[DB] Nested Loop Join
JOIN Alogrithms
참고:
NETSED LOOP JOIN, SORT MERGE JOIN, HASH JOIN
그루비
대용량 데이터베이스 아키텍처 2 - 이화식
RDBMS 는 동일한 속성(Attributes)을 가지는 데이터를 레코드라는 개념으로 추상화하고
레코드의 집합을 테이블(Relation)이라는 개념으로 관리하는것이 핵심입니다.
또한, 궁극적으로 이 테이블 간의 관계를 활용하여 실제 세상(Real World)를 모방합니다.
그렇기때문에, 테이블 간의 관계를 맺어서 또 다른 의미있는 데이터를 만드는 것은
핵심중의 핵심이고, RDBMS에서는 그것을 Join 연산을 통해서 제공합니다.
그리고, Join 방식에는 3가지가 존재합니다.
1. Nested Loop join : 중첩반복
2. Merge join : 정렬병합
3. Hash join : 해시매치
🟩 Netsted Loop Join
바깥 테이블의 처리 범위를 하나씩 액세스 해가면서 안쪽 테이블을 조인하는 방식입니다.
아래의 쿼리가 Join 을 수행하는 방식을 보며, 알아보겠습니다.
SELECT * FROM
FROM TAB1 a, TAB 2
WHERE a.KEY1 = b.KEY2
AND a.FLD1 = '111'
AND a.FLD2 like 'AB%'
AND b.COL1 = '10';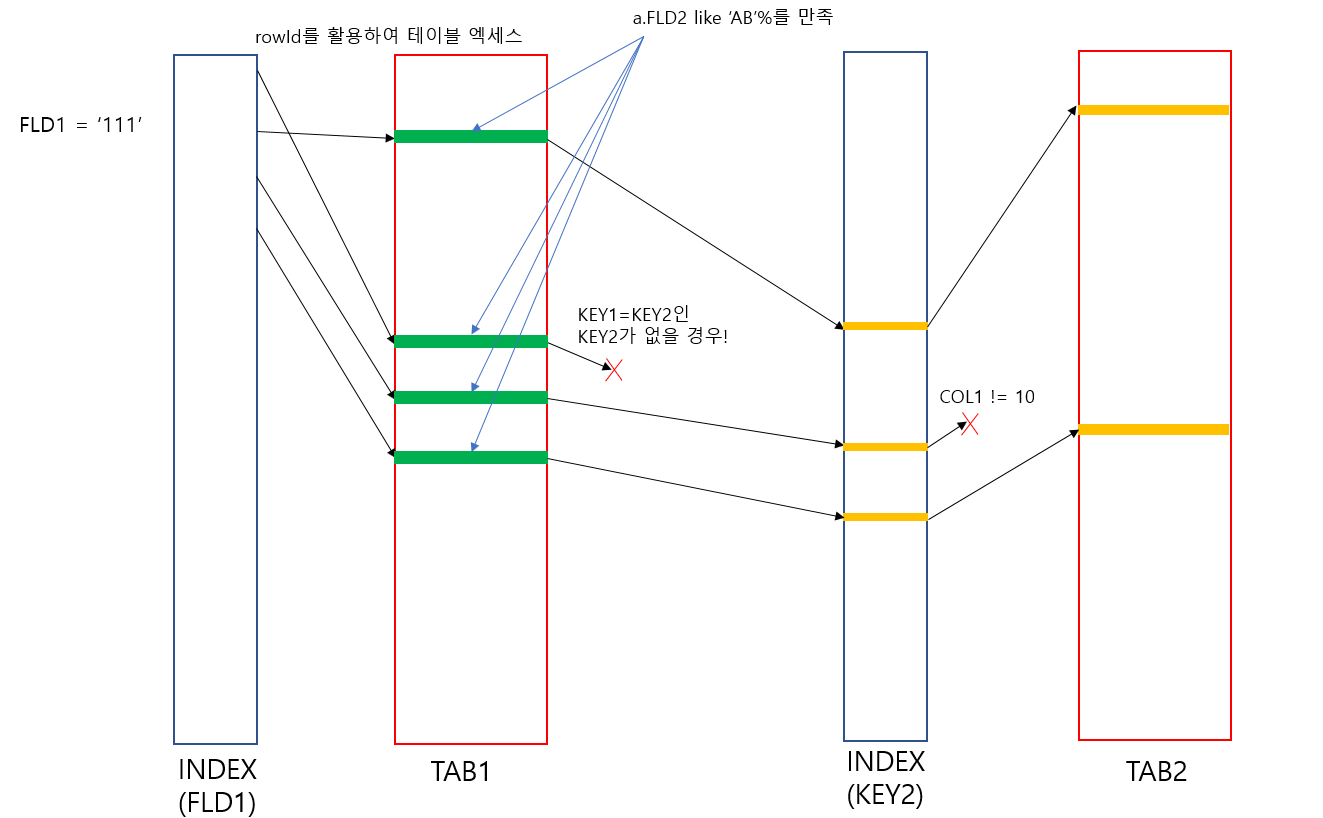
최대한 과정을 쉽게 따라갈 수 있도록 그림을 그려보았는데요.
구체적으로는 아래와 같이 진행되니 그림과 비교해보며 읽어보시기 바랍니다.
Nested loop join 진행과정
- TAB1(좌측 테이블)이 인덱스 FLD1을 통해 FLD1='111'인 범위 중 첫 번째 로우를 액세스합니다.
- FLD1 인덱스의 ROWID에 해당되는 TAB1의 로우를 액세스 합니다.
액세스된 로우의 모든 컬럼값들은 상수값이 됩니다.
이 상수값으로 다시 FDL2 LIKE 'AB%'인지 체크하여 성공하면 다음으로 진행하고
실패하면 (1)로 돌아가서 다음 건으로 다시 시도합니다 - 여기서 성공한 것들에 대해 TAB1의 KEY1 상수값을 이용하여 TAB2의 KEY2 인덱스로 대응되는
인덱스 로우를 찾습니다. 여기서도 대응되는 로우를 찾지 못한다면 다시 (1)로 돌아갑ㄴ디ㅏ - (3)에서 찾아진 KEY2에 해당되는 ROWID를 이용해서 로우에 액세스합니다.
액세스된 로우에 대해서 COL1 = '10'인지 체크하고, 맞다면 결과를 운반단위로 보낸다 - 이제 다시 (1)로 돌아가서 FDL1 인덱스의 두 번 째 로우를 읽어 반복한다
만약 부분범위처리가 가능하다면 운반단위가 채워질 때까지만 수행되고 일단 멈추며
전체범위처리라면 FDL1 범위가 끝날 때까지 계속해서 반복 수행된다.
이렇게, 처리되는 방식을 보면 2중 루프와 동일한 형태로 진행되는 것을 볼 수 있으며
그때문에, Nested Loop Join 이라고 불립니다.
여담으로, 여기서 TAB1(좌측)은 드라이빙 테이블 TAB2(우측)은 드리븐 테이블이라 불립니다.
예측하실 수 있듯이, 드라이빙 테이블이 어떤 테이블로 선택되느냐에 따라서
매우 다르게 실행되게 되며, 수행속도와 범위에 많은 차이가 존재할 수 있습니다.
이 주제에 대해서는 범위가 너무 넓기 때문에 여기서 다룰 수 없지만, 간단히 다뤄보면
위의 예제에서는 드라이빙 테이블이 TAB1이었고, 그것의 인덱스 FLD1 을 사용했습니다.
하지만, TAB2를 드라이빙 테이블로 선택해서 KEY2+COL1 의 복합인덱스로 사용해서
Nested Loop Join을 수행할 수도 있습니다.
그렇게되면, TAB2의 ROW 분포 특성에 따라서 TAB1을 드라이빙 테이블로 사용했을 때와는
또 다른 방식으로 수행될 수 있겠습니다.
따라서, 각 테이블의 인덱스 특성과 분포도를 확인하고, 실행하고자 하는 쿼리의 조건(=,<,>,LIKE)을
잘 활용해서, 필요하다면 Query Hint 를 제공해서 옵티마이저에게 더 효율적인 방식의
실행계획을 세울 수 있도록 도와주는 것도 필요하겠습니다.
Nested loop join 특징
1. 메모리 사용량이 적다
메모리에 한 번에 많은 데이터를 올리지 않고 개개의 로우에 대해서 실행되므로
메모리의 사용량이 많지 않습니다.
2. 바깥 테이블과 안쪽 테이블의 크기는 성능과 관련 없다
3. Outer 테이블의 조인 컬럼 인덱스 유무가 매우 중요하다.
인덱스가 존재하지 않으면 Outer 테이블에서 읽히는 건마다 Inner 테이블 전체를 스캔하기 때문이다.
이 때 옵티마이져는 Sort Merge Join이나 Hash Join을 고려한다
OLTP 시스템에서 조인을 튜닝할 때에는 일차적으로 NL Join 부터 고려하는 것이 올바른 순서다.
우선 NL Join 메커니즘을 따라 각 단계의 수행 일량을 분석해 과도한 Random 액세스가 발생하는 지점을 파악한다. 조인 순서를 변경해 Random 액세스 발생량을 줄일 수 있는 경우가 있지만, 그렇지 못할 때는 인덱스 컬럼 구성을 변경하거나 다른 인덱스의 사용을 고려해야 한다.
여러가지 방안을 검토한 결과 NL Join이 효과적이지 못하다고 판단될 때 Hash Join이나 Sort Merge Join을 검토한다
4. 부분범위처리를 하는 경우에 유리해진다
다른 방식의 조인들은 원천적으로 부분범위 처리가 불가능하기에
부분범위처리로 처리하고자 한다면, Nested Loop Join을 선택해야 한다.
5. 처리량이 적은 경우 유리하다
실행 특성상, 처리량이 적은 경우에 유리하다.
하지만, 랜덤 엑세스가 잦게 발생하므로(매 ROW 당 랜덤엑세스)
데이터량이 많다면 큰 부담이 될 수 있다.
6.조인 순서를 찾는것이 중요하다
앞서 말씀드렸듯이, 어떤 테이블이 드라이빙 테이블이 되는지
어떤 테이블이 드리븐 테이블이 되는지에 따라서
외부 루프의 범위가 결정되기 때문에, 조인 방향 선택이 매우 중요하게 됩니다.
