라
significant byte를 의미한다.
바이트 오더링은 비트의 순서가 아니라 바이트의 순서를 고려하는 것으로, 바이트 내 비트의 순서는 동일하고 바이트의 순서만 달라진다.
따라서 가장 왼쪽에 있는 바이트를 MSB(most significnat byte),
가장 오른쪽에 있는 바이트를 LSB(least significant byte)라 표현했다고 이해하면 된다.
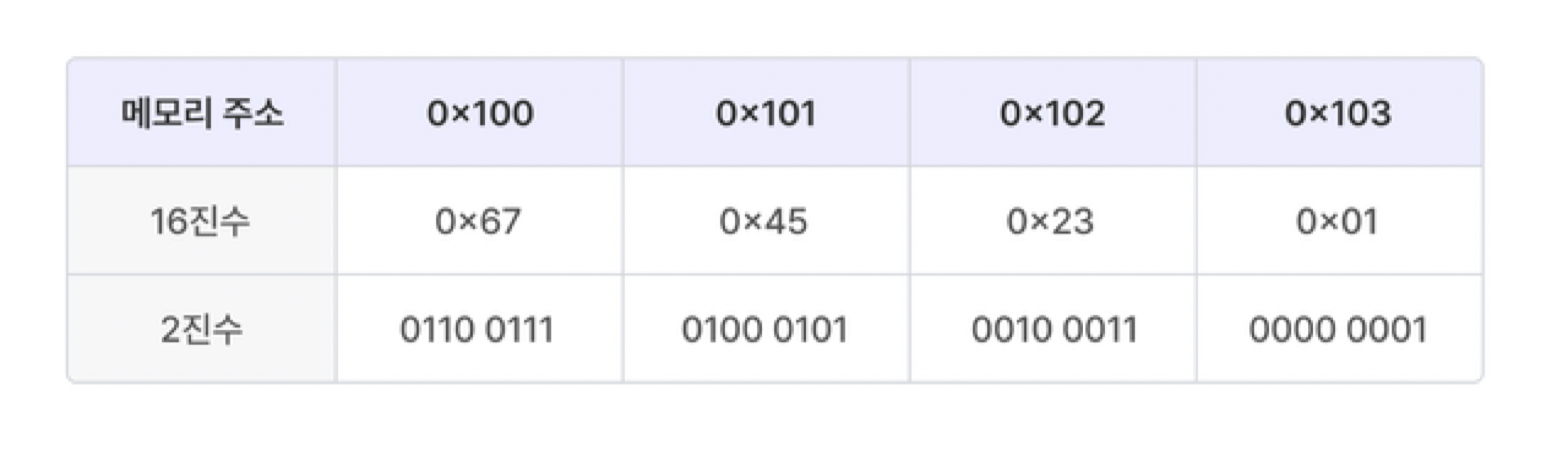
하단에 등장하는 이미지들은 4바이트 16진수 0x01234567 (2진수 0000 0001 0010 0011 0100 0101 0110 0111)을 메모리 주소 0x100에 저장한 결과이다.
PS. 16진수 2개는 2진수 8개이다.
- 빅 엔디안
가장 왼쪽에 있는(큰) 바이트부터 메모리의 낮은 주소에 저장된다.
네트워크 상에서 데이터를 전송할 때는 빅 엔디안 방식을 따른다.
대표적으로 SPAFC CPU에서 빅 엔디안을 사용한다.
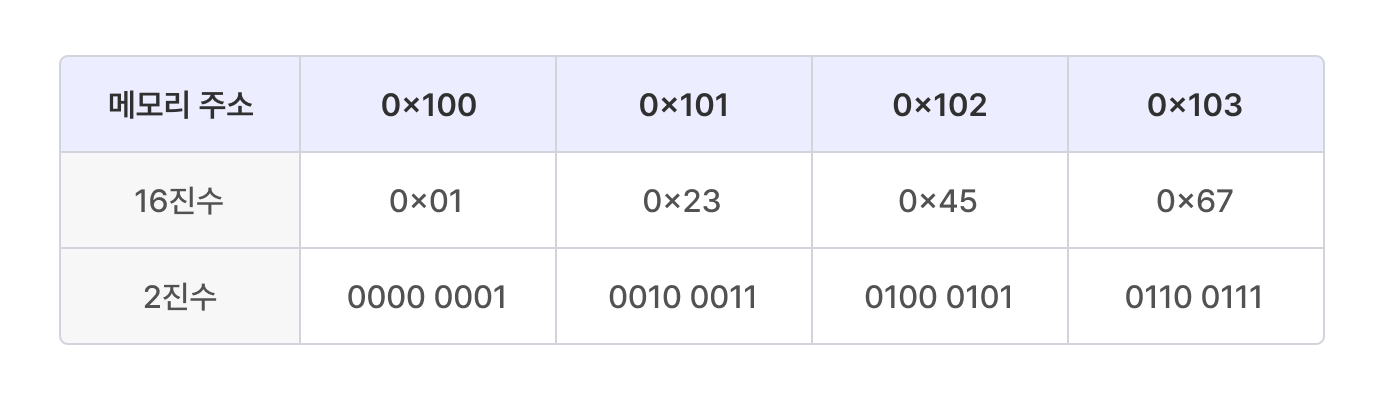
- 리틀 엔디안
가장 오른쪽에 있는(작은) 바이트부터 메모리의 낮은 주소에 저장된다.
대표적으로 Intel의 x86, x86-64 CPU에서 리틀 엔디안을 사용한다. 대다수의 개인용 컴퓨터 및 서버 환경에서 x886-64 CPU 아키텍처를 사용하고 있는 만큼, 리틀 엔디안 방식을 잘 알아야 함.
바이트 오더링 예시
해킹 분야에서는 정교해야하기 때문에 데이터가 어떤 바이트 오더링으로 메모리에 저장되었는지 고려하는 것은 기본이다.
예를 들어, 리버스 엔지니어링 분야에서 메모리에 저장된 값을 이용해 역연산을 수행하여 어떤 정답이 되는 값을 찾아내는 작업은 매우 흔하다.
이때 메모리에 저장된 값이 어떤 엔디안으로 저장되어 있는지를 고려하지 않으면,
전혀 다른 데이터로 혼동하여 올바른 역연산 결과를 얻을 수 없게 된다.
ex. 앞서 살펴본 예시와 같이 리틀 엔디안 방식으로 저장된 0x01234567을 빅 엔디안으로 생각하고 0x67452301이라는 숫자로 다뤄버리면, 결국 전혀 다른 데이터를 가지고 역연산을 수행하는 꼴이 되므로 올바른 결과를 얻을 수 없게 된다.
→ 왜 0x7654321 이 아니라 0x67452301일까
시스템 해킹을 예로 들어 보겠다.
공격을 위해 특정 메모리 주소에 원하는 값을 덮어씌워야 한다고 가정하자.
메모리의 낮은 주소부터 값을 쓰는 경우라면 리틀 엔디안을 고려하여 저장하려는 값의 가장 오른쪽 바이트부터 써야 원하는 값이 제대로 저장된다.
또한 어떤 변수의 출력값을 알아내려고 한다면, 메모리의 변수 주소 영역에서 높은 주소부터 값을 읽어온다는 것을 고려해야 한다.
현실에서 많은 개인용 컴퓨터와 서버 환경이 x86 아키텍처를 사용하고 있고,
이에 따라 드림핵 강의들 역시 대부분 x86 아키텍처 환경을 기준으로 설명하고 있다.
하단의 코드는 문자열과 16진수 정수를 메모리에 저장하는 c프로그램의 소스코드이다.
각각 메모리에 저장된 값과 출력값을 직접 확인하여 리틀 엔디안 방식이 어떻게 적용되었는지 알아보자.
#include <stdio.h>
#include <stdlib.h>
int main(void) {
char * str = "ABCD"; // 16진수: 41424344
puts(str); // 문자열 출력 결과: ABCD
unsigned int num = 0;
num = 0x41424344;
printf("%x\n", num); // 16진수 출력 결과: 41424344
return 0;
}- 문자열
str 변수 주소의 메모리를 1바이트식 4바이트 출력한 결과이다.
문자열을 메모리에 저장할 때는 바이트 오더링을 고려하지 않는다.
따라서 문자열 "ABCD"는 리틀 엔디안 방식을 따르지 않고,
문자 순서 그대로 메모리에 저장된다.
0x555555556004: 0x41 0x42 0x43 0x44- 문자열이 아닌 데이터 - 16진수 정수
num 변수 주소의 메모리를 1바이트씩 4바이트 출력한 결과이다.
문자열이 아닌 데이터는 리틀 엔디안 방식으로 저장된다.
따라서 16진수 0x41424344는 가장 오른쪽의 바이트부터 메모리의 낮은 주소에 저장된 것을 볼 수 있다.
num 변수 값을 출력하면 메모리에 저장된 4바이트에서 높은 주소부터 읽어 와서 원래 값 그대로 출력된다.
0x7fffffffe314: 0x44 0x43 0x42 0x41비트 연산
비트 연산 : 피연산자를 2진수로 표현하여 비트 단위로 연산하는 것
피연산자: A+B에서 +는 연산자, A와 B는 피연산자
비트 단위로 논리 연산을 수행하거나 비트를 특정 값만큼 이동하는 시프트(shift) 연산을 수행한다.
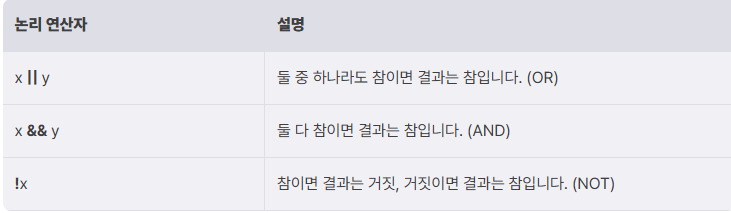
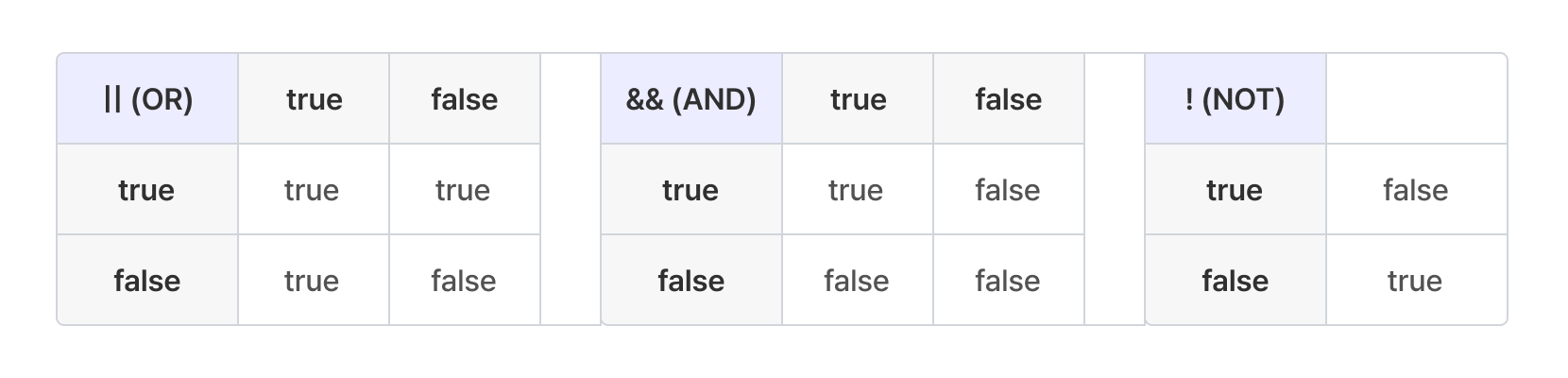
- 논리 연산
참 또는 거짓 값으로 연산을 수행하고 결과로 참(1, true) 또는 거짓(0, false)을 반환한다.
- 비트 연산자
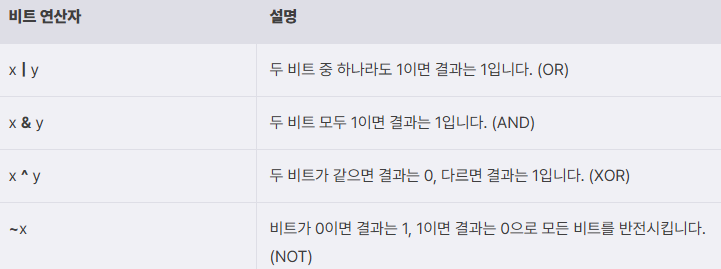
비트 단위로 논리 연산을 수행한다. 1은 참, 0은 거짓을 나타냄.
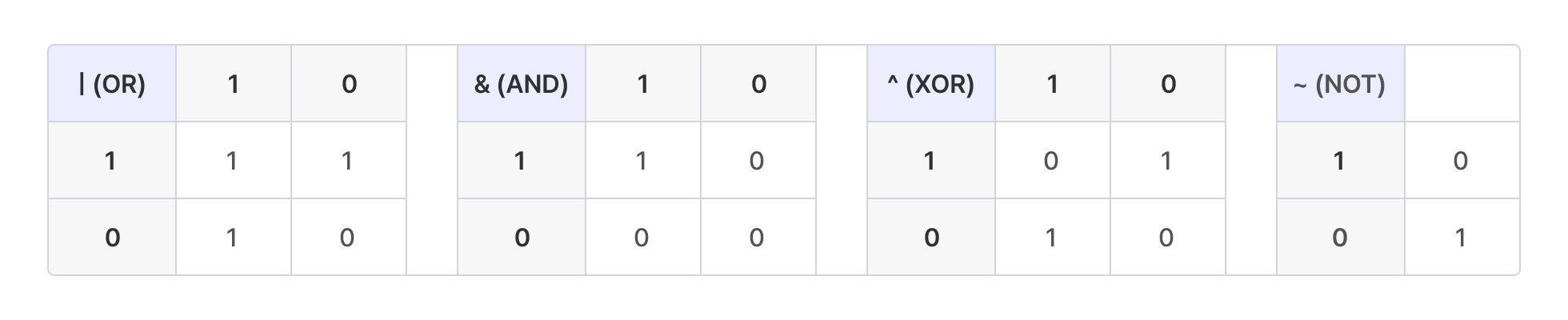
비트 연산자 OR (|) 예시
0b1010 | 0b1100 = 0b1110이다.
대응하는 비트 중 하나라도 1이면 1이 된다. 둘 다 1이 아닌 경우에만 0이 된다.
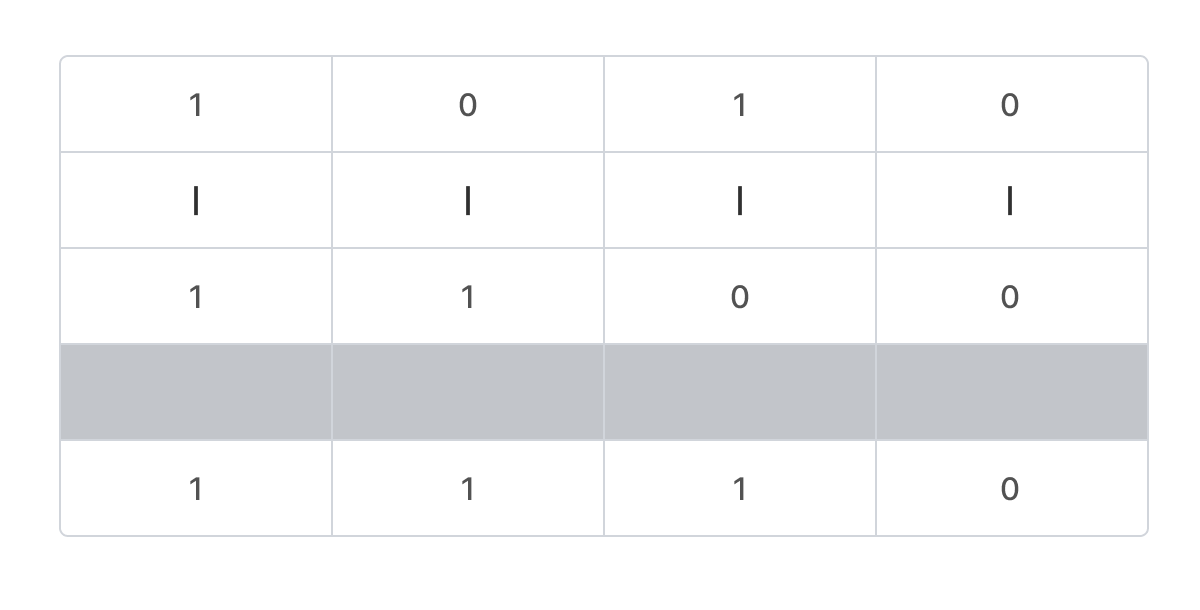
비트 연산자 AND (&) 예시
0b1010 & 0b1100 = 0b1000이다.
대응하는 비트가 모두 1이어야 되며, 하나라도 1이 아니면 0이 된다.
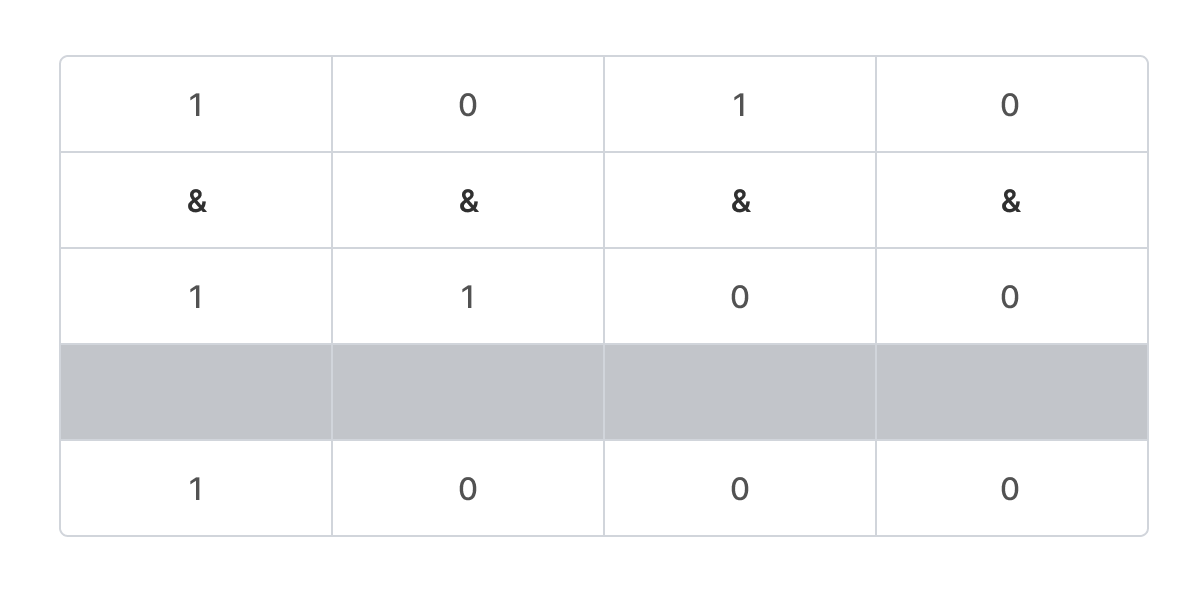
비트 연산자 XOR (^) 예시
0b1010 ^ 0b1100 = 0b0110이다.
대응하는 비트가 서로 다르면 1이 되고 서로 같으면 0이 된다.
→ XOR연산은 비트 값이 같으면 0을 반환하니까 자기 자신과 XOR연산을 하면 결과가 0이 됨. 두 변수에 저장된 값끼리 XOR 연산하여 결과가 0인지 확인하면 두 값이 같은지 비교할 수 있다.
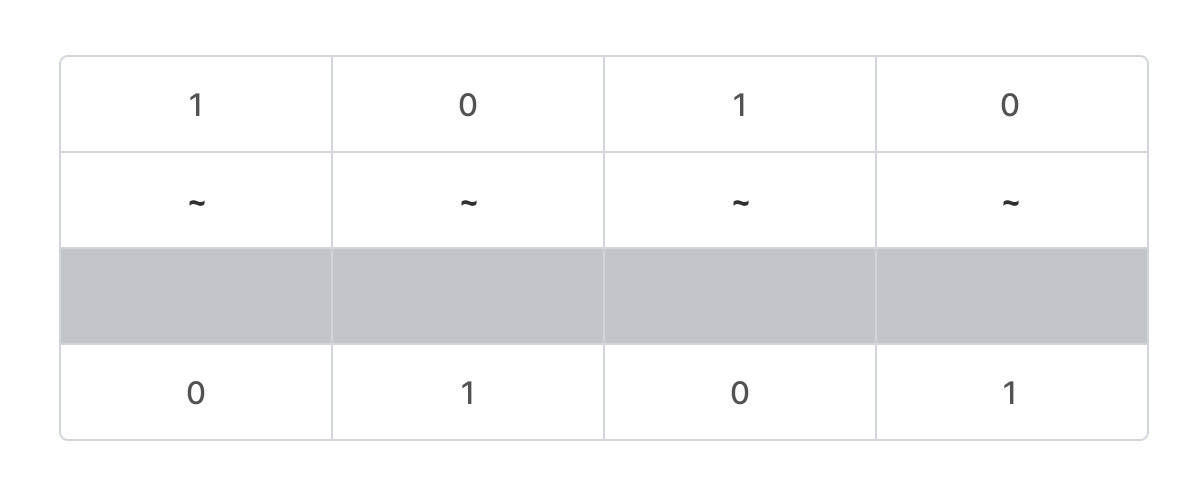
비트 연산자 NOT (~) 예시
~0b1010 = 0b0101이다. 다음과 같이 비트를 반전한다. 0은 1이 되고, 1은 0이 된다.
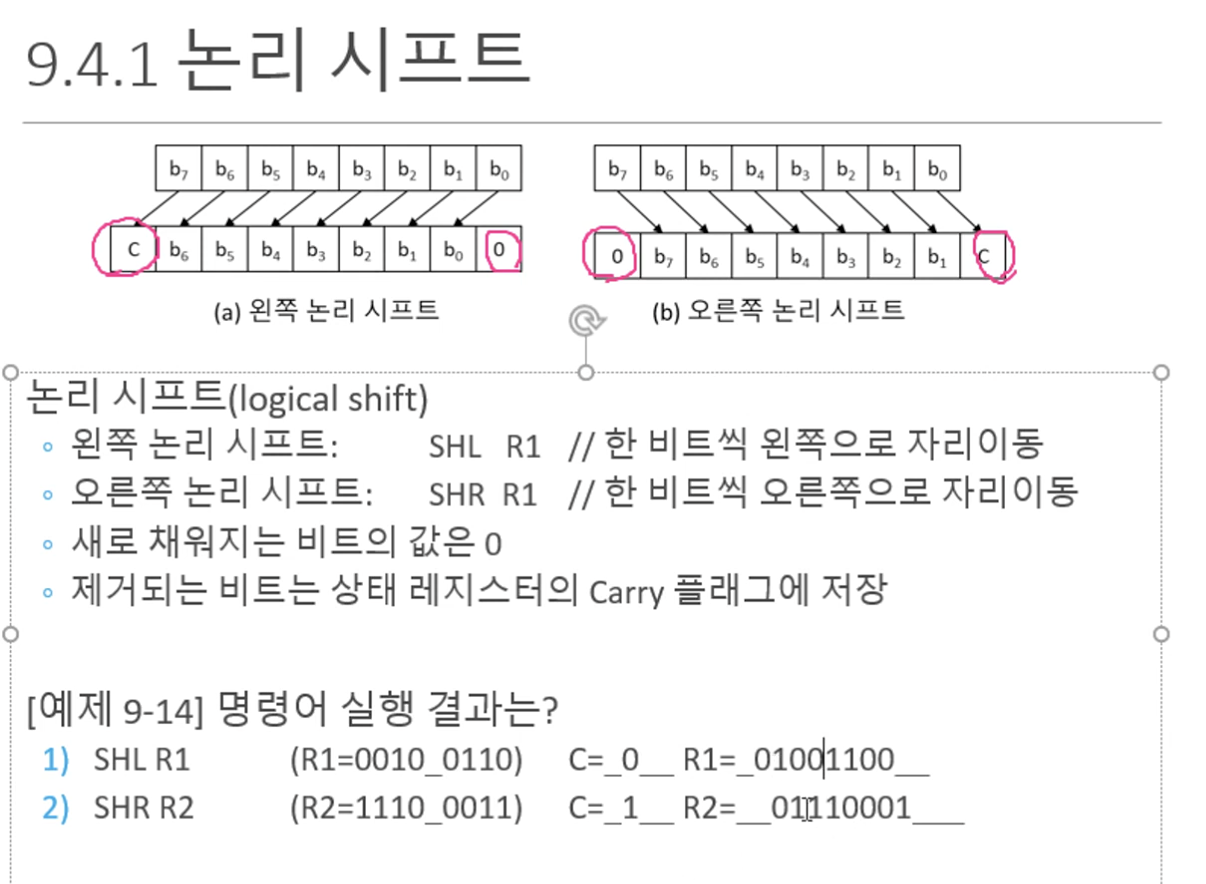
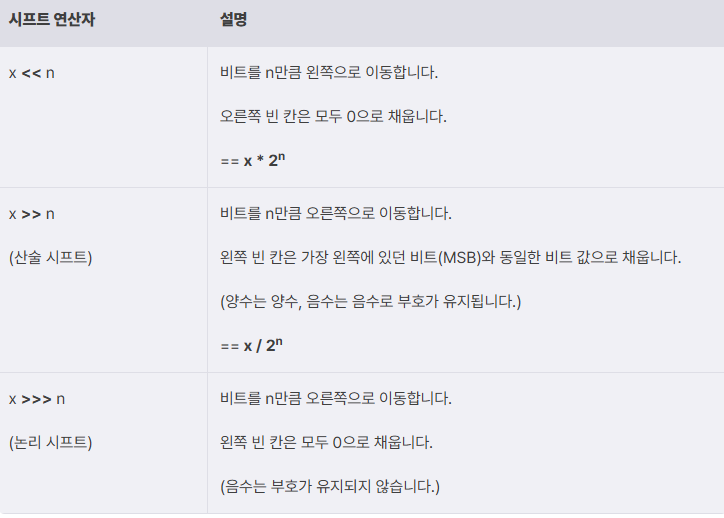
- 시프트 연산자
signed : 부호를 갖는(0은 양수, 1은 음수) 변수 선언 자료형
(ex. 산술시프트)
unsigned : 음수를 사용하지 않고, 0 추가하는 자료형 (항상 양수)
(ex. 논리시프트)
비트를 특정 값만큼 왼쪽 혹은 오른쪽으로 이동한다.
n만큼 시프트한 결과는 으로 곱하거나 나눈 값과 같다.
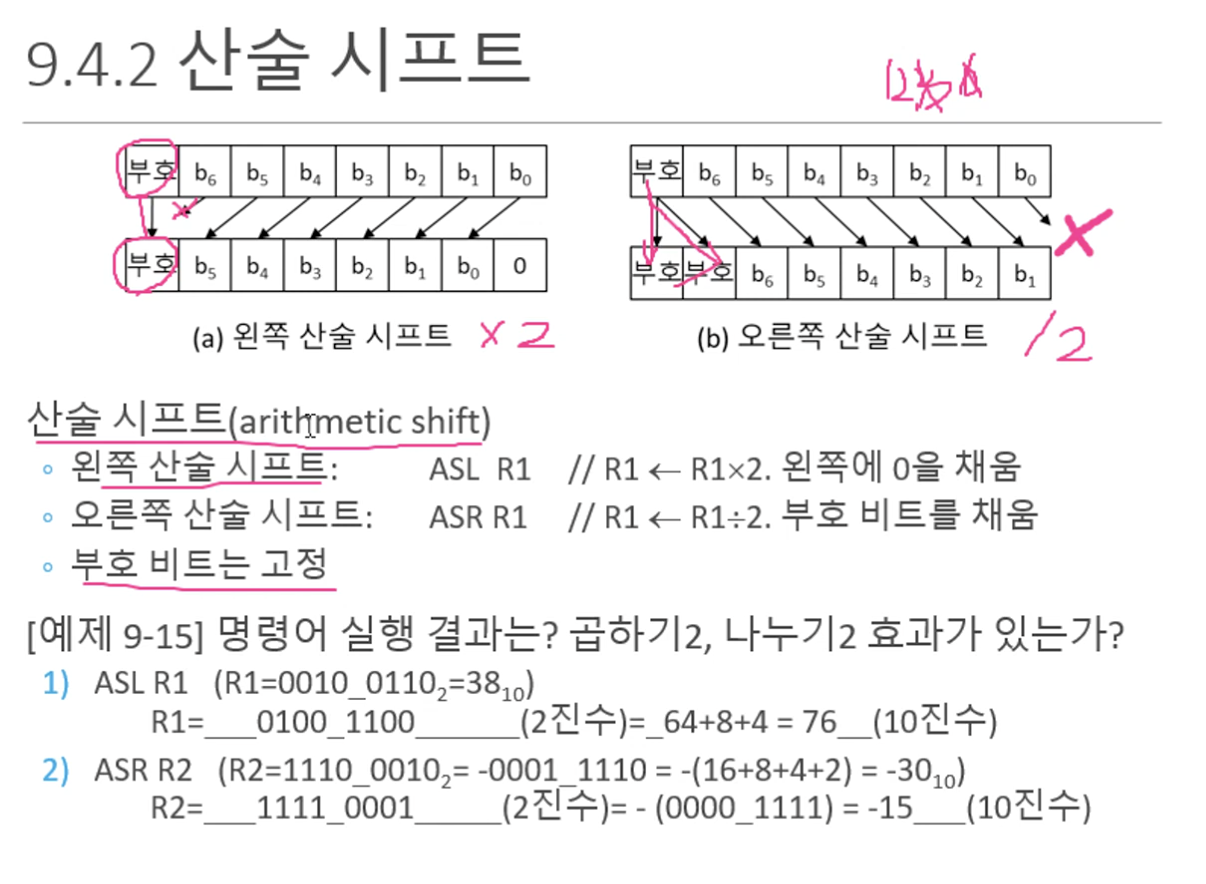
좌측 산술 시프트 : MSB는 안 변하고 수의 크기를 나타내는 비트들을 좌측으로 한칸씩 시프트하고
우측 산술 시프트 : 부호비트가 그 우측의 비트로 복사됨.
아래 표는 2바이트 즉, 16비트 크기를 가지는 데이터 273을 왼쪽으로 4비트만큼 시프트하는 모습을 보여준다. 10진수 273은 2진수로 0000 0001 0001 0001이다.
이를 4비트만큼 왼쪽으로 이동하면, 0001 0001 0001 0000이 되고, 10진수로는 4368이다.
앞서 언급하였듯이 1비트 왼쪽으로 시프트하는 행위는 데이터에 을 곱하는 것과 같다. 4비트 시프트하므로 273에 (16진수 한 자리)을 곱하면 마찬가지로 4368이 나온다는 사실을 알 수 있다.

아래 표는 2바이트 즉, 16비트 크기를 가지는 데이터 32529를 우측으로 4비트만큼 산술 시프트하는 모습을 보여준다.
10진수 32529는 2진수로 0111 1111 0001 0001이다.
우측 산술 시프트는 MSB(최상위비트)가 1이면 1로 채우고, 0은 0으로 채운다. 해당 데이터는 MSB가 0이므로 4비트만큼 우측 산술 시프트를 가하면, 0000 0111 1111 0001이 된다.
*2진수인데 오른쪽으로 4비트가 밀리니까 맨 오른쪽부터 읽어야 함.
맨오른쪽부터, 1000부터 오른쪽으로 밀리는 것임. 그 다음 1000부터 시작이 되는 것.
*처음 0111에서 가장 왼쪽 0은 MSE(최상위비트)라서 나중에 우측 산술 시프트에서 비어있는 4비트 채울 때 0000으로 채워짐.

아래 표에서 산술 시프트를 가할 데이터는 1111 1111 0001 0001이다. 이는 10진수 음수로는 -239이고 양수로는 65297이다.
우측 산술 시프트는 MSB가 1이면 1로 채우고, 0이면 0으로 채운다.
따라서 해당 데이터에 4비트만큼 우측 산술 시프트를 가하면, 1111 1111 1111 0001이 된다.
이는 10진수 음수로는 -15이고, 양수로는 65521이다.
*처음 1000에서 가장 오른쪽 1은 MSB(최상위비트)라서 나중에 우측 산술 시프트를 가하면 1 네 개로 채워짐.
*이건 오른쪽부터 읽는 것임. 맨 오른쪽부터 1000 1000 1111 1111인데,
맨 오른쪽의 4비트가 밀리는 거니까, 처음 1000이 밀리고, 그 다음 1000부터 시작.

→ MSB(최상위비트)는 시프트 연산자 종류와 상관없이 무조건 왼쪽에 위치한다.
아래 표는 1111 1111 0001 0001에 4비트만큼 우측으로 논리 시프트를 가하는 모습이다. MSB에 상관없이 0으로 채우기 때문에 0000 1111 1111 0001이 된다.

아래 표는 0111 1111 0001 0001에 4비트만큼 우측으로 논리 시프트를 가하는 모습이다. 마찬가지로 MSB에 상관없이 0으로 채우기 때문에 0000 0111 1111 0001이 된다.

비트 연산 활용
- AND (&) 연산을 활용한 비트 마스킹
비트 마스킹 : 어떤 데이터가 존재할 때 특정 위치의 비트만 표시하거나 가리는 연산
앞서 살펴보았듯이 AND 연산은 대응하는 비트가 모두 1이어야 1이 된다. 대응하는 비트 중에 하나라도 0이면 0이 된다. 이러한 AND 연산의 특징을 활용한 비트 마스킹의 예는 다음과 같다.
(=특정 비트 부분을 없애고 다음 비트 부분은 원래 비트와 똑같이 유지할 수 있음)
예를 들어 2바이트 크기의 데이터인 0xABCD가 존재할 때,
AND 연산을 활용하면
상위 8비트에 해당하는 0xAB는 없애고,
하위 8비트에 해당하는 0xCD만 남길 수 있다.
이를 위해 다음과 같이 0xABCD에 0x00FF를 AND 연산하면 된다.
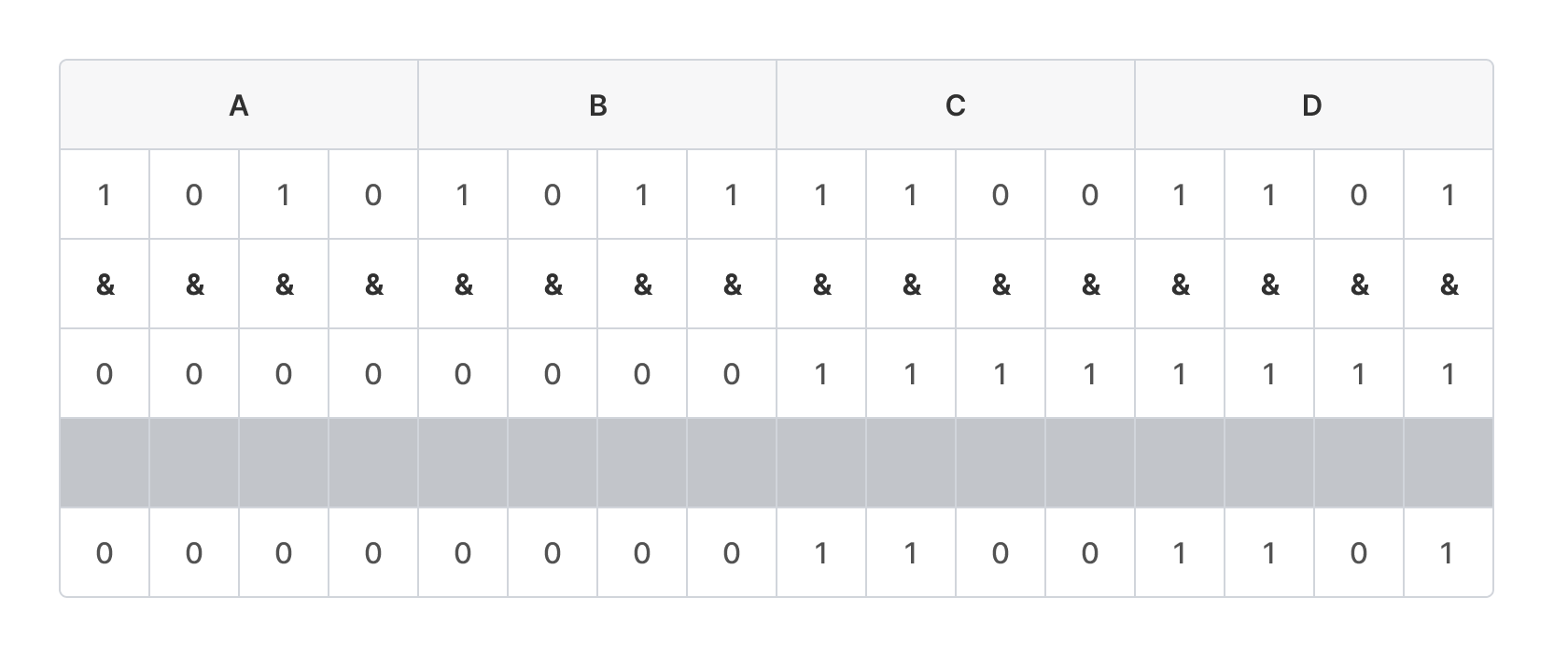
16진수 F(1111)는 특정 값과 AND 연산하면 기존 값에서 비트 값이 1이면 결과가 1, 0이면 결과가 0이기 때문에 기존 값과 동일한 결과가 나온다.
반대로 0(0000)은 특정 값과 AND 연산하면 모든 비트가 0이 되어 결과는 0이다.
따라서 상위 1바이트인 0xAB는 모두 0이 되고,
하위 1바이트인 0xCD는 1인 비트만 남아 결국 0xCD가 남는다.
- AND (&) 연산과 시프트 연산을 활용하여 특정 비트/바이트 가져오기
또한 AND 연산과 시프트 연산을 함께 활용하면 특정 위치의 비트를 가져올 수 있다.
다음은 32비트 즉, 4바이트 크기의 데이터인
0x12345678 (0001 0010 0011 0100 0101 0110 0111 1000)에서 특정 비트만 가져오는 예시이다.
- 하위 1바이트만 가져오기: 0x000000FF와 AND 연산한다.
0x12345678 & 0x000000FF = 0x00000078 (0000 0000 0000 0000 0000 0000 0111 1000)- 상위 1바이트만 가져오기: 24번 우측으로 논리 시프트를 수행한다. 또는 24번 우측으로 산술 시프트한 후, 0x000000FF와 AND 연산한다.
0x12345678 >>> 24 = 0x00000012 (0000 0000 0000 0000 0000 0000 0001 0010)
0x12345678 >> 24 & 0x000000FF = 0x00000012 (0000 0000 0000 0000 0000 0000 0001 0010)- 상위에서 두 번째 바이트 가져오기: 16번 우측으로 시프트 후 0x000000FF와 AND 연산한다.
0x12345678 >> 16 & 0x000000FF = 0x00000034 (0000 0000 0000 0000 0000 0000 0011 0100)- 하위 1바이트의 상위 4비트 가져오기: 4번 우측으로 시프트한 후 0x000000FF와 AND 연산한다.
0x12345678 >> 4 & 0x0000000F = 0x00000007 (0000 0000 0000 0000 0000 0000 0000 0111)- XOR 연산을 활용한 비교와 암호화
XOR 연산은 비트 값이 같으면 0을 반환한다.
즉, 자기 자신과 XOR 연산하면 결과는 0이다.
두 변수에 저장된 값끼리 XOR 연산하여 결과가 0인지 확인하면 두 값이 같은지 비교할 수 있다.
더 나아가, 같은 값에 어떤 값을 2번 XOR하면 원래의 값과 동일해진다는 특성을 이용할 수도 있다.
예를 들어 x ^ y를 수행한 결과가 z일때, z ^ y = x ^ y ^ y = x이다.
이러한 특성을 기반으로, y를 key로 설정하면 간단한 암호화, 복호화가 가능하다.
x ^ y = z
z ^ y = x ^ y ^ y = x
XOR 연산은 이러한 특성에 의해 어셈블리 코드나 암호 기법에 자주 등장하니 잘 기억해두면 좋다.
- 시프트 연산을 활용한 곱셈, 나눗셈
앞서 시프트 연산은 을 곱하거나 나눈 결과와 동일하다는 것을 보았다.
따라서 곱셈이나 나눗셈 연산자 대신 시프트 연산자를 사용하여 간단한 산술 연산을 수행할 수 있다.
시프트 연산자를 사용하면 비트 레벨에서 연산을 하므로 더 효율적이고 속도가 빠르다.
→ 왜 시프트 연산은 을 곱하거나 나눈 결과와 동일하니
인코딩, 디코딩
인코딩, 디코딩
인코딩: 데이터를 특정한 형식으로 변환하는 것.
데이터의 크기를 줄이거나, 컴퓨터가 이해하기 쉽게 변환할 때 사용한다.
인코딩된 데이터는 디코딩하여 원래의 값을 구할 수 있다.
인코딩은 암호화와 유사하지만,
암호화는 데이터의 기밀성을 목적으로 남이 데이터를 알아보지 못하도록 변환하기 때문에 비밀키가 있어야 원문을 복구할 수 있지만,
인코딩은 누구나 표준화된 방식을 사용해서 디코딩하여 원문을 구할 수 있다는 점이 다르다.
인코딩 예시로 압축이 있다.
인코딩은 컴퓨터가 데이터를 효율적으로 다루도록 중요한 역할을 수행한다. 그만큼 해킹을 공부하다보면 웹, 시스템, 네트워크 등 모든 분야에서 인코딩이 중요하다는 것을 알 수 있다.
어떤 인코딩된 데이터의 생김새를 보고 인코딩 방식을 유추하여 직접 디코딩해서 원문으로부터 단서를 얻어야 하는 경우도 있다. 이를 위해 자주 쓰이는 인코딩 방식과 각각의 형태를 알고 있으면 좋다.
아스키 코드
컴퓨터는 0과 1만을 이용하여 정보를 처리하고 표현한다. 우리가 입력하는 모든 글자가 0과 1로 변환되려면 숫자로 표현되어야 한다. 이를 위한 것이 아스키 코드이다.
아스키 코드(American Standard Code for Information Interchange, ASCII)
: 정보 교환을 위한 미국 표준 코드로, 문자를 숫자로 변환하는 문자 인코딩(character encoding)의 표준.
아스키 코드를 사용하여 문자를 숫자로 인코딩하면
서로 다른 장치 간 데이터 전송을 더 쉽게 수행할 수 있다.
아스키 문자 1개는 1바이트(16진수 2개) 크기로,
총 8비트(7비트로 문자를 표현하고 1비트는 오류 체크를 위해 사용)
따라서 가지의 문자 표현이 가능하며,
각 문자는 0~127까지의 10진수 값을 가진다.
이 값을 문자의 아스키 값이라고 한다.(ASCII value)
하단의 아스키 테이블을 보면 아스키 값에 해당하는 문자를 알 수 있다.

아래 표는 아스키 값이 문자로 표현되는 예시이다.
일련의 비트 값 0b 0110 0011 0110 0001 0111 0100은 총 24비트(3바이트)이므로 아스키 문자 3개로 표현할 수 있다.
8비트(1바이트)씩 보면, 각각 10진수로 99, 97, 116이다.
아스키 테이블에서 각 10진수에 해당하는 문자는 99=c, 97=a, 116=t 이다.
즉, 해당 비트 값을 아스키 문자열로 나타내면 cat이다.

*전체 아스키 테이블 링크
https://www.asciitable.com/
- 아스키 테이블 실습
아스키 테이블을 참조하여 다음 일련의 비트를 해석해보시길 바랍니다.

정답 : Hello, Dreamhack!
유니코드
아스키 코드는 미국에서 만든 표준 코드인 만큼 알파벳 대소문자, 숫자, 특수 문자, 제어 문자만을 포함하고 있다.
초반에는 이러한 코드도 문제가 없었으나, 점차 다양한 언어와 문자가 나타나면서 새로운 형식이 필요해졌고 유니코드가 등장했다.
유니코드: (영어 뿐 아니라) 전세계 모든 언어의 문자에 고유한 번호를 부여하는 국제 표준 코드.
서로 다른 언어를 사용할 때 문자가 호환되지 않는 문제를 해결하기 위해 만들어졌다.
아스키 코드보다 용량으르 크게 확장하여
최대 32비트로 문자 1개를 표현하여,
ASCII 기준 원래 문자 1개는 8비트(오류 판별비트 빼고 7비트)
현재 143000개 이상의 문자를 표현가능함.
유니코드의 처음 128개 문자는 아스키 코드 문자와 정확히 일치함.(유니코드 안에 아스키 코드가 포함됨)
유니코드 값은 U+뒤에 16진수를 붙여 나타냄.
유니코드를 사용하는 다양한 인코딩 형식: UTF-8, UTF-16, UTF-32 등
→ 이는 컴퓨터가 어떤 문자를 어떻게 읽어야 하는지 미리 정해줌.
UTF 뒤 숫자는 비트를 의미함.
ex. UTF-8은 1~4바이트의 가변적인 크기로 문자 1개를 표현하는 방식으로, 아스키 코드와 유사함. 현재 컴퓨터로 볼 수 있는 글자는 대부분 UTF-8로 인코딩된 값.
URL 인코딩(퍼센트 인코딩)
웹에서 사용되는 URL은 특정한 형식의 문자열만 허용한다.
알파벳 대소문자, 숫자, 일부 특수 문자만을 포함할 수 있다.
URL 인코딩: 웹 브라우저로부터 받은 URL 문자열을 유효한 형식으로 변환하는 것
URL 인코딩을 통해 문자열을 인터넷으로 전송 가능한 형식으로 변환한다.
이를 통해 전송 중에 문자가 수정되거나 의도와 다르게 해석되는 것을 막을 수 있다.
허용되지 않는 문자(=인코딩이 필요한 특수문자)
→ :/#[]@$&'()*+,;=%공백
URL 인코딩은 % 기호 뒤에 해당 문자의 아스키 코드 16진수 값을 붙여 나타낸다.
ex. URL 안에 공백이 포함되는 경우 + 기호 혹은 %20으로 변환된다.
여기서 %20이 인코딩 결과이다.
예를 들어, 문자열 Welcome, Dreamhack Beginners! :)를 URL 인코딩한 결과는
Welcome%2C20Dreamhack%20Beginners%21%20%3A%29이다.
Base64 인코딩
Base64 인코딩: 이진 데이터를 아스키 문자로 구성된 텍스트로 변환하는 인코딩 방식
총 64개의 아스키 문자가 인코딩에 사용되기 때문에 64진법(Base 64)라는 의미에서 이름이 붙여졌다.
64개의 아스키 문자는 알파벳 대소문자(52자), 숫자(10자), +, / 이다.
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/Base64 인코딩은 이진 데이터를 그대로 포함할 수 없이 텍스트만 허용되는 환경에서 이진 데이터를 텍스트 형식으로 나타내기 위해 사용한다.
ex. 이진 데이터인 이미지를 html 파일에 넣는 경우 base64로 인코딩해 넣을 수 있다.
Base64 인코딩 방식은 다음과 같다.
-
원본 이진 데이터를 비트 나열로 표현하고, 이를 6비트씩 끊어서 묶는다.
Base64 인코딩 시 원본 이진 데이터(Binary Data)는 0과 1로 구성된 이진수를 의미한다
만약 비트의 개수가 6의 배수가 아닐 경우, 0을 뒤에 추가하여 6의 배수로 만든다. -
각 6비트 묶음을 수로 변환한 뒤, base64 테이블 에서 해당하는 문자를 찾아 이로 치환한다.
-
이렇게 치환 과정을 거친 뒤, 글자 수가 4의 배수가 되도록 문자 '='을 반복해 뒤에 추가한다. 이를 패딩(Padding)이라 한다.
패딩을 왜 넣어야 할까?
예를 들어서ZA라는 두 글자를 디코딩하게 되면,
011001 000000이라는 12개의 비트 나열로 바뀌게 되고,
이를 앞에서 8개씩 끊어 읽으면 아스키 문자 'd'(01100100) 이후0000이 남게 된다.
이 경우 디코딩을 하는 입장에서 뒤에 추가적인 내용이 있는데 오지 않은 것인지, 아니면 여기서 디코딩을 끝내는 게 맞는지 알 수 없게 된다.
그러므로 총 비트의 개수가 8의 배수가 되게끔 패딩 문자 '='를 뒤에 붙여 이를 명확하게 하는 것이다.
(그니까 패딩 비트열 바로 앞의 비트열 단에서 남은 0의 개수를 포함해서 8개가 되도록 뒤에 패딩 숫자를 맞추는데에 = 이 쓰이는 것임)
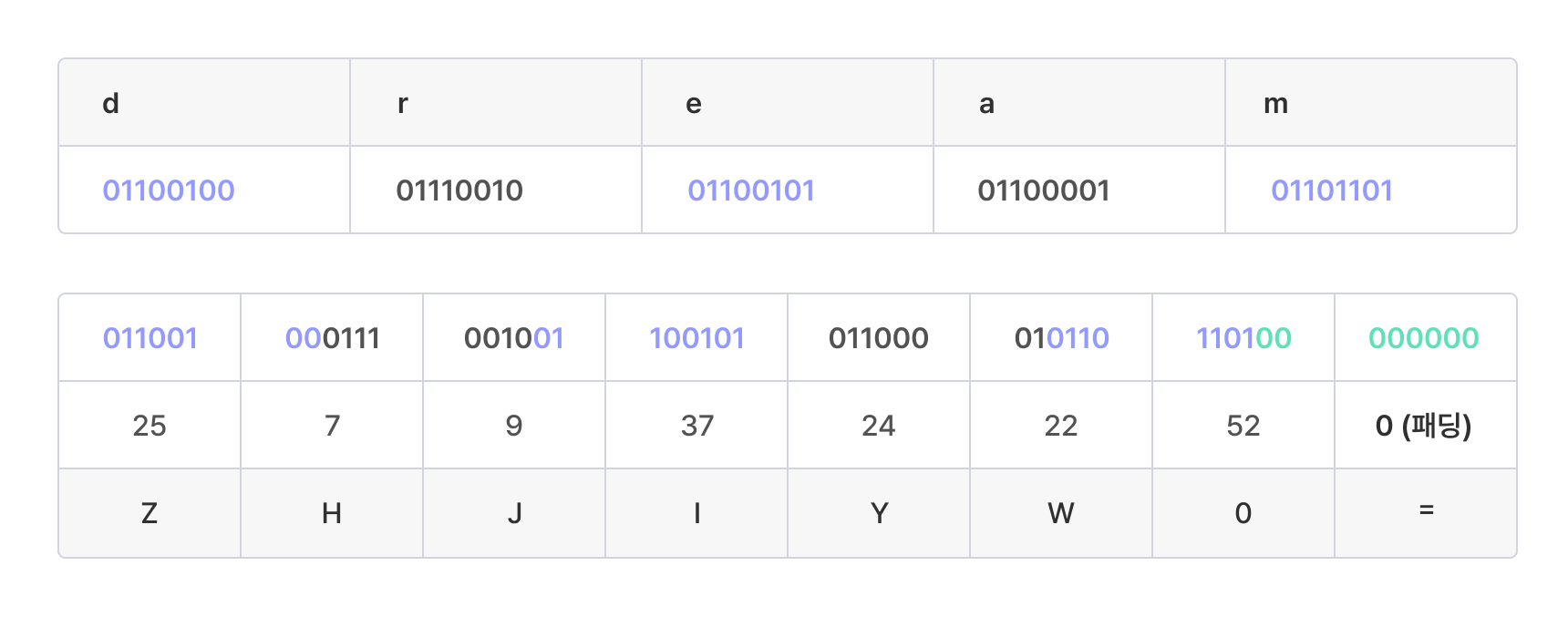
그림) 문자열 dream을 base64 인코딩한 예시
인코딩 결과: ZHJlYW0=이다.
→ Base64 인코딩 시 원본 이진 데이터(Binary Data)라는 것의 의미
- Base64 디코딩 실습
온라인 base64 디코더를 사용해서 다음의 데이터를 직접 디코딩해보길 바란다.
SGFwcHkgRHJlYW1oYWNrLCBIYXBweSBIYWNraW5nIQ==정답: Happy Dreamhack, Happy Hacking!
인코딩 도구
인코딩, 디코딩을 위한 도구는 매우 다양하다.
문자열을 특정 형식으로 인코딩, 디코딩할 수 있는 몇 가지 도구는 다음과 같다.
해킹 문제를 풀거나 문자열을 원하는 형태로 변환하고 싶을 때 유용하니 직접 사용해보는 걸 추천한다.
https://tools.dreamhack.games/cyberchef
https://emn178.github.io/online-tools/base64_encode.html
https://encoding.tools/
운영체제(OS)
운영체제
사용자는 웹 브라우저, 엑셀, 메모장 등의 프로그램으로 원하는 작업을 수행하곤 한다.
응용 프로그램: 사용자를 위해 특정한 기능을 수행하는 프로그램
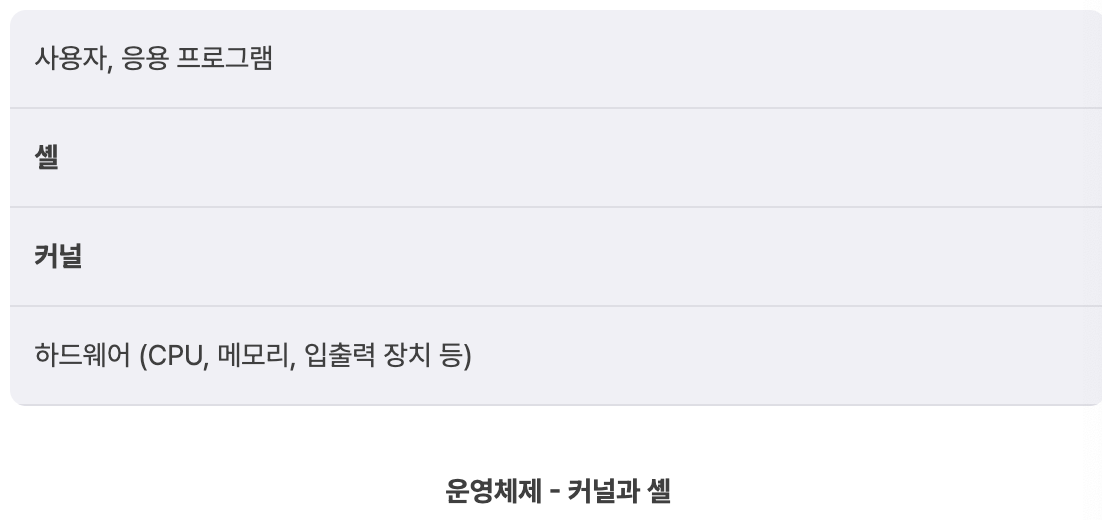
이때 응용 프로그램의 동작을 수행하고 응용 프로그램에게 시스템 자원을 할당하는 등의 복잡한 관리 작업은 사용자가 아니라 운영체제(Operating System, OS)라는 소프트웨어에 의해 이루어진다.
사용자 및 응용 프로그램은 컴퓨터 하드웨어(CPU, 메모리, 입출력 장치 등)에 직접 접근하지 않는다. 대신 운영체제가 하드웨어와 사용자/응용 프로그램 사이에서 중재자 역할을 한다. 운영체제는 컴퓨터 과학에서 매우 중요하고 공부할 내용이 많은 주제이지만 본 강의는 기초강의인 만큼 운영체제가 무엇이고 무슨 일을 하는지만 간략하게 알아본다.
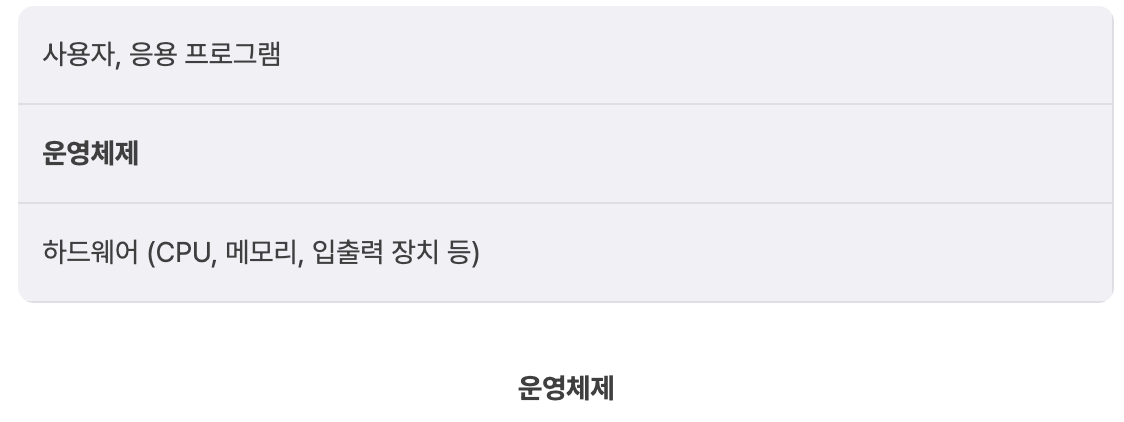
운영체제가 하는 일
운영체제는 CPU, 메모리, 입출력 장치(키보드, 마우스, 디스크) 등의 하드웨어 자원을 효율적으로 사용할 수 있도록 분배, 할당하여 성능을 높인다.
만약 운영체제가 없다면 사용자가 하드웨어를 직접 관리해야 한다. 운영체제 덕분에 사용자가 컴퓨터를 보다 편하게 사용할 수 있다. 운영체제는 하드웨어 자원들을 적절히 분배하고 각 기능을 수행한다.
운영체제가 수행하는 대표적인 기능
- 실행중인 프로그램 즉, 프로세스에 CPU를 번갈아 할당해야 하는데, 이때 어떤 프로세스에 CPU를 할당할지 결정한다.(CPU 스케줄링)
- 메모리 공간을 각 프로세스에 분배하고 사용하는 과정을 관리한다.
- 컴퓨터가 입출력 장치와 정보를 주고 받는 과정을 관리한다.
운영체제는 사용자와 컴퓨터 사이 인터페이스 역할도 한다.
사용자가 컴퓨터에 명령을 내릴 수 있도록 하는데, 이는 다음으로 소개할 '셸'의 기능이다.
커널과 셸
운영체제는 크게 커널과 셸로 나눌 수 있다.
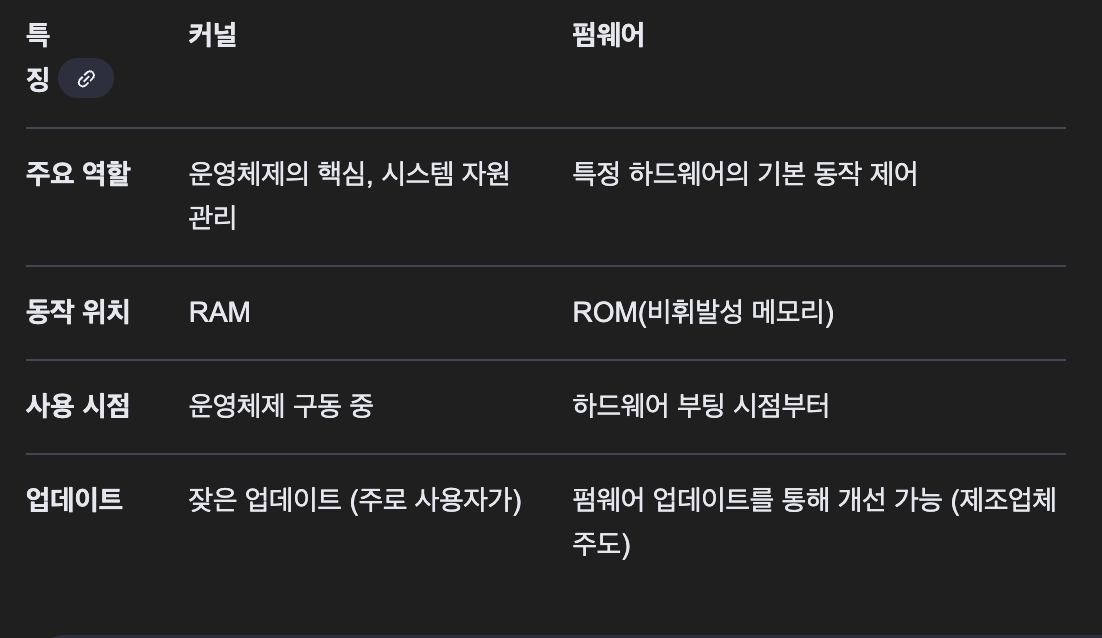
커널(kernel, 알맹이): 운영체제의 핵심 기능인 하드웨어 관리를 실제로 수행하는 프로그램
커널은 소프트웨어와 하드웨어 간의 커뮤니케이션을 관리하며, 시스템이 부팅될 때 메모리에 올라가서 꺼질때까지 실행된다.
커널, 펌웨어 차이
셸(shell, 껍질): 사용자와 운영체제의 커널 사이에서 사용자가 운영체제에 명령을 내릴 수 있도록 인터페이스 역할을 한다.
사용자가 셸에 명령을 입력하면, 셸이 명령어를 해석하여 커널에 요청한다.
커널은 명령을 수행하며 하드웨어를 조작하고 수행 결과를 셸에 전송한다.
셸은 이 결과를 해석하여 사용자에게 출력해준다.
즉, 셸은 명령어를 해석하는 역할을 하여
사용자와 운영체제가 소통할 수 있도록 한다.
셸을 획득하면 명령어를 통해 원하는 작업을 수행하고 시스템을 제어할 수 있게 된다. 따라서 일반적으로 셸을 획득하는 것을 시스템 해킹(포너블)의 성공으로 여긴다.
운영체제 종류
운영체제는 크게 Windows 운영체제와 UNIX/Linux 계열 운영체제로 나눌 수 있다.
windows: 마이크로소프트사에서 개발한 운영체제로, Graphical User Interface(GUI) 기능을 제공하여 사용자가 편리하게 사용할 수 있다. 2022년 통계에 의하면 대한민국 PC 운영체제 점유율의 90% 가까이를 윈도우가 차지하고 있다. 그만큼 많은 한국인들은 어렸을 때부터 윈도우를 사용해왔으며 윈도우 사용법에 친숙할 것이다.
UNIX: 벨 연구소에서 개발한 운영체제로, 대부분의 운영체제는 UNIX로부터 발전된 기술을 사용하고 있다. 따라서 현대 운영체제의 원형이라고 할 수 있다. 사용자가 키보드로 입력하는 명령에 의해 조작되는 Character User Interface(CUI) 기반의 대화식 운영체제이다.
UNIX가 개발된 이후, 리눅스 토발즈(Linus Benedict Tovaids)가 UNIX 기반의 Linux 운영체제를 개발했다.
Linux는 소스 코드를 공개하여 누구나 수정하고 재배포할 수 있는 오픈소스 프로그램으로, 많은 사람에 의해 계속하여 발전하고 있다. Linux 역시 CUI 기반의 운영체제이다. Linux를 기반으로 Ubuntu, CentOS 등의 다양한 버전이 존재하며, 드림핵 강의에서는 Ubuntu Linux를 사용한다.
UNIX 기반의 또 다른 운영체제로는 애플에서 개발한 GUI 기반 운영체제 macOS, 스마트폰을 많이 사용하는 현대인에게 친숙한 모바일 운영체제 Android와 iOS가 있다.
모바일에도 펌웨어 모드가 있다.

CUI, GUI차이
- CUI
: 그냥 개답답한 vim 같은거임.
텍스트 기반 명령어 입력 방식의 인터페이스.
키보드만으로 조작.
속도는 빠름(하드웨어와 직접 상호작용)
적은 메모리 필요
ex. MS-DOS- GUI
: 클릭으로 가능한 편한 인터페이스.
시각적 요소를 활용한 그래픽 기반 방식
아이콘, 메뉴, 버튼 등을 클릭하여 조작
속도 느림(그래픽 처리 필요)
많은 메모리 필요
ex. Windows, macOS
이외에도 사용자 인터페이스(UI)의 종류로는 GUI(그래픽 사용자 인터페이스), CLI(명령줄 인터페이스), VUI(음성 사용자 인터페이스), NUI(자연어 사용자 인터페이스), TUI(텍스트 사용자 인터페이스) 등
이번 강의로 얻어가야 할것
컴퓨터에서 값을 표현하고 메모리에 저장하는 방법
비트 연산을 수행하는 방법
인코딩 방식
운영체제가 뭔지

토글
- 0x, 0b를 앞에 붙이는 이유c언어보다 먼저 8진수(octal)는 단순히 0으로 시작하는 것으로 정의되었는데
(ex. 017은 10진수 15)
이후 16진수를 도입할 때 8진수와 구별하기 위한 추가 문자가 필요했음. 일단 0x의 경우, 16진수의 영어식 표기는 hexadecimal이고, x를 따서 0뒤에 붙이는 것임.
- 왜 2바이트 이상 데이터부터 메모리에 연속적으로 저장될까
1바이트는 컴퓨터에서 데이터를 표현하고 주소를 지정하는 최소 단위이다. 만약 어떤 데이터가 1바이트 크기라면 메모리에서 주소 하나(방 하나)를 차지하게 된다.
이 경우, 데이터 전체가 하나의 주소에 저장되므로 '연속적으로 저장된다'는 표현이 필요하지 않다.'
데이터의 크기가 1바이트를 초과하여 2,4,8바이트 등이 될 때 연속 저장(contiguous storage)라는 개념이 중요해진다.
ex. 2바이트 이상 데이터 : 예를 들어, int 타입의 정수가 4바이트라 가정하면. 이 데이터는 메모리의 4개의 연속된 바이트 공간을 차지해야 한다.
연속 저장의 이유 : CPU가 데이터를 한 번에 효율적으로 처리하기 위해서 연속 저장을 하는 것이다. 4바이트짜리 정수 값(0x12345678)이 주소 0x1000, 0x1002, 0x1005, 0x1008처럼 흩어져 저장된다면, CPU가 이 데이터를 읽어오기 위해 메모리 접근을 4번해야한다. 이는 비효율적이고, 처리 속도를 저하시킨다.
연속 저장의 효과 : 데이터가 0x1000부터 0x1003까지 연속적으로 저장되면 CPU는 데이터의 시작주소(0x1000)만 알고 있으면 한 번의 작업으로 4바이트 전체를 효율적으로 읽을 수 있다.
- 낮은 주소에 저장된다는 말 뜻 (feat. 메모리 주소의 범위)
- 낮은 주소: 메모리 공간의 시작점, 주소 번호가 작은 쪽 (ex. 0x00000000)
운영체제 커널이나 시스템의 핵심 데이터는 보통 낮은 주소에 저장되는 경우가 많다.
- 높은 주소: 메모리 공간의 끝 부분, 주소 번호가 큰 쪽 (ex. 0xFFFFFFFF 또는 그 이상)
일반적인 프로그램 데이터(스택, 힙)는 이 높은 주소 쪽을 향헤 영역을 확장하는 경우가 많다.
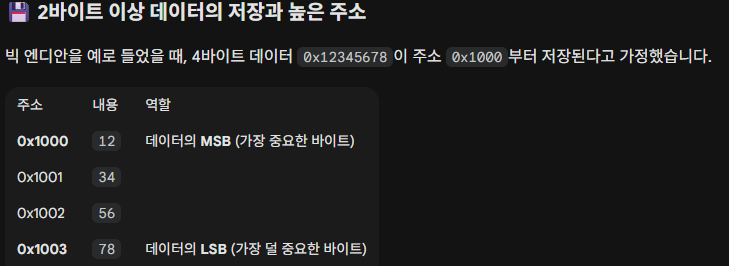
여기서 0x1003은 4바이트 데이터를 이루는 주소들 중 가장 높은 주소가 된다.
즉, 빅 엔디안은 MSB를 낮은 주소에, LSB를 높은 주소에 저장하고
리틀 엔디안은 LSB를 낮은 주소에, MSB를 높은 주소에 저장한다.
- 왜 0x7654321 이 아니라 0x67452301일까
바이트 순서가 역전되기 때문이며, 여기서 바이트 내 니블(nibble) 순서는 바뀌지 않기 때문이다.
즉, 바이트 단위(16진수 두자리가 1바이트)로 순서가 뒤집히는 것이지, 바이트를 이루는 각 자릿수(니블)이 뒤집히는 것이 아니다.
먼저 아래와 같이 4바이트 데이터(0x01234567)을 1바이트 단위로 분리한다.

리틀 엔디안은 가장 덜 중요한 바이트(LSB)를 가장 낮은 주소에 저장한다.
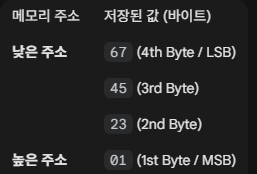
만약 CPU가 이 메모리 위치에 접근하여 데이터를 읽어올 때, 이 시스템이 빅 엔디안 방식이라고 착각하고 읽는다고 가정하자.
그러면 빅 엔디안은 가장 낮은 주소에 있는 바이트를 전체 데이터의 MSB(가장 중요한 부분)로 해석하게 된다.

CPU가 메모리에서 바이트를 순서대로 읽어와 다시 4바이트 데이터로 조합하면 다음과 같아진다.
따라서 0x1234567이 0x67452301로 바뀌는 것이다.
* 여기서 니블이란? : 16진수 1자리를 말함. 2진수 4개. 즉 4비트로 이루어진 정보단위.요약하면,
0x7654321처럼 수의 모든 자릿수(=니블)가 완전히 역순으로 바뀌지 않는 이유는
엔디안 방식은 바이트(=16진수 2개) 단위 덩어리로만 순서를 결정하며
하나의 바이트 내부(ex. 67)의 비트나 니블 순서는 건드리지 않기 때문이다.
- MSB(최상위비트)는 시프트 연산자 종류와 상관없이 무조건 왼쪽에 위치한다.
ex. 1234라는 수가 있을 때 1을 천의 자리로 읽는 것과 비슷한 원리.
예를 들어 8비트 2진수 1000 0000 이 있다고 할때 가장 왼쪽의 1이 MSB고, 가장 오른쪽의 0이 LSB이다.
무조건!
LSB: 비트열의 가장 오른쪽, LSB의 값(0 또는 1)은 빈자리를 채우는 채움 비트로 사용되지 않는다, 왼쪽 시프트 시 비트열이 왼쪽으로 이동하여 LSB 자리가 비면 항상 0이 채워진다, 오른쪽 시프트 시 LSB는 비트열 밖으로 사라진다.
MSB: 비트열의 가장 왼쪽, MSB의 값이 0이면 양수이고 1이면 음수(2의 보수)로 부호 비트 역할을 한다, 왼쪽 시프트 시 비트열 밖으로 사라진다, 오른쪽 시프트 시 빈자리가 MSB쪽에 생기고 채움 비트가 MSB의 값에 따라 결정된다.
시프트 연산 시 빈자리 채움 규칙에 대해서는 다음과 같이 설명될 수 있다.

- 왜 시프트 연산은 $2^n$을 곱하거나 나눈 결과와 동일하니

- Base64 인코딩 시 원본 이진 데이터(Binary Data)라는 것의 의미
컴퓨터는 모든 정보를 0과 1의 조합인 이진 형식으로 저장하고 처리한다.
Base64 인코딩은 이러한 이진 데이터를 텍스트 기반 시스템 (예: 이메일, HTTP 등)에서 안전하게 전송하거나 저장하기 위해 텍스트로 표현하는 방식이다.
즉, 원본 데이터는 이미지 파일, 실행 파일, 압축 파일 등 어떤 형태이든 컴퓨터 내부적으로는 모두 0과 1로 이루어진 바이트(byte) 배열 형태로 존재하며, Base64는 이 바이트들을 텍스트 문자열로 변환하는 것이다.
- 운영체제 없이도 컴퓨터가 돌아갈 수 있을까
1. 전원 공급 장치, 메인보드, CPU, RAM 등 하드웨어 부품들은 전원을 인가하면 작동이됨.
2. 펌웨어(BIOS/UEFI) 실행: 컴퓨터를 켰을때 가장 먼저 실행되는 것은 메인보드에 내장된 펌웨어인 BIOS(basic input/output system) 또는 UEFI(unified extensible fireware interfare)이다. 이 펌웨어는 하드웨어를 초기화하고 점검하며 운영체제를 찾아서 로드하려고 시도한다.
운영체제가 없으면: 부팅 과정에서 bios/uefi가 부팅 가능한 운영체제를 찾지 못하여 화면에 'an operating system wasn't found'이런 식으로 운영체제를 찾을 수 없다는 오류메시지를 표시하고 멈춘다. 사용자는 이 상태에서 키보드 입력을 통해 bios 설정 화면에 진입하는 정도의 제한적인 상호작용만 할 수 있다.
운영체제 없이 컴퓨터를 작동시키는 것은 '베어메탈 프로그래밍(bare-metal programming)'이라고 하여 마이크로컨트롤러나 시스템(ex. 토스터, 알람 시계..)에서는 가능하지만 일반적인 PC에서는 모든 작업을 수동으로 프로그래밍해야하므로 사실상 불가능함.
